| �������ȶԾ������㷨��ԭ�����з�����ָ������ڵ����⣬�����������ɭ���㷨��ͬ���������µ����ɭ�ֹ��첻ͬ���ǣ��ֲ�ʽ�����µľ�������������������Ż��Ļ������������������
IO �������㷨Ч�ʽ��dz��ͣ�Ϊ�˱��ĸ��������ɭ���ڷֲ�ʽ�����µľ����Ż����ԣ�Ȼ�����Դ����з��������ͨ�������������ɭ���ڽ�����������ν������ʿͻ��ķ��ࡣ
����
Spark �ڴ�������ڴ����ݴ���������ռ�о������صĵ�λ��2014
�� Spark ���� IT �磬Twitter ������ʾ Spark �Ѿ���Խ Hadoop��Yarn
�ȼ�������Ϊ�����ݴ��������������ŵļ�������ͼ 1 ��ʾ��2015 �� 6 �� 17 �գ�IBM �������ġ��������ݹ���ʦ�ƻ�������ŵ�����ƽ�
Apache Spark ��Ŀ�����Ƹ���ĿΪ��������Ϊ�����ģ�δ��ʮ����Ϊ��Ҫ���µĿ�Դ��Ŀ�����ƻ�Ͷ�볬��
3500 ���о��Ϳ�����Ա��ȫ��ʮ���ʵ���ҿ�չ�� Spark ��ص���Ŀ������Ϊ Spark ��Դ��̬ϵͳ���ṩͻ���ԵĻ���ѧϰ��������IBM
SystemML�����в��ѷ��֣�����ѧϰ������ IBM ����֧�� Spark ��һ����Ҫԭ��������Ϊ
Spark �ǻ����ڴ�ģ�������ѧϰ�㷨�ڲ�ʵ�ּ�������Ҫ���е���ʽ���㣬��ʹ�� Spark �ر������ڷֲ�ʽ�����µĻ���ѧϰ��
���Ľ��Ի���ѧϰ�����о���ķ���ͻع��㷨�������ɭ�֣�Random Forests�����н��ܡ����ȶ����ɭ���㷨�ĺ���ԭ�����н��ܣ����Ž�������
Spark �ϵ�ʵ�ַ�ʽ������Դ����з�����������һ������˵�����ɭ���㷨��ʵ����Ŀ�е�Ӧ�á�����������ݽ���ȫ���Է���ǶȽ��У��ع�Ԥ����������㷨�ϲ�û��̫��IJ��죬����ּ���������ɭ����
Spark �ϵ�ʵ��ԭ����
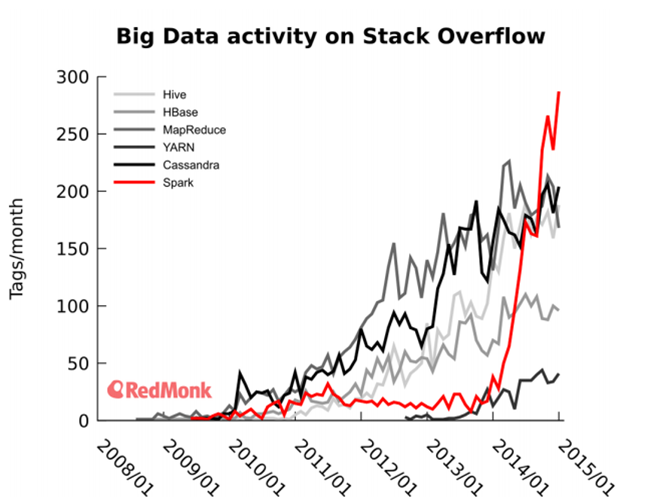
ͼ 1. Spark �����������ݴ������ߵĻ�Ծ�̶ȱȽ�
����Ҫ��
����ϵͳ��Linux�����IJ��õ� Ubuntu 10.04����ҿ��Ը����Լ���ϲ��ʹ���Լ��ó���
Linux ���а�
Java �� Scala �汾��Scala 2.10.4��Java 1.7
Spark ��Ⱥ������3 ̨����Hadoop 2.4.1+Spark 1.4.0
Դ���Ķ��밸��ʵս������Intellij IDEA 14.1.4
������
���ɭ���㷨�ǻ���ѧϰ��������Ӿ���������Ӧ�ü�Ϊ�㷺��һ���㷨���������������������࣬Ҳ���������ع鼴Ԥ�⣬���ɭ�ֻ��ɶ�����������ɣ�����ڵ����������㷨�������ࡢԤ��Ч�����ã������׳��ֹ�����ϵ������
���ɭ���㷨���ھ�����������ʽ�������ɭ���㷨֮ǰ���������ܾ�������ԭ�����������������ھ������ѧϰ������һ�ַdz���Ҫ�ķ��������㷨ͨ��ѵ������������һ�����ڷ���������Ӷ���δ֪���ݽ��и�Ч���ࡣ�ٸ�����������˵��ʲô�Ǿ���������ι���һ����������������þ��������з��࣬ij������վͨ������������ʷ���ݷ��֣�Ů����ʵ������ʱ�����±��֣�
�� 1. ������ʷ���ݱ�
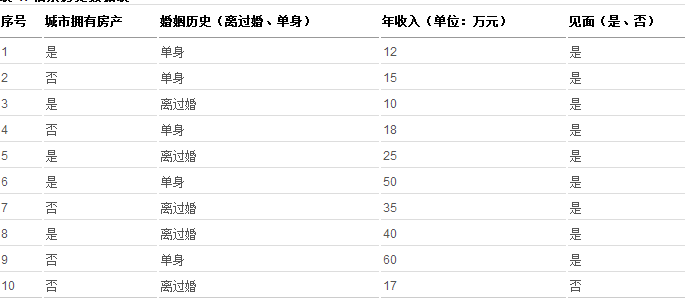
ͨ���� 1 ��ʾ��ʷ���ݿ��Թ������¾�������
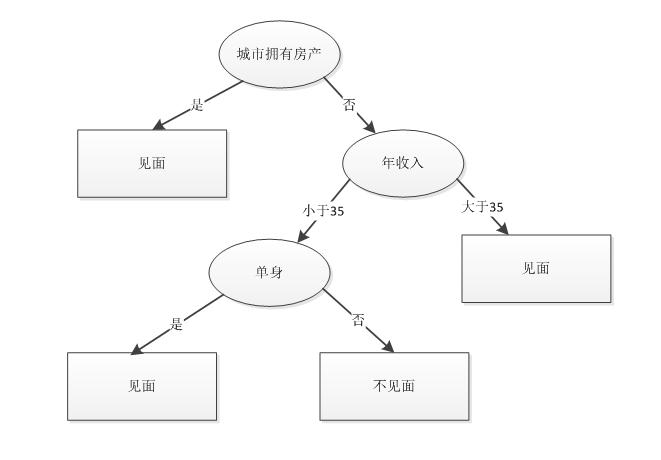
ͼ 2. ������ʾ��ͼ
�����վ��ע����һ���û������ڳ���������������С�� 35w ������飬�����Ԥ��Ů������������档ͨ��������������ӿ��Կ�����������������ʵ������к�ǿ��ָ�����塣ͨ�������ӣ�����Ҳ�����ܽ���������Ĺ������裺
�����м�¼������һ���ڵ�
����ÿ��������ÿ�ַָʽ���ҵ���õķָ��
���÷ָ�㽫��¼�ָ�������ӽ�� C1 �� C2
���ӽ�� C1 �� C2 �ظ�ִ�в��� 2����3����ֱ�������ض�����Ϊֹ
�ڹ����������Ĺ����У�����Ҫ��������ҵ���õķָ�㣬�������ķָ���������õ��أ����һ���ָ���ܹ���������¼ȷ�ط�Ϊ���࣬�Ǹ÷ָ��Ϳ�����Ϊ����õģ���ʱ���ֳɵ������������˵��������ģ�������ǰ��������С��ڳ���ӵ�з��������Խ����м�¼�����࣬�����ǡ��ǡ��Ķ����Ի�Ϊһ�࣬����������Ϊ����һ�ࡣ���С��ǡ����ֺ������������ģ���Ϊ�����ڳ���ӵ�з���������ʿ���������Ƿ�����顢��������ٶ�����棻�����С����ֺ���࣬�ֱ���Ϊ���࣬�����м���ģ�Ҳ�в�����ģ���������Ǻܴ��������������¼������������ġ�
���������ӵ��У����Կ����������ȿ��Դ��������ͱ���Ҳ���Դ��������ͱ����������ͱ����������룬�������á�>=������>��,��<����<=����Ϊ�ָ��������������ͱ���������Ƿ�ӵ�з�����ֵ�����ļ����硰�ǡ����������֣������á�=����Ϊ�ָ�������
��ǰ���ᵽ��Ѱ����õķָ����ͨ�������ָ����Ĵ�����ȷ���ģ�Ŀǰ�����ִ��ȼ��㷽ʽ���ֱ���
Gini �����ȡ��أ�Entropy���������ʣ����ǵĹ�ʽ�������£�
��ʽ�е� P(i) ��ʾ��¼�е� i ���¼��ռ�ܼ�¼���ı���������ǰ���Ů���������ӿ��Ը��ݼ�������Ϊ���࣬����ļ�¼ռ����Ϊ
P(1)=9/10��������ļ�¼ռ��Ϊ P(2)=1/10�������������ʽ����ֵԽ���ʾԽ����������ֵԽС��ʾԽ��������ʵ������õ���
Gini �����ȹ�ʽ�����������Ҳ�����øù�ʽ���д��ȼ��㡣
�������Ĺ�����һ���ݹ�Ĺ��̣�������������еļ�¼���ܱ���ȷ���࣬�����ɾ�����Ҷ�ڵ㶼��ȷ�������ͣ�����ʵ�������������������㣬��ʹ�þ������ڹ���ʱ���ܺ���ֹͣ����ʹ������ɣ�Ҳ������ʹ�����յĽڵ������࣬�Ӷ����¹�����ϣ�overfitting���������ʵ��Ӧ������Ҫ�趨ֹͣ���������ﵽֹͣ����ʱ��ֱ��ֹͣ�������Ĺ�����������Ȼ������ȫ�������������⣬������ϵĵ��ͱ����Ǿ�������ѵ�����ݴ����ʺܵͣ����Բ��������������ȴ�dz��ߡ�
������ϳ���ԭ���У�
��1��ѵ�������д���������
��2�����ݲ����д����ԡ�������ϵĵ��ͱ����Ǿ������Ľڵ���࣬���ʵ���г�����Ҫ�Թ����õľ���������֦Ҷ�ü���Prune
Tree�����������ܽ���������⣬���ɭ���㷨�ij����ܹ��Ϻõؽ������������⡣
���ɭ���㷨
�ɶ�����������ɵ�ɭ�֣��㷨����������Щ������ͶƱ�õ��������������ɵĹ��̵��зֱ����з�����з���������������̣��з����Ϲ���������ʱ���÷Żس�����bootstraping���õ�ѵ�����ݣ��з����ϲ����Ż���������õ������Ӽ������ݴ˵õ��������зֵ㣬��������ɭ���㷨�Ļ���ԭ����ͼ
3 ���������ɭ���㷨����ԭ������ͼ�п��Կ��������ɭ����һ�����ģ�ͣ��ڲ���Ȼ�ǻ��ھ�������ͬ��һ�ľ��������ͬ���ǣ����ɭ��ͨ�����������ͶƱ������з��࣬�㷨�����׳��ֹ���������⡣
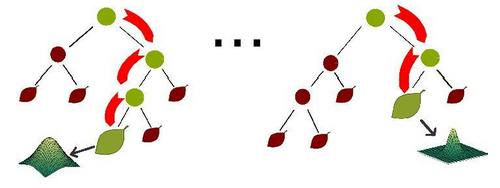
ͼ 3. ���ɭ��ʾ��ͼ
���ɭ���ڷֲ�ʽ�����µ��Ż�����
���ɭ���㷨�ڵ��������º�����ʵ�֣����ڷֲ�ʽ�������ر����� Spark
ƽ̨�ϣ���ͳ������ʽ�ĵ�����ʽ����Ҫ������Ӧ�Ľ����������ڷֲ�ʽ������������Ϊ�ڷֲ�ʽ�����£�����Ҳ�Ƿֲ�ʽ�ģ���ͼ
5 ��ʾ�����㷨��Ʋ��õ������ɴ����� IO ����������Ƶ�����������ݴ��䣬�Ӷ�Ӱ���㷨Ч�ʡ�

ͼ 4. �������������ݴ洢

ͼ 5. �ֲ�ʽ���������ݴ洢
��ˣ��� Spark �Ͻ������ɭ���㷨��ʵ�֣���Ҫ����һ�����Ż���Spark
�е����ɭ���㷨��Ҫʵ���������Ż����ԣ�
�зֵ����ͳ�ƣ���ͼ 6 ��ʾ���ڵ��������µľ��������������������зֵ�ѡ��ʱ��һ����ͨ�����������������Ȼ��ȡ����������֮��ĵ���Ϊ�зֵ㣬���ڵ����������ǿ��еģ�������ڷֲ�ʽ��������˲����Ļ�����������������紫��������ر��ǵ��������ﵽ
PB ��ʱ���㷨Ч�ʽ���Ϊ���¡�Ϊ��������⣬Spark �е����ɭ���ڹ���������ʱ����Ը���������һ�������������Խ��г�����Ȼ�����ɸ���������ͳ�����ݣ������յõ��зֵ㡣
����װ�䣨Binning������ͼ 7 ��ʾ���������Ĺ������̾��Ƕ�������ȡֵ���Ͻ��л��ֵĹ��̣�������ɢ�������������
M ��ֵ�����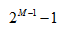 �����֣����ֵ������ģ���ô�����
M-1 �����֡������������������ϣ��У��� 3 ��ֵ����������� �����֣����ֵ������ģ���ô�����
M-1 �����֡������������������ϣ��У��� 3 ��ֵ�����������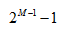 ������
3 �ֻ��֣���|�У��٣��ϣ���|�٣��ϣ���|�У����������ģ������ϣ��У��ٵ�����ôֻ�� m-1 ������
2 �ֻ��֣���|�У��٣��ϣ���|�١�������������������ʵ���ǽ��з�Χ���֣������ֵĵ���� split���зֵ㣩�����ֳ����������
bin���������������������� split �������ģ��ڷֲ������²�����ȡ�����е�ֵ����������õ��ǣ�1���е��е����ͳ�Ʒ����� ������
3 �ֻ��֣���|�У��٣��ϣ���|�٣��ϣ���|�У����������ģ������ϣ��У��ٵ�����ôֻ�� m-1 ������
2 �ֻ��֣���|�У��٣��ϣ���|�١�������������������ʵ���ǽ��з�Χ���֣������ֵĵ���� split���зֵ㣩�����ֳ����������
bin���������������������� split �������ģ��ڷֲ������²�����ȡ�����е�ֵ����������õ��ǣ�1���е��е����ͳ�Ʒ�����
���ѵ����level-wise training������ͼ 8 ��ʾ�������汾�ľ��������ɹ�����ͨ���ݹ���ã���������������ȣ��ķ�ʽ���������ڹ�������ͬʱ����Ҫ�ƶ����ݣ���ͬһ���ӽڵ�������ƶ���һ�𡣴˷����ڷֲ�ʽ���ݽṹ������Ч��ִ�У�����Ҳ��ִ�У���Ϊ����̫��������һ�������ڷֲ�ʽ�����²��õIJ�������㹹�����ڵ㣨�������ǹ�����ȣ������������������ݵĴ��������������е���������ÿ�α���ʱ��ֻ��Ҫ����ÿ���ڵ������зֵ�ͳ�Ʋ�������������ݽڵ���������֣������Ƿ��з֣��Լ�����з֡�
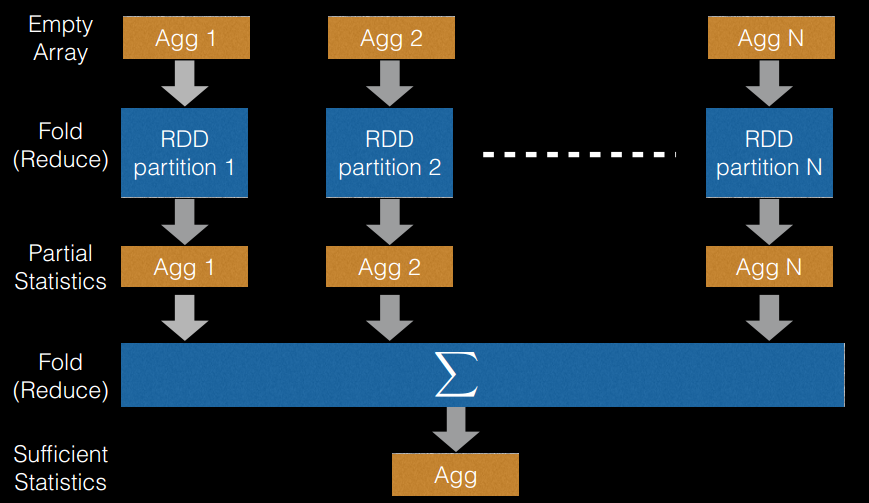
ͼ 6. �зֵ����ͳ��
ͼ 7. ����װ��
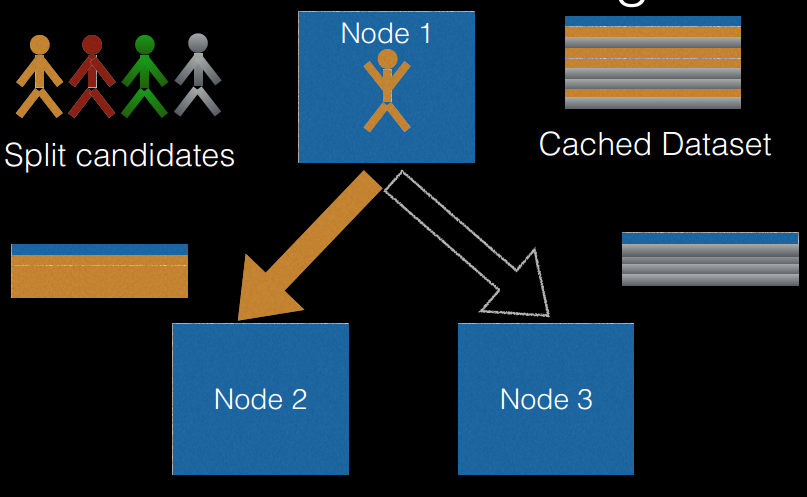
ͼ 8. ���ѵ��
���ɭ���㷨Դ�����
�ڶԾ����������ɭ���㷨ԭ���� Spark �ϵ��Ż����Ե���������ϣ����ڽ���
Spark MLlib �е����ɭ���㷨Դ����з��������ȸ����˹����ϵ��㷨ʹ�� demo��Ȼ�������뵽��Ӧ����Դ���У���ʵ��ԭ�����з�����
�嵥 1. ���ɭ��ʹ�� demo
import org.apache.spark.mllib.tree.RandomForest
import org.apache.spark.mllib.tree.model.RandomForestModel
import org.apache.spark.mllib.util.MLUtils
// ��������
val data = MLUtils.loadLibSVMFile(sc, "data/mllib/sample_libsvm_data.txt")
// �������������Ϊ���ݣ�һ������ѵ����һ�����ڲ���
val splits = data.randomSplit(Array(0.7, 0.3))
val (trainingData, testData) = (splits(0), splits(1))
// ���ɭ��ѵ����������
//������
val numClasses = 2
// categoricalFeaturesInfo Ϊ�գ���ζ�����е�����Ϊ�����ͱ���
val categoricalFeaturesInfo = Map[Int, Int]()
//���ĸ���
val numTrees = 3
//�����Ӽ��������ԣ�auto ��ʾ�㷨����ѡȡ
val featureSubsetStrategy = "auto"
//���ȼ���
val impurity = "gini"
//���������
val maxDepth = 4
//�������װ����
val maxBins = 32
//ѵ�����ɭ�ַ�������trainClassifier ���ص��� RandomForestModel ����
val model = RandomForest.trainClassifier(trainingData, numClasses, categoricalFeaturesInfo,
numTrees, featureSubsetStrategy, impurity, maxDepth, maxBins)
// ������������ѵ���õķ����������������
val labelAndPreds = testData.map { point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
val testErr = labelAndPreds.filter(r => r._1
!= r._2).count.toDouble / testData.count()
println("Test Error = " + testErr)
println("Learned classification forest model:\n"
+ model.toDebugString)
// ��ѵ��������ɭ��ģ�ͳ־û�
model.save(sc, "myModelPath")
//�������ɭ��ģ�͵��ڴ�
val sameModel = RandomForestModel.load(sc, "myModelPath") |
ͨ����������������Կ�������ʹ���ߵĽǶ����������ɭ���йؼ������� org.apache.spark.mllib.tree.RandomForest��org.apache.spark.mllib.tree.model.RandomForestModel
�������࣬�����ṩ�����ɭ�־���� trainClassifier �� predict ������
������� demo �п��Կ�����ѵ�����ɭ���㷨���õ��� RandomForest �İ��������е� trainClassifier
��������Դ�루Ϊ�������⣬��������ǰ���ע�ͼ�����˵�������£�
�嵥 2. ����Դ����� 1
/**
* Method to train a decision tree model for binary or multiclass classification.
*
* @param input Training dataset: RDD of [[org.apache.spark.mllib.regression.LabeledPoint]].
* Labels should take values {0, 1, ..., numClasses-1}.
* @param numClasses number of classes for classification.
* @param categoricalFeaturesInfo Map storing arity of categorical features.
* E.g., an entry (n -> k) indicates that feature n is categorical
* with k categories indexed from 0: {0, 1, ..., k-1}.
* @param numTrees Number of trees in the random forest.
* @param featureSubsetStrategy Number of features to consider for splits at each node.
* Supported: "auto", "all", "sqrt", "log2", "onethird".
* If "auto" is set, this parameter is set based on numTrees:
* if numTrees == 1, set to "all";
* if numTrees > 1 (forest) set to "sqrt".
* @param impurity Criterion used for information gain calculation.
* Supported values: "gini" (recommended) or "entropy".
* @param maxDepth Maximum depth of the tree.
* E.g., depth 0 means 1 leaf node; depth 1 means 1 internal node + 2 leaf nodes.
* (suggested value: 4)
* @param maxBins maximum number of bins used for splitting features
* (suggested value: 100)
* @param seed Random seed for bootstrapping and choosing feature subsets.
* @return a random forest model that can be used for prediction
*/
def trainClassifier(
input: RDD[LabeledPoint],
numClasses: Int,
categoricalFeaturesInfo: Map[Int, Int],
numTrees: Int,
featureSubsetStrategy: String,
impurity: String,
maxDepth: Int,
maxBins: Int,
seed: Int = Utils.random.nextInt()): RandomForestModel = {
val impurityType = Impurities.fromString(impurity)
val strategy = new Strategy(Classification, impurityType, maxDepth,
numClasses, maxBins, Sort, categoricalFeaturesInfo)
//���õ������ص�����һ�� trainClassifier
trainClassifier(input, strategy, numTrees, featureSubsetStrategy, seed)
} |
���غ� trainClassifier �����������£�
�嵥 3. ����Դ����� 2
/**
* Method to train a decision tree model for binary or multiclass classification.
*
* @param input Training dataset: RDD of [[org.apache.spark.mllib.regression.LabeledPoint]].
* Labels should take values {0, 1, ..., numClasses-1}.
* @param strategy Parameters for training each tree in the forest.
* @param numTrees Number of trees in the random forest.
* @param featureSubsetStrategy Number of features to consider for splits at each node.
* Supported: "auto", "all", "sqrt", "log2", "onethird".
* If "auto" is set, this parameter is set based on numTrees:
* if numTrees == 1, set to "all";
* if numTrees > 1 (forest) set to "sqrt".
* @param seed Random seed for bootstrapping and choosing feature subsets.
* @return a random forest model that can be used for prediction
*/
def trainClassifier(
input: RDD[LabeledPoint],
strategy: Strategy,
numTrees: Int,
featureSubsetStrategy: String,
seed: Int): RandomForestModel = {
require(strategy.algo == Classification,
s"RandomForest.trainClassifier given Strategy with invalid algo: ${strategy.algo}")
//�ڸ÷����д��� RandomForest ����
val rf = new RandomForest(strategy, numTrees, featureSubsetStrategy, seed)
//�ٵ����� run ����������IJ��������� RDD[LabeledPoint]���������ص��� RandomForestModel ʵ��
rf.run(input)
} |
���� RandomForest �е� run ��������������£�
�嵥 4. ����Դ����� 3
/**
* Method to train a decision tree model over an RDD
* @param input Training data: RDD of [[org.apache.spark.mllib.regression.LabeledPoint]]
* @return a random forest model that can be used for prediction
*/
def run(input: RDD[LabeledPoint]): RandomForestModel = {
val timer = new TimeTracker()
timer.start("total")
timer.start("init")
val retaggedInput = input.retag(classOf[LabeledPoint])
//������������Ԫ������Ϣ�����ѵ�λ�á��������������Ӱ����������Ե�ֵ�ȵȣ�
val metadata =
DecisionTreeMetadata.buildMetadata(retaggedInput,
strategy, numTrees, featureSubsetStrategy)
logDebug("algo = " + strategy.algo)
logDebug("numTrees = " + numTrees)
logDebug("seed = " + seed)
logDebug("maxBins = " + metadata.maxBins)
logDebug("featureSubsetStrategy = "
+ featureSubsetStrategy)
logDebug("numFeaturesPerNode = " + metadata.numFeaturesPerNode)
logDebug("subsamplingRate = " + strategy.subsamplingRate)
// Find the splits and the corresponding bins
(interval between the splits) using a sample
// of the input data.
timer.start("findSplitsBins")
//�ҵ��зֵ㣨splits����������Ϣ��Bins��
//���������������������зֵ����ͳ�Ƽ���
//�������������������������ģ�������и� splits=2^(numBins-1)-1
����
//���������ģ�������� splits=numBins-1 ������
val (splits, bins) = DecisionTree.findSplitsBins(retaggedInput,
metadata)
timer.stop("findSplitsBins")
logDebug("numBins: feature: number of bins")
logDebug(Range(0, metadata.numFeatures).map {
featureIndex =>
s"\t$featureIndex\t${metadata.numBins(featureIndex)}"
}.mkString("\n"))
// Bin feature values (TreePoint representation).
// Cache input RDD for speedup during multiple
passes.
//ת�������ε� RDD ���ͣ�ת���������������Ѿ������ѵ������ֵ��˸��Ե�������
val treeInput = TreePoint.convertToTreeRDD(retaggedInput,
bins, metadata)
val withReplacement = if (numTrees > 1) true
else false
// convertToBaggedRDD ����ʹ��ÿ��������������һ���Ӽ�
val baggedInput
= BaggedPoint.convertToBaggedRDD(treeInput,
strategy.subsamplingRate, numTrees,
withReplacement, seed).persist(StorageLevel.MEMORY_AND_DISK)
// depth of the decision tree
val maxDepth = strategy.maxDepth
require(maxDepth <= 30,
s"DecisionTree currently only supports maxDepth
<= 30, but was given maxDepth = $maxDepth.")
// Max memory usage for aggregates
// TODO: Calculate memory usage more precisely.
val maxMemoryUsage: Long = strategy.maxMemoryInMB
* 1024L * 1024L
logDebug("max memory usage for aggregates
= " + maxMemoryUsage + " bytes.")
val maxMemoryPerNode = {
val featureSubset: Option[Array[Int]] = if (metadata.subsamplingFeatures)
{
// Find numFeaturesPerNode largest bins to get
an upper bound on memory usage.
Some(metadata.numBins.zipWithIndex.sortBy(- _._1)
.take(metadata.numFeaturesPerNode).map(_._2))
} else {
None
}
//����ۺϲ���ʱ�ڵ���ڴ�
RandomForest.aggregateSizeForNode(metadata, featureSubset)
* 8L
}
require(maxMemoryPerNode <= maxMemoryUsage,
s"RandomForest/DecisionTree given maxMemoryInMB
= ${strategy.maxMemoryInMB}," +
" which is too small for the given features."
+
s" Minimum value = ${maxMemoryPerNode / (1024L
* 1024L)}")
timer.stop("init")
/*
* The main idea here is to perform group-wise
training of the decision tree nodes thus
* reducing the passes over the data from (# nodes)
to (# nodes / maxNumberOfNodesPerGroup).
* Each data sample is handled by a particular
node (or it reaches a leaf and is not used
* in lower levels).
*/
// Create an RDD of node Id cache.
// At first, all the rows belong to the root nodes
(node Id == 1).
//�ڵ��Ƿ�ʹ�û��棬�ڵ� ID �� 1 ��ʼ��1 ��Ϊ������ĸ��ڵ㣬��ڵ�Ϊ 2���ҽڵ�Ϊ
3�����ε�����ȥ
val nodeIdCache = if (strategy.useNodeIdCache)
{
Some(NodeIdCache.init(
data = baggedInput,
numTrees = numTrees,
checkpointInterval = strategy.checkpointInterval,
initVal = 1))
} else {
None
}
// FIFO queue of nodes to train: (treeIndex,
node)
val nodeQueue = new mutable.Queue[(Int, Node)]()
val rng = new scala.util.Random()
rng.setSeed(seed)
// Allocate and queue root nodes.
//�������ĸ��ڵ�
val topNodes: Array[Node] = Array.fill[Node](numTrees)(Node.emptyNode(nodeIndex
= 1))
//�����������������ĸ��ڵ㣩��ӣ��������� 0 ��ʼ�����ڵ�� 1 ��ʼ
Range(0, numTrees).foreach(treeIndex => nodeQueue.enqueue((treeIndex,
topNodes(treeIndex))))
while (nodeQueue.nonEmpty) {
// Collect some nodes to split, and choose features
for each node (if subsampling).
// Each group of nodes may come from one or multiple
trees, and at multiple levels.
// ȡ��ÿ����������Ҫ�зֵĽڵ�
val (nodesForGroup, treeToNodeToIndexInfo) =
RandomForest.selectNodesToSplit(nodeQueue, maxMemoryUsage,
metadata, rng)
// Sanity check (should never occur):
assert(nodesForGroup.size > 0,
s"RandomForest selected empty nodesForGroup.
Error for unknown reason.")
// Choose node splits, and enqueue new nodes
as needed.
timer.start("findBestSplits")
//�ҳ������е�
DecisionTree.findBestSplits(baggedInput, metadata,
topNodes, nodesForGroup,
treeToNodeToIndexInfo, splits, bins, nodeQueue,
timer, nodeIdCache = nodeIdCache)
timer.stop("findBestSplits")
}
baggedInput.unpersist()
timer.stop("total")
logInfo("Internal timing for DecisionTree:")
logInfo(s"$timer")
// Delete any remaining checkpoints used for
node Id cache.
if (nodeIdCache.nonEmpty) {
try {
nodeIdCache.get.deleteAllCheckpoints()
} catch {
case e: IOException =>
logWarning(s"delete all checkpoints failed.
Error reason: ${e.getMessage}")
}
}
val trees = topNodes.map(topNode => new DecisionTreeModel(topNode,
strategy.algo))
new RandomForestModel(strategy.algo, trees)
}
} |
����������� RandomForest ���еĺ��ķ��� run �Ĵ��룬��ȷ���зֵ㼰������Ϣ��ʱ�������
DecisionTree.findSplitsBins ����������÷��������Կ������´��룺
�嵥 5. ����Դ����� 4
/**
* Returns splits and bins for decision tree calculation.
* Continuous and categorical features are handled differently.
*
* Continuous features:
* For each feature, there are numBins - 1 possible splits representing the possible binary
* decisions at each node in the tree.
* This finds locations (feature values) for splits using a subsample of the data.
*
* Categorical features:
* For each feature, there is 1 bin per split.
* Splits and bins are handled in 2 ways:
* (a) "unordered features"
* For multiclass classification with a low-arity feature
* (i.e., if isMulticlass && isSpaceSufficientForAllCategoricalSplits),
* the feature is split based on subsets of categories.
* (b) "ordered features"
* For regression and binary classification,
* and for multiclass classification with a high-arity feature,
* there is one bin per category.
*
* @param input Training data: RDD of [[org.apache.spark.mllib.regression.LabeledPoint]]
* @param metadata Learning and dataset metadata
* @return A tuple of (splits, bins).
* Splits is an Array of [[org.apache.spark.mllib.tree.model.Split]]
* of size (numFeatures, numSplits).
* Bins is an Array of [[org.apache.spark.mllib.tree.model.Bin]]
* of size (numFeatures, numBins).
*/
protected[tree] def findSplitsBins(
input: RDD[LabeledPoint],
metadata: DecisionTreeMetadata): (Array[Array[Split]], Array[Array[Bin]]) = {
logDebug("isMulticlass = " + metadata.isMulticlass)
val numFeatures = metadata.numFeatures
// Sample the input only if there are continuous
features.
// �ж��������Ƿ������������
val hasContinuousFeatures = Range(0, numFeatures).exists(metadata.isContinuous)
val sampledInput = if (hasContinuousFeatures)
{
// Calculate the number of samples for approximate
quantile calculation.
//������������������Ӧ��Ϊ 10000 ��
val requiredSamples = math.max(metadata.maxBins
* metadata.maxBins, 10000)
//�����������
val fraction = if (requiredSamples < metadata.numExamples)
{
requiredSamples.toDouble / metadata.numExamples
} else {
1.0
}
logDebug("fraction of data used for calculating
quantiles = " + fraction)
input.sample(withReplacement = false, fraction,
new XORShiftRandom().nextInt()).collect()
} else {
//���Ϊ��ɢ��������һ�������飨�����������
new Array[LabeledPoint](0)
}
// //���ѵ���ԣ�Ŀǰ Spark ��ֻʵ����һ�ֲ��ԣ����� Sort
metadata.quantileStrategy match {
case Sort =>
//ÿ�������ֱ��Ӧһ���зֵ�λ��
val splits = new Array[Array[Split]](numFeatures)
//����зֵ�λ�ö�Ӧ��������Ϣ
val bins = new Array[Array[Bin]](numFeatures)
// Find all splits.
// Iterate over all features.
var featureIndex = 0
//�����������
while (featureIndex < numFeatures) {
//�������������
if (metadata.isContinuous(featureIndex)) {
val featureSamples = sampledInput.map(lp =>
lp.features(featureIndex))
// findSplitsForContinuousFeature �������������������з�λ��
val featureSplits = findSplitsForContinuousFeature(featureSamples,
metadata, featureIndex)
val numSplits = featureSplits.length
//����������������Ϊ�зֵ����+1
val numBins = numSplits + 1
logDebug(s"featureIndex = $featureIndex,
numSplits = $numSplits")
//�зֵ����鼰������������
splits(featureIndex) = new Array[Split](numSplits)
bins(featureIndex) = new Array[Bin](numBins)
var splitIndex = 0
//�����зֵ�
while (splitIndex < numSplits) {
//��ȡ�зֵ��Ӧ��ֵ���������Ź���ģ������������ֵ����
val threshold = featureSplits(splitIndex)
//�����Ӧ�������е��зֵ�λ����Ϣ
splits(featureIndex)(splitIndex) =
new Split(featureIndex, threshold, Continuous,
List())
splitIndex += 1
}
//������С��ֵ Double.MinValue ��Ϊ����ߵķ���λ�ò�����װ��
bins(featureIndex)(0) = new Bin(new DummyLowSplit(featureIndex,
Continuous),
splits(featureIndex)(0), Continuous, Double.MinValue)
splitIndex = 1
//�����һ��������ʣ�����ӵļ��㣬�������ォ��ŵ��������зֵ�λ����ֵ���������ֵ
while (splitIndex < numSplits) {
bins(featureIndex)(splitIndex) =
new Bin(splits(featureIndex)(splitIndex - 1),
splits(featureIndex)(splitIndex),
Continuous, Double.MinValue)
splitIndex += 1
}
//���һ�����ӵļ�����������ֵ Double.MaxValue ��Ϊ���ұߵ��з�λ��
bins(featureIndex)(numSplits) = new Bin(splits(featureIndex)(numSplits
- 1),
new DummyHighSplit(featureIndex, Continuous),
Continuous, Double.MinValue)
} else { //����Ϊ��ɢ���ʱ�ļ���
val numSplits = metadata.numSplits(featureIndex)
val numBins = metadata.numBins(featureIndex)
// Categorical feature
//�������Եĸ���
val featureArity = metadata.featureArity(featureIndex)
//��������ʱ�Ĵ�����ʽ
if (metadata.isUnordered(featureIndex)) {
// Unordered features
// 2^(maxFeatureValue - 1) - 1 combinations
splits(featureIndex) = new Array[Split](numSplits)
var splitIndex = 0
while (splitIndex < numSplits) {
//��ȡ����������ֵ�����ؼ��ϰ�������һ����������ɢ����ֵ
val categories: List[Double] =
extractMultiClassCategories(splitIndex + 1, featureArity)
splits(featureIndex)(splitIndex) =
new Split(featureIndex, Double.MinValue, Categorical,
categories)
splitIndex += 1
}
} else {
//�����������账��������������ֵ��Ӧ
// Ordered features
// Bins correspond to feature values, so we do
not need to compute splits or bins
// beforehand. Splits are constructed as needed
during training.
splits(featureIndex) = new Array[Split](0)
}
// For ordered features, bins correspond to feature
values.
// For unordered categorical features, there is
no need to construct the bins.
// since there is a one-to-one correspondence
between the splits and the bins.
bins(featureIndex) = new Array[Bin](0)
}
featureIndex += 1
}
(splits, bins)
case MinMax =>
throw new UnsupportedOperationException("minmax
not supported yet.")
case ApproxHist =>
throw new UnsupportedOperationException("approximate
histogram not supported yet.")
}
} |
�� findSplitsBins �����⣬����һ���dz���Ҫ�� DecisionTree.findBestSplits()
���������������зֵ�IJ��ң��÷����еĹؼ��Ƕ� binsToBestSplit �����ĵ��ã��� binsToBestSplit
�����������£�
�嵥 6. ����Դ����� 5
/**
* Find the best split for a node.
* @param binAggregates Bin statistics.
* @return tuple for best split: (Split, information gain, prediction at node)
*/
private def binsToBestSplit(
binAggregates: DTStatsAggregator, // DTStatsAggregator������������ ImpurityAggregator���������㲻���� impurity ����
splits: Array[Array[Split]],
featuresForNode: Option[Array[Int]],
node: Node): (Split, InformationGainStats, Predict) = {
// calculate predict and impurity if current
node is top node
val level = Node.indexToLevel(node.id)
var predictWithImpurity: Option[(Predict, Double)]
= if (level == 0) {
None
} else {
Some((node.predict, node.impurity))
}
// For each (feature, split), calculate the gain,
and select the best (feature, split).
//�Ը��������зֵ㣬��������Ϣ���沢����ѡ������ (feature, split)
val (bestSplit, bestSplitStats) =
Range(0, binAggregates.metadata.numFeaturesPerNode).map
{ featureIndexIdx =>
val featureIndex = if (featuresForNode.nonEmpty)
{
featuresForNode.get.apply(featureIndexIdx)
} else {
featureIndexIdx
}
val numSplits = binAggregates.metadata.numSplits(featureIndex)
//����Ϊ����ֵ�����
if (binAggregates.metadata.isContinuous(featureIndex))
{
// Cumulative sum (scanLeft) of bin statistics.
// Afterwards, binAggregates for a bin is the
sum of aggregates for
// that bin + all preceding bins.
val nodeFeatureOffset = binAggregates.getFeatureOffset(featureIndexIdx)
var splitIndex = 0
while (splitIndex < numSplits) {
binAggregates.mergeForFeature(nodeFeatureOffset,
splitIndex + 1, splitIndex)
splitIndex += 1
}
// Find best split.
val (bestFeatureSplitIndex, bestFeatureGainStats)
=
Range(0, numSplits).map { case splitIdx =>
//���� leftChild �� rightChild �ӽڵ�� impurity
val leftChildStats = binAggregates.getImpurityCalculator(nodeFeatureOffset,
splitIdx)
val rightChildStats = binAggregates.getImpurityCalculator(nodeFeatureOffset,
numSplits)
rightChildStats.subtract(leftChildStats)
//�� impurity ��Ԥ��ֵ�����õ���ƽ��ֵ����
predictWithImpurity = Some(predictWithImpurity.getOrElse(
calculatePredictImpurity(leftChildStats, rightChildStats)))
//����Ϣ���� information gain ֵ�����������зֵ��Ƿ�����
val gainStats = calculateGainForSplit(leftChildStats,
rightChildStats, binAggregates.metadata, predictWithImpurity.get._2)
(splitIdx, gainStats)
}.maxBy(_._2.gain)
(splits(featureIndex)(bestFeatureSplitIndex),
bestFeatureGainStats)
} else if (binAggregates.metadata.isUnordered(featureIndex))
{ //������ɢ����ʱ�����
// Unordered categorical feature
val (leftChildOffset, rightChildOffset) =
binAggregates.getLeftRightFeatureOffsets(featureIndexIdx)
val (bestFeatureSplitIndex, bestFeatureGainStats)
=
Range(0, numSplits).map { splitIndex =>
val leftChildStats = binAggregates.getImpurityCalculator(leftChildOffset,
splitIndex)
val rightChildStats = binAggregates.getImpurityCalculator(rightChildOffset,
splitIndex)
predictWithImpurity = Some(predictWithImpurity.getOrElse(
calculatePredictImpurity(leftChildStats, rightChildStats)))
val gainStats = calculateGainForSplit(leftChildStats,
rightChildStats, binAggregates.metadata, predictWithImpurity.get._2)
(splitIndex, gainStats)
}.maxBy(_._2.gain)
(splits(featureIndex)(bestFeatureSplitIndex),
bestFeatureGainStats)
} else { //������ɢ����ʱ�����
// Ordered categorical feature
val nodeFeatureOffset = binAggregates.getFeatureOffset(featureIndexIdx)
val numBins = binAggregates.metadata.numBins(featureIndex)
/* Each bin is one category (feature value).
* The bins are ordered based on centroidForCategories,
and this ordering determines which
* splits are considered. (With K categories, we
consider K - 1 possible splits.)
*
* centroidForCategories is a list: (category,
centroid)
*/
//��Ԫ����ʱ�����
val centroidForCategories = if (binAggregates.metadata.isMulticlass)
{
// For categorical variables in multiclass classification,
// the bins are ordered by the impurity of their
corresponding labels.
Range(0, numBins).map { case featureValue =>
val categoryStats = binAggregates.getImpurityCalculator(nodeFeatureOffset,
featureValue)
val centroid = if (categoryStats.count != 0) {
// impurity ��ľ��Ǿ�����
categoryStats.calculate()
} else {
Double.MaxValue
}
(featureValue, centroid)
}
} else { // �ع���Ԫ����ʱ����� regression or binary classification
// For categorical variables in regression and
binary classification,
// the bins are ordered by the centroid of their
corresponding labels.
Range(0, numBins).map { case featureValue =>
val categoryStats = binAggregates.getImpurityCalculator(nodeFeatureOffset,
featureValue)
val centroid = if (categoryStats.count != 0) {
//��ľ���ƽ��ֵ��Ϊ impurity
categoryStats.predict
} else {
Double.MaxValue
}
(featureValue, centroid)
}
}
logDebug("Centroids for categorical variable:
" + centroidForCategories.mkString(","))
// bins sorted by centroids
val categoriesSortedByCentroid = centroidForCategories.toList.sortBy(_._2)
logDebug("Sorted centroids for categorical
variable = " +
categoriesSortedByCentroid.mkString(","))
// Cumulative sum (scanLeft) of bin statistics.
// Afterwards, binAggregates for a bin is the
sum of aggregates for
// that bin + all preceding bins.
var splitIndex = 0
while (splitIndex < numSplits) {
val currentCategory = categoriesSortedByCentroid(splitIndex)._1
val nextCategory = categoriesSortedByCentroid(splitIndex
+ 1)._1
//���������ӵ�״̬��Ϣ���кϲ�
binAggregates.mergeForFeature(nodeFeatureOffset,
nextCategory, currentCategory)
splitIndex += 1
}
// lastCategory = index of bin with total aggregates
for this (node, feature)
val lastCategory = categoriesSortedByCentroid.last._1
// Find best split.
//ͨ����Ϣ����ֵѡ�������зֵ�
val (bestFeatureSplitIndex, bestFeatureGainStats)
=
Range(0, numSplits).map { splitIndex =>
val featureValue = categoriesSortedByCentroid(splitIndex)._1
val leftChildStats =
binAggregates.getImpurityCalculator(nodeFeatureOffset,
featureValue)
val rightChildStats =
binAggregates.getImpurityCalculator(nodeFeatureOffset,
lastCategory)
rightChildStats.subtract(leftChildStats)
predictWithImpurity = Some(predictWithImpurity.getOrElse(
calculatePredictImpurity(leftChildStats, rightChildStats)))
val gainStats = calculateGainForSplit(leftChildStats,
rightChildStats, binAggregates.metadata, predictWithImpurity.get._2)
(splitIndex, gainStats)
}.maxBy(_._2.gain)
val categoriesForSplit =
categoriesSortedByCentroid.map(_._1.toDouble).slice(0,
bestFeatureSplitIndex + 1)
val bestFeatureSplit =
new Split(featureIndex, Double.MinValue, Categorical,
categoriesForSplit)
(bestFeatureSplit, bestFeatureGainStats)
}
}.maxBy(_._2.gain)
(bestSplit, bestSplitStats, predictWithImpurity.get._1)
} |
�������������һ�����������ɭ�ֹ�����̺��Ĵ��룬����Ҳ�ᵽ RandomForest
�е� run �������ص��� RandomForestModel������Ĵ������£�
�嵥 7. ����Դ����� 6
/**
* :: Experimental ::
* Represents a random forest model.
*
* @param algo algorithm for the ensemble model, either Classification or Regression
* @param trees tree ensembles
*/
// RandomForestModel ��չ�� TreeEnsembleModel
@Experimental
class RandomForestModel(override val algo: Algo, override val trees: Array[DecisionTreeModel])
extends TreeEnsembleModel(algo, trees, Array.fill(trees.length)(1.0),
combiningStrategy = if (algo == Classification) Vote else Average)
with Saveable {
require(trees.forall(_.algo == algo))
//��ѵ���õ�ģ�ͳ־û�
override def save(sc: SparkContext, path: String):
Unit = {
TreeEnsembleModel.SaveLoadV1_0.save(sc, path,
this,
RandomForestModel.SaveLoadV1_0.thisClassName)
}
override protected def formatVersion: String
= RandomForestModel.formatVersion
}
object RandomForestModel extends Loader[RandomForestModel]
{
private[mllib] def formatVersion: String = TreeEnsembleModel.SaveLoadV1_0.thisFormatVersion
//��ѵ���õ�ģ�ͼ��ص��ڴ�
override def load(sc: SparkContext, path: String):
RandomForestModel = {
val (loadedClassName, version, jsonMetadata) =
Loader.loadMetadata(sc, path)
val classNameV1_0 = SaveLoadV1_0.thisClassName
(loadedClassName, version) match {
case (className, "1.0") if className
== classNameV1_0 =>
val metadata = TreeEnsembleModel.SaveLoadV1_0.readMetadata(jsonMetadata)
assert(metadata.treeWeights.forall(_ == 1.0))
val trees =
TreeEnsembleModel.SaveLoadV1_0.loadTrees(sc, path,
metadata.treeAlgo)
new RandomForestModel(Algo.fromString(metadata.algo),
trees)
case _ => throw new Exception(s"RandomForestModel.load
did not recognize model" +
s" with (className, format version): ($loadedClassName,
$version). Supported:\n" +
s" ($classNameV1_0, 1.0)")
}
}
private object SaveLoadV1_0 {
// Hard-code class name string in case it changes
in the future
def thisClassName: String = "org.apache.spark.mllib.tree.model.RandomForestModel"
}
} |
���������ɭ�ֽ���Ԥ��ʱ�����õ� predict ������չ�� TreeEnsembleModel���������ṹ���ģ�͵ı�ʾ�������ɭ�������
Gradient-Boosted Trees (GBTs)���䲿�ֺ��Ĵ������£�
�嵥 8. ����Դ����� 7
/**
* Represents a tree ensemble model.
*
* @param algo algorithm for the ensemble model, either Classification or Regression
* @param trees tree ensembles
* @param treeWeights tree ensemble weights
* @param combiningStrategy strategy for combining the predictions, not used for regression.
*/
private[tree] sealed class TreeEnsembleModel(
protected val algo: Algo,
protected val trees: Array[DecisionTreeModel],
protected val treeWeights: Array[Double],
protected val combiningStrategy: EnsembleCombiningStrategy) extends Serializable {
require(numTrees > 0, "TreeEnsembleModel
cannot be created without trees.")
//��������ʡ��
//ͨ��ͶƱʵ�����յķ���
/**
* Classifies a single data point based on (weighted)
majority votes.
*/
private def predictByVoting(features: Vector):
Double = {
val votes = mutable.Map.empty[Int, Double]
trees.view.zip(treeWeights).foreach { case (tree,
weight) =>
val prediction = tree.predict(features).toInt
votes(prediction) = votes.getOrElse(prediction,
0.0) + weight
}
votes.maxBy(_._2)._1
}
/**
* Predict values for a single data point using
the model trained.
*
* @param features array representing a single
data point
* @return predicted category from the trained
model
*/
//��ͬ�IJ��Բ��ò�ͬ��Ԥ�ⷽ��
def findSplitsBins(features: Vector): Double =
{
(algo, combiningStrategy) match {
case (Regression, Sum) =>
predictBySumming(features)
case (Regression, Average) =>
predictBySumming(features) / sumWeights
case (Classification, Sum) => // binary classification
val prediction = predictBySumming(features)
// TODO: predicted labels are +1 or -1 for GBT.
Need a better way to store this info.
if (prediction > 0.0) 1.0 else 0.0
//���ɭ�ֶ�Ӧ predictByVoting ����
case (Classification, Vote) =>
predictByVoting(features)
case _ =>
throw new IllegalArgumentException(
"TreeEnsembleModel given unsupported (algo,
combiningStrategy) combination: " +
s"($algo, $combiningStrategy).")
}
}
// predict �����ľ���ʵ��
/**
* Predict values for the given data set.
*
* @param features RDD representing data points
to be predicted
* @return RDD[Double] where each entry contains
the corresponding prediction
*/
def predict(features: RDD[Vector]): RDD[Double]
= features.map(x => findSplitsBins (x))
//��������ʡ��
} |
ͨ���������Ĵ�������������Ѿ��������������ɭ���㷨���ڲ����ƣ���һС�ڸ�����ʵ��ʹ�ð�����
���ɭ���㷨����ʵս
���ڽ�ͨ������һ��������˵�����ɭ�ֵľ���Ӧ�á�һ�������ڻ���֮ǰ����Ҫ�Կͻ��Ļ�����������������������ͻ��������Ƚ��Ӵ��Ŵ������Ա��ѹ����dz���ʱ������ϣ��ͨ������������и������ߡ����ɭ���㷨�����ڸó�����ʹ�ã�������Խ�ԭ�е���ʷ�������뵽���ɭ���㷨���н�������ѵ��������ѵ����õ���ģ�Ͷ��µĿͻ����ݽ��з��࣬��������Թ��˵����������������Ŀͻ�����˱��ܼ���ؼ����Ż������Ա�Ĺ�������
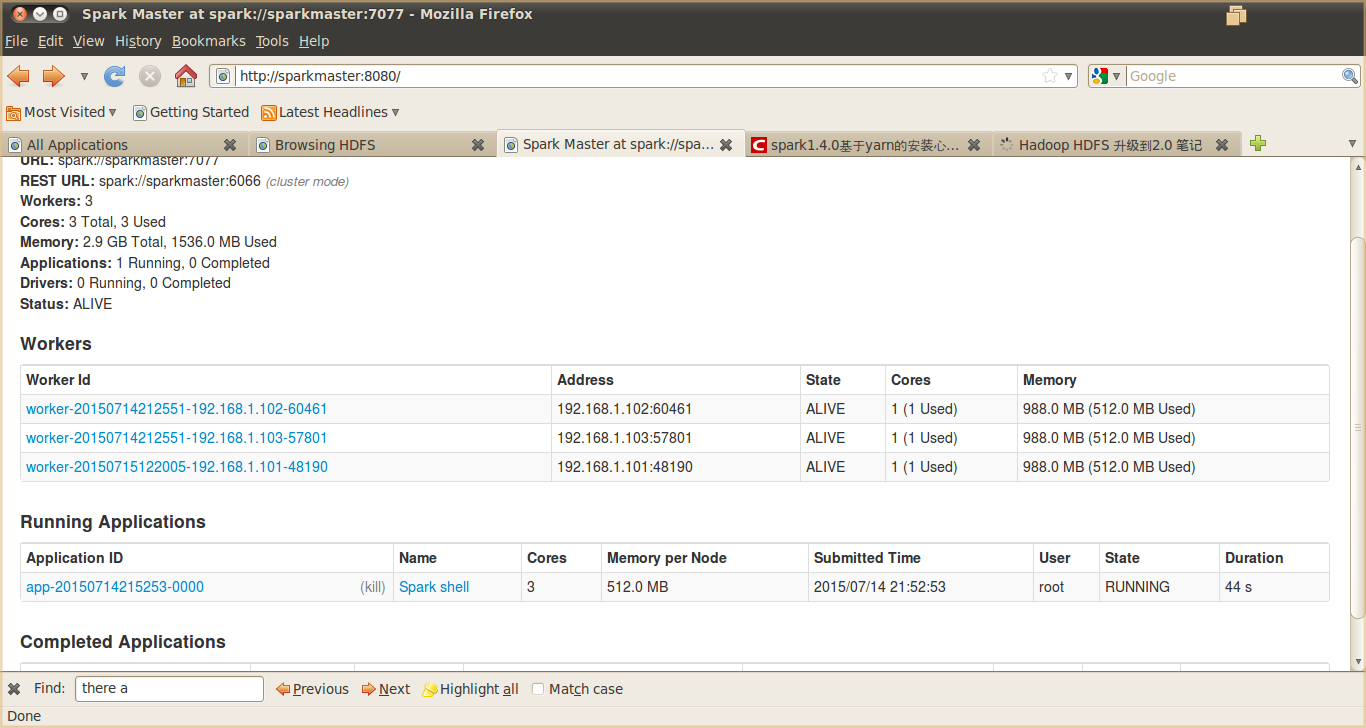
ͼ 9. Spark ��Ⱥ����Ч��ͼ
������������Ŵ��û���ʷ�����¼��
�� 2. �Ŵ��û���ʷ�������ݱ�
�����Ŵ��û���ʷ�����¼����ʽ��Ϊ label index1:feature1
index2:feature2 index3:feature3 ���ָ�ʽ�������ϱ��еĵ�һ����¼������ʽ��Ϊ
0 1:0 2:1 3:10�����ֶκ������£�
�Ƿ�߱��������� �Ƿ�ӵ�з��� ���������0 ��ʾ������ ������
0 ��ʾ�ǣ�1 ��ʾ�� 0 ��ʾ��1 ��ʾ�� 1 ��ʾ�ѻ顢2 ��ʾ���
����ʵ������
0 1:0 2:1 3:10
��������������ת������Ϊ sample_data.txt������������ѵ�����ɭ�֡���������Ϊ��
�� 3. �������ݱ�

������ɭ��ģ��ѵ����ȷ�Ļ������������û����ݵõ��Ľ��Ӧ���Ǿ߱�����������Ϊ������ڴ��������ǽ��䱣��Ϊ
input.txt��������
0 1:0 2:1 3:12
�� sample_data.txt��input.txt ���� hadoop
fs �Cput input.txt sample_data.txt /data �ϴ��� HDFS �е�/data
Ŀ¼���У��ٱ�д���嵥 9 ��ʾ�Ĵ��������֤
�嵥 9. �жϿͻ��Ƿ���л�������˵
package cn.ml
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.mllib.util.MLUtils
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.rdd.RDD
import org.apache.spark.mllib.tree.RandomForest
import org.apache.spark.mllib.tree.model.RandomForestModel
import org.apache.spark.mllib.linalg.Vectors
object RandomForstExample {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setAppName("RandomForestExample").
setMaster("spark://sparkmaster:7077")
val sc = new SparkContext(sparkConf)
val data: RDD[LabeledPoint] = MLUtils.loadLibSVMFile(sc,
"/data/sample_data.txt")
val numClasses = 2
val featureSubsetStrategy = "auto"
val numTrees = 3
val model: RandomForestModel =RandomForest.trainClassifier(
data, Strategy.defaultStrategy("classification"),numTrees,
featureSubsetStrategy,new java.util.Random().nextInt())
val input: RDD[LabeledPoint] = MLUtils.loadLibSVMFile(sc,
"/data/input.txt")
val predictResult = input.map { point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
//��ӡ���������� spark-shell ��ִ��ʱʹ��
predictResult.collect()
//��������浽 hdfs //predictResult.saveAsTextFile("/data/predictResult")
sc.stop()
}
} |
��������ȿ��Դ�������� spark-summit �ύ����������ִ�У�Ҳ������
spark-shell ��ִ�в鿴���. ͼ 10 ������ѵ���õ���RadomForest ģ�ͽ����ͼ
11 ������ RandomForest ģ��Ԥ��õ��Ľ�������Կ���Ԥ������Ԥ����һ�µġ�
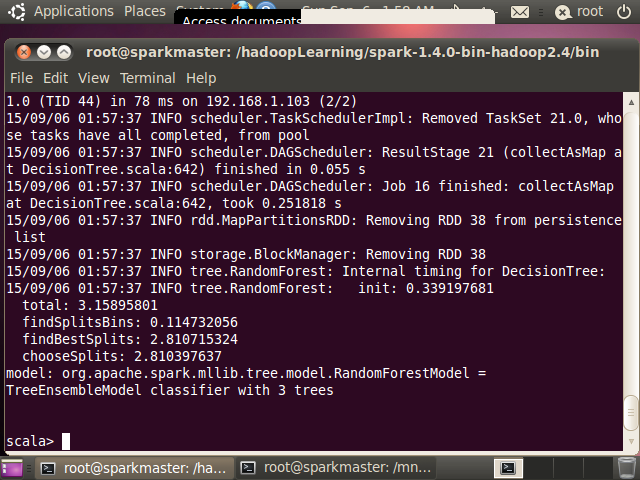
ͼ 10. ѵ���õ��� RadomForest
ģ��
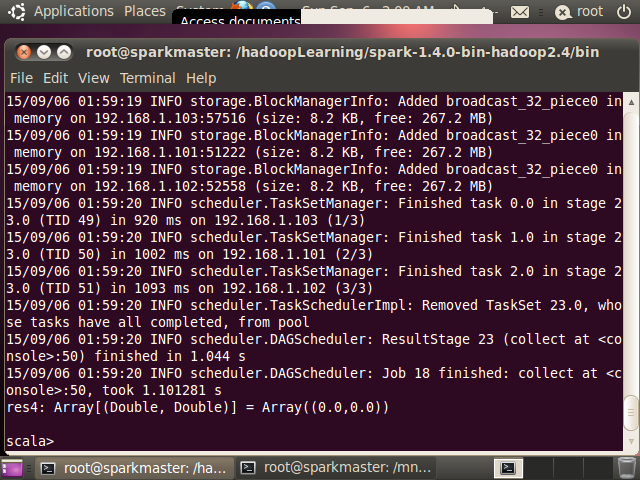
ͼ 11. collect �������صĽ��
������
���Ķ����ɭ���㷨������������������ȷ����˾������㷨��ԭ����ָ������ڹ���������⣬Ȼ��ָ�����ɭ���㷨�ܹ��ܺõر�������⣬��Ϊ���ɭ��ͨ�����ɾ���������ͶƱ���������յ�Ԥ����������Ϊ������ɭ�ֲַ������µ�Ч�����⣬������չʾ�����ɭ���ڷֲ�ʽ�����µ��Ż����ԣ��ڴ˻����϶���
Spark �ϵĺ���Դ������˷����������������ɭ���㷨��һ��ʵ�ʰ���������ҳ�����������ø��㷨�������ʿͻ��ķ��ࡣ
|






