| TerarkDB
简介
TerarkDB 是一个拥有极高性能和数据压缩率的存储引擎。使用方法类似Facebook的RocksDB,不过比
RocksDB 具有更多功能,下面是 TerarkDB 的功能特性:
(1)高压缩率,通常是 snappy 的2~5倍
(2)实时免解压直接检索数据
(3)Query 延迟很低并且很稳定
(4)同一 Table 可包含多个索引,支持联合索引,支持范围搜索
(5)原生支持正则表达式检索
(6)支持嵌入进程,或者 Server-Client 模式>
(7)数据持久化
(8)支持 Schema,包含丰富的数据类型
(9)列存储以及行存储,支持 Column Group
TerarkDB 在互联网以及传统行业都有相当广泛的应用场景。由于 TerarkDB 对于读操作做了大量优化,因此更适合多读少写,以及批量写大量读的场景。
TerarkDB 使用方法相当灵活,可以作为独立库使用以适应客户的定制化场景。官方提供了下载包以及 Docker
以方便用户下载使用。目前支持Linux,Windows以及Mac OS操作系统。
TerarkDB 作为一个存储引擎,有自己的原生接口,同时提供兼容 LevelDB 的接口,从而可以适配到所有使用
LevelDB 的系统和应用,例如实现了大部分 Redis 接口的 SSDB。另外,大家广泛使用的 RocksDB
接口是 LevelDB 接口的超集,所以大部分使用 RocksDB 的系统和应用也可以很容易地适配到 TerarkDB。
Terark 官方提供了 TerarkDB 到 MongoDB 的适配,到 MySQL 以及其他分布式数据库系统的适配也在紧张的开发过程中,稳定版的
MongoTerark 产品已计划在近期发布。
TerarkDB 性能测试报告
目录
1.环境
1.1.服务器信息
1.2.比较对象
1.3.测试数据集
1.4.测试源代码
1.5.压缩率说明
2.Tests
2.1.随机读测试
2.2.随机写测试
2.3.读写混测
2.4 读延迟测试
1.环境
1.1.服务器信息

1.2.比较对象

1.3.测试数据集
Amazon movie data (~8 million reviews), 平均每条数据长度大约
1K
原始数据格式
product/productId: B00006HAXW
review/userId: A1RSDE90N6RSZF
review/profileName: Joseph M. Kotow
review/helpfulness: 9/9
review/score: 5.0
review/time: 1042502400
review/summary: Pittsburgh - Home of the OLDIES
review/text: I have all of the doo wop DVD's and this one is as good or better than the
1st ones. Remember once these performers are gone, we'll never get to see them again.
Rhino did an excellent job and if you like or love doo wop and Rock n Roll you'll LOVE
this DVD !! |
元数据(列名)
(1)因为 TerarkDB 有 Schema,不需要在每条记录中额外保存元数据(列名)
(2)为公平起见,对其它数据库,仅在列(字段)之间插入一个分隔符,不保存列名
数据集大小
movies数据集的总大小约为 9GB, 记录数大约为 800万
1.4.Benchmark 源代码
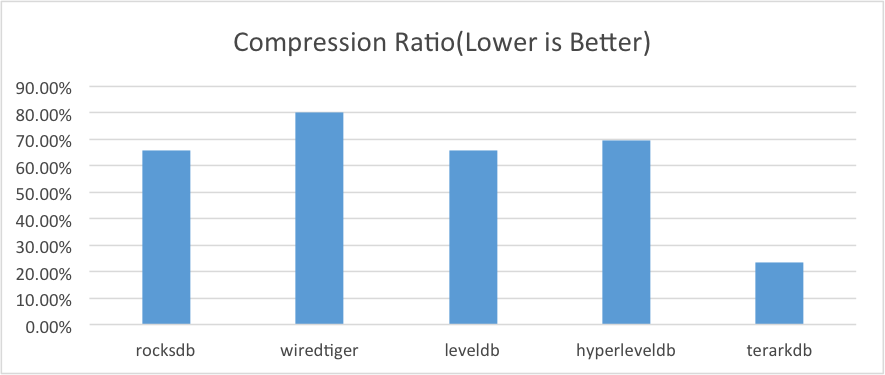
1.5.Compression Ratio
(1)TerarkDB 使用自己研发的压缩算法进行数据压缩
(2)其他数据库使用块压缩,块大小为 4KB,压缩算法设置为 snappy
(3)我们使用 随机写 的测试用例,对写入并压缩后的数据尺寸进行对比
2.Tests
所有的读操作,都是单条记录随机查询。所有的写操作,也都是单条记录随机插入或更新。 |
2.1.Random Read
(1)所有的数据会预先写入文件系统
(2)所有的数据库写入操作均启用压缩,配置 rocksdb/leveldb/wiredtiger
使用 snappy 算法
(3)TerarkDB使用我们自己专有的压缩算法,不需要块压缩,其他数据库均使用4KB的默认块大小(Block
Size)
2.1.1.数据小于内存
在这种情况下我们的内存足够大,可以把所有的数据装入内存,同时 TerarkDB 不需要专有缓存,但其它数据库需要专有缓存(主要用来缓存对块压缩解压后的数据),我们为这些数据库设置专有缓存设置为3GB。
同时这项测试我们不限制操作系统对内存的使用(总内存64GB),数据量远小于内存,操作系统可以把所有数据缓存起来。
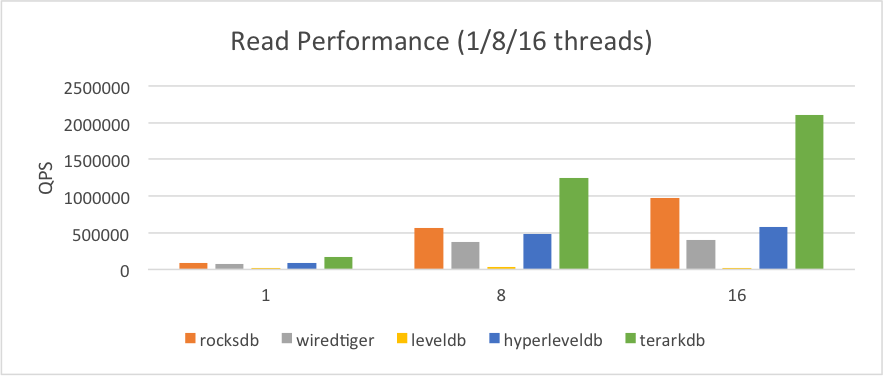
我们可以看到TerarkDB在这种情况下要好于其他数据库:
(1)TerarkDB 使用自主研发的数据压缩算法,可以直接提取单条记录,不需要传统数据库的块压缩/解压
(2)TerarkDB 使用自主研发的Succinct压缩型数据结构作为索引,使用更少的内存,并且搜索速度更快
2.1.2.数据略大于内存
当数据量无法全部载入内存的情况下,我们需要把数据存储在物理磁盘上(我们此处使用 SSD 作为存储介质)。
(1)操作系统可以使用的的物理内存限制为8GB
(2)我们为其他数据库设置了1GB的专用缓存用来装载热数据
(3)所有数据库进行了预热(TerarkDB开启mmap populate,
其他数据库进行一轮预读)
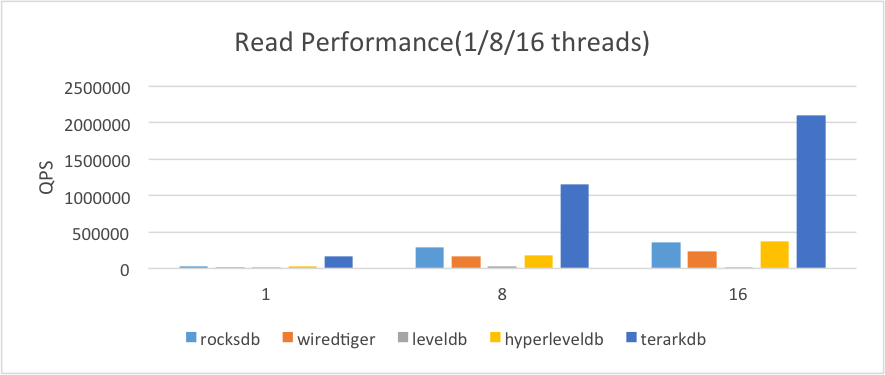
这种情况下,TerarkDB 的优势更明显 :
(1)除了 TerarkDB 以外,其他的数据库均需要使用块压缩,在随机读的情况下,即便有缓存支持,但毕竟缓存的大小有限,不可能把所有数据装入缓存,这就会导致频繁的磁盘I/O,降低读性能
(2)TerarkDB 的压缩率比较高,压缩后的数据可以全部装入内存,同时
TerarkDB 可以直接访问压缩后的数据,使 TerarkDB 的优势更加明显
(3)其他数据库由于使用了专有缓存,当读取的数据远远超出缓存容量,会造成大量的数据换入和换出,增加了额外的资源开销
2.1.3.数据远大于内存
(1)操作系统内存限制为3G
(2)为其他数据库设置256M的专用缓存
(3)所有数据库进行了预热(TerarkDB开启mmap populate,
其他数据库进行一轮预读)
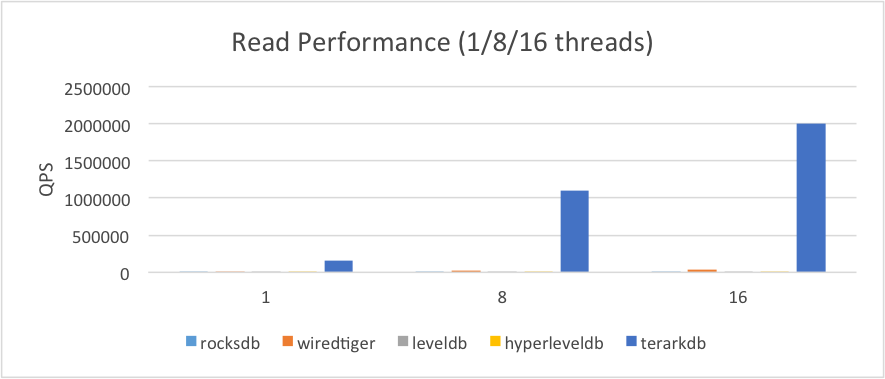
由于TerarkDB比其他数据库的数据高出太多,下面这幅图使用对数坐标,更便于查看数量级(请观察纵坐标轴)
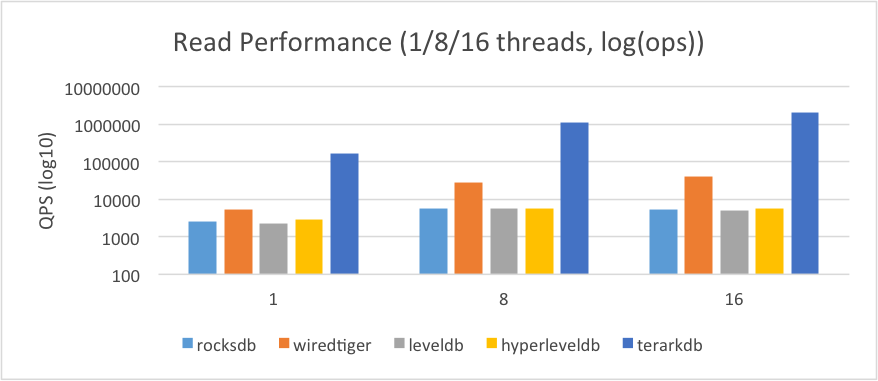
2.2.Random Write
(1)写入时所有的数据库均开启压缩,并且默认块压缩的大小为 4KB(TerarkDB不需要块压缩)
(2)所有的写 Buffer 都设置为256M
(3)写入时分别使用 1/3/6 个线程同时进行操作
2.2.1.数据小于内存
随机写测试和随机读(Random Read)测试的环境类似:
(1)存储介质使用内存文件系统(即数据先预读到内存文件系统中,以加快测试速度)
(2)操作系统内存不做限制
(3)除了 TerarkDB, 为其他数据库设置 3GB 的专用缓存
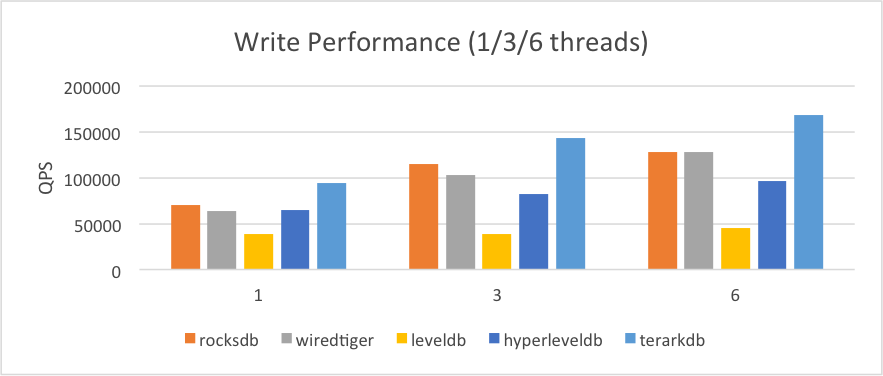
2.2.2.数据略大于内存
与随机读测试的环境类似:
(1)操作系统的总内存限制为 8GB
(2)除了 TerarkDB ,其他数据库的专用缓存设置为1GB
(3)数据存储介质采用 SSD
(4)写 buffer 设置为 256M
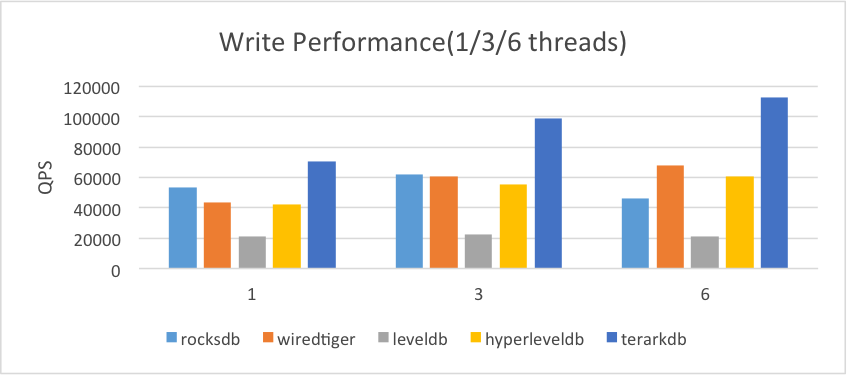
在SSD上的测试结果,更真实的反应了磁盘I/O对性能的影响:
TerarkDB 采用索引和数据分离的方式进行写操作,能够将数据的写入方式在一定程度上转换成顺序写
2.2.3.数据远大于内存
(1)操作系统内存限制为3G
(2)为其他数据库设置256M的专用缓存
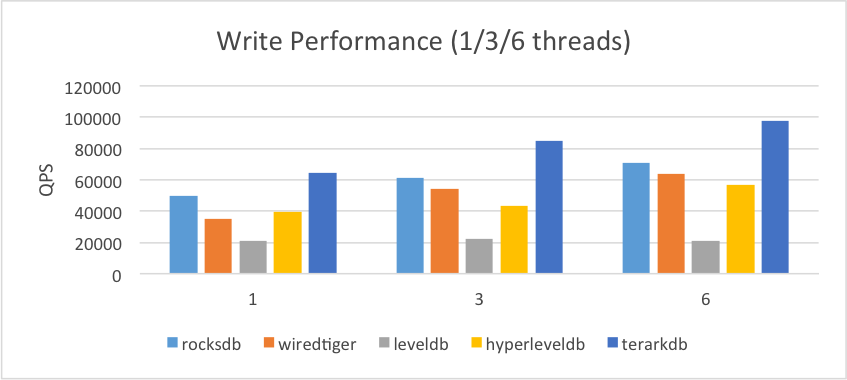
2.3.Read-Write Mixed
(1)TerarkDB 主要应用于少量写大量读的场景
(2)测试一共使用8个线程,其中每个线程内部随机读写,95% / 99%的时间在进行读操作
(3)写操作全部启用压缩,块压缩的大小是 4KB
(4) 首先让其他数据库进行一轮随机读(warm up), 填充专用缓存
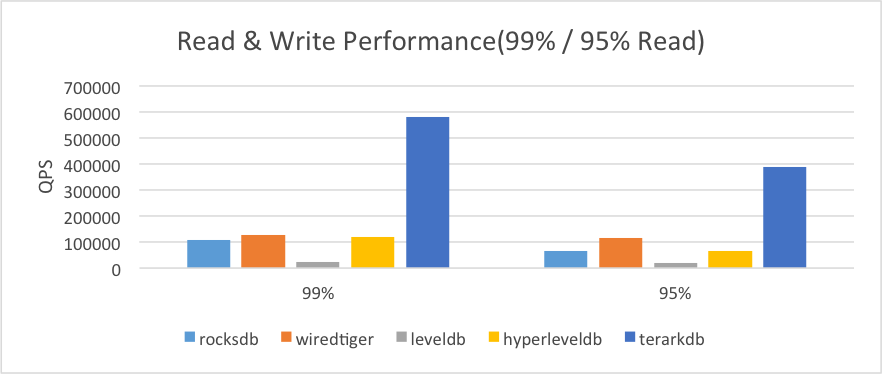
2.3.1. 数据量小于内存
(1)存储介质使用内存文件系统(即数据先预读到内存文件系统中,以加快测试速度)
(2)操作系统内存不做限制
(3)除了 TerarkDB ,其他数据库的专用缓存设置为3GB
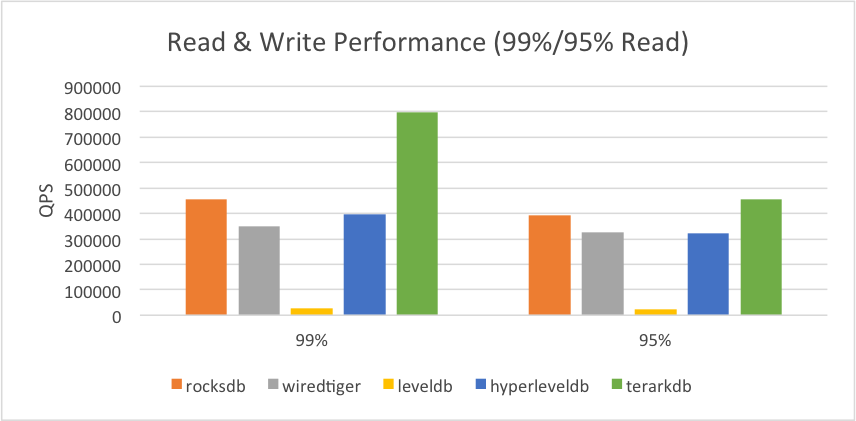
2.3.2. 数据略大于内存
(1)存储介质改为 SSD
(2) 操作系统内存限制为8GB
(3) 其他数据库的专用缓存设置为1GB
(4)分别测试 99% Read 和 95% Read
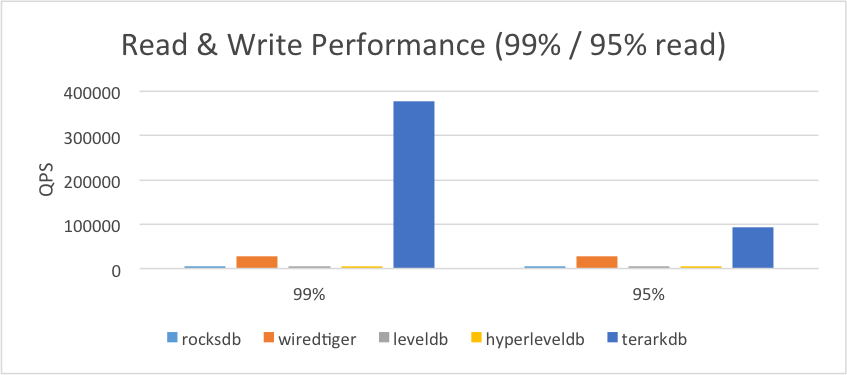
2.3.3.数据远大于内存
(1)操作系统内存限制为3G
(2)为其他数据库设置256M的专用缓存
(3)所有数据库进行了预热(TerarkDB开启mmap populate,
其他数据库进行一轮预读)
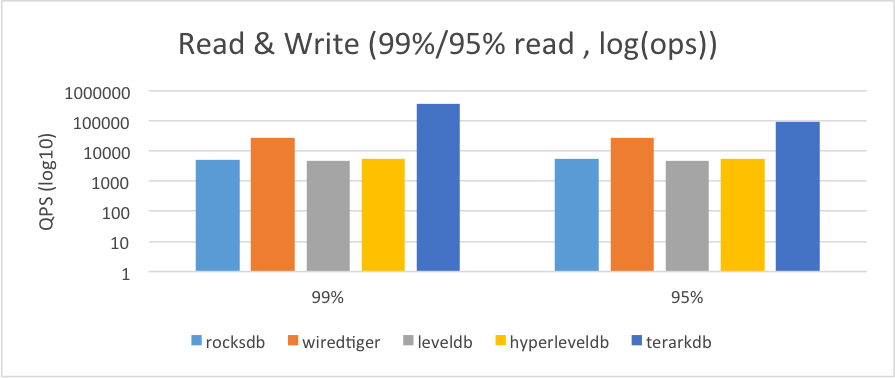
同样,由于数量级相差较大,我们通过对数坐标看一下数据:
2.4 Read Latency Test
该测试中数据集依然是9G的电影点评数据,仅测试的 Read Query 延迟,测试中无 Write 操作。
因为 TerarkDB 的压缩率很高,系统内存3G就可以装下全部数据(实际上压缩后的数据只有2.1G,但测试程序本身要占大约750M内存),所以以下3组对比中,TerarkDB都是在3G内存的条件下测试的。对于rocksdb和wiredtiger,我们分别在8G,4G和3G内存的条件下进行了测试。所有测试中,我们均使用了8个线程。
2.4.1. 数据略大于内存
(1)8G物理内存(TerarkDB是3G)
(2)其他数据库有512M专用缓存


(1)横坐标表示延迟,数字的单位是微秒,坐标比例是近似对数的仔细观察横坐标的数字可以发现 TerarkDB
的延迟要低得多
(2)纵坐标表示区间内累计Query数的所占总Query数的百分比
(3)Point(X, Y%) 表示 延迟低于 X微秒的Query数 占
总Query数 的 Y%
(4)数据结果,越快到达100%,说明 Query 延迟表现越好(延迟越低)
(5)在当前情况下,内存对所有数据库都够用,所以曲线较为平滑
(6)TerarkDB的Latency均值,中值,标准差,99分位值都有明显优势,Latency很稳定。
2.4.2. 数据远大于内存
(1)3G物理内存
(2)其他数据库有256M的专有缓存
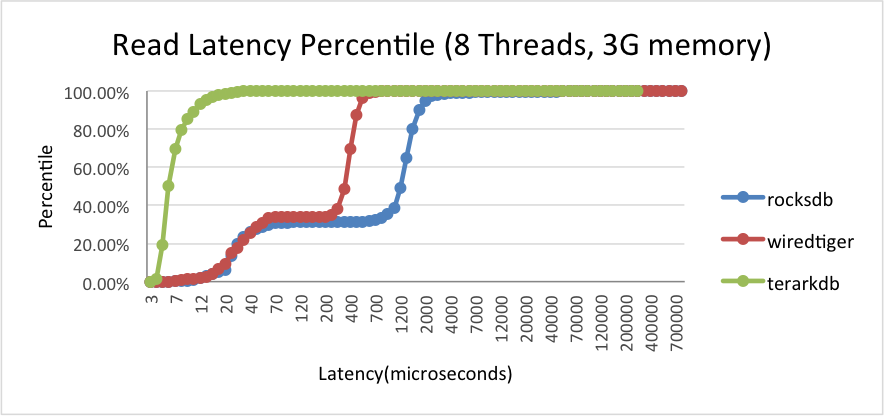

其他数据库有两段斜向上的曲线,分别表示读取的数据命中内存以及没有命中内存两种情况下的延迟,中间那条直线基本上是缓存是否命中的分界 TerarkDB的延迟要低得多,TerarkDB的Latency均值,中值,标准差,99分位值都有明显优势,Latency很稳定 在这种情况下,虽然总内存只有3G,但是我们的压缩率比较高,压缩后的数据完全可以装入内存,所以不会出现Cache未命中的情况
2.4.3 我们还测试了 rocksdb 和 wiredtiger 在4G内存条件下的指标:
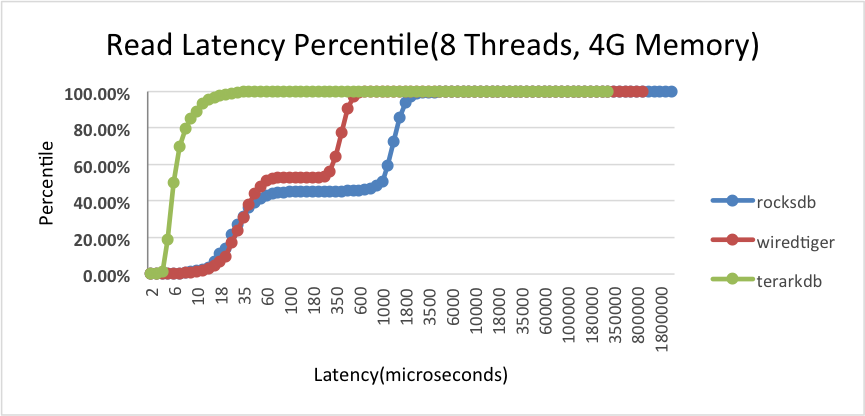

我们可以看到,在 4G 内存的情况下,RocksDB 和 WiredTiger 出现缓存命中的操作比率升高了(中间一段水平直线)
技术解析
TerarkDB使用了非常先进并且复杂的技术,同时也申请了4个专利。其核心技术与其他数据库产品的B+树、LSM树、以及块压缩技术有着本质的区别。带来的好处就是压缩率与性能的同时大幅提高,并非简单的时间空间互换。本文简要介绍几个技术点,更多的技术细节请大家到
terark.com 上查看文档。
并非“空间换时间”或“时间换空间”
现有技术
现有的主流数据库也在使用压缩技术,只不过它们主要是对时间与空间的折衷:压缩的方式都是使用通用压缩技术按块/页(block/page)压缩(块尺寸通常是
4K~32K,以压缩率著称的 TokuDB 块尺寸是 2M~4M)。
当启用压缩的时候,随之而来的是访问速度下降,这是因为:
(1)写入时,很多条记录被打包在一起压缩成一个个的块,增大块尺寸,压缩算法可以获得更大的上下文,从而提高压缩率;相反地,减小块尺寸,会降低压缩率。
(2)读取时,即便是读取很短的数据,也需要先把整个块解压,再去读取解压后的数据。这样,块尺寸越大,同一个块内包含的记录数目越多,为读取一条数据,所做的不必要的解压就也就越多,性能也就越差。相反地,块尺寸越小,性能也就越好。
一旦启用压缩,为了缓解以上问题,传统数据库一般都需要比较大的专用缓存,用来缓存解压后的数据,这样可以大幅提高热数据的访问性能,但又引起了双缓存的空间占用问题,一是操作系统缓存中的压缩数据,二是专用缓存中解压后的数据。还有一个同样很严重的问题:专用缓存终归是缓存,当缓存未命中时,仍需要解压整个块,这就是慢Query问题的一个来源;慢Query
的另一个来源是操作系统缓存未命中时……
传统数据库的 Btree 索引本身也会占据较大的空间,因为 Btree 通常使用的前缀压缩的压缩率很低。
这些都导致现有传统数据库在访问速度和空间占用上是一个此消彼长,无法彻底解决的问题,只能进行这样或那样的折衷。
Terark 的技术 与现有数据库有本质上的区别
对于数据的压缩(可以认为是 key-value 中对 value 的压缩),TerarkDB 主要使用自己研发的专门针对数据库的全局压缩技术,压缩率更高,并且没有块压缩的概念,也没有双缓存的问题。这种压缩技术可以按
RowID/RecordID 直接读取单条数据,如果把这种读取单条数据看作是一种解压,那么,按 RowID
顺序解压时,解压速度一般在 500MB每秒(单线程),最高达到约 7GB/s;按 RowID 随机解压时,解压速度一般在
300MB每秒(单线程),最高达到约3GB/s。
对于索引的压缩,Terark 主要使用 Succinct 技术,压缩率高于现有技术,并且压缩的同时,不用解压就可以高效地执行搜索,除此之外,索引可以支持正则表达式搜索(不用逐条遍历匹配正则表达式)。这种基于
Succinct 技术的索引,还额外支持 反向搜索:正向是从 Key 获取 RowID,反向搜索就是从
RowID 获取 Key,这样,Key 就不需要再单独存储一份(传统Btree索引无这个功能)。这就为
TerarkDB 在同一个 Table 上支持多个索引提供了一个技术支点。
Succinct 技术诞生已有很长时间,但是一直因为性能问题未得到广泛应用,Terark Succinct
技术在 CPU 指令级别专门做了优化,大幅提升了 Succinct 的性能。
正是这些新技术的使用,TerarkDB 的压缩率和访问速度同时大幅提升,并且功能非常丰富。
TerarkDB数据库架构
TerarkDB 数据库包含多个 segment,按照 segment 的状态可分为 writing
segment,writable frozen segment,以及 readonly segment。数据会首先写入
writing segment,这个 segment 中的数据可以直接更新及检索。当写入的数据达到一定的尺寸时,writing
segment 会成为 writable frozen segment ,同时开始被后台线程进行压缩。当后台压缩结束时,就会生成
readonly segment,并删除 writable frozen segment。除此之外,数据的物理删除、segment
合并等工作也都在后台线程中执行。最终,大部分数据都会处于 readonly segment 中,从而拥有极高的压缩率和访问性能。
自动机技术和 Succinct 技术
与 Terark 同时在工程化 Succinct 技术的还有著名的伯克利 AmpLab 实验室,Spark
就是在这个实验室诞生的。Terark 在算法、数据结构和工程技术上都有着自身的优势。
自动机技术在 TerarkDB 中有大量的应用,自动机就是一张状态转移图,这张图用来表达数据,沿着图中的边,按照某个确定的规则访问节点,就可以抽取出所需要的数据。用传统技术来存储这个图,内存消耗很大,Terark
采用 Succinct 技术来压缩这个状态转移图。Succinct 技术的本质就是使用 bitmap 来表示数据结构,内存用量大大降低的同时保持快速的访问性能。另一方面,由于是基于自动机,也就可以原生支持正则表达式检索。
结语
欢迎大家下载使用 Terark 产品。未来 Terark 计划把核心引擎移植到更多分布式系统以适用更多场景,比如
Elastic Search,Spark,手机和嵌入式设备等。Terark 现阶段的计划是,寻找到更多的研发和商务合作,把产品尽快推向市场。我们目前也在招人,感兴趣的朋友可以直接联系我们。也可以访问
官方网站 来获取更多信息。 | 





