| 最近利用闲暇时间,又重新研读了一下Storm。认真对比了一下Hadoop,前者更擅长的是,实时流式数据处理,后者更擅长的是基于HDFS,通过MapReduce方式的离线数据分析计算。对于Hadoop,本身不擅长实时的数据分析处理。两者的共同点都是分布式的架构,而且,都类似有主/从关系的概念。本文中我就不具体阐述Storm集群和Zookeeper集群如何部署的问题,我想通过一个实际的案例切入,分析一下如何利用Storm,完成实时分析处理数据的。
Storm本身是Apache托管的开源的分布式实时计算系统,它的前身是Twitter Storm。在Storm问世以前,处理海量的实时数据信息,大部分是类似于使用消息队列,加上工作进程/线程的方式。这使得构建这类的应用程序,变得异常的复杂。很多的业务逻辑中,你不得不考虑消息的发送和接收,线程之间的并发控制等等问题。而其中的业务逻辑可能只是占据整个应用的一小部分,而且很难做到业务逻辑的解耦。但是Storm的出现改变了这种局面,它首先抽象出数据流Stream的抽象概念,一个Stream指的是tuples组成的无边界的序列。后面又继续提出Spouts、Bolts的概念。Spouts在Storm里面是数据源,专门负责生成流。而Bolts则是以流作为输入,并重新生成流作为输出,并且Bolts还会继续指定它输入的流应该如何划分。最后Storm是通过拓扑(Topology)这种抽象概念,组织起若干个Spouts、Bolts构成的分布式数据处理网络。Storm设计的时候,就有意的把Spouts、Bolts组成的拓扑(Topology)网络通过Thrift服务方式进行封装,这个做法,使得Storm的Spouts、Bolts组件可以通过目前主流的任意语言实现,使得整个框架的兼容性和扩展性更加的优秀。
在Storm里面拓扑(Topology)的概念,非常类似Hadoop里面MapReduce的Job的概念。不同的是Storm的拓扑(Topology)只要你启动了,它就会一直运行下去,除非你kill掉;而MapReduce的Job最终它是会结束的。基于这样的模式,使得Storm非常适合处理实时性的数据分析,持续计算,DRPC(分布式RPC)等。
好了,我就结合实际的案例,设计分析一下,如何利用Storm改善应用的处理性能。
移动公司的垃圾短信监控平台,实时地上传每个省的疑似垃圾短信用户的垃圾短信内容文件,每个省则根据文件中垃圾短信的内容,解析过滤出,包含指定敏感关键字的垃圾短信进行入库。被入库的垃圾短信用户被列为敏感用户,是重点监控对象,毕竟乱发这些垃圾短信是非常不对的。垃圾短信监控平台生成的文件速度非常惊人,原来的传统做法是,根据每个省的每一个地市,对应一个独立应用,串行化地解析、过滤敏感关键字,来进行入库处理。但是,从现状来看,程序处理的性能并不高效,常常造成文件积压,没有及时处理入库。
现在,我们就通过Storm,来重新梳理、组织一下上述的应用场景。
首先,我先说明一下,该案例中,Storm集群和Zookeeper集群的部署情况,如下图所示:
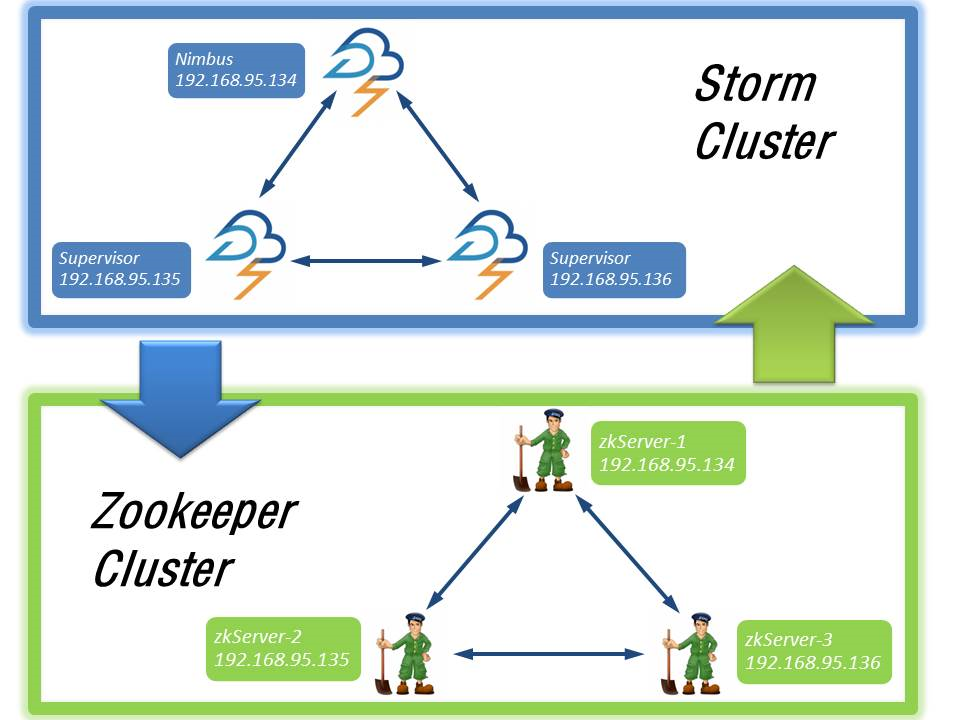
mbus对应的主机是192.168.95.134是Storm主节点,其余两台从节点Supervisor对应的主机分别是192.168.95.135(主机名:slave1)、192.168.95.136(主机名:slave2)。同样的,Zookeeper集群也是部署在上述节点上。Storm集群和Zookeeper集群会互相通信,因为Storm就是基于Zookeeper的。然后先启动每个节点的Zookeeper服务,其次分别启动Storm的Nimbus、Supervisor服务。具体可以到Storm安装的bin目录下面启动服务,启动命令分别为storm
nimbus > /dev/null 2 > &1 &和storm supervisor
> /dev/null 2 > &1 &。然后用jps观察启动的效果。没有问题的话,在Nimbus服务对应的主机上启动Storm
UI监控对应的服务,在Storm安装目录的bin目录输入命令:storm ui >/dev/null
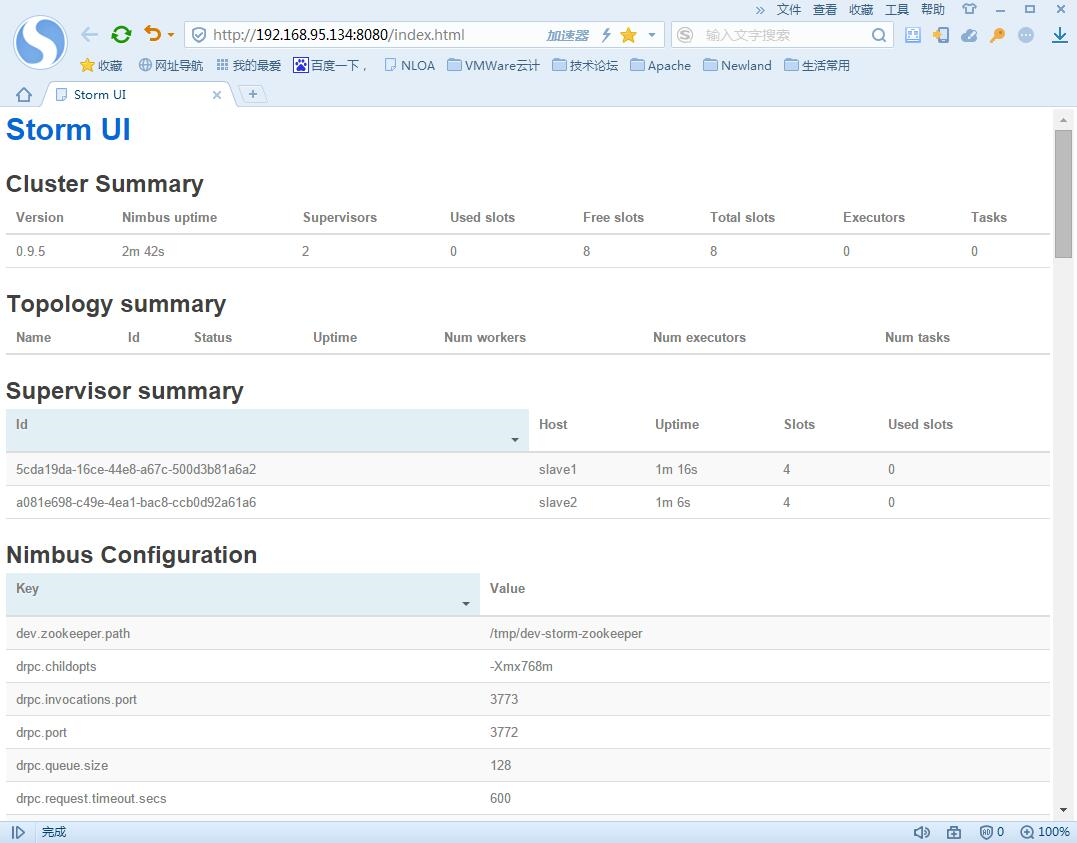
2>&1 &。然后打开浏览器输入:http://{Nimbus服务对应的主机ip}:8080,这里就是输入:http://192.168.95.134:8080/。观察Storm集群的部署情况,如下图所示:
可以发现,我们的Storm的版本是0.9.5,它的从节点(Supervisor)有2个,分别是slave1、slave2。一共的woker的数量是8个(Total
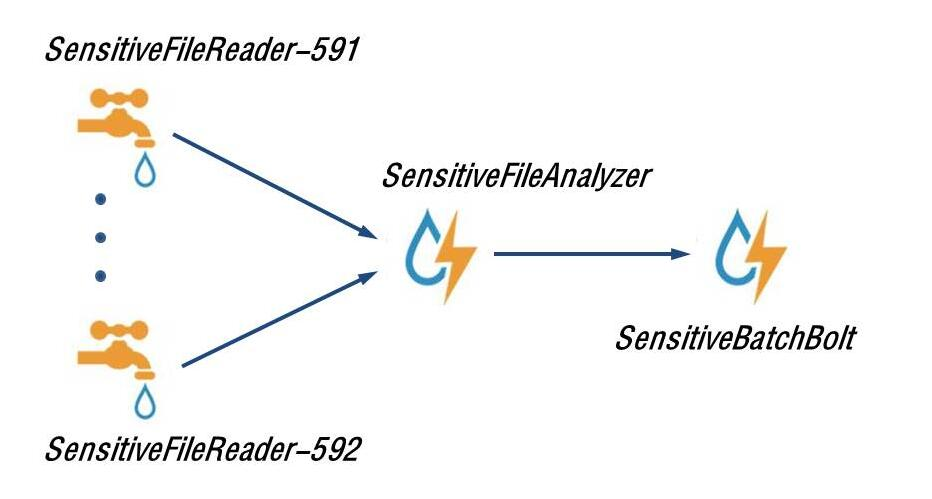
slots)。Storm集群我们已经部署完毕,也启动成功了。现在我们就利用Storm的方式,来重新改写一下这种敏感信息实时监控过滤的应用。首先看下,Storm方式的拓扑结构图:
其中的SensitiveFileReader-591、SensitiveFileReader-592(用户短信采集器,分地市)代表的是Storm中的Spouts组件,表示一个数据的源头,这里是表示从服务器的指定目录下,读取疑似垃圾短信用户的垃圾短信内容文件。当然Spouts的组件你可以根据实际的需求,扩展出许多Spouts。
然后读取出文件中每一行的内容之后,就是分析文件的内容组件了,这里是指:SensitiveFileAnalyzer(监控短信内容拆解分析),它负责分析出文件的格式内容。
为了简单演示起见,我这里定义文件的格式为如下内容(随便写一个例子):home_city=591&user_id=5911000&msisdn=10000&sms_content=abc-slave1。每个列之间用&进行连接。其中home_city=591表示疑似垃圾短信的用户归属地市编码,591表示福州、592表示厦门;user_id=5911000表示疑似垃圾短信的用户标识;msisdn=10000表示疑似垃圾短信的用户手机号码;sms_content=abc-slave1代表的就是垃圾短信的内容了。SensitiveFileAnalyzer代表的就是Storm中的Bolt组件,用来处理Spouts“流”出的数据。
最后,就是我们根据解析好的数据,匹配业务规定的敏感关键字,进行过滤入库了。这里我们是把过滤好的数据存入MySQL数据库中。负责这项任务的组件是:SensitiveBatchBolt(敏感信息采集处理),当然它也是Storm中的Bolt组件。好了,以上就是完整的Storm拓扑(Topology)结构了。
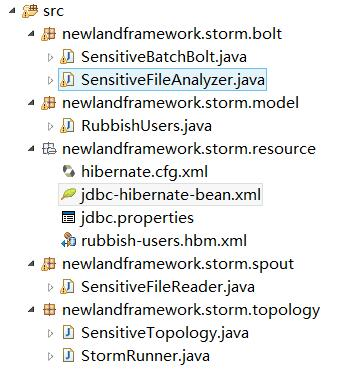
现在,我们对于整个敏感信息采集过滤监控的拓扑结构,有了一个整体的了解之后,我们再来看下如何具体编码实现!先来看下整个工程的代码层次结构,它如下图所示:
首先来看下,我们定义的敏感用户的数据结构RubbishUsers,假设,我们要过滤的敏感用户的短信内容中,要包含“racketeer”、“Bad”等敏感关键字。具体代码如下:
最近利用闲暇时间,又重新研读了一下Storm。认真对比了一下Hadoop,前者更擅长的是,实时流式数据处理,后者更擅长的是基于HDFS,通过MapReduce方式的离线数据分析计算。对于Hadoop,本身不擅长实时的数据分析处理。两者的共同点都是分布式的架构,而且,都类似有主/从关系的概念。本文中我就不具体阐述Storm集群和Zookeeper集群如何部署的问题,我想通过一个实际的案例切入,分析一下如何利用Storm,完成实时分析处理数据的。
Storm本身是Apache托管的开源的分布式实时计算系统,它的前身是Twitter Storm。在Storm问世以前,处理海量的实时数据信息,大部分是类似于使用消息队列,加上工作进程/线程的方式。这使得构建这类的应用程序,变得异常的复杂。很多的业务逻辑中,你不得不考虑消息的发送和接收,线程之间的并发控制等等问题。而其中的业务逻辑可能只是占据整个应用的一小部分,而且很难做到业务逻辑的解耦。但是Storm的出现改变了这种局面,它首先抽象出数据流Stream的抽象概念,一个Stream指的是tuples组成的无边界的序列。后面又继续提出Spouts、Bolts的概念。Spouts在Storm里面是数据源,专门负责生成流。而Bolts则是以流作为输入,并重新生成流作为输出,并且Bolts还会继续指定它输入的流应该如何划分。最后Storm是通过拓扑(Topology)这种抽象概念,组织起若干个Spouts、Bolts构成的分布式数据处理网络。Storm设计的时候,就有意的把Spouts、Bolts组成的拓扑(Topology)网络通过Thrift服务方式进行封装,这个做法,使得Storm的Spouts、Bolts组件可以通过目前主流的任意语言实现,使得整个框架的兼容性和扩展性更加的优秀。
在Storm里面拓扑(Topology)的概念,非常类似Hadoop里面MapReduce的Job的概念。不同的是Storm的拓扑(Topology)只要你启动了,它就会一直运行下去,除非你kill掉;而MapReduce的Job最终它是会结束的。基于这样的模式,使得Storm非常适合处理实时性的数据分析,持续计算,DRPC(分布式RPC)等。
好了,我就结合实际的案例,设计分析一下,如何利用Storm改善应用的处理性能。
移动公司的垃圾短信监控平台,实时地上传每个省的疑似垃圾短信用户的垃圾短信内容文件,每个省则根据文件中垃圾短信的内容,解析过滤出,包含指定敏感关键字的垃圾短信进行入库。被入库的垃圾短信用户被列为敏感用户,是重点监控对象,毕竟乱发这些垃圾短信是非常不对的。垃圾短信监控平台生成的文件速度非常惊人,原来的传统做法是,根据每个省的每一个地市,对应一个独立应用,串行化地解析、过滤敏感关键字,来进行入库处理。但是,从现状来看,程序处理的性能并不高效,常常造成文件积压,没有及时处理入库。
现在,我们就通过Storm,来重新梳理、组织一下上述的应用场景。
首先,我先说明一下,该案例中,Storm集群和Zookeeper集群的部署情况,如下图所示:
Nimbus对应的主机是192.168.95.134是Storm主节点,其余两台从节点Supervisor对应的主机分别是192.168.95.135(主机名:slave1)、192.168.95.136(主机名:slave2)。同样的,Zookeeper集群也是部署在上述节点上。Storm集群和Zookeeper集群会互相通信,因为Storm就是基于Zookeeper的。然后先启动每个节点的Zookeeper服务,其次分别启动Storm的Nimbus、Supervisor服务。具体可以到Storm安装的bin目录下面启动服务,启动命令分别为storm
nimbus > /dev/null 2 > &1 &和storm supervisor
> /dev/null 2 > &1 &。然后用jps观察启动的效果。没有问题的话,在Nimbus服务对应的主机上启动Storm
UI监控对应的服务,在Storm安装目录的bin目录输入命令:storm ui >/dev/null
2>&1 &。然后打开浏览器输入:http://{Nimbus服务对应的主机ip}:8080,这里就是输入:http://192.168.95.134:8080/。观察Storm集群的部署情况,如下图所示:
可以发现,我们的Storm的版本是0.9.5,它的从节点(Supervisor)有2个,分别是slave1、slave2。一共的woker的数量是8个(Total
slots)。Storm集群我们已经部署完毕,也启动成功了。现在我们就利用Storm的方式,来重新改写一下这种敏感信息实时监控过滤的应用。首先看下,Storm方式的拓扑结构图:
其中的SensitiveFileReader-591、SensitiveFileReader-592(用户短信采集器,分地市)代表的是Storm中的Spouts组件,表示一个数据的源头,这里是表示从服务器的指定目录下,读取疑似垃圾短信用户的垃圾短信内容文件。当然Spouts的组件你可以根据实际的需求,扩展出许多Spouts。
然后读取出文件中每一行的内容之后,就是分析文件的内容组件了,这里是指:SensitiveFileAnalyzer(监控短信内容拆解分析),它负责分析出文件的格式内容。
为了简单演示起见,我这里定义文件的格式为如下内容(随便写一个例子):home_city=591&user_id=5911000&msisdn=10000&sms_content=abc-slave1。每个列之间用&进行连接。其中home_city=591表示疑似垃圾短信的用户归属地市编码,591表示福州、592表示厦门;user_id=5911000表示疑似垃圾短信的用户标识;msisdn=10000表示疑似垃圾短信的用户手机号码;sms_content=abc-slave1代表的就是垃圾短信的内容了。SensitiveFileAnalyzer代表的就是Storm中的Bolt组件,用来处理Spouts“流”出的数据。
最后,就是我们根据解析好的数据,匹配业务规定的敏感关键字,进行过滤入库了。这里我们是把过滤好的数据存入MySQL数据库中。负责这项任务的组件是:SensitiveBatchBolt(敏感信息采集处理),当然它也是Storm中的Bolt组件。好了,以上就是完整的Storm拓扑(Topology)结构了。
现在,我们对于整个敏感信息采集过滤监控的拓扑结构,有了一个整体的了解之后,我们再来看下如何具体编码实现!先来看下整个工程的代码层次结构,它如下图所示:
首先来看下,我们定义的敏感用户的数据结构RubbishUsers,假设,我们要过滤的敏感用户的短信内容中,要包含“racketeer”、“Bad”等敏感关键字。具体代码如下:
/**
* @filename:RubbishUsers.java
*
* Newland Co. Ltd. All rights reserved.
*
* @Description:敏感用户实体定义
* @author tangjie
* @version 1.0
*
*/
package newlandframework.storm.model;
import org.apache.commons.lang.builder.ToStringBuilder;
import org.apache.commons.lang.builder.ToStringStyle;
import java.io.Serializable;
public class RubbishUsers implements Serializable
{
// 用户归属地市编码
private Integer homeCity;
// 用户编码
private Integer userId;
// 用户号码
private Integer msisdn;
// 短信内容
String smsContent;
public final static String HOMECITY_COLUMNNAME
= "home_city";
public final static String USERID_COLUMNNAME =
"user_id";
public final static String MSISDN_COLUMNNAME =
"msisdn";
public final static String SMSCONTENT_COLUMNNAME
= "sms_content";
public final static Integer[] SENSITIVE_HOMECITYS
= new Integer[] {
591/* 福州 */, 592 /* 厦门 */};
// 敏感关键字,后续可以考虑单独开辟放入缓存或数据库中,这里仅仅为了Demo演示
public final static String SENSITIVE_KEYWORD1
= "Bad";
public final static String SENSITIVE_KEYWORD2
= "racketeer";
public final static String[] SENSITIVE_KEYWORDS
= new String[] {
SENSITIVE_KEYWORD1, SENSITIVE_KEYWORD2 };
public Integer getHomeCity() {
return homeCity;
}
public void setHomeCity(Integer homeCity) {
this.homeCity = homeCity;
}
public Integer getUserId() {
return userId;
}
public void setUserId(Integer userId) {
this.userId = userId;
}
public Integer getMsisdn() {
return msisdn;
}
public void setMsisdn(Integer msisdn) {
this.msisdn = msisdn;
}
public String getSmsContent() {
return smsContent;
}
public void setSmsContent(String smsContent)
{
this.smsContent = smsContent;
}
public String toString() {
return new ToStringBuilder(this, ToStringStyle.SHORT_PREFIX_STYLE)
.append("homeCity", homeCity).append("userId",
userId)
.append("msisdn", msisdn).append("smsContent",
smsContent)
.toString();
}
}
|
现在,我们看下敏感信息数据源组件SensitiveFileReader的具体实现,它负责从服务器的指定目录下面,读取疑似垃圾短信用户的垃圾短信内容文件,然后把每一行的数据,发送给下一个处理的Bolt(SensitiveFileAnalyzer),每个文件全部发送结束之后,在当前目录中,把原文件重命名成后缀bak的文件(当然,你可以重新建立一个备份目录,专门用来存储这种处理结束的文件),SensitiveFileReader的具体实现如下:
/**
* @filename:SensitiveFileReader.java
*
* Newland Co. Ltd. All rights reserved.
*
* @Description:用户短信采集器
* @author tangjie
* @version 1.0
*
*/
package newlandframework.storm.spout;
import java.io.File;
import java.io.IOException;
import java.util.Collection;
import java.util.List;
import java.util.Map;
import org.apache.commons.io.FileUtils;
import org.apache.commons.io.filefilter.FileFilterUtils;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
public class SensitiveFileReader extends BaseRichSpout
{
// 福州地市用户敏感短信文件上传路径
public static final String InputFuZhouPath = "/home/tj/data/591";
// 厦门地市用户敏感短信文件上传路径
public static final String InputXiaMenPath = "/home/tj/data/592";
// 处理成功改成bak后缀
public static final String FinishFileSuffix =
".bak";
private String sensitiveFilePath = "";
private SpoutOutputCollector collector;
public SensitiveFileReader(String sensitiveFilePath)
{
this.sensitiveFilePath = sensitiveFilePath;
}
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
this.collector = collector;
}
@Override
public void nextTuple() {
Collection<File> files = FileUtils.listFiles(
new File(sensitiveFilePath),
FileFilterUtils.notFileFilter(FileFilterUtils
.suffixFileFilter(FinishFileSuffix)), null);
for (File f : files) {
try {
List<String> lines = FileUtils.readLines(f,
"GBK");
for (String line : lines) {
System.out.println("[SensitiveTrace]:"
+ line);
collector.emit(new Values(line));
}
FileUtils.moveFile(f,
new File(f.getPath() + System.currentTimeMillis()
+ FinishFileSuffix));
} catch (IOException e) {
e.printStackTrace();
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer
declarer) {
declarer.declare(new Fields("sensitive"));
}
}
|
监控短信内容拆解分析器SensitiveFileAnalyzer,这个Bolt组件,接收到数据源SensitiveFileReader的数据之后,就按照上面定义的格式,对文件中每一行的内容进行解析,然后把解析完毕的内容,继续发送给下一个Bolt组件:SensitiveBatchBolt(敏感信息采集处理)。现在,我们来看下SensitiveFileAnalyzer这个Bolt组件的实现:
/**
* @filename:SensitiveFileAnalyzer.java
*
* Newland Co. Ltd. All rights reserved.
*
* @Description:监控短信内容拆解分析
* @author tangjie
* @version 1.0
*
*/
package newlandframework.storm.bolt;
import java.util.Map;
import newlandframework.storm.model.RubbishUsers;
import org.apache.storm.guava.base.Splitter;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
public class SensitiveFileAnalyzer extends BaseBasicBolt
{
@Override
public void execute(Tuple input, BasicOutputCollector
collector) {
String line = input.getString(0);
Map<String, String> join = Splitter.on("&").withKeyValueSeparator("=").split(line);
collector.emit(new Values((String) join
.get(RubbishUsers.HOMECITY_COLUMNNAME), (String)
join
.get(RubbishUsers.USERID_COLUMNNAME), (String)
join
.get(RubbishUsers.MSISDN_COLUMNNAME), (String)
join
.get(RubbishUsers.SMSCONTENT_COLUMNNAME)));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer
declarer) {
declarer.declare(new Fields(RubbishUsers.HOMECITY_COLUMNNAME,
RubbishUsers.USERID_COLUMNNAME, RubbishUsers.MSISDN_COLUMNNAME,
RubbishUsers.SMSCONTENT_COLUMNNAME));
}
}
|
最后一个Bolt组件SensitiveBatchBolt(敏感信息采集处理)根据上游Bolt组件SensitiveFileAnalyzer发送过来的数据,然后跟业务规定的敏感关键字进行匹配,如果匹配成功,说明这个用户,就是我们要重点监控的用户,我们把他,通过hibernate采集到MySQL数据库,统一管理。最后要说明的是,SensitiveBatchBolt组件还实现了一个监控的功能,就是定期打印出,我们已经采集到的敏感信息用户数据。现在给出SensitiveBatchBolt的实现:
/**
* @filename:SensitiveBatchBolt.java
*
* Newland Co. Ltd. All rights reserved.
*
* @Description:敏感信息采集处理
* @author tangjie
* @version 1.0
*
*/
package newlandframework.storm.bolt;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.IBasicBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
import org.apache.commons.collections.Predicate;
import org.apache.commons.collections.iterators.FilterIterator;
import org.apache.commons.lang.StringUtils;
import org.hibernate.Criteria;
import org.hibernate.HibernateException;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.criterion.MatchMode;
import org.hibernate.criterion.Restrictions;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import newlandframework.storm.model.RubbishUsers;
public class SensitiveBatchBolt implements IBasicBolt
{
// Hibernate配置加载
private final static String HIBERNATE_APPLICATIONCONTEXT
= "newlandframework/storm/resource/jdbc-hibernate-bean.xml";
// Spring、Hibernate上下文不要序列化
private static transient ApplicationContext hibernate
= new ClassPathXmlApplicationContext(
HIBERNATE_APPLICATIONCONTEXT);
private static transient SessionFactory sessionFactory
= (SessionFactory) hibernate
.getBean("sessionFactory");
public SensitiveBatchBolt() throws SQLException
{
super();
}
private static List list = new ArrayList(Arrays.asList(RubbishUsers.SENSITIVE_KEYWORDS));
// 敏感信息数据源,可以考虑放入缓存或者数据库中加载判断
private class SensitivePredicate implements Predicate
{
private String sensitiveWord = null;
SensitivePredicate(String sensitiveWord) {
this.sensitiveWord = sensitiveWord;
}
public boolean evaluate(Object object) {
return this.sensitiveWord.contains((String) object);
}
}
// Monitor线程定期打印监控采集处理情况
class SensitiveMonitorThread implements Runnable
{
private int sensitiveMonitorTimeInterval = 0;
private Session session = null;
SensitiveMonitorThread(int sensitiveMonitorTimeInterval)
{
this.sensitiveMonitorTimeInterval = sensitiveMonitorTimeInterval;
session = sessionFactory.openSession();
}
public void run() {
while (true) {
try {
Criteria criteria1 = session.createCriteria(RubbishUsers.class);
criteria1.add(Restrictions.and(Restrictions.or(Restrictions
.like("smsContent", StringUtils
.center(RubbishUsers.SENSITIVE_KEYWORD1,
RubbishUsers.SENSITIVE_KEYWORD1
.length() + 2, "%"),
MatchMode.ANYWHERE), Restrictions.like(
"smsContent", StringUtils
.center(RubbishUsers.SENSITIVE_KEYWORD2,
RubbishUsers.SENSITIVE_KEYWORD2
.length() + 2, "%"),
MatchMode.ANYWHERE)), Restrictions.in("homeCity",
RubbishUsers.SENSITIVE_HOMECITYS)));
List<RubbishUsers> rubbishList = (List<RubbishUsers>)
criteria1.list();
System.out.println(StringUtils.center("[SensitiveTrace
敏感用户清单如下]", 40, "-"));
if (rubbishList != null) {
System.out.println("[SensitiveTrace 敏感用户数量]:"
+ rubbishList.size());
for (RubbishUsers rubbish : rubbishList) {
System.out.println(rubbish + rubbish.getSmsContent());
}
} else {
System.out.println("[SensitiveTrace 敏感用户数量]:0");
}
} catch (HibernateException e) {
e.printStackTrace();
}
try {
Thread.sleep(sensitiveMonitorTimeInterval * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
// 分布式环境下面的要同步控制
private synchronized void save(Tuple input) {
Session session = sessionFactory.openSession();
try {
RubbishUsers users = new RubbishUsers();
users.setUserId(Integer.parseInt(input
.getStringByField(RubbishUsers.USERID_COLUMNNAME)));
users.setHomeCity(Integer.parseInt(input
.getStringByField(RubbishUsers.HOMECITY_COLUMNNAME)));
users.setMsisdn(Integer.parseInt(input
.getStringByField(RubbishUsers.MSISDN_COLUMNNAME)));
users.setSmsContent(input
.getStringByField(RubbishUsers.SMSCONTENT_COLUMNNAME));
Predicate isSensitiveFileAnalysis = new SensitivePredicate(
(String) input.getStringByField(RubbishUsers.SMSCONTENT_COLUMNNAME));
FilterIterator iterator = new FilterIterator(list.iterator(),isSensitiveFileAnalysis);
if (iterator.hasNext()) {
session.beginTransaction();
// 入库MySQL
session.save(users);
session.getTransaction().commit();
}
} catch (HibernateException e) {
e.printStackTrace();
session.getTransaction().rollback();
} finally {
session.close();
}
}
// 很多情况下面storm运行期执行报错,都是由于execute有异常导致的,重点观察execute的函数逻辑
// 最经常报错的情况是报告:ERROR backtype.storm.daemon.executor
- java.lang.RuntimeException:java.lang.NullPointerException
// backtype.storm.utils.DisruptorQueue.consumeBatchToCursor(DisruptorQueue.java
...)
// 类似这样的错误,有点莫名其妙,开始都运行的很正常,后面忽然就报空指针异常了,我开始以为是storm部署的问题,
// 后面jstack跟踪发现,主要还是execute逻辑的问题,所以遇到这类的问题不要手忙脚乱,适当结合jstack跟踪定位
@Override
public void execute(Tuple input, BasicOutputCollector
collector) {
save(input);
}
public Map<String, Object> getComponentConfiguration()
{
return null;
}
@Override
public void prepare(Map stormConf, TopologyContext
context) {
final int sensitiveMonitorTimeInterval = Integer.parseInt(stormConf
.get("RUBBISHMONITOR_INTERVAL").toString());
SensitiveMonitorThread montor = new SensitiveMonitorThread(
sensitiveMonitorTimeInterval);
new Thread(montor).start();
}
@Override
public void cleanup() {
// TODO Auto-generated method stub
}
@Override
public void declareOutputFields(OutputFieldsDeclarer
arg0) {
// TODO Auto-generated method stub
}
}
|
由于是通过hibernate入库到MySQL,所以给出hibernate配置,首先是:hibernate.cfg.xml
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<property name="hibernate.bytecode.use_reflection_optimizer">false</property>
<property name="hibernate.dialect">org.hibernate.dialect.MySQLDialect</property>
<property name="show_sql">true</property>
<mapping resource="newlandframework/storm/resource/rubbish-users.hbm.xml"/>
</session-factory>
</hibernate-configuration>
|
对应的ORM映射配置文件rubbish-users.hbm.xml内容如下:
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class name="newlandframework.storm.model.RubbishUsers" table="rubbish_users" catalog="ccs">
<id name="userId" type="java.lang.Integer">
<column name="user_id"/>
<generator class="assigned"/>
</id>
<property name="homeCity" type="java.lang.Integer">
<column name="home_city" not-null="true"/>
</property>
<property name="msisdn" type="java.lang.Integer">
<column name="msisdn" not-null="true"/>
</property>
<property name="smsContent" type="java.lang.String">
<column name="sms_content" not-null="true"/>
</property>
</class>
</hibernate-mapping>
|
最后,还是通过Spring把hibernate集成起来,数据库连接池用的是:DBCP。对应的Spring配置文件jdbc-hibernate-bean.xml的内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.0.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx-2.5.xsd"
default-autowire="byType" default-lazy-init="false">
<bean id="placeholder"
class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="locations">
<list>
<value>newlandframework/storm/resource/jdbc.properties</value>
</list>
</property>
</bean>
<bean id="dbcpDataSource"
class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="${database.driverClassName}"/>
<property name="url" value="${database.url}"/>
<property name="username" value="${database.username}"/>
<property name="password" value="${database.password}"/>
<property name="maxActive" value="32"/>
<property name="initialSize" value="1"/>
<property name="maxWait" value="60000"/>
<property name="maxIdle" value="32"/>
<property name="minIdle" value="5"/>
<property name="removeAbandoned" value="true"/>
<property name="removeAbandonedTimeout" value="180"/>
<property name="connectionProperties"
value="bigStringTryClob=true;clientEncoding=GBK;
defaultRowPrefetch=50;serverEncoding=ISO-8859-1"/>
<property name="timeBetweenEvictionRunsMillis">
<value>60000</value>
</property>
<property name="minEvictableIdleTimeMillis">
<value>1800000</value>
</property>
</bean>
<!-- hibernate session factory -->
<bean id="sessionFactory"
class="org.springframework.orm.hibernate3.LocalSessionFactoryBean">
<property name="dataSource" ref="dbcpDataSource"/>
<property name="configLocation"
value="newlandframework/storm/resource/hibernate.cfg.xml"/>
<property name="eventListeners">
<map></map>
</property>
<property name="entityCacheStrategies">
<props></props>
</property>
<property name="collectionCacheStrategies">
<props></props>
</property>
<property name="configurationClass">
<value>org.hibernate.cfg.AnnotationConfiguration</value>
</property>
</bean>
<bean id="hibernateTemplete"
class="org.springframework.orm.hibernate3.HibernateTemplate">
<property name="sessionFactory" ref="sessionFactory"/>
</bean>
</beans> |
到此为止,我们已经完成了敏感信息实时监控的所有的Storm组件的开发。现在,我们来完成Storm的拓扑(Topology),由于拓扑(Topology)又分为本地拓扑和分布式拓扑,因此封装了一个工具类StormRunner(拓扑执行器),对应的代码如下:
/**
* @filename:StormRunner.java
*
* Newland Co. Ltd. All rights reserved.
*
* @Description:拓扑执行器
* @author tangjie
* @version 1.0
*
*/
package newlandframework.storm.topology;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.generated.StormTopology;
public final class StormRunner {
private static final int MILLIS_IN_SEC = 1000;
// 本地拓扑 Storm用一个进程里面的N个线程进行模拟
public static void runTopologyLocally(StormTopology
topology,
String topologyName, Config conf, int runtimeInSeconds)
throws InterruptedException {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology(topologyName, conf, topology);
Thread.sleep((long) runtimeInSeconds * MILLIS_IN_SEC);
cluster.killTopology(topologyName);
cluster.shutdown();
}
// 分布式拓扑 真正的Storm集群运行环境
public static void runTopologyRemotely(StormTopology
topology,
String topologyName, Config conf) throws AlreadyAliveException,
InvalidTopologyException {
StormSubmitter.submitTopology(topologyName, conf,
topology);
}
}
|
好了,现在我们把上面所有的Spouts/Bolts拼接成“拓扑”(Topology)结构,我们这里用的是分布式拓扑,来进行部署运行。具体的SensitiveTopology(敏感用户监控Storm拓扑)代码如下:
/**
* @filename:SensitiveTopology.java
*
* Newland Co. Ltd. All rights reserved.
*
* @Description:敏感用户监控Storm拓扑
* @author tangjie
* @version 1.0
*
*/
package newlandframework.storm.topology;
import java.sql.SQLException;
import newlandframework.storm.bolt.SensitiveBatchBolt;
import newlandframework.storm.bolt.SensitiveFileAnalyzer;
import newlandframework.storm.model.RubbishUsers;
import newlandframework.storm.spout.SensitiveFileReader;
import org.apache.commons.lang.StringUtils;
import backtype.storm.Config;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
public class SensitiveTopology {
// Spout/Bolt的ID定义
public static final String SensitiveSpoutFuZhou
= "SensitiveSpout591";
public static final String SensitiveSpoutXiaMen
= "SensitiveSpout592";
public static final String SensitiveBoltAnalysis
= "SensitiveBoltAnalysis";
public static final String SensitiveBoltPersistence
= "SensitiveBolPersistence";
public static void main(String[] args) throws
SQLException {
System.out.println(StringUtils.center("SensitiveTopology",
40, "*"));
TopologyBuilder builder = new TopologyBuilder();
// 构建spout,分别设置并行度为2
builder.setSpout(SensitiveSpoutFuZhou, new SensitiveFileReader(
SensitiveFileReader.InputFuZhouPath), 2);
builder.setSpout(SensitiveSpoutXiaMen, new SensitiveFileReader(
SensitiveFileReader.InputXiaMenPath), 2);
// 构建bolt设置并行度为4
builder.setBolt(SensitiveBoltAnalysis, new SensitiveFileAnalyzer(),
4)
.shuffleGrouping(SensitiveSpoutFuZhou)
.shuffleGrouping(SensitiveSpoutXiaMen);
// 构建bolt设置并行度为4
SensitiveBatchBolt persistenceBolt = new SensitiveBatchBolt();
builder.setBolt(SensitiveBoltPersistence, persistenceBolt,
4)
.fieldsGrouping(
SensitiveBoltAnalysis,
new Fields(RubbishUsers.HOMECITY_COLUMNNAME,
RubbishUsers.USERID_COLUMNNAME,
RubbishUsers.MSISDN_COLUMNNAME));
Config conf = new Config();
conf.setDebug(true);
// 设置worker,集群里面最大就8个slots了,全部使用上
conf.setNumWorkers(8);
// 3秒监控一次敏感信息入库MySQL情况
conf.put("RUBBISHMONITOR_INTERVAL",
3);
// 执行分布式拓扑
try {
StormRunner.runTopologyRemotely(builder.createTopology(),"SensitiveTopology",
conf);
} catch (AlreadyAliveException e) {
e.printStackTrace();
} catch (InvalidTopologyException e) {
e.printStackTrace();
}
}
}
|
到此为止,所有的Storm组件已经开发完毕!现在,我们把上述工程打成jar包,放到Storm集群中运行,
具体可以到Nimbus对应的Storm安装目录下面的bin目录,输入:storm jar + {jar路径}。
比如我这里是输入:storm jar /home/tj/install/SensitiveTopology.jar
newlandframework.storm.topology.SensitiveTopology,然后,把疑似垃圾短信用户的垃圾短信内容文件放到指定的服务器下面的目录(/home/tj/data/591、/home/tj/data/592),最后,打开刚才的Storm
UI,观察任务的启动执行情况,这里如下图所示:
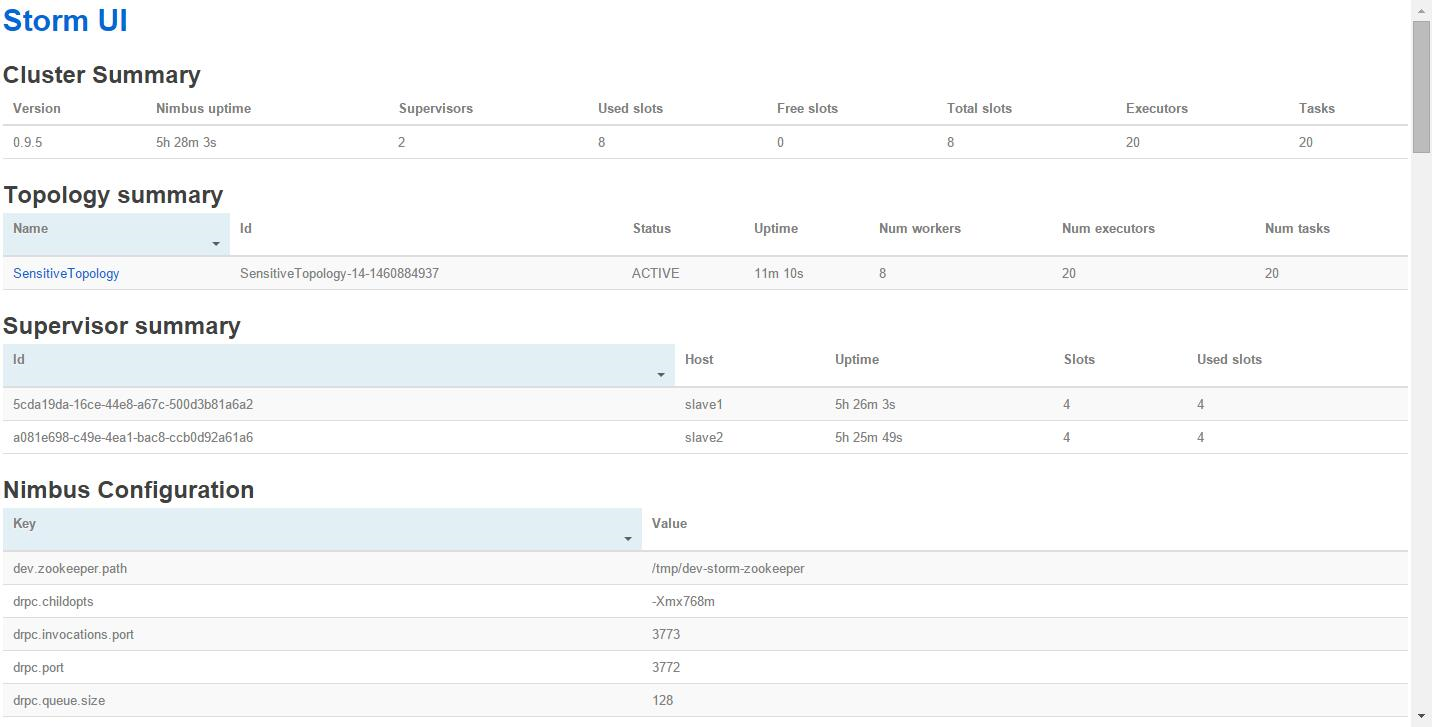
可以看到我们刚才提交的拓扑:SensitiveTopology已经成功提交到Storm集群里面了。这个时候,你可以鼠标点击SensitiveTopology,然后,会打开如下的一个Spouts/Bolts的监控界面,如下图所示:
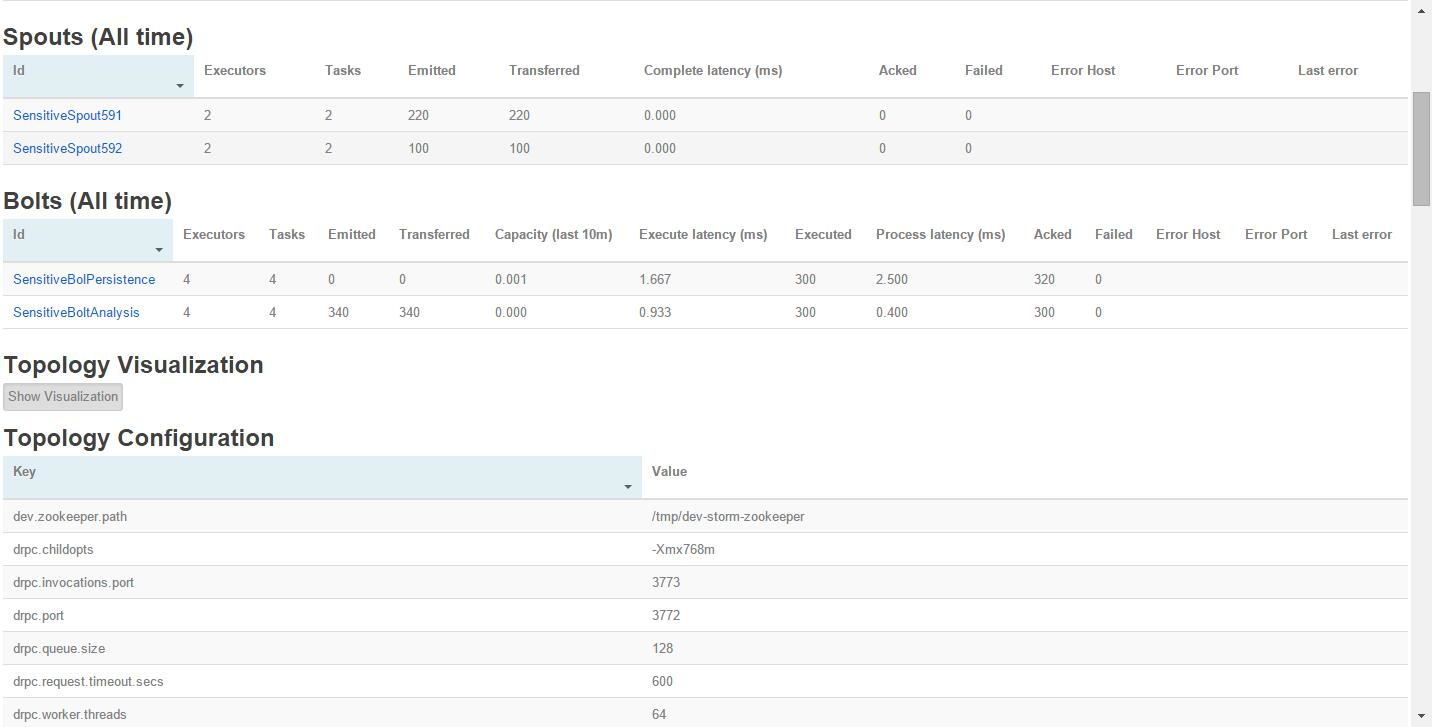
我们可以很清楚的看到:Spouts组件(用户短信采集器):SensitiveFileReader591、SensitiveFileReader592的线程数executors、任务提交emitted情况。以及Bolts组件:监控短信内容拆解分析器(SensitiveFileAnalyzer)、敏感信息采集处理(SensitiveBatchBolt)的运行情况,这样监控起来就非常方便。除此之外,我们还可以到对应的Supervisor服务器对应的Storm安装目录下面的logs目录,查看一下worker的工作日志,我们来看下敏感信息监控过滤的处理情况,截图如下:
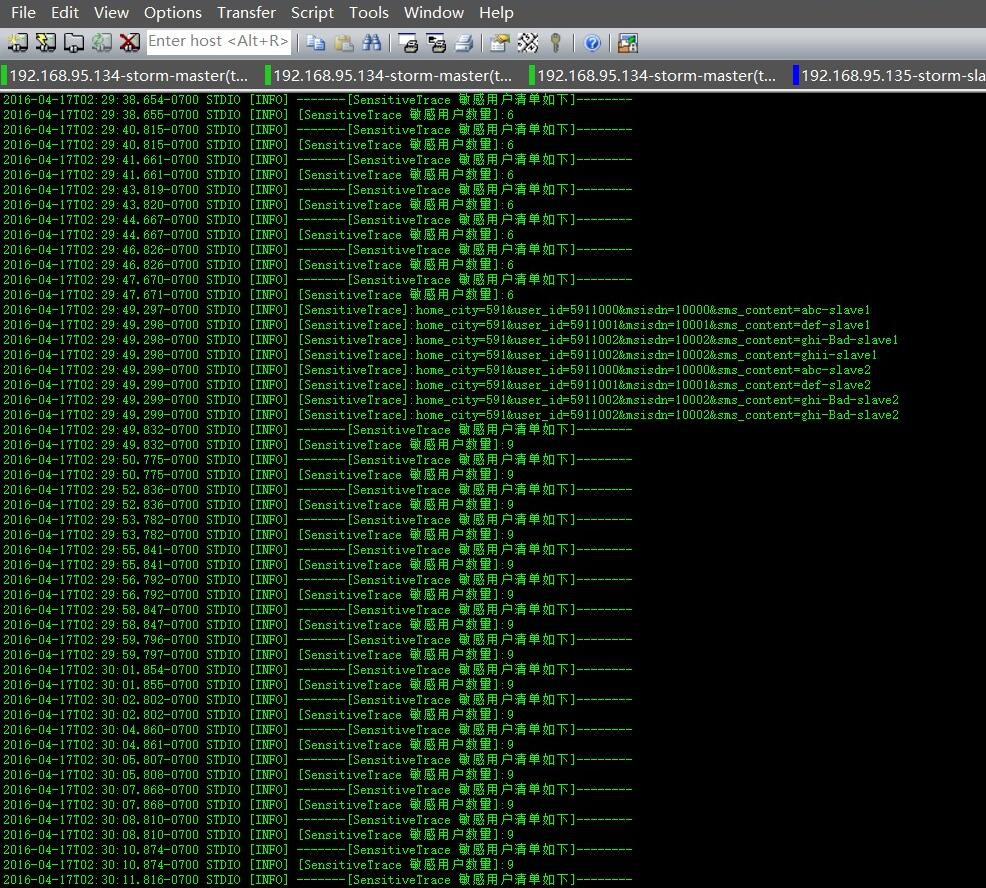
通过SensitiveBatchBolt模块的监控线程,可以看到,我们目前已经采集到了9个敏感信息用户了,我们再来看下,这些包含敏感关键字的用户有没有入库MySQL成功呢?
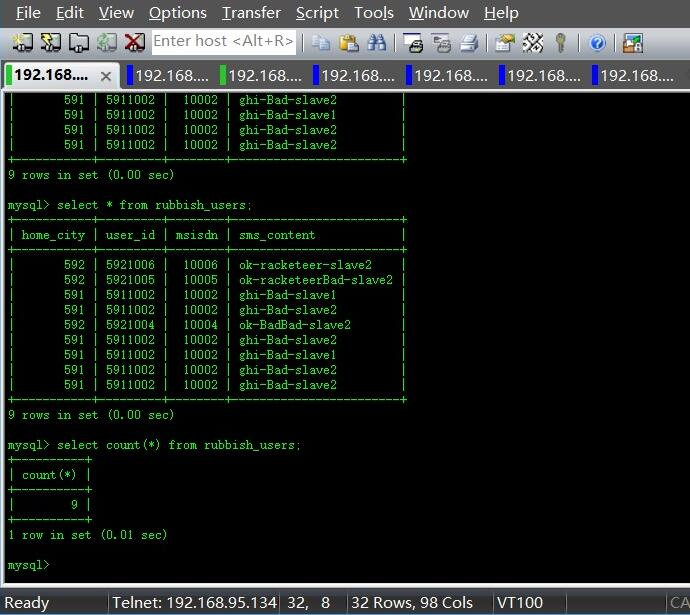
发现入库的结果也是9个,和日志打印的数量上是一致的。而且垃圾短信内容sms_content果然都包含了“racketeer”、“Bad”这些敏感关键字!完全符合我们的预期。而且,以后文件处理量上来了,我们可以通过调整设置Spouts/Bolts的并行度,和Worker的数量进行化解。当然,你还可以通过水平扩展集群的数量来解决这个问题。
Storm在Apache开源项目的网址是:http://storm.apache.org/,有兴趣的朋友可以经常关注一下。官网上面有很权威的技术规范说明,以及如何把Storm和消息队列、HDFS、HBase有效的集成起来。目前在国内,就我个人看法,对Storm分析应用,做得最好的应该算是阿里巴巴,它在原来Storm的基础上加以改良,开源出JStorm,有兴趣的朋友,同样可以多关注一下。
借助Storm,我们可以很轻松地开发分布式实时处理应用,上述场景的设计,只是Storm应用的一个案例。相比传统的单机服务器应用而言,集群化的并行协同计算处理,是云计算、大数据时代的一个趋势
|






