| 我们基于Hadoop
1.2.1源码分析MapReduce V1的处理流程。在MapReduce程序运行的过程中,JobTracker端会在内存中维护一些与Job/Task运行相关的信息,了解这些内容对分析MapReduce程序执行流程的源码会非常有帮助。
在编写MapReduce程序时,我们是以Job为单位进行编程处理,一个应用程序可能由一组Job组成,而MapReduce框架给我们暴露的只是一些Map和Reduce的函数接口,在运行期它会构建对应MapTask和ReduceTask,所以我们知道一个Job是由一个或多个MapTask,以及0个或1个ReduceTask组成。而对于MapTask,它是根据输入的数据文件的的逻辑分片(InputSplit)而定的,通常有多少个分片就会有多少个MapTask;而对于ReduceTask,它会根据我们编写的MapReduce程序配置的个数来运行。
有了这些信息,我们能够预想到,在Job运行过程中,无非也需要维护与这些Job/Task相关的一些状态信息,通过一定的调度策略来管理Job/Task的运行。这里,我们主要关注JobTracker端的一些非常有用的数据结构:JobTracker、JobInProgress、TaskInProgress,来熟悉各种数据结构的定义及作用。
数据结构总体抽象
MapReduce框架就为了运行Job,所以我们基于Job的抽象来对JobTracker端的相关对象进行抽象,总体上理解它们之间的关系,如下图所示:
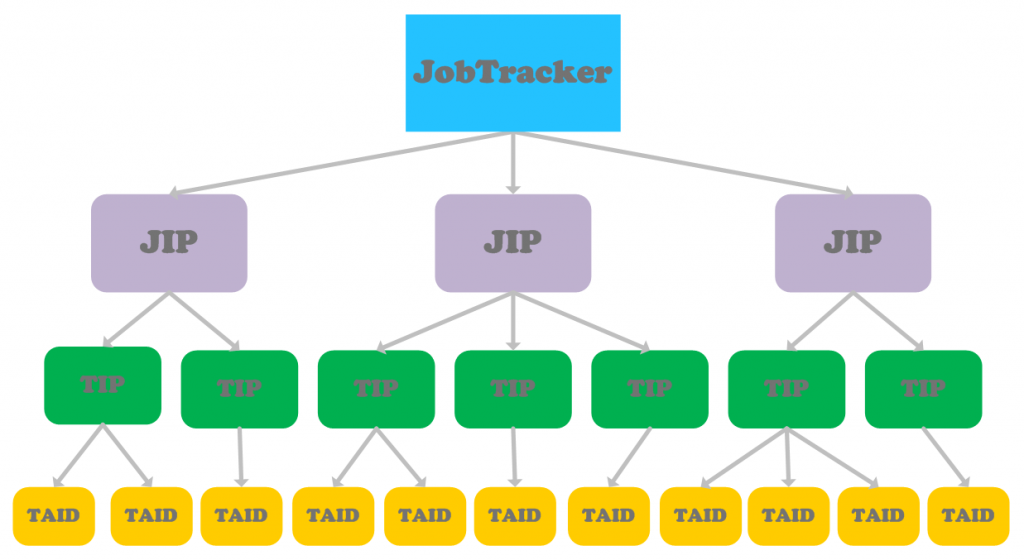
在JobTracker端,通过维护JobInProgress的信息来跟踪Job的运行生命周期,那么,JobTracker端肯定有一个用来维护所有Job状态的JobInProgress对象集合。而Job又是由Task组成,所以自然而然JobInProgress中应该有对Task运行状态的维护,Task的状态在JobTracker端通过TaskInProgress来抽象。一个Task可能运行失败,所以可能经过多次运行才能成功,而每一次运行会对应一个TaskAttempID,那么一个TaskInProgress又可能对应着多个TaskAttempID。
TaskInProgress数据结构
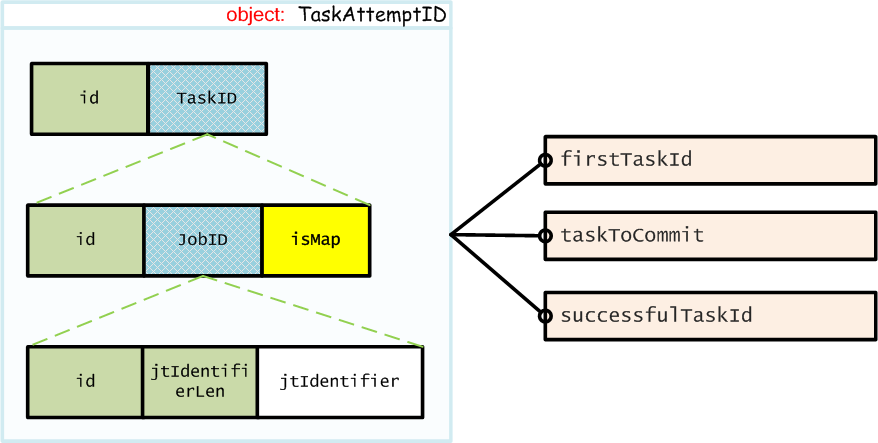
TaskAttemptID结构
一个TaskInProgress结构中包含了3个TaskAttemptID类型的数据,如下图所示:
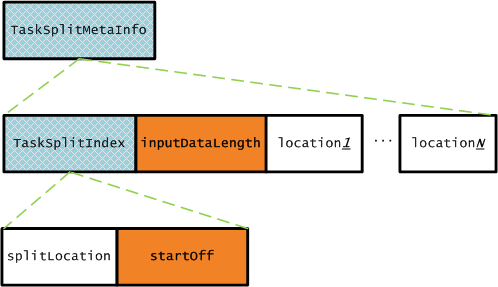
TaskSplitMetaInfo结构
JobTracker会创建每一个Task需要运行Split的信息,包含了该Split所在的位置信息、起始偏移量、总输入字节数,结构图如下所示:
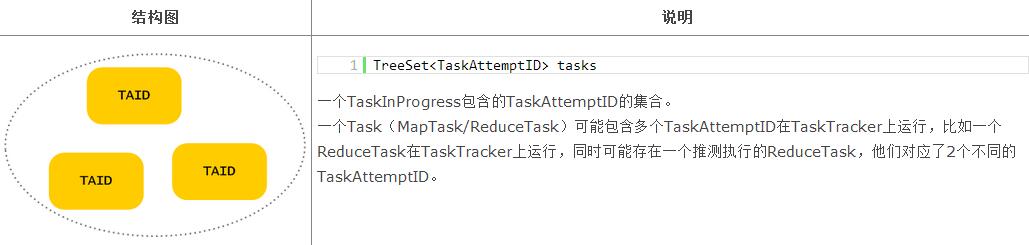
其他结构
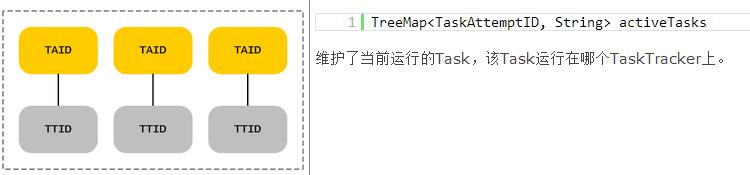


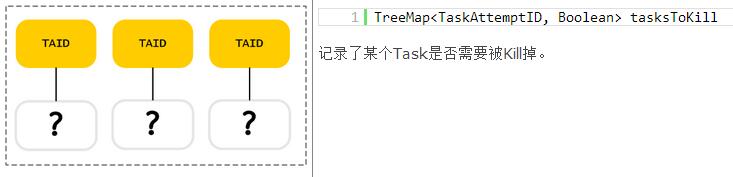

JobInProgress数据结构
JobID结构
JobID的结构,如下图所示:

上图中jtIdentifier的值为job,它是组成一个Job的ID字符串的前缀,唯一标识一个Job的完整ID的组成,如下所示:
job_<JobTracker启动时间字符串>_<序号> |
例如,一个Job的ID字符串为job_200912121733_0002 。
JobProfile结构
JobProfile描述了一个Job的基本信息,它的结构,如下图所示:

通过上图可以看出,JobProfile包含了一个Job的如下信息:

组成Job的Task的信息
一个Job可能包含多个Task(MapTask/ReduceTask),每个Task在JobTracker端使用TaskInProgress结构来跟踪Task的信息,一个Job由下面4组结构来表示这些信息,如下图所示:
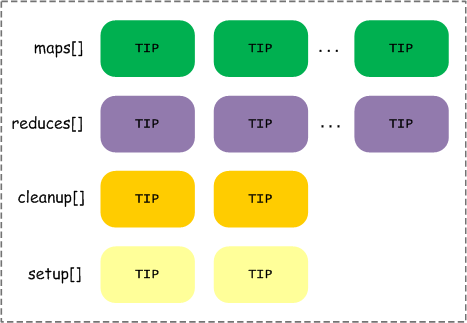
上图中出现了4种类型的Task,我们需要明白每种Task的作用是什么。一个Job在调度时,需要分解为上述4种类型的Task,基于类型来说明,一个Job对应的这4种类型的Task的运行顺序为:setup
task、MapTask、ReduceTask、cleanup task,其中setup task和cleanup
task运行也需要申请slot来运行,map setup运行需要占用Map Slot,而reduce setup运行需要占用Reduce
Slot,对于cleanup task也是类似的。
这里说明一下cleanup task和setup task的作用。其实在JobTracker端来看,setup
task、cleanup task都与MapTask、ReduceTask使用相同的TaskInProgress数据结构来维护状态。setup
task主要是在一个Job开始运行之前,初始化一些状态信息,由于存在MapTask和ReduceTask两种计算型Task,那么对应就存在map
setup task和reduce setup task两种setup task。cleanup task主要是在一个Job运行结束后,负责清理在TaskTracker上运行的Task生成的临时数据,更新TaskTracker端维护的相关对象的状态信息,等等,类似地也存在map
cleanup task和reduce cleanup task两种cleanup task。
JobStatus结构
JobStatus结构定义一个Job的当前状态信息,如下图所示:

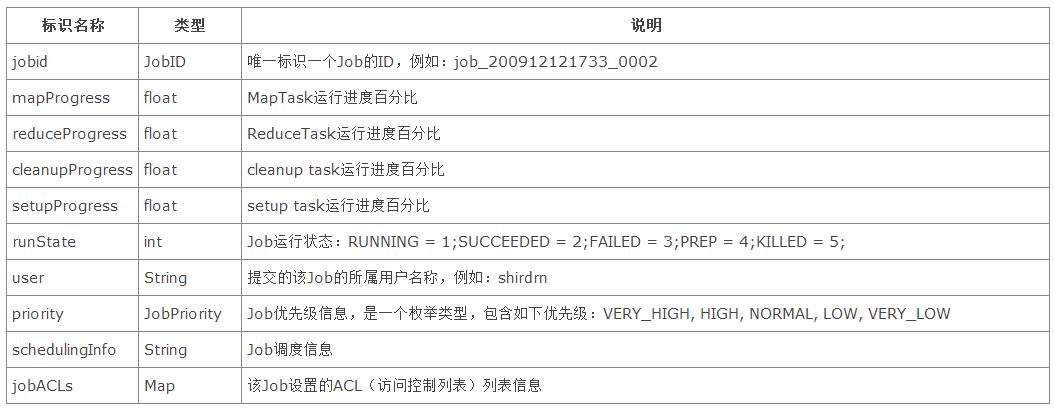
除了定义Job运行状态信息,还包含了其他信息,如下表所示:
Counters结构
Counters包含了一组计数器,用来跟踪一个Job运行的信息,结构如下图所示:
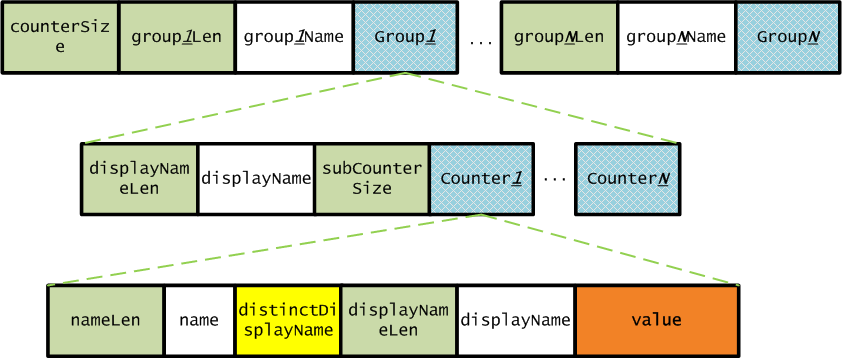
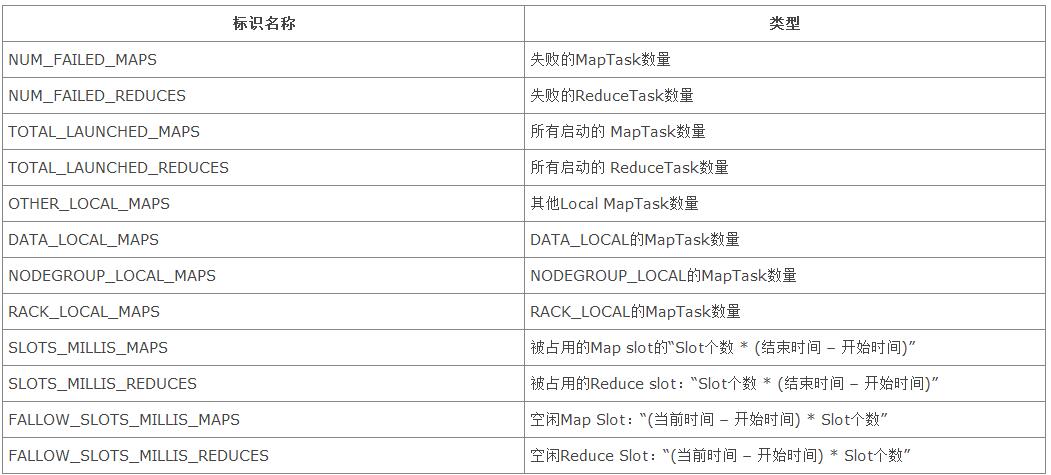
每个Job都包含一组Counter计数器,如下表所示:
其他结构
JobInProgress中使用了大量的集合来维护Job/Task相关的状态信息,具体内容如下表所示:
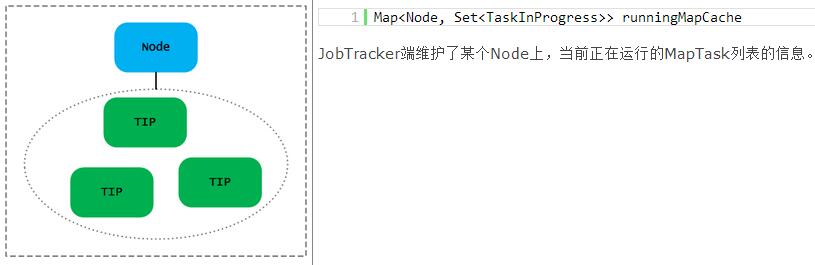

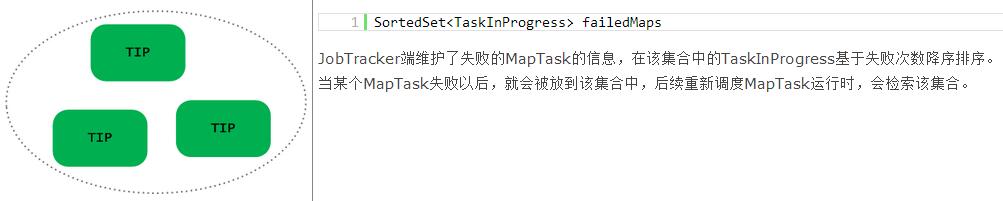
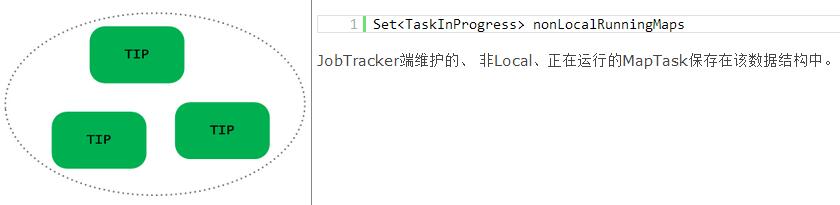
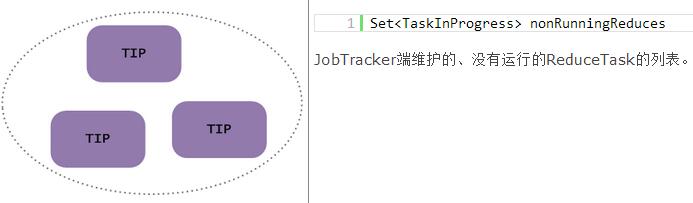
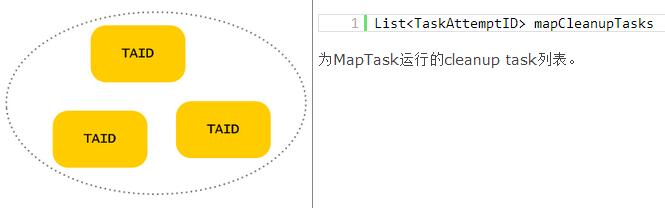
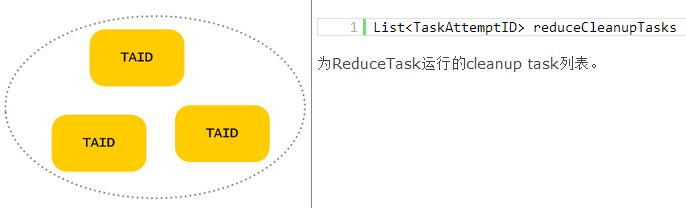


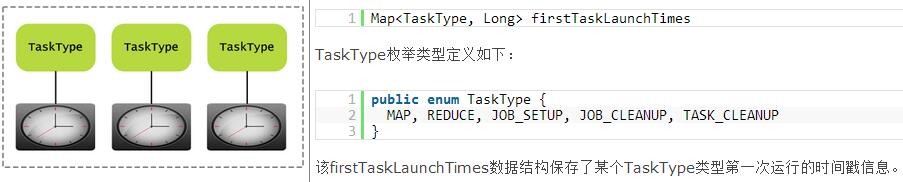
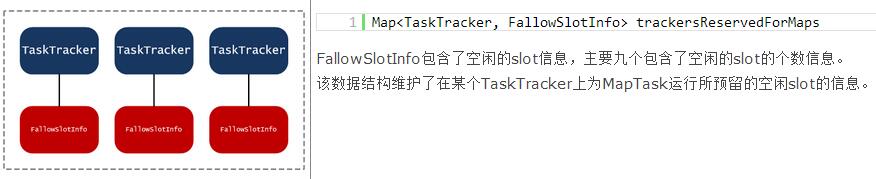

JobTracker数据结构
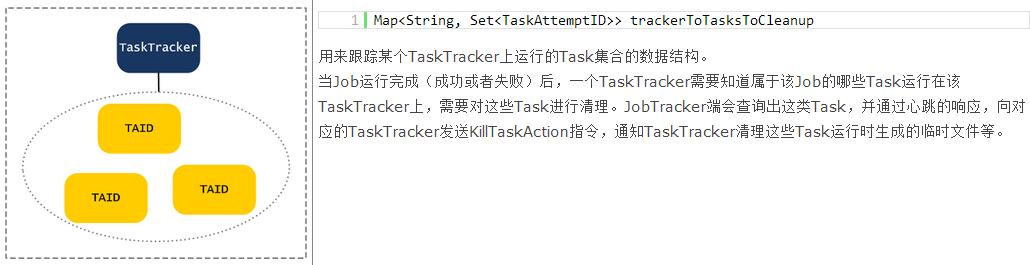
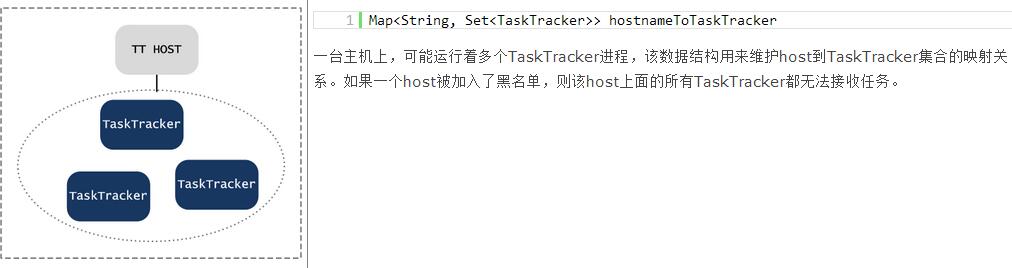
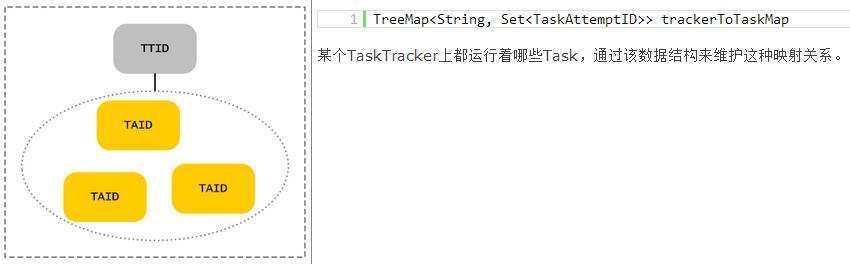
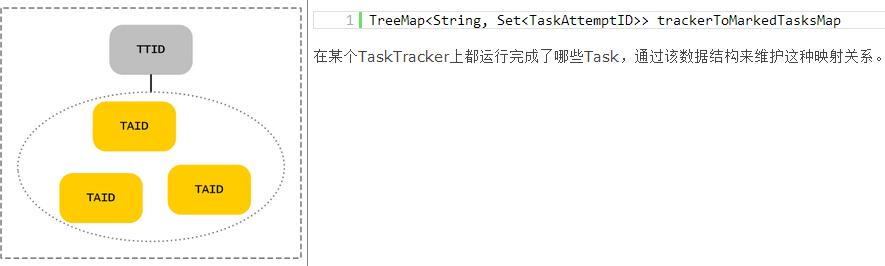
JobTracker通过在内存中维护有关Job、Task相关的所有信息,来跟踪他们运行、交互过程中所发生的数据交换,等等,如下表所示:


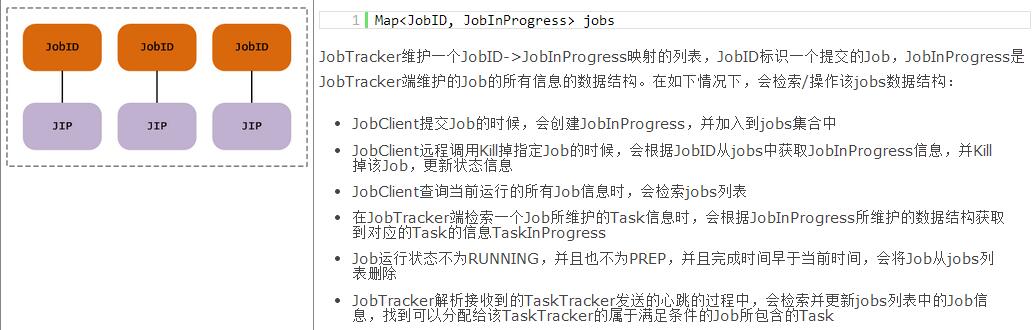

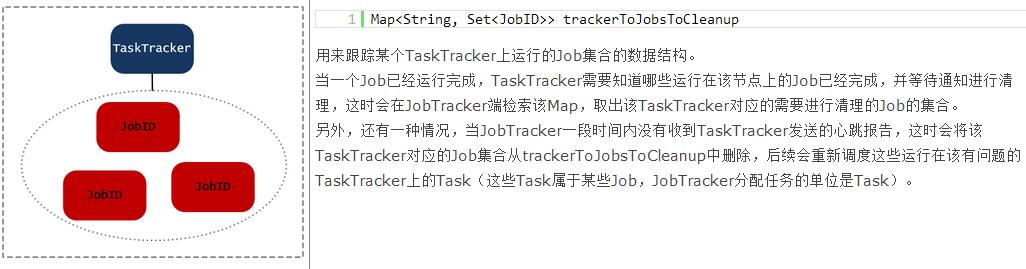




附录
这里给出文中(文字/图片上)一些缩写词对应的完整名称,如下表所示:
|







