| MongoDB的备份其实算是一个基本操作,最近总是有人问起,看来很多人对这里还不太熟悉。为了避免一次又一次地重复解释,特总结成一篇博客供后来者查阅。如有不尽正确之处请指正。
1. 内建方法
1.1 复制数据库文件
不用多做解释,几乎对任何数据库都有用,简单粗暴。但像多数数据库一样,这个操作必须在mongod实例停止的情况下进行才能保证你得到的是正确状态下的数据库。否则在备份过程中如果有写操作,可能造成备份到的库处于非正常状态而不可使用。必须停止数据库这一点就造成了这个方法的可用性非常低,使用场景有限。
1.2 mongodump/mongorestore
我不打算细说这两个命令如何使用,因为介绍这两个命令的文章网上已经一大堆了,大家可以轻松从别处或者官方文档中找到说明。不想细说的另一个原因也是希望看到这里的读者能够养成独立解决问题的能力,不要对所谓的“高手”产生依赖,遇到问题独立思考独立解决,这将是你今后的道路上必不可少的技能之一。
下面介绍一些别人说得相对少的东西。
1.2.1 除了mongodump/mongorestore之外还有一对组合是mongoexport/mongoimport
区别在哪里?
1.mongoexport/mongoimport导入/导出的是JSON格式,而mongodump/mongorestore导入/导出的是BSON格式。
2.JSON可读性强但体积较大,BSON则是二进制文件,体积小但对人类几乎没有可读性。
3.在一些mongodb版本之间,BSON格式可能会随版本不同而有所不同,所以不同版本之间用mongodump/mongorestore可能不会成功,具体要看版本之间的兼容性。当无法使用BSON进行跨版本的数据迁移的时候,使用JSON格式即mongoexport/mongoimport是一个可选项。跨版本的mongodump/mongorestore个人并不推荐,实在要做请先检查文档看两个版本是否兼容(大部分时候是的)。
4.JSON虽然具有较好的跨版本通用性,但其只保留了数据部分,不保留索引,账户等其他基础信息。使用时应该注意。
总之,这两套工具在实际使用中各有优势,应该根据应用场景选择使用(好像跟没说一样)。但严格地说,mongoexport/mongoimport的主要作用还是导入/导出数据时使用,并不是一个真正意义上的备份工具。所以这里也不展开介绍了。
1.2.2 mongodump有一个值得一提的选项是--oplog
注意这是replica set或者master/slave模式专用(standalone模式运行mongodb并不推荐)。
--oplog use oplog for taking a point-in-time snapshot |
看英文说明好牛B的样子,point-in-time快照哦,我第一次看到这句话的时候的理解是它可以让数据库回到这段时间中的任意一个时间点的状态,美了好一阵。但实际上并不是。它的实际作用是在导出的同时生成一个oplog.bson文件,存放在你开始进行dump到dump结束之间所有的oplog。这个东西具体有什么用先卖个关子。用图形来说明下oplog.bson的覆盖范围:

为了后面的讲解不至于把人说晕,进一步说明之前先解释一下什么是oplog及其相关概念。官方提供的文档其实已经很全面地做了解释,点击查看中文文档或英文文档。
简单地说,在replica set中oplog是一个定容集合(capped collection),它的默认大小是磁盘空间的5%(可以通过--oplogSizeMB参数修改),位于local库的db.oplog.rs,有兴趣可以看看里面到底有些什么内容。其中记录的是整个mongod实例一段时间内数据库的所有变更(插入/更新/删除)操作。当空间用完时新记录自动覆盖最老的记录。所以从时间轴上看,oplog的覆盖范围大概是这样的:
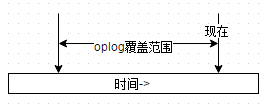
其覆盖范围被称作oplog时间窗口。需要注意的是,因为oplog是一个定容集合,所以时间窗口能覆盖的范围会因为你单位时间内的更新次数不同而变化。想要查看当前的oplog时间窗口预计值,可以使用以下命令:
test:PRIMARY> rs.printReplicationInfo()
configured oplog size: 1561.5615234375MB <--集合大小
log length start to end: 423849secs (117.74hrs) <--预计窗口覆盖时间
oplog first event time: Wed Sep 09 2015 17:39:50 GMT+0800 (CST)
oplog last event time: Mon Sep 14 2015 15:23:59 GMT+0800 (CST)
now: Mon Sep 14 2015 16:37:30 GMT+0800 (CST) |
oplog有一个非常重要的特性――幂等性(idempotent)。即对一个数据集合,使用oplog中记录的操作重放时,无论被重放多少次,其结果会是一样的。举例来说,如果oplog中记录的是一个插入操作,并不会因为你重放了两次,数据库中就得到两条相同的记录。这是一个很重要的特性,也是后面这些操作的基础。
回到主题上来,看看oplog.bson到底有什么作用。首先要明白的一个问题是数据之间互相有依赖性,比如集合A中存放了订单,集合B中存放了订单的所有明细,那么只有一个订单有完整的明细时才是正确的状态。假设在任意一个时间点,A和B集合的数据都是完整对应并且有意义的(对非关系型数据库要做到这点并不容易,且对于MongoDB来说这样的数据结构并非合理。但此处我们假设这个条件成立),那么如果A处于时间点x,而B处于x之后的一个时间点y时,可以想象A和B中的数据极有可能不对应而失去意义。
再回来看mongodump的操作。mongodump的进行过程中并不会把数据库锁死以保证整个库冻结在一个固定的时间点,这在业务上常常是不允许的。所以就有了dump的最终结果中A集合是10点整的状态,而B集合则是10点零1分的状态这种情况。这样的备份即使恢复回去,可以想象得到的结果恐怕意义有限。那么上面这个oplog.bson的意义就在这里体现出来了。如果在dump数据的基础上,再重做一遍oplog中记录的所有操作,这时的数据就可以代表dump结束时那个时间点(point-in-time)的数据库状态。
这个结论成立的重要条件就是幂等性:已存在的数据,重做oplog不会重复;不存在的数据重做oplog就可以进入数据库。所以当做完截止到某个时间点的oplog时,数据库就恢复到了截止那个时间点的状态。
来看看mongorestore的选项。跟oplog相关的选项有--oplogReplay和--oplogLimit。第一个选项顾名思义,可以重放oplog.bson中的操作内容。第二个选项
后面再做介绍。先来看一个例子:
首先我们模拟一个不断有插入操作的集合foo,
use test
for(var i = 0; i < 100000; i++) {
db.foo.insert({a: i});
} |
然后在插入过程中模拟一次mongodump并指定--oplog。
mongodump -h 127.0.0.1 --oplog |
注意--oplog选项只对全库导出有效,所以不能指定-d选项。因为整个实例的变更操作都会集中在local库中的oplog.rs集合中。
根据上面所说,从dump开始的时间系统将记录所有的oplog到oplog.bson中,所以我们得到这些文件:
yaoxing ~ $ ll dump/
total 440
-rw-r--r-- 1 yaoxing yaoxing 442470 Sep 14 17:21 oplog.bson
drwxr-xr-x 2 yaoxing yaoxing 4096 Sep 14 17:21 test |
其中test是我们刚才使用的数据库,oplog.bson是导出期间进行的所有操作。如果对oplog.bson中的内容好奇,可以用bsondump工具来查看其中的内容,例如:
{"h":{"$numberLong":"2279811375157953332"},"ns":"test.foo",
"o":{"_id":{"$oid":"55f834ae6b530b5854f9d6ee"},"a":7784.0},"op":"i","ts":{"$timestamp":{"t":1442329774,"i":3248}},"v":2} |
从oplog.bson中我们挑选第一条和最后一条内容出来观察
{"h":{"$numberLong":"2279811375157953332"},"ns":"test.foo","
o":{"_id":{"$oid":"55f834ae6b530b5854f9d6ee"},"a":7784.0},"op":"i","ts":{"$timestamp":{"t":1442329774,"i":3248}},"v":2}
...
{"h":{"$numberLong":"-1177358680665374097"},"ns":"test.foo",
"o":{"_id":{"$oid":"55f834b26b530b5854f9fa5e"},"a":16856.0},"op":"i","ts":{"$timestamp":{"t":1442329778,"i":1361}},"v":2} |
红字部分可以看出,从开始进行mongodump时,循环进行到i=7784,而到整个操作结束时,循环进行到i=16856。再看一下test/foo.bson中数据的最后一条
{"_id":{"$oid":"55f834ae6b530b5854f9d73d"},"a":7863.0} |
可以发现,最终dump出的数据既不是最开始的状态,也不是最后的状态,而是中间某个随机状态。这正是因为集合不断变化造成的。
那么使用mongorestore来恢复:
yaoxing ~ $ mongorestore -h 127.0.0.1 --oplogReplay dump
2015-09-19T01:22:20.095+0800 building a list of dbs and collections to restore from dump dir
2015-09-19T01:22:20.095+0800 reading metadata for test.foo from
2015-09-19T01:22:20.096+0800 restoring test.foo from
2015-09-19T01:22:20.248+0800 restoring indexes for collection test.foo from metadata
2015-09-19T01:22:20.248+0800 finished restoring test.foo (7864 documents)
2015-09-19T01:22:20.248+0800 replaying oplog
2015-09-19T01:22:20.463+0800 done |
注意红字的两句,第一句表示test.foo集合中恢复了7864个文档;第二句表示重放了oplog中的所有操作。所以理论上foo应该有16857个文档(7864个来自foo.bson,剩下的来自oplog.bson)。验证一下:
test:PRIMARY> db.foo.count()
16857 |
这就是带oplog的mongodump的真正作用。
1.2.3 从别处而来的oplog
聪明如你可能已经想到,既然dump出的数据配合oplog就可以把数据库恢复到某个状态,那是不是拥有一份从某个时间点开始备份的dump数据,再加上从dump开始之后的oplog,如果oplog足够长,是不是就可以把数据库恢复到其后的任意状态了?是的!事实上replica
set正是依赖oplog的重放机制在工作。当secondary第一次加入replica set时做的initial
sync就相当于是在做mongodump,此后只需要不断地同步和重放oplog.rs中的数据,就达到了secondary与primary同步的目的。
既然oplog一直都在oplog.rs中存在,我们为什么还需要在mongodump时指定--oplog呢?需要的时候从oplog.rs中拿不就完了吗?答案是肯定的,你确实可以只dump数据,不需要oplog。在需要的时候可以再从oplog.rs中取。但前提是oplog时间窗口(忘了时间窗口概念的请往前翻)必须能够覆盖dump的开始时间。
明白了这个道理,理论上只要我们的mongodump做得足够频繁,是可以保证数据库能够恢复到过去的任意一个时间点的。MMS(现在叫Cloud
Manager)的付费备份也正是在利用这个原理工作。假设oplog时间窗口有24小时,那么理论上只要我在每24小时内完成一次dump,即可保证dump之后的24小时的point-in-time数据恢复。在oplog时间窗口快要滑出24小时的时候,只要及时完成下一次dump,就又可以有24小时的安全期。
来做个测试。仍然使用前面的方法模拟一段时间的数据库插入操作:
use test
for(var i = 0; i < 100000; i++) {
db.foo.insert({a: i});
} |
同时做一次mongodump并不带--oplog:
yaoxing ~/dump $ mongodump -h 127.0.0.1
2015-09-24T00:06:11.929+0800 writing test.system.indexes to dump/test/system.indexes.bson
2015-09-24T00:06:11.929+0800 done dumping test.system.indexes (1 document)
2015-09-24T00:06:11.929+0800 writing test.foo to dump/test/foo.bson
2015-09-24T00:06:11.963+0800 done dumping test.foo (11162 documents) |
可见我们导出了i=11162时的状态。等插入完成后,理论上我们的foo集合应该有100000条记录
> use test
switched to db test
> db.foo.count()
100000 |
现在假设我进行了一次误操作:
> db.foo.remove({})
WriteResult({ "nRemoved" : 100000 }) |
更惨的是我之后又往foo里面插入了一条数据
> db.foo.insert({a: 100001});
WriteResult({ "nInserted" : 1 }) |
现在怎样让时间倒流,回到灾难前的状态呢?由于在灾难前我们有过一次dump,因此现在只要在oplog时间窗口还能覆盖导出时间之前把oplog抢救出来就好了:
yaoxing ~ $ mongodump -h 127.0.0.1 -d local -c oplog.rs
2015-09-24T00:09:41.040+0800 writing local.oplog.rs to dump/local/oplog.rs.bson
2015-09-24T00:09:41.525+0800 done dumping local.oplog.rs (200003 documents) |
为什么会有200003条记录呢?请自行使用bsondump工具查看发生了什么事情。
从前面讲的可知,使用mongodump加oplog.bson(请注意文件位置)即可恢复数据库。这里的dump/local/oplog.rs.bson其实就是我们需要的oplog.bson。因此把它重命名后放到合适的位置,一个模拟出来的恢复环境就准备好了
yaoxing ~/dump $ ll
total 18464
-rw-r--r-- 1 yaoxing yaoxing 18900271 Sep 24 00:09 oplog.bson
drwxr-xr-x 2 yaoxing yaoxing 4096 Sep 24 00:06 test |
但是这个oplog.bson可是包含了所有灾难操作的啊,如果全盘恢复回去,就等于是先让时光倒流,再看悲剧重演一遍。心都碎了……这时候你需要一个新朋友,就是上面提到的--oplogLimit。它与--oplogReplay一起使用时,可以限制重放到的时间点。那么重要的问题就是如何找到灾难发生的时间点了。仍然是bsondump。如果你对Linux命令熟悉,可以在管道中直接操作。如果不行,那就先dump到文件中,再用文本编辑器打开慢慢找好了。我们需要找的内容是"op":"d",它表示进行了一次删除操作。可以发现,oplog.bson中有100000次删除操作,实际上是一条一条把记录删除掉,这也是为什么remove({})操作会这么慢。如果对一个集合进行drop()就会快得多,它进行的操作请读者自己尝试。
yaoxing ~/dump $ bsondump oplog.bson | grep "\"op\":\"d\"" | head
{"b":true,"h":{"$numberLong":"5331406427126597755"},"ns":"test.foo",
"o":{"_id":{"$oid":"5602cdf1befd4a4bfb4d149b"}},"op":"d","ts":{"$timestamp":{"t":1443024507,"i":1}},"v":2}
... |
此条记录中我们需要的是红色的$timestamp部分,它代表的发生这个操作的时间,也正是我们的--oplogLimit需要传入的时间,只是格式稍稍有变:
yaoxing ~ $ mongorestore -h 127.0.0.1 --oplogReplay --oplogLimit "1443024507:1" dump/
2015-09-24T00:34:09.533+0800 building a list of dbs and collections to restore from dump dir
2015-09-24T00:34:09.534+0800 reading metadata for test.foo from
2015-09-24T00:34:09.534+0800 restoring test.foo from
2015-09-24T00:34:09.659+0800 restoring indexes for collection test.foo from metadata
2015-09-24T00:34:09.659+0800 finished restoring test.foo (11162 documents)
2015-09-24T00:34:09.659+0800 replaying oplog
2015-09-24T00:34:11.548+0800 done |
其中1443024507即是$timestamp中的"t",1即是$timestamp中的"i"。这样配置后oplog将会重放到这个时间点以前,即正好避开了第一条删除语句及其后面的操作,数据库停留在灾难前状态。验证一下:
rs0:PRIMARY> db.foo.count()
100000 |
1.3 小结
结合上术知识,我们可以总结一些mongodb的备份准则(只针对replica或master/slave),满足这些准则,MongoDB就可以进行point-in-time恢复操作:
任意两次数据备份的时间间隔(第一次备份开始到第二次备份结束)不能超过oplog时间窗口覆盖范围。
在上次数据备份的基础上,在oplog时间窗口没有滑出上次备份结束的时间点前进行完整的oplog备份。请充分考虑oplog备份需要的时间,权衡服务器空间情况确定oplog备份间隔。
实际应用中的注意事项:
考虑到oplog时间窗口是个变化值,请关注oplog时间窗口的具体时间。
在靠近oplog时间窗口滑动出有效时间之前必须要有足够的时间dump出需要的oplog.rs,请预留足够的时间,不要顶满时间窗口再备份。
当灾难发生时,第一件事情就是要停止数据库的写入操作,以往oplog滑出时间窗口。特别是像上述这样的remove({})操作,瞬间就会插入大量d记录从而导致oplog迅速滑出时间窗口。
2. 外置方法
1. MMS/Cloud Manager
以前叫做MMS,监控功能免费,备份功能收费;前两个月更名为Cloud Manager并开始对监控功能收费,另外增加一个运维自动化机器人,挺傻瓜化的,有兴趣可以玩玩。不过既然收费,我相信我国国情决定了可能没有几个公司会愿意使用。因此不做重点介绍,只要知道它能提供任意时间点的数据恢复就可以了,功能强大,土豪公司欢迎使用。
2. 磁盘快照
常见的如LVM快照,是可以用来备份MongoDB的,但必须开启MongoDB的Journal并且Journal必须和数据文件在一个卷上。话说应该多数人都是开启Journal的吧?没有Journal的话断电是会丢失最多60s的数据的。
快照其实是一个较mongodump/mongorestore来得更快的备份方式,相当实用,但只能提供到备份时间点的数据恢复,作用有限。不展开细说,有兴趣可以查阅官方文档。理论上说,快照当然也可以结合oplog重放来达到point-in-time数据恢复的。但是本人没有亲身实验,有兴趣的朋友可以玩玩并做个介绍。
|






