|
随着业务对大数据技术需求的不断演变,分布式数据库在整个生态圈中的地位愈加重要,已可预见必将成为未来大数据技术发展的又一个核心,而其中OLAP(联机分析处理)显得尤其重要。
基本理论
数据库的基本理论ACID
原子性(Atomic)。整个事务中的所有操作要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
一致性(Consistent)。在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
隔离性(Isolated)。隔离状态执行事务,使它们好像是在给定时间内系统执行的唯一操作。如果有两个事务,运行在相同的时间内,执行相同的功能,事务的隔离性将确保每一事务在系统中认为只有该事务在使用系统。这种属性有时称为串行化,为了防止事务操作间的混淆,必须串行化或序列化请求,使得在同一时间仅有一个请求用于同一数据。
持久性(Durable)。在事务完成以后,该事务对数据库所作的更改便持久地保存在数据库之中,并不会被回滚。
对于ACID的实现方式主要有两个,一个是日志式的方式(Write ahead logging),几乎所有的数据库系统(MySQL、Oracle等)都基于日志的方式。另外一种是Shadow paging,代表的数据库主要是SQLite,Android或者iOS APP开发的话应该会比较了解,但大型的数据库都不会用到。
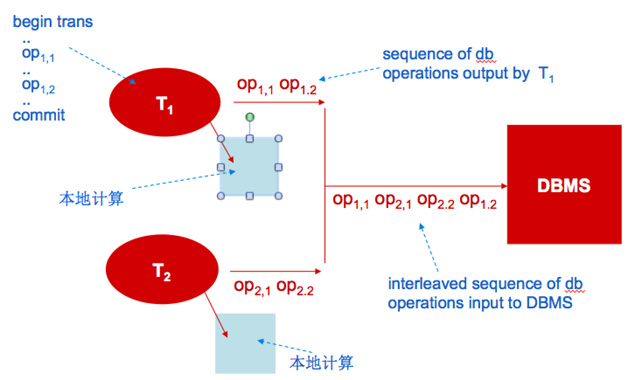
图1 事务隔离性一览
分布式数据库的CAP理论
一致性(C)。分布式系统中所有数据备份在同一时刻的值是否相同。
可用性(A)。当集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求(可用性不仅包括读,还有写)。
分区容忍性(P)。集群中的某些节点无法联系后,集群整体是否还能继续进行服务。
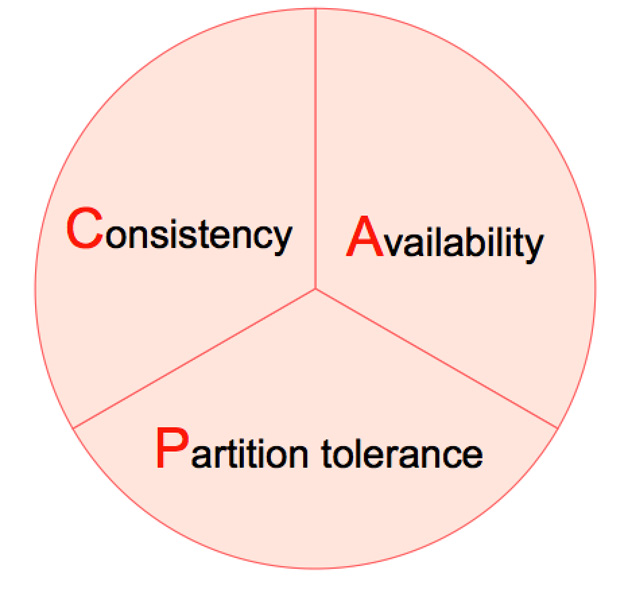
图2 CAP三大定律
NoSQL分类
如果同时满足这三点,成本将会非常高,所以建议根据业务的具体需求做好平衡选择。把NoSQL做一个简单分类将包括如下几种:
Key/Value 或 ‘the big hash table’。典型的有Amazon S3 (Dynamo)、Voldemort、Scalaris、Memcached (in-memory key/value store)、Redis等。
Schema-less。典型的有Cassandra (column-based)、CouchDB (document-based)、MongoDB(document-based)、Neo4J (graph-based)、HBase (column-based)、ElasticSearch(document-based)等。
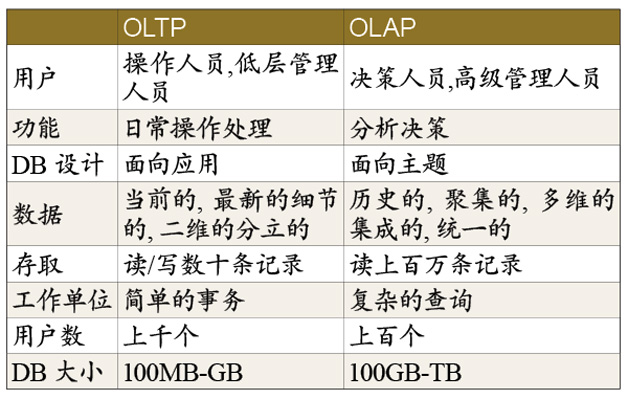
OLTP和OLAP的对比分析
目前分布式数据库主要分为两种场景――OLTP(联机事务处理)和OLAP(联机分析处理)。随着大数据技术发展,数据库选择越来越多,其主要差别包括:面向事务还是面向分析;数据内容是当前的、详细的数据还是历史的、汇总的数据;数据库设计是实体联系模型ER和面向应用的数据库设计,还是星型、雪花模型和面向主题的数据库设计等。前者指的是OLTP场景,后者指的是OLAP场景。
表1 OLTP和OLAP对比
基于分布式数据库的理论,不管是数据库的优化还是设计、使用,遇到的问题非常多。举例说,现在硬件发展很好,特别SSD,如果其设备性能远远没有达到,那么使用SSD的数据库性能该如何提高。如果只是为了满足业务当前的简单需求,可以把现在很多数据库的传输引擎存储直接换成SSD,可以快速地解决很大的问题。另外还有一个很经典的问题,怎么保证在高可靠的前提下提高数据库插入和查询性能。刚才说的是单机模式,多机的分布式模式下又该怎么提高数据调用性能,也有许多挑战。总之,一定要根据业务的需求来选择最合适自己的数据库系统。
分布式数据库实际案例
HBase
在HBase的设计原则中,每个列族可以包含任意多的列,每个列可以有任意多的版本,列只有在有值时才存在,列本身是排序的。
重点看一下Zookeeper的模型,它用了一个非常经典的模型叫Leader/Follower。举个例子说,在去餐厅吃饭时,进餐厅肯定有领班把你领过去,安排到某个座位,点菜则不是他的工作,而由其同事完成,这是非常传统的半同步模型。而Leader/Follower模型是领班把你领过去帮你点菜,他在之前会再选一个Follower做Leader,通过选举制来实现,这样会减少线程的调度,这对数据库的性能会有很大的提升。
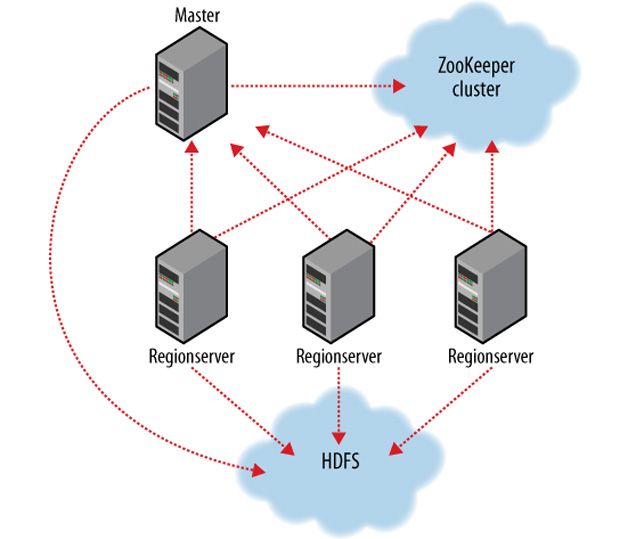
图3 HBase中的功能实现
ElasticSearch(ES)
对于分布式数据库里把ElasticSearch也作为一种分布式数据库是有原因的,如果需要快速查询,但列很多,HBase的SQL支持不太好,使用不方便。而ES对于前端工程师开发非常简单,不需要对分布式数据库内核了解很深就可以很快使用起来,而只需要了解RestfulAPI就可以了,并且也很方便。ES底层都是分布式的Lucene,如Github使用Elasticsearch搜索20TB的数据,包括13亿的文件。ES的模型比较清晰比较简单,就两个步骤,一个步骤是怎么把数据建索引,建完索引主要是做查询,怎么把SQL的语句做查询。
图4 ElasticSearch亮点
ES最重要的是建索引,每个的记录都会根据需求建索引,这么做有好有坏――如果突然来了100亿条记录,建索引的时间会很长,对于业务索引是不能忍受的。所以如果支持离线建立索引,后面实时增量建索引这样会更好,目前ES这个模型还不能支持。 但是ES时下已发展的比较成熟,现在能对接的接口都能支持,所以是非常方便的。
分布式数据库系统对比
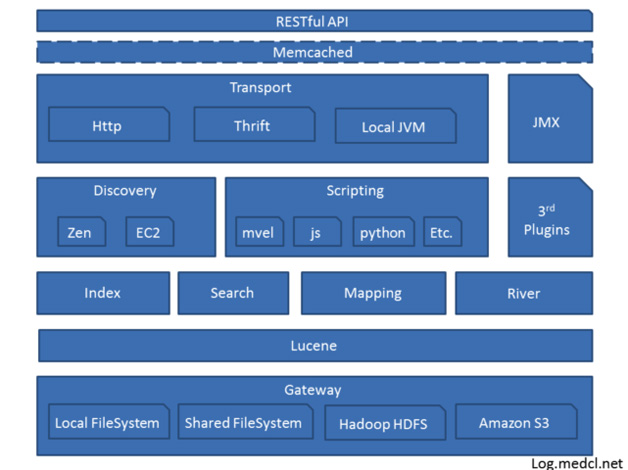
图5 ElasticSearch功能模块
这里主要对比Pinot和Druid,支持多维度实时查询的分布式系统。
表2 Druid和Pinot功能实现对比

由于Pinot跟ES系统架构很类似,而Pinot比Druid支持存储格式更多一些,所以我们用Pinot和ES做了一个性能测试对比,测试条件如下:
- 记录条数分为100亿以内和1000亿条
- 服务器数量为70台,配置为:CPU 12核,内存96G,硬盘48T
- 测试语句:select count(*) from test where age > 25 and gender > 0 and os > “500” and sc in (“0001009”,”0002036”,”0016030”,”…”) or bs>585 and group by age,gender,os,bs
- 总共12列:动态列为3列(多值列),普通列为9列
表3 ElasticSearch和Pinot百亿条检索对比

表4 ElasticSearch和Pinot千亿条检索对比

对于Pinot和ES有一个共性,他们都有多值列的属性,即类似的属性可以放入同一列,这样查的话大部分需要把一个列的数据查出来,从而更有益于性能。
真实案例分析
业务需求:
- 每天请求数超过 100 亿
- 每天增长超过 5TB 级数据
- 每天对几千亿条记录进行上 1000 种维度的计算
- 客户有流式、实时、离线需求
图6是系统数据流程。
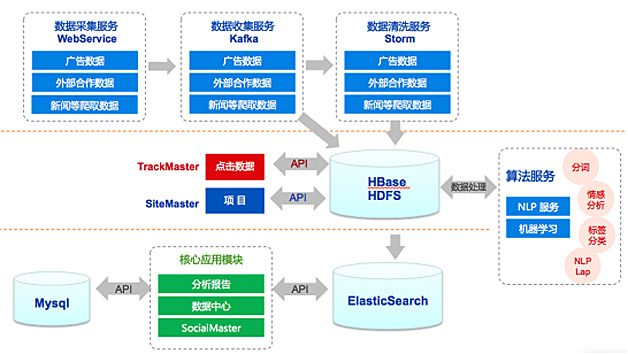
图6 系统数据流程
数据采集用WebService,如Nginx;数据收集服务用Kafka和Flume;数据清洗服务Storm,采用Storm主要有下面两个原因,业务需求在毫秒级需要;有严格要求的时间序列,如原来输入是1、2、3、4、5,输出还必须是1、2、3、4、5。其他用Spark Streaming将会比较好。
接下来把Kafka分流出来的数据对应每一条不同的业务,然后导入对应的存储,如HBase、HDFS等,通过不同的流来解决不同的业务问题,然后基于不同存储做各种算法分析;最后将各种结果数据导入ElasticSearch或者MySQL给前端做数据可视化。
通过阅读上述知识相信各位对分布式数据库的发展和不同系统的技术特点已经有了一定的了解,限于篇幅的原因,笔者以分享几个ES的使用心得结束:
- 用 ES 的 Alias 特性实现数据的水平扩展。
- 用 Kibana 分析和展现数据(ELK三剑客)可以满足很多公司业务80%以上的需求,ELK是指ElasticSearch、Logstash、Kibana,它们分别功能为:ElasticSearch是负责日志检索和分析;Logstash负责日志的收集,处理和储存;Kibana负责日志的可视化,建议用Kibana4版本。
- 多条件聚合查询,布尔查询。
- 定制分词插件(IK),实现对特殊字符的精确匹配,目前现在主流的搜索引擎在搜索关键词的时候对标点符号是忽略的,但是在实现一些对监控微博等社交数据时,如果微博里有很多符号,举例来说“:)”其实代表的是笑脸,而笑脸对于我们来判断正负面是非常有用的,所以判断正负面不只是语义分析的,还有对标点符号分析也非常重要。
|






