|
摘要:一些大数据客户想分析新数据以对特定事件作出响应,他们可能已经定义好管道来执行批处理操作,这些管道是由AWS Data Pipeline精心协调安排的。
一些大数据客户想分析新数据以对特定事件作出响应,他们可能已经定义好管道来执行批处理操作,这些管道是由AWS Data Pipeline精心协调安排的。事件触发管道的示例之一就是当数据分析师在一收到数据就必须对其进行分析时,以便他们可以立刻向合作伙伴作出相应。在这种情况下调度不是最优的解决方案,主要问题是如何在任意时间使用依赖于调度程序的Data Pipeline调度数据处理过程。
这里有一个解决方案。首先,创建一个简单的管道,使用来自Amazon S3的数据对管道进行测试,然后添加一个Amazon SNS主题,使其在管道完成时通知客户,以便数据分析师能够查看处理结果。最后,创建一个AWS Lambda函数,使其在新数据被成功提交到S3桶中时激活Data Pipeline,在此过程中,不用管理任何调度活动。该篇帖子将会向你展示如何实现这一过程。
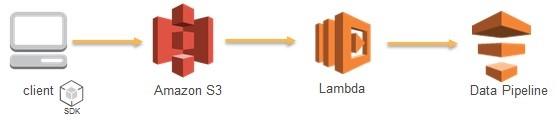
在Data Pipeline活动可被调度时,客户可以定义先决条件。这些先决条件可以看到数据是否存在于S3中,然后进行资源分配。但是,在Data Pipeline需要随时被激活时,使用Lambda是一种很好的途径。
克隆管道以备后用
在这种场景下,客户的管道已经通过一些预定的活动被激活,但是想要能够调用相同的管道以对某个特别事件,如提交新数据到S3桶中,作出响应。客户已经开发了一个达到Finished状态的“模板”管道。
重新发起该管道的一种方法是在S3中使用管道定义来保存JSON文件,使用它创建一个新管道。一些客户在S3中对相同管道以多个版本的形式存储,但是又想克隆和重新使用最近刚刚执行的那个管道版本。从已完成管道中获取管道定义并创建一个克隆管道,这是可以满足这种要求的简单方法。这种方法依赖于最近被执行的管道,不需要客户保存来自S3的管道版本注册表,也不需要追踪最近被执行的版本。
即使客户想在S3中保留这样的一个管道注册表,他们可能也想使用Lambda API即时从一个既存的管道中获取一个管道定义。他们可能有复杂的事件驱动工作流程,在这些流程中,他们需要克隆已完成的管道,重新运行它们,然后删除克隆的管道。这就是为什么首先检测处于Finished状态的管道是如此重要了。
在本篇帖子中,我会向你展示如何完成这样即时的管道克隆。在Data Pipeline中没有直接克隆API,所以你可以进行几次API调用完成这一过程。我也提供了代码,使你能够删除已完成的过时的克隆管道。
三步式工作流程
- 创建一个简单管道用于测试。
- 创建一个SNS通知,在管道完成时通知分析师。
- 创建一个Lambda函数,在新数据被提交到S3桶中时激活管道
第一步:创建一个简单管道。
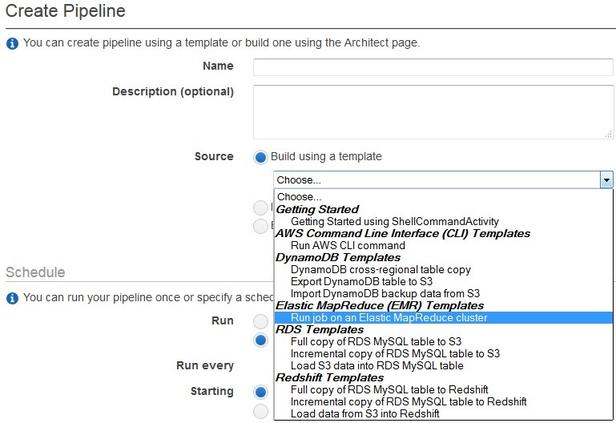
- 打开AWS Data Pipeline控制台。
- 如果在该域中还没有创建管道,控制台屏幕将会展示介绍性的信息。在这种情况下,选择Get started now。如果在该域中你已经创建过管道了,控制台将会显示你在该域中创建的所有管道。在这种情况下,选择Create new pipeline。
- 输入名称和描述信息。
- 选择一个Elastic MapReduce (EMR)模板,然后选择Run once on pipeline activation。
- 在Step字段中,输入如下信息:
/home/hadoop/contrib/streaming/hadoop-streaming.jar,-input,
s3n://elasticmapreduce/samples/wordcount/input,-output,
s3://example-bucket/wordcount/output/#{@scheduledStartTime},-mapper,
s3n://elasticmapreduce/samples/wordcount/wordSplitter.py,-reducer,aggregate |
你可以调整Amazon EMR集群节点的数量,选择分发方式。想要获取管道创建的更多信息,参见Getting Started with AWS Data Pipeline。
第二步:创建一个SNS主题
想要创建一个SNS主题,执行以下步骤:
- 在浏览器的一个新页签中,打开Amazon SNS console(Amazon SNS控制台)。
- 选择Create topic。
- 在Topic name字段中,输入主题名称。
- 选择Create topic。
选择新主题,然后选择主题ARN。Topic Details页面出现
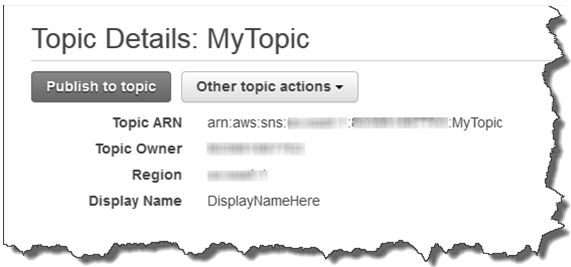
- 拷贝主题ARN用于下一个任务。
- 为该主题创建订阅任务,提供你的电子邮件地址。AWS会发送电子邮件来确认你的订阅结果。
想要在管道中配置主题通知动作,执行以下步骤
- 在AWS Data Pipeline控制台,在Architect窗口中打开你的管道。
- 在右侧窗格中,选择Others。
- 在DefaultAction1下,执行如下步骤:
- 输入通知的名称(如MyEMRJobNotice)
- 在Type字段中,选择SnsAlarm。
- 在Subject字段中,输入事由行。
- 在Topic Arn字段中,输入主题的ARN。
- 在Message字段中,输入消息内容。
- LeaveRoleset to the default value.Role保留其默认值。
保存并激活管道,确保它能成功执行。
第三步:创建一个Lambda函数
在Lambda控制台中,选择Create a Lambda function。你可以选择一个蓝图或者只是跳过第一步,继续进行Step 2: Configure function(第二步:配置函数),在该步骤中,你提供一个函数名称(如LambdaDP)和一条描述信息,选择Node.js作为Runtime字段的值。
测试管道已经完成。目前仍不支持重新运行已完成的管道。要想重新运行一个已完成管道,从模板中克隆该管道,Lambda会触发一个新管道。每一次清除老的克隆管道时,你将需要Lambda来创建一个新克隆管道。下面是帮助实现新管道克隆的一些函数。在Lambda控制台中,使用Code entry type和Edit code inline字段,以下面的代码开始:
console.log('Loading function'); var AWS = require('aws-sdk'); exports.handler
= function(event, context) { var Data Pipeline = new AWS.Data Pipeline();
var pipeline2delete ='None'; var pipeline ='df-02….T'; ………. } |
定义管道ID,为克隆管道ID创建一个变量,比如pipeline2delete。然后,添加一个函数,执行下面的代码,检查前面的运行过程中遗留下来的既存克隆管道:
//Iterate over the list of pipelines and check if the pipeline clone already
exists Data Pipeline.listPipelines(paramsall, function(err, data) { if
(err) {console.log(err, err.stack); // an error occurred} else {console.log(data);
// successful response for (var i in data.pipelineIdList){ if (data.pipelineIdList[i].name
=='myLambdaSample') { pipeline2delete = data.pipelineIdList[i].id; console.log('Pipeline
clone id to delete: ' + pipeline2delete); }; |
如果前面的运行过程中遗留下来的已完成克隆管道已经被识别出来,你必须在该循环中调用删除函数。下面展示了实现调用的示例代码:
var paramsd = {pipelineId: pipeline2delete /* required */};
Data Pipeline.deletePipeline(paramsd, function(err, data) {
if (err) {console.log(err, err.stack); // an error occurred}
else console.log('Old clone deleted ' + pipeline2delete + ' Create new clone now');
}); |
最后,你需要进行三次API调用,从原来的Data Pipeline模板中创建一个新的克隆。下面是你可以使用的API:
- getPipelineDefinition (for the finished pipeline)
- createPipeline
- putPipelineDefinition (from #1)
下面是这三次调用的示例:
1、使用管道定义创建下一个克隆:
var params = {pipelineId: pipeline};
Data Pipeline.getPipelineDefinition(params, function(err, definition) {
if (err) console.log(err, err.stack); // an error occurred
else {
var params = {
name: 'myLambdaSample', /* required */
uniqueId: 'myLambdaSample' /* required */
}; <b>
</b> |
2、使用来自定义对象的克隆定义:
Data Pipeline.createPipeline(params, function(err, pipelineIdObject) {
if (err) console.log(err, err.stack); // an error occurred
else { //new pipeline created with id=pipelineIdObject.pipelineId
console.log(pipelineIdObject); // successful response
//Create and activate pipeline
var params = {
pipelineId: pipelineIdObject.pipelineId,
pipelineObjects: definition.pipelineObjects//(you can add parameter objects and values) |
3、使用来自getPipelineDefinition API结果的定义:
Data Pipeline.putPipelineDefinition(params, function(err, data) {
if (err) console.log(err, err.stack);
else {
Data Pipeline.activatePipeline(pipelineIdObject,
function(err, data) { //Activate the pipeline finally
if (err) console.log(err, err.stack);
else console.log(data);
});
}
});
}});
}}); |
现在你具备了Lambda函数所需的所有函数调用过程。你也可以执行下面的步骤将这些调用过程打包成一个独立的函数:
输入Handler字段的值作为函数(LambdaDP.index)的名称。
Role。该选项可以使你访问像S3和Data Pipeline这样的资源。
- 保留Memory和Timeout的默认值。
- 选择Next,检查函数,选择Create function。
- 在Event source字段中,选择S3。
- 提供管道所使用的桶的名称。
- 在Event type字段,选择Put。在新文件被提交到桶中时,该选项会激活管道。
- 保存管道,上传一个数据文件到S3桶中。
- 检查Data Pipeline控制台,确保新管道已经创建完毕并已被激活(管道完成后,你应该能收到一条SNS通知消息)。
|






