| 我们基于Hadoop
1.2.1源码分析MapReduce V1的处理流程。MapReduce V1实现中,主要存在3个主要的分布式进程(角色):JobClient、JobTracker和TaskTracker,我们主要是以这三个角色的实际处理活动为主线,并结合源码,分析实际处理流程。
上一篇我们分析了Job提交过程中JobClient端的处理流程(详见文章
MapReduce V1:Job提交流程之JobClient端分析),这里我们继续详细分析Job提交在JobTracker端的具体流程。通过阅读源码可以发现,这部分的处理逻辑还是有点复杂,经过梳理,更加细化清晰的流程,如下图所示:
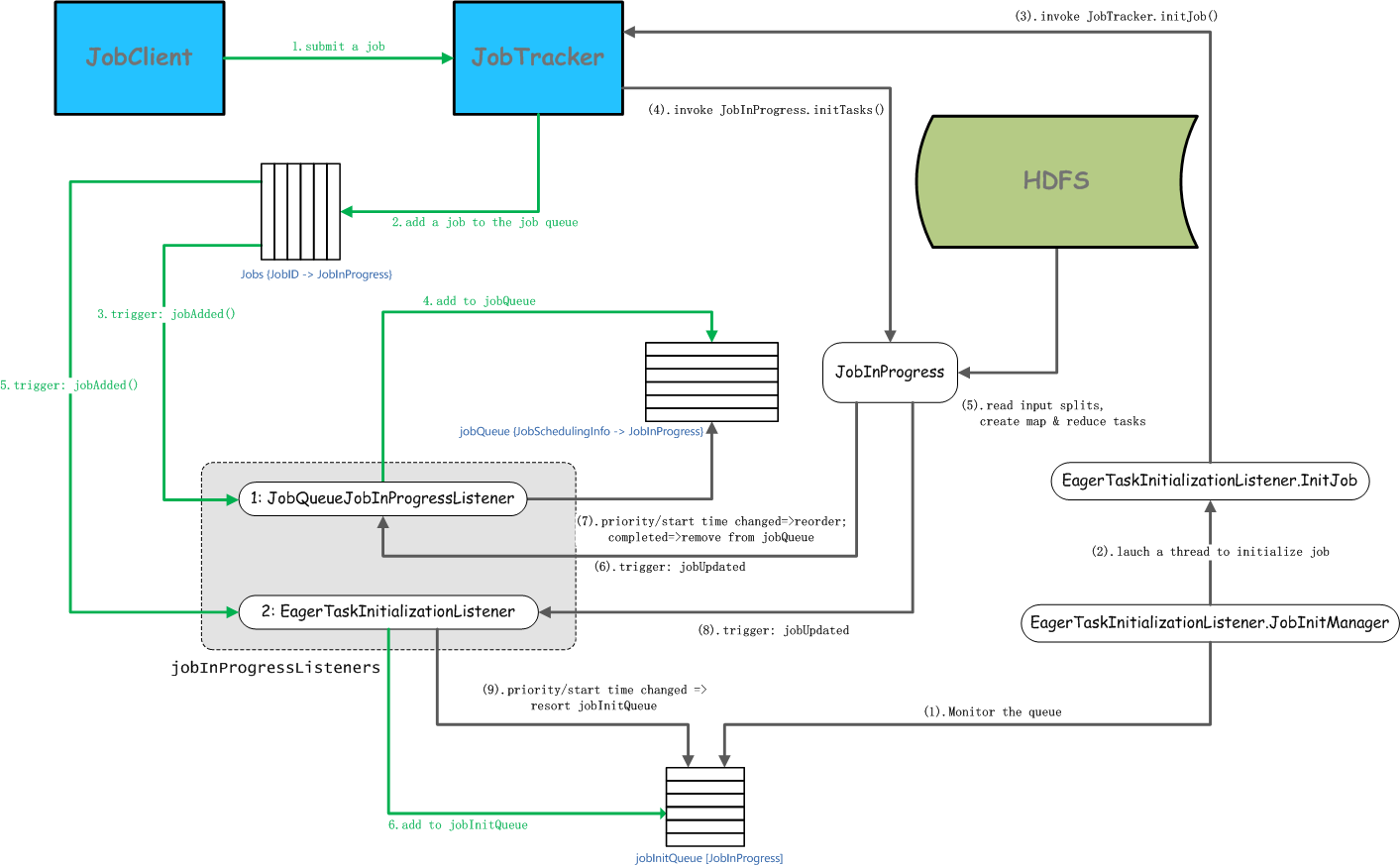
上图中主要分为两大部分:一部分是JobClient基于RPC调用提交Job到JobTracker后,在JobTracker端触发TaskScheduler所注册的一系列Listener进行Job信息初始化;另一部分是JobTracker端监听Job队列的线程,监听到Job状态发生变更触发一系列Listener更新状态。我们从这两个方面展开分析:
JobTracker接收Job提交
JobTracker接收到JobClient提交的Job,在JobTracker端具体执行流程,描述如下:
JobClient基于JobSubmissionProtocol协议远程调用JobTracker的submitJob方法提交Job
JobTracker接收提交的Job,创建一个JobInProgress对象,将其放入内部维护的Map<JobID,
JobInProgress> jobs队列中
触发JobQueueJobInProgressListener
执行JobQueueJobInProgressListener的jobAdded方法,创建JobSchedulingInfo对象,并放入到JobQueueJobInProgressListener内部维护的Map<JobSchedulingInfo,
JobInProgress> jobQueue队列中
触发EagerTaskInitializationListener
执行EagerTaskInitializationListener的jobAdded方法,将JobInProgress对象加入到List<JobInProgress>
jobInitQueue队列中
在JobTracker端使用TaskScheduler进行Job/Task的调度,可以通过mapred.jobtracker.taskScheduler配置所使用的TaskScheduler实现类,默认使用的实现类JobQueueTaskScheduler,如下所示:
// Create the scheduler
2
Class<? extends TaskScheduler> schedulerClass
3
= conf.getClass("mapred.jobtracker.taskScheduler", JobQueueTaskScheduler.class, TaskScheduler.class);
4
taskScheduler = (TaskScheduler) ReflectionUtils.newInstance(schedulerClass, conf);
|
如果想要使用其他的TaskScheduler实现,可以在mapred-site.xml中配置mapred.jobtracker.taskScheduler的属性值,覆盖默认的调度策略即可。
在JobQueueTaskScheduler实现类中,注册了2个JobInProgressListener,JobInProgressListener是用来监听由JobClient端提交后在JobTracker端Job(在JobTracker端维护的JobInProgress)生命周期变化,并触发相应事件(jobAdded/jobUpdated/jobRemoved)的,如下所示:
01
protected JobQueueJobInProgressListener jobQueueJobInProgressListener;
02
protected EagerTaskInitializationListener eagerTaskInitializationListener;
03
private float padFraction;
04
05
public JobQueueTaskScheduler() {
06
this.jobQueueJobInProgressListener = new JobQueueJobInProgressListener();
07
}
08
09
@Override
10
public synchronized void start() throws IOException {
11
super.start();
12
taskTrackerManager.addJobInProgressListener(jobQueueJobInProgressListener); // taskTrackerManager是JobTracker的引用
13
eagerTaskInitializationListener.setTaskTrackerManager(taskTrackerManager);
14
eagerTaskInitializationListener.start();
15
taskTrackerManager.addJobInProgressListener(eagerTaskInitializationListener);
16
}
|
JobTracker维护一个List<JobInProgressListener> jobInProgressListeners队列,在TaskScheduler(默认JobQueueTaskScheduler
)启动的时候向JobTracker注册。在JobClient提交Job后,在JobTracker段创建一个对应的JobInProgress对象,并将其放入到jobs队列后,触发这一组JobInProgressListener的jobAdded方法。
JobTracker管理Job提交
JobTracker接收到提交的Job后,需要对提交的Job进行初始化操作,具体流程如下所示:
EagerTaskInitializationListener.JobInitManager线程监控EagerTaskInitializationListener内部的List<JobInProgress>
jobInitQueue队列
加载一个EagerTaskInitializationListener.InitJob线程去初始化Job
在EagerTaskInitializationListener.InitJob线程中,调用JobTracker的initJob方法初始化Job
调用JobInProgress的initTasks方法初始化该Job对应的Tasks
从HDFS读取该Job对应的splits信息,创建MapTask和ReduceTask(在JobTracker端维护的Task实际上是TaskInProgress)
Job状态变更,触发JobQueueJobInProgressListener
如果Job优先级(Priority)/开始时间发生变更,则对Map<JobSchedulingInfo,
JobInProgress> jobQueue队列进行重新排序;如果Job完成,则将Job从jobQueue队列中移除
Job状态变更,触发EagerTaskInitializationListener
如果Job优先级(Priority)/开始时间发生变更,则对List<JobInProgress>
jobInitQueue队列进行重新排序
下面,我们分析的Job初始化,以及Task初始化,都是在JobTracker端执行的工作,主要是为了管理Job和Task的运行,创建了对应的数据结构,Job对应JobInProgress,Task对应TaskInProgress。我们分析说明如下:
Job初始化
JobTracker接收到JobClient提交的Job,在放到JobTracker的Map<JobID,
JobInProgress> jobs队列后,触发2个JobInProgressListener执行jobAdded方法,首先会放到EagerTaskInitializationListener的List<JobInProgress>
jobInitQueue队列中。在EagerTaskInitializationListener内部,有一个内部线程类JobInitManager在监控jobInitQueue队列,如果有新的JobInProgress对象加入到队列,则取出并启动一个新的初始化线程InitJob去初始化该Job,代码如下所示:
class JobInitManager implements Runnable {
02
03
public void run() {
04
JobInProgress job = null;
05
while (true) {
06
try {
07
synchronized (jobInitQueue) {
08
while (jobInitQueue.isEmpty()) {
09
jobInitQueue.wait();
10
}
11
job = jobInitQueue.remove(0); // 取出JobInProgress
12
}
13
threadPool.execute(new InitJob(job)); // 创建一个InitJob线程去初始化该JobInProgress
14
} catch (InterruptedException t) {
15
LOG.info("JobInitManagerThread interrupted.");
16
break;
17
}
18
}
19
LOG.info("Shutting down thread pool");
20
threadPool.shutdownNow();
21
}
22
}
|
然后,在InitJob线程中,调用JobTracker的initJob方法初始化Job,如下所示:
class InitJob implements Runnable {
02
03
private JobInProgress job;
04
05
public InitJob(JobInProgress job) {
06
this.job = job;
07
}
08
09
public void run() {
10
ttm.initJob(job); // TaskTrackerManager ttm,调用JobTracker的initJob方法初始化
11
}
12
}
|
JobTracker中的initJob方法的主要逻辑,如下所示:
JobStatus prevStatus = (JobStatus)job.getStatus().clone();
02
LOG.info("Initializing " + job.getJobID());
03
job.initTasks(); // 调用JobInProgress的initTasks方法初始化Task
04
// Inform the listeners if the job state has changed
05
// Note : that the job will be in PREP state.
06
JobStatus newStatus = (JobStatus)job.getStatus().clone();
07
if (prevStatus.getRunState() != newStatus.getRunState()) {
08
JobStatusChangeEvent event =
09
new JobStatusChangeEvent(job, EventType.RUN_STATE_CHANGED, prevStatus,
10
newStatus);
11
synchronized (JobTracker.this) {
12
updateJobInProgressListeners(event); // 更新Job相关队列的状态
13
}
14
}
|
实际上,在JobTracker中的initJob方法中最核心的逻辑,就是初始化组成该Job的MapTask和ReduceTask,它们在JobTracker端都抽象为TaskInProgress。
初始化Task
在JobClient提交Job的过程中,已经将该Job所对应的资源复制到HDFS,在JobTracker端需要读取这些信息来创建MapTask和ReduceTask。我们回顾一下:默认情况下,split和对应的元数据存储路径分别为/tmp/hadoop/mapred/staging/${user}/.staging/${jobid}/job.split和/tmp/hadoop/mapred/staging/${user}/.staging/${jobid}/job.splitmetainfo,在创建MapTask和ReduceTask只需要split的元数据信息即可,我们看一下job.splitmetainfo文件存储的数据格式如下图所示:
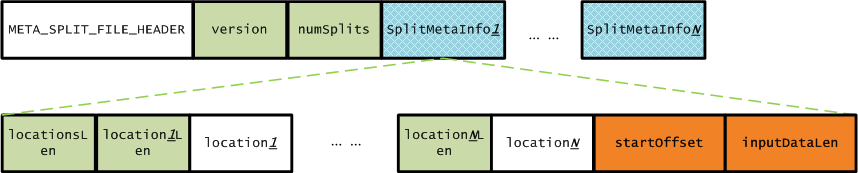
上图中,META_SPLIT_FILE_HEADER的值为META-SPL,版本version的值为1,numSplits的值根据实际Job输入split大小计算的到,SplitMetaInfo包括的信息为split所存放的节点位置个数、所有的节点位置信息、split在文件中的起始偏移量、split数据的长度。有了这些描述信息,JobTracker就可以知道一个Job需要创建几个MapTask,实现代码如下所示:
TaskSplitMetaInfo[] splits = createSplits(jobId);
2
...
3
numMapTasks = splits.length;
4
...
5
maps = new TaskInProgress[numMapTasks]; // MapTask在JobTracker的表示为TaskInProgress
6
for(int i=0; i < numMapTasks; ++i) {
7
inputLength += splits[i].getInputDataLength();
8
maps[i] = new TaskInProgress(jobId, jobFile, splits[i], jobtracker, conf, this, i, numSlotsPerMap);
9
}
|
而ReduceTask的个数,根据用户在配置Job时指定的Reduce的个数,创建ReduceTask的代码,如下所示:
//
2
// Create reduce tasks
3
//
4
this.reduces = new TaskInProgress[numReduceTasks];
5
for (int i = 0; i < numReduceTasks; i++) {
6
reduces[i] = new TaskInProgress(jobId, jobFile, numMapTasks, i, jobtracker, conf, this, numSlotsPerReduce);
7
nonRunningReduces.add(reduces[i]);
8
}
|
除了创建MapTask和ReduceTask之外,还会创建setup和cleanup task,每个Job的MapTask和ReduceTask各对应一个,即共计2个setup
task和2个cleanup task。setup task用来初始化MapTask/ReduceTask,而cleanup
task用来清理MapTask/ReduceTask。创建setup和cleanup task,代码如下所示:
// create cleanup two cleanup tips, one map and one reduce.
02
cleanup = new TaskInProgress[2]; // cleanup task,map对应一个,reduce对应一个
03
04
// cleanup map tip. This map doesn't use any splits. Just assign an empty split.
05
TaskSplitMetaInfo emptySplit = JobSplit.EMPTY_TASK_SPLIT;
06
cleanup[0] = new TaskInProgress(jobId, jobFile, emptySplit, jobtracker, conf, this, numMapTasks, 1);
07
cleanup[0].setJobCleanupTask();
08
09
// cleanup reduce tip.
10
cleanup[1] = new TaskInProgress(jobId, jobFile, numMapTasks, numReduceTasks, jobtracker, conf, this, 1);
11
cleanup[1].setJobCleanupTask();
12
13
// create two setup tips, one map and one reduce.
14
setup = new TaskInProgress[2]; // setup task,map对应一个,reduce对应一个
15
16
// setup map tip. This map doesn't use any split. Just assign an empty split.
17
setup[0] = new TaskInProgress(jobId, jobFile, emptySplit, jobtracker, conf, this, numMapTasks + 1, 1);
18
setup[0].setJobSetupTask();
19
20
// setup reduce tip.
21
setup[1] = new TaskInProgress(jobId, jobFile, numMapTasks, numReduceTasks + 1, jobtracker, conf, this, 1);
22
setup[1].setJobSetupTask();
|
一个Job在JobInProgress中进行初始化Task,这里初始化Task使得该Job满足被调度的要求,比如,知道一个Job有哪些Task组成,每个Task对应哪个split等等。在初始化完成后,置一个Task初始化完成标志,如下所示:
synchronized(jobInitKillStatus){
02
jobInitKillStatus.initDone = true;
03
04
// set this before the throw to make sure cleanup works properly
05
tasksInited = true; // 置Task初始化完成标志
06
07
if(jobInitKillStatus.killed) {
08
throw new KillInterruptedException("Job " + jobId + " killed in init");
09
}
10
}
|
在置tasksInited = true;后,该JobInProgress就可以被TaskScheduler进行调度了,调度时,是以Task(MapTask/ReduceTask)为单位分派给TaskTracker。而对于哪些TaskTracker可以运行Task,需要通过TaskTracker向JobTracker周期性发送的心跳得到TaskTracker的健康状况信息、节点资源信息等来确定,是否该TaskTracker可以运行一个Job的一个或多个Task。
|







