|
Greenplum 数据库是最先进的分布式开源数据库技术,主要用来处理大规模的数据分析任务,包括数据仓库、商务智能(OLAP)和数据挖掘等。自2015年10月正式开源以来,受到国内外业内人士的广泛关注。本文就社区关心的Greenplum数据库技术架构进行介绍。

一. Greenplum数据库简介
大数据是个炙手可热的词,各行各业都在谈。一谈到大数据,好多人认为就是Hadoop。实际上Hadoop只是大数据若干处理方案中的一个。现在的SQL、NoSQL、NewSQL、Hadoop等等,都能在不同层面或不同应用上处理大数据的某些问题。而Greenplum数据库做为一个分布式大规模并行处理数据库,在大多数情况下,更适合做大数据的存储引擎、计算引擎和分析引擎。
Greenplum数据库也简称GPDB。它拥有丰富的特性:
第一,完善的标准支持:GPDB完全支持ANSI SQL 2008标准和SQL OLAP 2003 扩展;从应用编程接口上讲,它支持ODBC和JDBC。完善的标准支持使得系统开发、维护和管理都大为方便。而现在的 NoSQL,NewSQL和Hadoop 对 SQL 的支持都不完善,不同的系统需要单独开发和管理,且移植性不好。
第二,支持分布式事务,支持ACID。保证数据的强一致性。
第三,做为分布式数据库,拥有良好的线性扩展能力。在国内外用户生产环境中,具有上百个物理节点的GPDB集群都有很多案例。
第四,GPDB是企业级数据库产品,全球有上千个集群在不同客户的生产环境运行。这些集群为全球很多大的金融、政府、物流、零售等公司的关键业务提供服务。
第五,GPDB是Greenplum(现在的Pivotal)公司十多年研发投入的结果。GPDB基于PostgreSQL 8.2,PostgreSQL 8.2有大约80万行源代码,而GPDB现在有130万行源码。相比PostgreSQL 8.2,增加了约50万行的源代码。
第六,Greenplum有很多合作伙伴,GPDB有完善的生态系统,可以与很多企业级产品集成,譬如SAS,Cognos,Informatic,Tableau等;也可以很多种开源软件集成,譬如Pentaho,Talend 等。
二. Greenplum架构
2.1 平台架构
图(1)是Greenplum数据库平台概括图。平台分为四个层次,我们依次从下往上看。
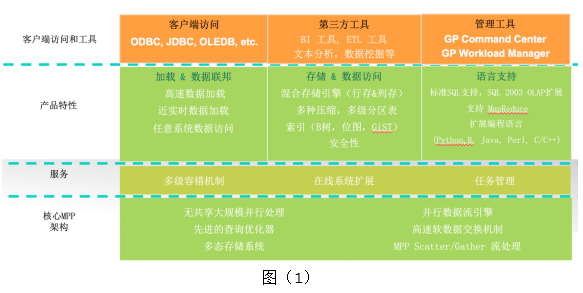
MPP核心架构
- GPDB是大规模无共享的处理架构,后面会专门介绍;
- 先进的并行优化器是性能突出的关键之一。GPDB有两个优化器,一个是基于PostgreSQL planner的优化器;一个是全新开发的ORCA优化器。ORCA是Greenplum 5年以前启动的全新项目,这个优化器经过几年的开发和测试之后,最近已经成为GPDB企业版本的默认优化器。
- GPDB的存储引擎支持多态存储,一个表的数据可以根据访问模式的不同使用不同的存储方式。存储方式对用户透明,执行查询时,不用关心待访问的数据使用的存储模式,优化器会自动选择最佳查询计划。
- 分布式数据库中,某些操作(例如跨节点关联)需要多个节点间进行数据交换。GPDB的并行数据库流引擎,可以根据数据的特点,例如分布方式、数据量等选择最合适的数据流操作符。目前GPDB支持两种数据流操作符:重分发(Redistribution)和广播(Broadcast)。重分发根据数据的哈希值重新分发到各个数据节点上,适用于数据量大的情况;广播则将数据发送给所有数据节点,适用于数据量较小的情况,例如维度表。
- 软件交换机是GPDB的一个重要组件,软件交换机可以在各个数据节点间及与主节点间建立可靠的UDP数据通讯机制,是实现高效数据流的核心。
- Scatter/Gather 流引擎是专为并行数据加载和导出而设计,Scatter指数据通过并行加载服务器并行分散到各个数据节点,Gather指数据在 GPDB内部可以根据分布策略按需并行分发。
服务层
- GPDB支持多级容错机制和高可用:?
o 主节点(Master)高可用:为了避免主节点单点故障,可以设置一个主节点的副本(称为 Standby Master),他们之间通过流复制技术实现同步复制。当主节点发生故障时,从节点成为主节点,处理用户请求并协调查询执行。它们之间通过心跳检测故障。?
o 数据节点(Segment)高可用:每个数据节点都可以配备一个镜像,它们之间通过文件操作级别的同步实现数据的同步复制(称为filerep技术)。数据节点上建议使用RAID5磁盘,以进一步提高数据的高可用。故障检测进程(ftsprobe)定期发送心跳给各个数据节点。当某个节点发生故障时,GPDB会自动进行故障切换。?
o 网络高可用:为了避免网络的单点故障,每个主机配置多个网口,并使用多个交换机避免网络故障时造成整个服务不可用。
- 在线扩展:数据量增大,现有集群不能满足需求时,可以对GPDB数据库进行动态扩展。扩展过程中,业务可以继续运行,不需要宕机。
- 任务管理是指对资源的管理和使用情况的管理。
产品特性
- 数据加载在后面会专门介绍。
- 数据联邦是比较有意思的,最近“数据湖泊”这个词非常火热,数据湖泊的目的是不需再对数据像以前那样经过定制,生成特定的业务报表;而是保存原始数据,什么时候想分析就从原始数据上直接处理。GBDB可以实现数据湖泊(我们称之为数据联邦),它能访问和处理数据中心里面的所有数据,不管你的数据是在Hadoop、在文件系统上、还是在其他数据库中,Greenplum可以使用一个SQL在保证ACID的前提下访问所有数据。
- GPDB即支持行存,也支持列存。还为不需更新的数据存储和处理进行了专门的优化。
- 支持多种压缩方法,包括QuickLZ,Zlib,RLE 等。
- 支持多级分区表,分区支持多种模式,包括范围,列表等。
- 支持B树、位图和GiST 等索引
- GPDB认证机制支持多种方式,包括LDAP和Kerberos等。通过访问控制列表(ACL),可以实现灵活的基于角色的安全控制。
- 扩展语言支持:GPDB 支持使用多种流行语言实现用户自定义函数(UDF,类似于Oracle的存储过程),包括 Python,R,Java,Perl,C/C++ 等。
- 地理信息处理:通过集成PostGIS,GPDB支持对地理信息进行存储和分析。
- 内建数据挖掘算法库:通过MADLib(现在是Apache孵化项目)算法库,可以内建几十种常见的数据分析和挖掘算法到GPDB数据库中,包括逻辑回归,决策树,随机森林等。不需要写任何算法代码,通过SQL就可以使用其中的所有算法。
- 文本检索:通过GPText扩展,GPDB可以支持高效灵活丰富的全文检索功能。与 MADLib 合用,可以进行并行文本分析和挖掘。
客户端访问和工具
通过psql命令行工具可以访问GPDB数据库的所有功能,此外还提供了ODBC、JDBC、OLEDB、libpq等应用编程接口。
数据库或者数据集群的管理工具非常重要,GPDB提供了图形化的管理工具GPCC(Greenplum Command Center),帮你管理状态,监控资源使用情况。
Greenplum Workload Manager是刚刚发布的新产品,用以实现基于规则的资源管理。它支持自定义规则,当某个SQL满足规则描述的条件时会执行某些操作。比如你可以定义规则自动取消消耗CPU资源达50%以上的查询。
2.2 大规模并行处理(MPP)无共享架构
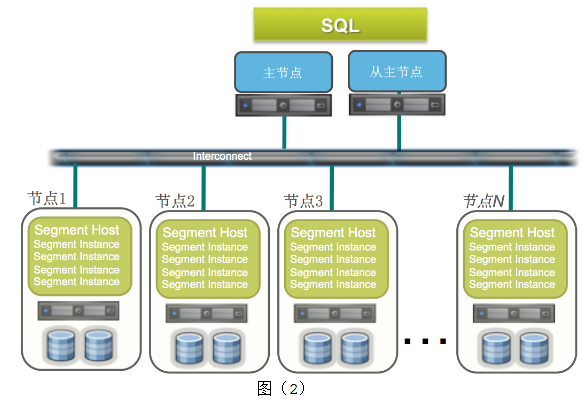
MPP 是Greenplum数据库最突出的特色。现在很流行MPP这个词,我们可以看一下它是什么意思。下边图(2)中,主节点有两个,一个是主节点,一个是从主节点。通过软交换机制,也就是通过高速网络,主节点连到数据节点。每个数据节点有自己的CPU,自己的内存,自己的硬盘,他们唯一共享的就是网络。这也是称为无共享架构的原因。这种架构的好处是集群是分布式的环境,数据可以分布在很多节点上进行并行处理,可以做到线性扩展。
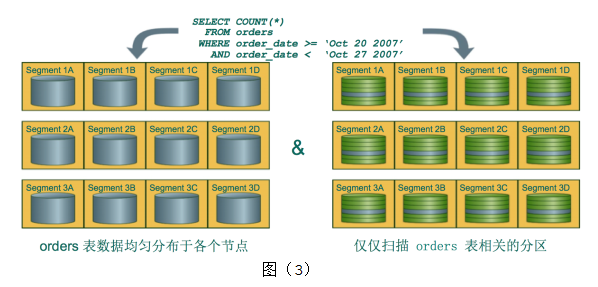
在分布式数据库中,性能好坏的最重要因素是数据分布是否均匀。如果数据分布不均匀,有的节点上数据非常多,有的节点数据很少,这样会出现短板效应,整个SQL的效率不会很好。Greenplum支持多种数据分布的策略,默认使用主键或者第一个字段进行哈希分布,还支持随机分布。除了横向上数据可以按节点分布之外,在某个节点上还可以对数据进行分区。分区的规则比较灵活,可以按照范围分区,也可以按照列表值分区,如图(3)。
2.3 并行查询计划和执行
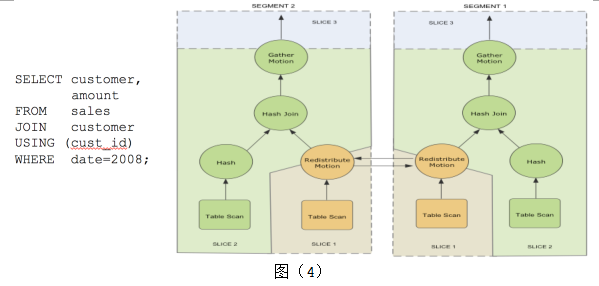
下面是个简单的SQL,如图(4),从两张表中找到2008年的销售数据。图中右边是这个SQL的查询计划。从生成的查询计划树中看到有三种不同的颜色,颜色相同表示做同一件事情,我们称之为分片/切片(Slice)。最下层的橙色切片中有一个重分发节点,这个节点将本节点的数据重新分发到其他节点上。中间绿色切片表示分布式数据关联(HashJoin)。最上面切片负责将各个数据节点收到的数据进行汇总。
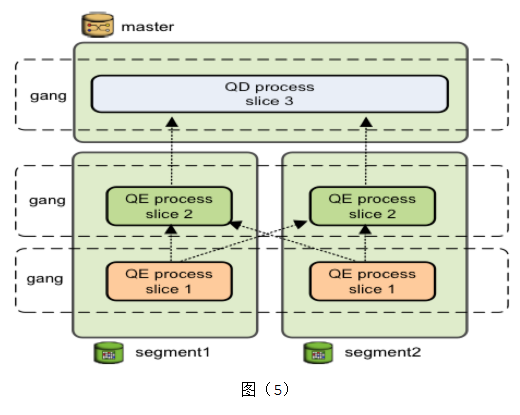
然后看看这个查询计划的执行,如图(5)。主节点(Master)上的调度器(QD)会下发查询任务到每个数据节点,数据节点收到任务后(查询计划树),创建工作进程(QE)执行任务。如果需要跨节点数据交换(例如上面的HashJoin),则数据节点上会创建多个工作进程协调执行任务。不同节点上执行同一任务(查询计划中的切片)的进程组成一个团伙(Gang)。数据从下往上流动,最终Master返回给客户端。
2.4 多态存储
上面介绍了GPDB的特点和SQL执行计划以及执行过程,那数据在每个节点上到底怎么样存储?
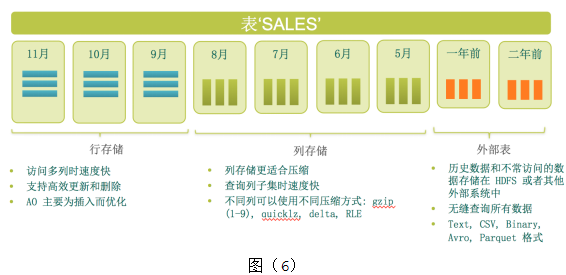
Greenplum提供称为“多态存储”的灵活存储方式。多态存储可以根据数据热度或者访问模式的不同而使用不同的存储方式。一张表的不同数据可以使用不同的物理存储方式,如图(6)。支持的存储方式包含:
- 行存储:行存储是传统数据库常用的存储方式,特点是访问比较快,多列更新比较容易。
- 列存储:列存储按列保存,不同列的数据存储在不同的地方(通常是不同文件中)。适合一次只访问宽表中某几个字段的情况。列存储的另外一个优势是压缩比高。
- 外部表:数据保存在其他系统中例如HDFS,数据库只保留元数据信息。
2.5 大规模并行数据加载
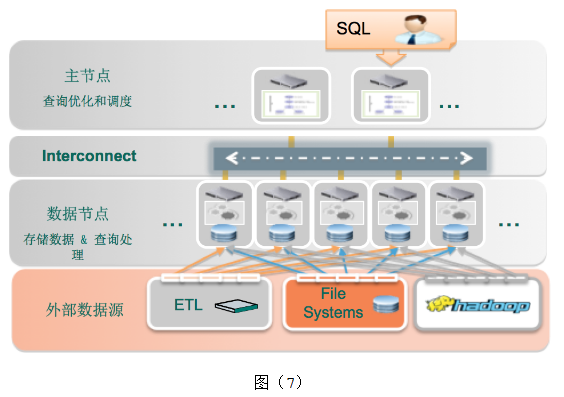
作为一个数据库,一定会保存和处理数据。那数据来源于什么地方?Oracle这样的数据库里面的数据多是客户生成的,譬如你银行转账、淘宝订单等。对于数据分析型的数据库,其源数据通常是在其他系统中,而且数据量很大。这样数据加载的能力就变得非常重要。Greenplum提供了非常好的数据加载方案,支持高速的加载各种数据源的不同数据格式的数据,如图(7)。
- 并行数据加载:因为是并行数据加载,所以性能非常好。Greenplum有叫DCA的一体机产品,第一代DCA可以做到10TB/小时;第二代为16TB/小时。第三代很快就要发布了,速度会更快。
- 数据源和数据格式:数据源支持Hadoop,文件系统,数据库,还有 ETL管理的数据。数据格式支持文本,CSV,Parquet,Avro等。
三. Greenplum核心组件
Greenplum 数据库包括以下核心组件:
- 解析器:主节点收到客户端请求后,执行认证操作。认证成功建立连接后,客户端可以发送查询给数据库。解析器负责对收到的查询SQL字符串进行词法解析、语法解析,并生成语法树。
- 优化器:优化器对解析器的结果进行处理,从所有可能的查询计划中选择一个最优或者接近最优的计划,生成查询计划。查询计划描述了如何执行一个查询,通常以树形结构描述。Greenplum最新的优化器叫 ORCA,关于 ORCA,可以从 ACM 论文中获得详细信息。(http://dl.acm.org/citation.cfm?id=2595637&dl=ACM&coll=DL&CFID=569750122&CFTOKEN=89888184)
- 调度器(QD):调度器发送优化后的查询计划给所有数据节点(Segments)上的执行器(QE)。调度器负责任务的执行,包括执行器的创建、销毁、错误处理、任务取消、状态更新等。
- 执行器(QE):执行器收到调度器发送的查询计划后,开始执行自己负责的那部分计划。典型的操作包括数据扫描、哈希关联、排序、聚集等。
- Interconnect:负责集群中各个节点间的数据传输。
- 系统表:系统表存储和管理数据库、表、字段的元数据。每个节点上都有相应的拷贝。
- 分布式事务:主节点上的分布式事务管理器协调数据节点上事务的提交和回滚操作,由两阶段提交(2PC)实现。每个数据节点都有自己的事务日志,负责自己节点上的事务处理。
四、Greenplum开源
2015年3月份,Pivotal宣布了Greenplum的开源计划,经过6个月紧锣密鼓的工作,于10月27号正式开源。官方网站为http://greenplum.org。许可证书使用Apache 2许可证。
Greenplum 开源社区提供了运行环境沙盒以及使用教程,里面包含了Greenplum数据库的一些主要特性。从https://github.com/greenplum-db/gpdb-sandbox-tutorials可以下载沙盒和教程。
有关Greenplum数据库使用和开发的任何问题都可以去邮件列表讨论:邮件列表有两个:gpdb-dev@greenplum.org 和gpdb-user@greenplum.org。
源代码位于https://github.com/greenplum-db/gpdb,开源不到两个月就有1187个收藏,256个fork,超过150个pull request,其中136个pull request 已经关闭。贡献者中除了包含Pivotal的员工外,还有来自全球(包括中国、美国、日本和欧洲)的社区开发人员。关于从源代码编译和安装Greenplum数据库,可以参考:http://gpdb.rocks/gpdb/2015/10/29/how-to-build-gpdb.html
作者简介:姚延栋 Pivotal研发总监,2005年毕业于中科院软件所。曾在Sun Microsystems、Symantec工作多年,2010年加入Greenplum(现在的Pivotal),负责中国研发团队。
|






