| Hadoop��2006��1��28�յ�������������10�꣬���ı�����ҵ�����ݵĴ洢�������ͷ����Ĺ��̣������˴����ݵķ�չ���γ����Լ��ļ���𱬵ļ�����̬Ȧ�����ܵ��dz��㷺��Ӧ�á���2016��Hadoopʮ������֮�ʣ�InfoQ����һ��Hadoop�ȵ�ϵ�����£�Ϊ�������Hadoop��ʮ��ı仯������Ȧ����̬״�����ع���ǰ�������Ժ�
��ʮ����������Hadoop��̬ϵͳ�IJ������ƣ�Hadoop���ѳ�Ϊ��������ʵ�ϵ���ҵ��֮һ����Ե������������ľ��TB����PB��ԭʼ���ݣ����û���Hadoop�����ݲֿ�������Hive������Hadoop���ȵ�Ӧ��֮һ����������Ŷӳ����������о��ͻ���Hadoopϵͳ�ļ����;��飬���������˷ֲ�ʽ�洢���������ھ��Լ�Ӧ�õ����״����ݴ���ƽ̨��
���Ľ���Hiveԭ�������ݷ���ƽ̨�ܹ������ݷ���ʵս��Hive�Ż����ĸ�����������һЩ����ϵͳ�ܹ���Hive���ĵú�ʵս���飬ϣ����������ջ�
1 Hiveԭ��
Hadoop��һ�����еĿ�Դ��ܣ������洢�ʹ�������Ӳ���ϵĴ��ģ���ݼ�������HDFS�ϵĺ�����־���ԣ���дMapreduce�����������������ݲֿ��������˵�����Ե����������ά�������ã�Hive��Ϊһ�ֻ���Hadoop�����ݲֿ�������Ӧ�˶��������õ��˹㷺Ӧ�á�
Hive�ǻ���Hadoop�����ݲֿ�ƽ̨����Facebook���ף���֧������SQL�Ľṹ����ѯ���ܡ�Facebook��ƿ���Hive�ij��Ծ�������Щ��Ϥsql��̷�ʽ����Ҳ���Ը��õ�����hadoop��hive���������ݷ�����Աֻ��ע�ھ���ҵ��ģ�ͣ�������Ҫ�����˽�Map/Reduce�ı��ϸ�ڣ������Ⲣ����ζ��ʹ��hive����Ҫ�˽��ѧϰMap/Reduce���ģ�ͺ�hadoop������Hive������Ա��˵�������˽�Hadoop��Hive��ԭ����Mapreduceģ�ͣ������Ż���ѯ�����洦��
1.1 Hive�����ģ��
Hive����������Ͽ��Է�Ϊ���¼������֣��û��ӿڣ�UI������������������Ԫ���ݣ�Hiveϵͳ�������ݣ���ִ�����档Hive�а���4������ģ�ͣ�Tabel��ExternalTable��Partition��Bucket��
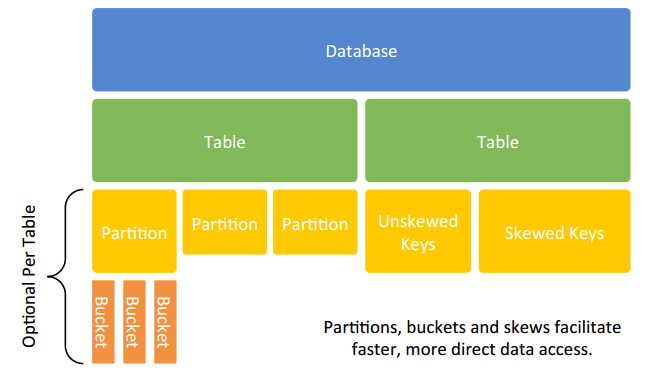
ͼ��hive����ģ��
a) Table��ÿһ��Table��Hive�ж���һ����Ӧ��Ŀ¼���洢���ݣ�
b) Partition�����е�һ��Partition��Ӧ�ڱ��µ�һ��Ŀ¼�����е�Partition���ݶ��洢�ڶ�Ӧ��Ŀ¼�У�
c) Buckets����ָ���м����hash������hashֵ�з����ݣ�Ŀ����Ϊ�˱��ڲ��У�ÿһ��Buckets��Ӧһ���ļ���
d) External Tableָ���Ѵ���HDFS�е����ݣ��ɴ���Partition��
��ʱ��֤����
�봫ͳ���ݿ�Ա����ݽ���дʱ���ز�ͬ��Hive�����ݵ���֤��ʽΪ��ʱģʽ����ֻ���ڶ������ݵ�ʱ��hive�ż�����������ֶΡ�shema�ȣ��Ӷ���֤�˴��������Ŀ��ټ��ء�
�����schema����ļ����ݲ�ƥ�䣬Hive�ᾡ�����ܵ�ȥ�����ݡ����schema�б���10���ֶΣ����ļ���¼ȴֻ��3���ֶΣ���ô����7���ֶν�Ϊnull�����ijЩ�ֶ����Ͷ�λΪ��ֵ���ͣ����Ǽ�¼��ȴΪ����ֵ�ַ�������Щ�ֶ�Ҳ���ᱻת��Ϊnull��Hive��Ŭ��catch������ʱ�����Ĵ���Ŭ�����ء���ȻHive�����ݴ洢��HDFS����Hive���õ��Ƕ�ʱ��֤��ʽ�����������schema���Զ����ɱ����ݵ�HDFSĿ¼�������ǿ������κο��ܵķ�ʽ�����ر����ݻ�������HDFS
API������д���ļ���ͬ��������������Ҫ��hive����д�������⣨��oracle����Ҳ����ֱ��ͨ��api��ȡ������д��Ŀ��⡣
�ٴ�ע�⣬���ػ���д�����������Ҫ�ͱ������schemaһ�£���������ֶλ��߱�Ϊ�ա�
1.2 HQL�����MapReduce Job
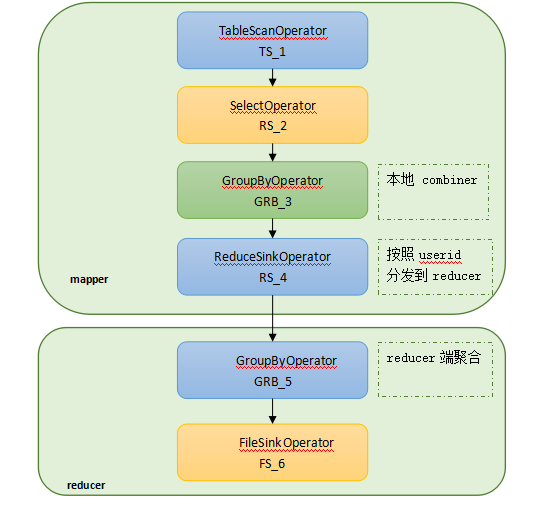
Hive��������HQL����ת����һ���������operator������������Hive����С������Ԫ��ÿ��������������һ��HDFS��������MapReduce��ҵ��Hive�еIJ�����������TableScanOperator��ReduceSinkOperator��JoinOperator��SelectOperator��FileSinkOperator��FilterOperator��GroupByOperator��MapJoinOperator�ȡ�
Hive���
INSERT OVERWRITE TABLE read_log_tmp
SELECT a.userid,a.bookid,b.author,b.categoryid
FROM user_read_log a JOIN book_info b ON a.bookid = b.bookid; |
��ִ�мƻ�Ϊ��
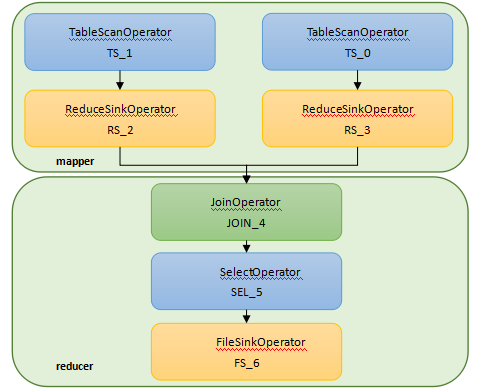
ͼ��join������ִ������
1.3 ��һ��SQL������
Hive ��ͼ��һ�����ݿ���ͼ
Hive��ͼֻ֧������ͼ����֧���ﻯ��ͼ����ÿ�ζ���ͼ�IJ�ѯhive����ִ�в�ѯ���������ͼ������������ϵ���������ΪHive��ѯ�Ż���һ���֣�����ͼ�IJ�ѯ����������ͼ�Ķ����ѯ������佫�ᾡ���ܵĺϲ���һ��������ѯ��
Hive������һ�����ݿ�����
Hive1.2.1�汾Ŀǰ֧�ֵ�����������CompactIndexHandler��Bitmap��
CompactIndexHandler ѹ������ͨ����������ͬ��ֵ���ֶν���ѹ���Ӷ���С�洢�ͼӿ����ʱ�䡣��Ҫע�����Hive����ѹ������ʱ�Ὣ��������Ҳ�洢��Hive���С����ڱ�tb_index
(id int, name string) ���ԣ��������������������Ĭ�ϵ�����һ��Ϊ�����У�id����hdfs�ļ���ַ(_bucketname)��ƫ����(offset)��
Bitmap λͼ������Ϊһ�ֳ��������������������ֻ�й̶��ļ���ֵ����ô�Ϳ��Բ���λͼ���������ٲ�ѯ������λͼ�������Է���Ľ���AND/OR/XOR�ȸ�����㣬Hive0.8�汾��ʼ����λͼ������λͼ�����ڴ����ݴ��������Ӧ�ù㷺�������������bitmap�������û������ʣ������������㣬Ч��Զ����join�ķ�ʽ�������Bitmap������ϡ�裬��ô����Ҫ������ѹ���Խ�ʡ�洢�ռ�ͼӿ�IO��Hive��Bitmap
Handler���õ���EWAH��https://github.com/lemire/javaewah��ѹ����ʽ��
2 ���ݷ���ƽ̨
2.1 �ܹ���ģ��
������ݷ���ƽ̨���������ռ�����ģ�顢���ݷ�������ģ�顢�������ϵͳ�Լ����ӻ�ϵͳ��
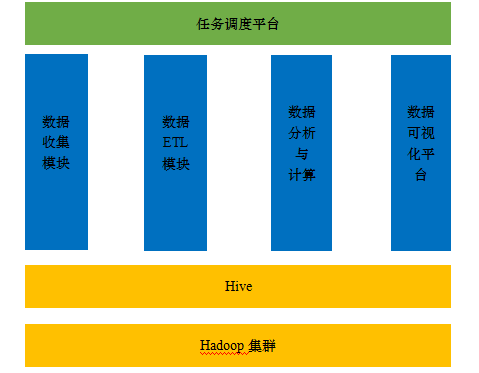
ͼ�����ݷ���ƽ̨�������
�����ռ�ģ��
����ģ�鸺���ռ��ƶ���app����ҳ���Լ��������˴�������־���ݡ��ƶ��˿����п��������ϱ����ܻ���ʹ��sdk���ϱ����ݡ���ҳ������ֲ���js���û�����Ϊ�����ϱ�����������ͨ��http
server���ռ��ϱ������ݡ��������˵���־��Ϣ����ͨ��DXģ��(һ���������ݽ���ϵͳ)������������������hive���ݷ���ƽ̨������֮�⣬������Դ������������user
��item�������ݵȵȡ������ռ���ɽ�������Ҫ����������ԭʼ��������hadoopƽ̨����������ʽ��������������������д��HDFS��
����ETLģ��
һ����ԣ��ϱ������ݶ��Ƿǽṹ�����߰�ṹ���ġ�ETL����ȡ��ת�������أ�ģ�鸺�����еķǽṹ���߰�ṹ������ת���ɽṹ�������ݲ����ص�hive����С���������û�������־��������web
server��־����������Ҫ��ÿ����־�г�ȡ���û��ı�ʶ��cookie��imei����userid����ip��Դ��url�ȡ�����ʽ��������ETL��HDFS��ԭʼ���ݽṹ�����Ա�����ʽ�ṩ������
���ݷ��������
����ҵ��������ܣ�����HQLʵ�ָ���ͳ�Ʒ�����һ��Hive�������Դ�������Ƕ�����������Ҳ�п��ܻ�д����ű���
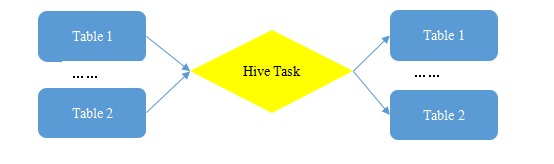
ͼ��Hive����ִ���������
�������ϵͳ
����ͼ���Կ�����Hive����֮�����������ϵ��������Hive����֮�����������Hive������DX����֮�䡢DX����֮�䶼���ܴ���ij��������ϵ��������ݷ���ƽ̨֧�ֵ��������ͻ�����MR����shell����ȣ�������ݷ���ƽ̨���п���˾�ϵ���ϵͳ�����ƽ̨����������ĵ��ȡ�����˾�ϵ���ϵͳ�ɼ��������ۡ�
���ݷ���ƽ̨ģ��
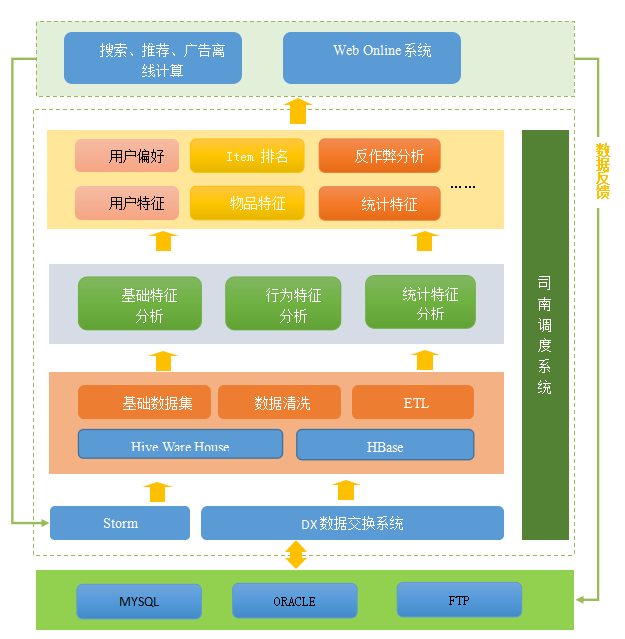
ͼ�����ݷ���ƽ̨����ģ��
��������½�����ܣ����ݷ���ƽ̨�е�������Ҫģ�飺DX���ݽ���ϵͳ�Լ��������ϵͳ��
2.2 DX���ݽ���
DXϵͳ�����ڹ�ϵ�����ݿ⡢Hive��FTP��ϵͳ֮��ʵ�����ݵĽ�����DX������Writer��Reader�ӿ�����������ݵĶ�д���������ڸ��ִ洢���͵����ݣ��趨�����ǵ�ʵ�ַ�����
��ϵ�����ݿ�����JDBCʵ�����д���ܣ�����Hive���ԣ�ֱ������HDFS
APIʵ�ֶ�HDFS�ļ��Ķ�д������Hive�Ķ�ʱ��֤���ƣ���Ҫ�ڶ�дHive���ļ�ʱ���������ֶθ��������Ƶ���Ϣ����֤�������һ�£�FTP�ļ�Ŀǰ�Ĵ����������Ƚ����ݴ�FTP��������������Ȼ��ȡ�ļ����ݣ�д��Hive���ݿ⡣
���Ϲ�������������Դ��Hive�����ݴ�����̣�Hive����ͬ������ͨ��DXϵͳд����������Դ��
2.3 �������
������ݷ���ƽ̨������˾�ϵ���ϵͳ�������Ϊ��Դ�����ͺ�ʵ�������͡�ʱ������������������crontab��ʱ����һ������ʱ������ִ�С���Դ������������Ҫ����������Դ������ʱ�Żᴥ����ִ�С��ɵ��ȵ��������Ͱ���DX����Hive����MR����shell����ȡ�
˾��ϵͳ����Ϊ�ؼ�����dispatcherģ�飬��ģ��ͨ��zookeeper������������agent��ִ������Ĵ�������������Ҫ���ö�����ϵ����У�����zookeeper���Э���ֲ�ʽӦ�õ�һ�����ڴ˲���������
2.4 �ܹ��ݻ�
������ݷ���ƽ̨��ʹ�ù����У���������������Ժ��ȶ��ԡ��ڴ������о��Ϳ��������У�ƽ̨�����У��߳���һ�����������ơ����Ӿ��ҵ���ֵ��
�ӷ�ɢ�����ݽ��������е����ݽ���ϵͳ
��ʹ��ͳһ�����ݽ���ϵͳDX��ҵ��ϵͳ�����ݿ��Ը��õĽ��л�ۺʹ�ͨ������ͳһ�ķ����ʹ�����
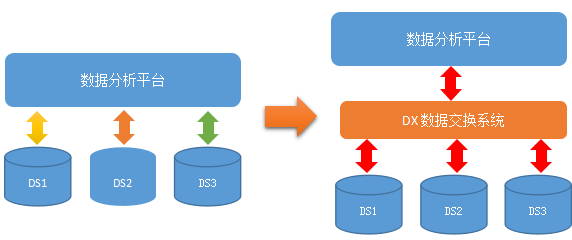
�ӷ�ɢ����ҵ���ȵ����е��������ϵͳ
ÿ�켸ǧ��ģ��������ʹ������ĵ��ȼ������ѣ��ر��ǵ�����֮�����������ϵʱ����Ȼ��ͨ��crontab�Ѿ�������ҵ�������˾�ϵ���ϵͳ��֤��������������ȷ�����С�
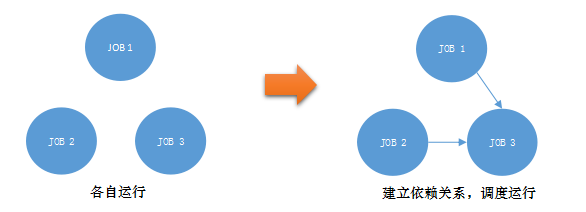
������ʽ������������ʽ����
����ʵʱͳ�Ʒ���������Խ��Խ�࣬hive��ѯ����MR������ʵ�ֵ�ȱ���������ԣ���������������Ϊ���ṩʵʱ�����ݷ�������ƽ̨��ʼ����storm��ʽ����ģ�͡�Storm��������Ϊ�������������㣬ÿ��һ�����ݾͲ���һ�μ�������ʱЧ�Էdz��ߣ���ҵ��Ҳ�õ��˷ḻ��Ӧ�á�
�ӹ�ϵ�����ݿHbase
���ڣ����ݷ����Ľ�����ݶ���ͨ��DX�����ϵ�����ݿ⣬�Ա����ݿ��ӻ�ƽ̨���û�������ϵͳʹ�ã�������������ɹ�ϵ���ݿ�������Ӵ������ص��������⡣HBase��һ����Դ����ʽ�ֲ�ʽ�����ݿ⣬����HDFS�ļ�ϵͳ�����Է���ĺ�Hive���м��ɡ���������HBase��Ϊ���ӻ�ƽ̨������ϵͳ�ṩ������DX�����������ͷ����ӳ١�
3 Hive����ʵ��
3.1 Schema���
û��ͨ�õ�schema��ֻ�к��ʵ�schema�������Hive��schema��ʱ����Ҫ���ǵ��洢��ҵ���ϵĸ�Ƶ��ѯ��ɵĿ����ȵȣ�����ʺ��Լ�������ģ�͡�
���÷�����
����Hive��˵�����÷�������Ʊ����DZ�Ҫ�ģ������ṩ��һ�ָ������ݺ��Ż���ѯ�ı����ķ�ʽ�����÷���ʱ����Ҫ���DZ����óɷ������ֶΣ�����ʱ�����һ����Ծ���һ���õķ�������ô��������ǰ��ղ�ͬʱ��������ȷ�����ʴ�С�����ݻ�����������ʱ������ƣ����������������Ǿ��ȵģ������Ĵ�СҲ�Ǿ��ȵġ�
����С�ļ�
��Ȼ���������ڸ������ݺͲ�ѯ�����ù����ϸ�ķ���Ҳ�����ƿ������Ҫ����Ϊ����ķ�����ζ���ļ�����Ŀ��Խ�࣬����������С�ļ����namecode�����������ѹ����ͬʱС�ļ������Ӱ��JOB��ִ�У�hadoop�Ὣһ��jobת���ɶ��task����ʹ����ÿ��С�ļ�Ҳ��Ҫһ��taskȥ�����������������ܿ�������ˣ�hive����Ƶķ�����Ӧ�ù����ϸ��ÿ��Ŀ¼�µ��ļ��㹻��Ӧ�����ļ�ϵͳ�п��С�����ɱ���
ѡ���ļ���ʽ
Hive�ṩ��Ĭ���ļ��洢��ʽ��textfile��sequencefile��rcfile�ȡ��û�Ҳ����ͨ��ʵ�ֽӿ����Զ�����������ļ���ʽ��
��ʵ��Ӧ���У�textfile������ѹ�������̼������Ŀ������ܴ�һ�����ʹ�á�Sequencefile�Լ�ֵ�Ե���ʽ�洢�Ķ����Ƶĸ�ʽ����֧����Լ�¼����Ϳ鼶���ѹ����rcfile��һ�����н�ϵĴ洢��ʽ��text
file��sequencefile�����б�[row table]�����䱣֤ͬһ����¼��ͬһ��hdfs���У�������ʽ�洢��rcfile�ľۺ����㲻һ�����Ǵ��ڣ�����rcfile�ĸ�ѹ����ȷʵ�����ļ���С�����ʵ��Ӧ���У�rcfile���dz�Ϊ������ѡ�������ƽ̨��ѡ���ļ��洢��ʽʱҲ����ѡ����rcfile������
3.2 ͳ�Ʒ���
���ڽ�������ʹ��ں�����������Ľ���Hive��ͳ�Ʒ������ܡ�
��������������ʵ�ʵ�ҵ���о����������������ܻ�ӭ���鼮������TOP100����Ʒ�ȵȡ���ʵ������£����Dz�����Ҫ���Ǹ�����ָ�꣬����Ҫ�������Ŷ����⡣
���������ORDER BY value LIMIT n
������ѯ��������������ָ�꣬��������ƽ���������ϴ�
�������������ڶ࣬������ݷ���ƽ̨�ڽ���item ��������û����û�ͶƱ�������㷨�����������ѷ����������㷨�����㷨���ԽϺõĽ��С�����IJ�ȷ���⡣
ͼ������ѷ����
���ڷ�������
Hive�ṩ�˷ḻ����ѧͳ�ƺ�����ͬʱҲ�ṩ���û��Զ��庯���Ľӿڣ��û������Զ���UDF��UDAF��UDTF
Hive 0.11�汾��ʼ�ṩ���ںͷ���������Windowing and Analytics Functions��������LEAD��LAG��FIRST_VALUE��LAST_VALUE��RANK��ROW_NUMBER��PERCENT_RANK��CUBE��ROLLUP�ȡ����ں�����ۺϺ���һ�������ǶԱ��Ӽ��IJ������ӽ���Ͽ����������ڴ��ں����Ľ������ۺϣ�ԭ�е�ÿ�м�¼��Ȼ����ڡ����ں����ĵ��ͷ���Ӧ�ð������������ۺϣ�����top
n���⣩���м���㣨ʱ�����з��������������㣨��������������
������һ�����м���������˵�����ں�����Ӧ�ã��������������ľ���˵������ο�hive�ĵ������û��Ķ���Ϊ��ͳ�Ʒ�����Ҫ�ӵ���鼮��Ϊ�й���ͳ�Ƴ������û������־�ṹ���±���ʾ��ÿ����¼Ϊ�û��ĵ��ε����Ϊ��

ͨ�����������û������־������ͨ��Hive�ṩ�Ĵ��ڷ����������Լ�����û����½ڵ��Ķ�ʱ�䡣
SELECT userid, bookid, chapterid, end_time �C start_time as read_time
FROM
(
SELECT userid, bookid, chapterid, log_time as start_time,
lead(log_time,1,null) over(partition by userid, bookid order by log_time) as end_time
FROM user_read_log where pt=��2015-12-01��
) t; |
ͨ��������ѯ�ȿ����ҳ�2015-12-01�������û���ÿһ�½ڵ��Ķ�ʱ�䡣ֻ��ͨ������mr�������ʵ��udaf��ʵ���������ܡ�
���ڷ��������ؼ����ڶ���Ĵ������ݼ�����Դ��ڵIJ�����ͨ��over�����ڶ�����䣩�����崰�ڡ��ճ�������ʵ��Ӧ���У��������д��ڷ���Ӧ�õij�����������ڷ����������ϡ�ͳ�Ƶȸ��Ӳ���������������Ҫͳ��ÿ���û��Ķ�ʱ������3����:

ͼ���м����ʾ��ͼ������
���ں���ʹ��Hive�ľ߱������������ݷ������ܣ���ʵ�ʵ�Ӧ�û����У�������ݷ����ŶӴ���ʹ��hive���ڷ���������ʵ�ֽ�Ϊ���ӵ�������߿����͵���Ч�ʡ�
3.3 �û�����
�û���������ʵ���ݵ��û�ģ�͡�����˵���û�������ȡ���û���������Ϣ����Ϊ��Ϣ���Ӷ�����ͳ�Ƴ����˿�ѧ������ƫ�������ȡ������û�ģ�͵���Ҫ���������ȡ�������Ȱ����û�����������Ҳ������Ϊ������ͳ��������
�û�ģ�ͱ����Ͼ��ǿ̻��û���Ȥ��ģ�ͣ����û�����Ȥģ���Ƕ�ά�ȡ���߶ȵġ��̻��û�ģ�ͻ���Ҫ��ʱ���Ͻ��ж����������ǽ��ж�߶ȵ���ϣ������û���Ϊͳ��ʱ��ij��̣����Խ��û���ƫ�÷�Ϊ����ƫ�úͳ���ƫ�á�ƫ�õ�Ȩ�ؼ�Ϊ�û���ƫ�ó̶ȵĶ�����
���û�ƫ�õ�����������Ҫ�������Ŷȵ����⣬�������һ���Ķ���Ϊ����ϡ����û���˵���̻����Ķ����ƫ���Ǻ�������ġ�
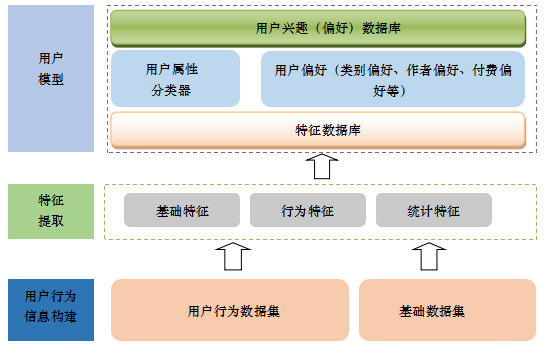
ͼ���û�����̻�
3.4 ��������
������֪�����������Ϳ��ܴ������ס�������桢��������ˢ����ˢ�����������һ����˵������Ŀ�Ķ���Ϊ������Լ��������������ǽ��Ͷ��ֵ�����������Hive�����ݽ��з������Թ��˵������Ե��������ݣ��ﵽ������ϴ��Ŀ�ġ�
�������һ��ˢ��������Ϊ����Ҫ�����Ų���ˢ��־��Ϊ����������������ǿ���ָ�����ɹ����������������ݡ���ͬIPͬ��Ʒͬ��Ϊ��Ŀ�쳣��ͬ�û�ID��ΪƵ���쳣��ͬ��ƷID��ΪƵ���쳣�ȵȡ�����ͼ��������������item��ƽ���������ƣ����ijitem�������������ƽ��ˮƽ������ô�����ĸ��ʾͱȽϸߡ�
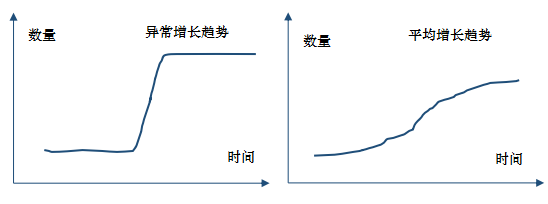
ͼ����������������ƽ���������ݶԱ�
����������Ҫ���ҵ��������ص㣬���ú��ʵĻ���ѧϰ�㷨�����и���һ�����жϺ��ˣ��ﵽ������Ŀ�ꡣ
4 Hive�Ż�
��۵����ݲֿ����Hive���ÿ����Ҫ���������ļ������̣�Hive���ȶ��Ժ�����������Ҫ���ڶ��������Ҫ���Ǻ����ĵ��ڷ��伯Ⱥ��Դ�����������ø��������������Ż���ѯ��Hive�Ż������������棬��job�����Ż���job��map/reducer�����Ż�������ִ���Ż��ȵȣ����ڽ���Ҫ����HQL�е���ʱ���ڵ�JOIN���Ż����顣
4.1 Join���
����������join��䣬����book_info������Ϊǧ��ģ��
INSERT OVERWRITE TABLE read_log_tmp
SELECT a.userid,a.bookid,b.author
FROM user_read_log a JOIN book_info b ON a.bookid = b.bookid; |
������ִ�мƻ�Ϊ��
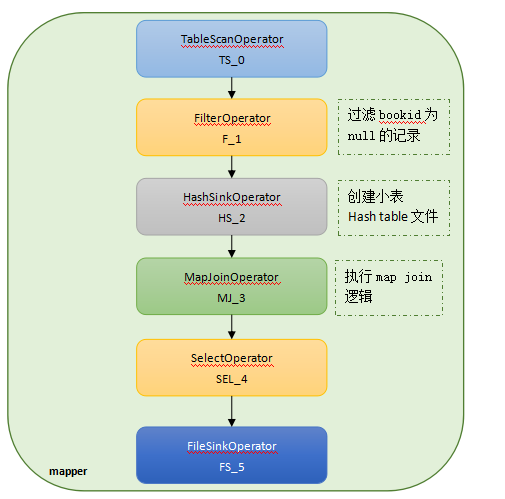
ͼ��map join������ִ������
����С��������hive���Զ���ȡmap join�ķ�ʽ���Ż�join����mapreduce�ı��ģ��������ʵ��join�ķ�ʽ��Ҫ��map��join��reduce��join��Map��join����hadoop
�ֲ�ʽ���漼��ͨ����С���任��hashtable�ļ��ַ�������task��map���ʱ����ֱ���ж�hashtable�����join��ע��С����hashtable�Ƿ����ڴ��еģ����ڴ�����ƥ�䣬���map
join��һ�ַdz����join��ʽ��Ҳ��һ�ֳ������Ż���ʽ�����С����С����ô�Ϳ�����map join�ķ�ʽ�����join��ɡ�Hiveͨ������hive.auto.convert.join=true(Ĭ��ֵ)���Զ����map
join���Ż�����������ʾָʾmap join��ȱʡ�����map join���Ż��Ǵġ�
Reduce��join��Ҫreducer�����join���̣���������join���룬reduce
��join��mr�������£�
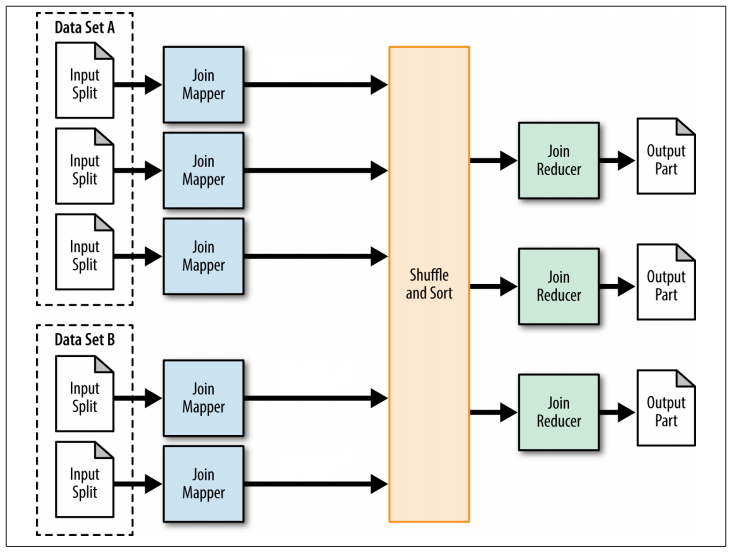
ͼ��reduce��join��mapreduce����
�����map join, reduce ��join����map�����й����κμ�¼��ֻ�ܽ�join�����ű����������ݰ���join
key����shuffle/sort��������join key��hashֵ��<key,value>�Էַ����ض���reducer��Reducer�������еļ�ֵ��ִ��join����������0�ţ�bookid��hashֵΪ0��reducer�յ��ļ�ֵ�����£�����T1��T2��ʾ��¼����Դ������ʶ���ã�

ͼ��reduce��join��reducer
join
Reducer��join�������reduce�ض��Լ�����Ĵ������ݶ������Ⱥ�������ѹ��������ͼ���Կ�������hash(bookid)
% reducer_number����0��key-value�Զ���ͨ��shuffle���ַ���0��reducer������ֵ�0��reducer�ļ�¼��ĿԶ��������reducer�ļ�¼��Ŀ����Ȼ0�ŵ�reducer�����ݴ���������Զ��������reducer����˴���ʱ��Ҳ��Զ��������reducer������������ڴ���������⣬�����������б���⡣����join��ɵ�������б�������ǿ���ͨ�����ò���set
Hive.optimize.skewjoin=true����hive�Լ����Խ��join�����в�������б���⡣
4.2 Group by
������Ƕ�user_read_log����userid goup by���������̽��������б���⣬��������explain
group by��䣺
explain select userid,count(*) from user_read_log group by userid |
ͼ��goup by��ִ�мƻ�
Group by��ִ�мƻ�����userid��hashֵ�ַ����ݣ�ͬʱ��map��Ҳ���˱���reduce��group
by��shuffle�����ǰ���hash(userid)���ַ��ģ�ʵ��Ӧ������־�кܶ��û�����δע���û�����δ��¼��userid�ֶ�Ϊ�յļ�¼��Զ����userid��Ϊ�յļ�¼���������еĿ�userid��¼���ַ����ض�ijһ��reducer��Ҳ��������ص�������б���⡣���������б����Ҫԭ�����ڷַ���ij����ij����reducer��������Զ��������reducer����������
����group by��ɵ�������б���⣬���ǿ���ͨ�����ò���
set hive.map.aggr=true (����map��combiner);
set hive.groupby.skewindata=true��
�����������������reduce������ʱ���õ���key������������ֵͬ��ͬһ��Reduce����������ַ���Ȼ��reduce���ۺϣ�����֮������һ��MR����ǰ��ۺϹ�����������������Ȼ����һ��MR�����ǿ�����Ч�ļ���������б������ܴ�����Σ�ա�
Hive���������б
��ȷ������Hive����������ij�̶ֳ��ϱ����������б���⣬���ʵIJ�ѯ���Ҳ���Ա���������б���⡣Ҫ����Ĺ������ݺͲü����ݣ����ٺ�����������������ʹ��join
key�����ݷֲ���Ϊ���ȣ������ֶ��������ֵ�������ȿ��Ծ��ȷַ���б�����ݣ�
select userid,name from user_info a
join (
select case when userid is null then cast(rand(47)*100000 as int)
else userid
from user_read_log
) b on a.userid = b.userid |
����û��ڶ���schema��ʱ����Ѿ�Ԥ�ϵ������ݿ��ܻ�������ص�������б���⣬Hive��0.10.0������skew
table�ĸ���罨�����
CREATE TABLE user_read_log (userid int,bookid, ��)
SKEWED BY (userid) ON (null) [STORED AS DIRECTORIES]; |
��Ҫע����ǣ�skew tableֻ�ǽ���б�ر����ص��еķֿ��洢Ϊ��ͬ���ļ���ÿ���ƶ�����бֵ�ƶ�Ϊһ���ļ�����Ŀ¼������ڲ�ѯ��ʱ�����ͨ��������бֵ������������б���⣺
select userid,name from user_info a
join (
select userid from user_read_log where pt=��2015�� and userid is not null
) b on a.userid = b.userid |
���Կ�����������ӹ�����������б����ǻ���ڣ�ͨ����skew table�ӹ��������ĺô��DZ�����mapper�ı�ɨ����˲�����
4.3 Join�������Ż�
Hive�ڲ�ʵ����MapJoinResolver������MapJoin����SkewJoinResolver��������бjoin����CommonJoinResolver��������ͨJoin��������ʵ��join�IJ�ѯ�����Ż���/org/apache/hadoop/hive/ql/optimizer/physical����
CommonJoinResolver�ฺ����ͨJoinת����MapJoin��Hiveͨ���������ʵ��mapjoin���Զ��Ż������ڱ�A�ͱ�B��join��ѯ�������3����֧��
1) �Ա�A��Ϊ�������Mapjoin��
2) �Ա�A��Ϊ�������Mapjoin��
3) Map-reduce join
���ڲ�֪���������ݹ�ģ����˱���ʱ������������Ǹ���֧������������ʱ�ж����Ǹ���֧����Ҫע�����Ҫ����������Զ�ת������Ҫ��hive.auto.convert.join.noconditionaltask����Ϊtrue��Ĭ��ֵ����ͬʱ�����ֹ�����ת�ؽ��ڴ��С���Ĵ�С��hive.auto.convert.join.noconditionaltask.size����
MapJoinResolver �ฺ���������mr�����ÿ�������Ƿ����map
join����������У��Ὣlocal map workת����local map join work��
SkewJoinResolver�ฺ�������join������reducer����һ������reducer��������б����ô�ͻὫ��бֵ������д��hdfs��Ȼ����һ���µ�map
join��������������бֵ�ļ��㡣��Ȼ����һ��mr���������ڲ��õ�map join��Ч��Ҳ�Ǻܸߵġ����õ�mrģʽ��ִ����������������Ҫ�ġ�
5 �ܽ�
������ϸ�����˴�۴����ݷ���ƽ̨�Ļ����ܹ���ԭ��������hadoop/hive�Ĵ����ݷ���ƽ̨ʹ�������ݵĴ洢���������ھ���Ϊ��ʵ�����������벻�����洦����Ϊ���ݷ���ƽ̨��������Hive��Ȼ���ڲ��ϵķ�չ֮�У���HQL�����Mapreduce��������Hadoop�ĺ��������Ǹ��õ�ʹ�ú��Ż�Hive�ĸ�������������Ŷ�Ҳ������������չ���������������ҵ������ȡ�����Ŀ�ܼܹ�����������ƽ̨�Ĵ���������
|






