|
摘要:如今,eBay的买家分布于全球190+国家,超过2500万活跃卖家,1.57亿活跃买家,8亿活跃商品,通过Connected Commerce连接着全球各地的买家和买家,2014年产生超过2550亿美元的GMV,其中来自移动端的GMV超过280亿美元。
eBay, 全球最大的在线交易平台,由程序员Pierre Omidyar于1995年劳动节周末在美国创立,起初叫AuctionWeb,于1997年7月正式改名为eBay,今年九月将迎来其20周年纪念。
eBay第一笔交易是一只破损的激光笔,成交价14.83美元,Pierre主动联系买家以确信其知道这是一只破损的激光笔,而买家则回复“我是一个破损激光笔收藏家”。从此,eBay 20年的发展正式开始了,带领了电子商务产业的极速成长,如今,eBay已经成为全球最大的在线交易网站,买家分布于全球190多个国家,超过2500万活跃卖家,1.57亿活跃买家,8亿活跃商品,通过Connected Commerce连接着全球各地的买家和买家,2014年产生超过2550亿美元的GMV,其中来自移动端的GMV超过280亿美元。据统计,在美国每五秒售出一个手袋,在澳大利亚每分钟通过移动端售出一双鞋,在德国每10分钟通过移动端售出一辆汽车或卡车。
如此大量的用户及交易下,数据成为eBay的重中之中,从点击流到搜索,商品查看,交易以及愿望清单等不断进行收集。在eBay数据平台中存储着超过100PB的数据,其关键是如何获取、存储、加工和分析数据,并释放数据的价值使之成为行动指南,而各个大数据平台,则在各个方面为上万名分析师及业务用户提供了坚实的保障和基础,并不断创新以满足日新月异的变革和需求。
eBay目前的大数据平台分为三层,数据整合层:负责数据获取,处理及清洗等ETL工作,包括批处理及实时处理能力,包括相关的商业产品和开源产品;数据平台层:主要由传统数据仓库(EDW),基于Teradata集群,总容量超过10PB;奇点(Singularity),存放半结构化及深层次结构化数据存储,总容量超过36PB;以及Hadoop集群,总容量超过100PB;数据访问层:通过各种工具,平台为业务用户和分析师提供访问和分析相关数据的能力,包括各种商业工具,开源产品及自研的各种平台等。本文将着重介绍eBay在相关领域的发展,平台及未来发展趋势。
Connect with Hadoop
1. Hadoop在eBay的发展历史
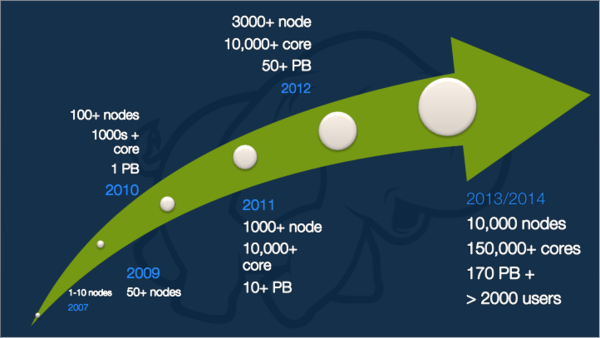
eBay最早的Hadoop应用是在eBay研究实验室(eBay Research Lab, eRL)构建,主要用作日志分析,以期提高每天的日志处理速度。最初的版本是0.18.2,4个节点,存储并处理约几百GB的日志,最大的处理能力为44个Map。
随后,eBay搜索团队构建了10个节点的集群开始了Hadoop在eBay搜索领域的发展,并在2012年上线了基于HBase的搜索平台:Cassini。
2010年,eBay 上线了基于CDH2的集群,拥有532个节点,超过5PB的存储容量,并于2012年上线了基于HDP的集群,超过3000个节点,容量超过50PB。2014年,总节点数据超过10000多个,存储容量超过170PB,活跃用户超过2000多,现在,相关规模还在不断增长中。随之带来的管理、监控、分析和存储的挑战越来越严峻。
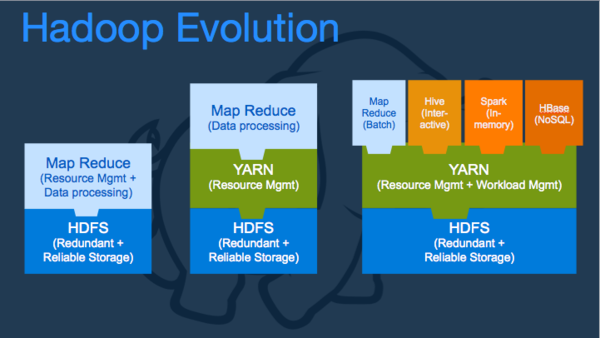
基础架构的创新主导了Hadoop 的进化,从最初的基于HDFS和MapReduce的批处理应用不断演变,第一代的Hadoop提供了灵活和可扩展的数据结构和处理能力,并在大数据兴起之时满足了公司各种大小数据处理需求提供了民主化需求。然而毕竟其只是第一步,有着各种限制,如果将其对比于操作系统的话, 第一代Hadoop就如操作系统和应用,例如记事本捆绑在一起,且仅有一个应用,即MapReduce。然而随之而来的大量任务导致了调度瓶颈,从而促成了YARN(Yet Another Resource Negotiator)项目的成立和发展,其解决了JobTracker在超大规模集中成为瓶颈等问题,并支持各种应用通过YARN来进行资源调度和管理从而将Hadoop带入了下一个时代,
下一代的Hadoop取得了巨大的跃进,从面向批处理到提供交互式的处理能力。并提供了战略性的决定以支持独立的执行模式,例如MapReduce可以作为YARN上的一个应用运行。从此,通过YARN,Hadoop变成一个真正的数据操作系统。
现在,从交易型数据库,文档数据库及图数据库的数据都可以存储在Hadoop之上,通过基于YARN的应用可以访问数据而无需复制或者在不同的应用中移动数据,包括MapReduce、Hive、HBase以及Spark等各种应用。从而提供了非常丰富的数据处理和创新能力。一个统一的数据存储,利用的平台将是确定的趋势。
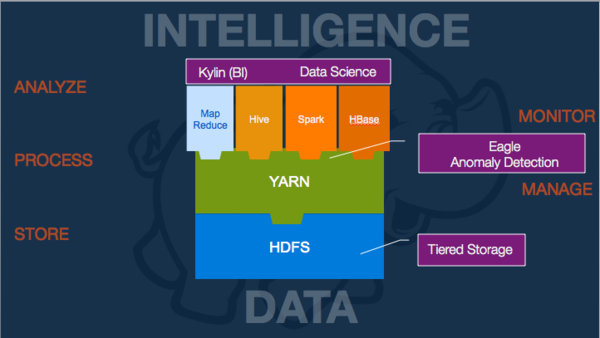
2. 分层存储
当前普遍的认知是使用廉价硬件组建Hadoop集群以存储超大容量数据及提供计算能力,例如,一个1000节点的集群,每个节点附带20TB的存储能力,则整个集群可以存储20PB的数据。所有的机器都有足够的计算能力以实现Hadoop的名言:“Moving Computation is Cheaper than Moving Data”。
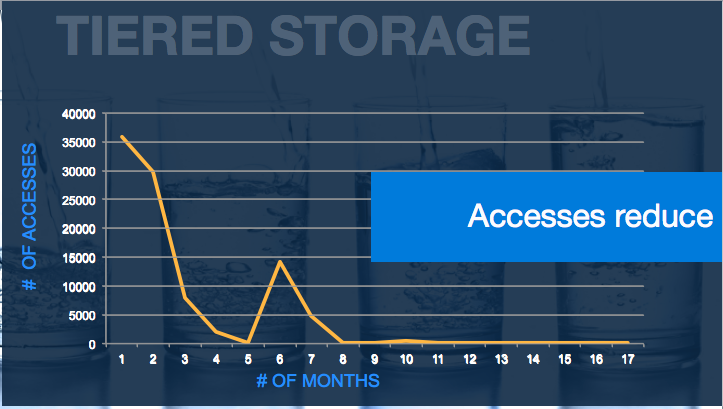
不同类型的数据集通常都存放在同一个集群中,并被不同的团队共享以运行各种应用来满足业务需求。而数据的一个共同特点是其使用率会随着时间而逐渐降低,越新的数据使用率越高,而越旧数据的访问次数逐渐降低。初次生成的数据有着最大的使用率,我们将其定义为Hot,基于我们的分析,一周内访问量下降的数据被称为Warm,而之后三个月内只有少量访问的数据被称为Cold。最后,访问率降低到每年仅有几次甚至为零的数据集被称为Frozen,如下表:

由此分析,将不同热度的数据存放在同一个集群,使用相同的计算和存储资源则变得越来越有问题,随着时间的增长,冷数据越来越多,将占据宝贵的存储和计算资源,而当有更多热数据需要进来或者作大量计算的时候,相应的存储变成了瓶颈,很多其他公司甚至提到了删除低价值数据等做法。在管理和运维超大Hadoop集群时如何处理不同热度的数据成为非常迫切的需求和现实挑战。
将低热度数据集与高热度数据集作不同存放的策略已势在必行,在Hadoop 2.3中,HDFS支持了分层存储,通过在集群中添加归档存储能力为冷数据提供深层存储能力,且保持对于上层应用的透明性。由于数据依然在同一个集群中,因此当请求需要访问相应冷数据时依然可以及时获得。例如,我们可以为上面的例子中添加100个节点,每个节点附带200TB存储但仅使用有限的计算资源,于是整个集群的总量将变为40PB (20PB 磁盘+20PB归档)。通过相关数据策略,将不同热度的数据分布到不同存储上,例如,假设每份数据按Hadoop默认设置复制三份,对于Hot型数据则将三份数据全部存放在快速磁盘上,对于Warm类型数据仅存放一份拷贝在快速磁盘而其余两份放到归档存储,将Cold和Frozen数据全部存放于归档中。从而将不同的数据进行有效分配,示例如下图:
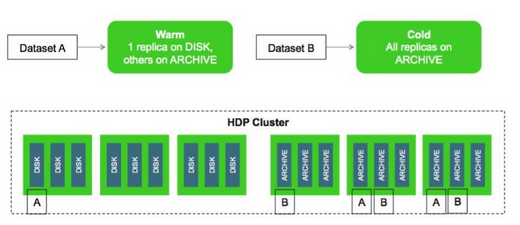
分层存储已经在eBay最大 Hadoop集群上使用,该集群拥有40PB的存储,我们为之添加了额外的10PB存储,每个节点附带220TB容量,由此将Warm、Cold及Frozen数据集逐步进行迁移。而由于仅需有限的计算能力,这些节点的每GB成本比其他节点便宜4倍左右。后续,eBay将持续在这方面进行研究和投入,例如SSD存储等。
3. 监控、告警及自动化运维
当集群数量达到成千上万的规模时,监控、告警及自动化运维是保障数据高可用性及为上层应用提供持续服务的基础。在eBay的日常工作中,Hadoop集群的管理和维护任务相当繁重,而现有的管理和监控工具无法满足多集群,大规模及分布式收集日志,监控数据的需求。因此eBay研发了名为Eagle的集群监控告警平台。
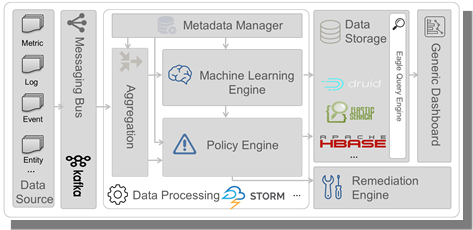
Eagle主要由基础的核心框架以及针对不同应用领域的诸多app组成,专注于解决大数据时代大型分布式系统自身监控这个复杂的大数据问题,具有高扩展性、高实时性,以及高可用性等特点,同时支持使用机器学习为复杂情况提供预测分析。
轻量级分布式流处理框架:以DAG为基础模型对通用流处理范式进行抽象,在开发期用户只需基于DSL API定义监控程序的流式处理逻辑,运行期再选择实际物理执行环境,默认支持单进程和Storm,同时也支持对于其他执行环境的扩展,比如Spark Streaming 或者 Flink等。
实时流聚合引擎:提供简单易用的实时流聚合规则定义语法,元数据驱动,动态部署,实现线性扩展的实时监控数据流聚合。
分布式Policy引擎:分布式实时预警规则执行引擎,提供类SQL的描述性规则定义语法以及机器学习自动等多种扩展,支持预警规则的动态加载和分区。
存储和查询框架:通用监控数据存储框架,可用于存储和查询日志、指标、警报、事件等多种类型数据,默认支持HBase,并针对HBase进行多种优化和扩展,比如coprocesser,二级索引以及分区等,也支持其他存储类型的扩展比如RDBMS等,并提供通用的ORM, REST API以及易用强大的类SQL查询语法。
可定制化监控报表:提供类Notebook的交互式实时可视化分析,也支持进一步选取部分图标,并定义布局保存为dashboard以供分享或者持续监控。
除了对日常集群指标监控外,Eagle集成了Job Performance Analyzer(JPA),通过实时监控Hadoop 平台上的作业当前和历史执行状态,提供多维度不同粒度的性能分析,支持多种异常预警和性能警告,比如作业运行时间过长、读写过慢、数据倾斜、失败任务比率过多等,可有效在作业无法满足SLA之前提供预警和性能建议。
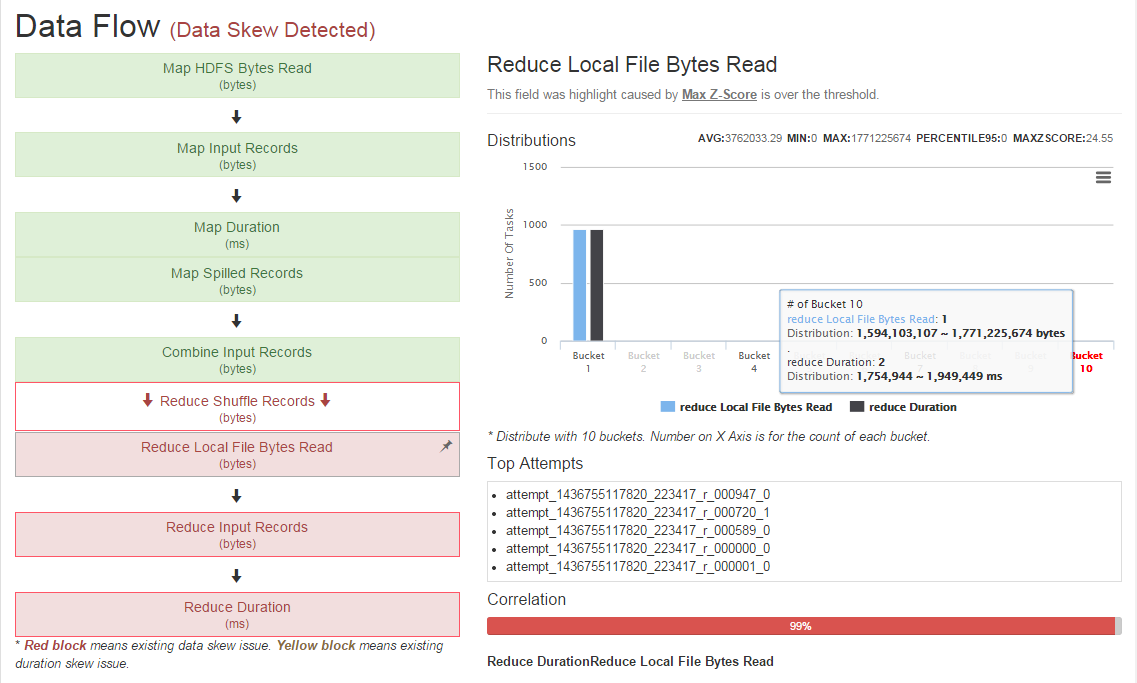
同时结合机器学习模型,基于任务分布或指标变化等协同预测任务或者服务器节点等可能潜在的异常,并集成Remediation系统对系统进行自动修复。同时,针对异常用户行为,危险操作等,开发了Eagle DAM(Data Activities Monitoring)的安全监控应用,通过自定义策略及机器学习模型,对关键数据,操作等进行监控和报警,防范于未然。
4. 在线交互分析
当数据规模随着用户群体的多样化拓展而不断增长时,我们的用户,比如分析师与业务部门,希望能在保持最低延迟水平的前提下继续使用自己所熟悉的工具和方式来访问和分析存储于Hadoop之上的超大规模数据集,并且希望数据的获取、处理、存储和分析同时在Hadoop集群上完成,而无需再将数据从一个数据源迁移到另外一个数据源。在研究和评估了多种开源及商业产品后,eBay中国研发中心于2013年中正式立项启动了OLAP on Hadoop项目,并在2014年10月开源,之后贡献给了Apache基金会,现在正在孵化阶段。
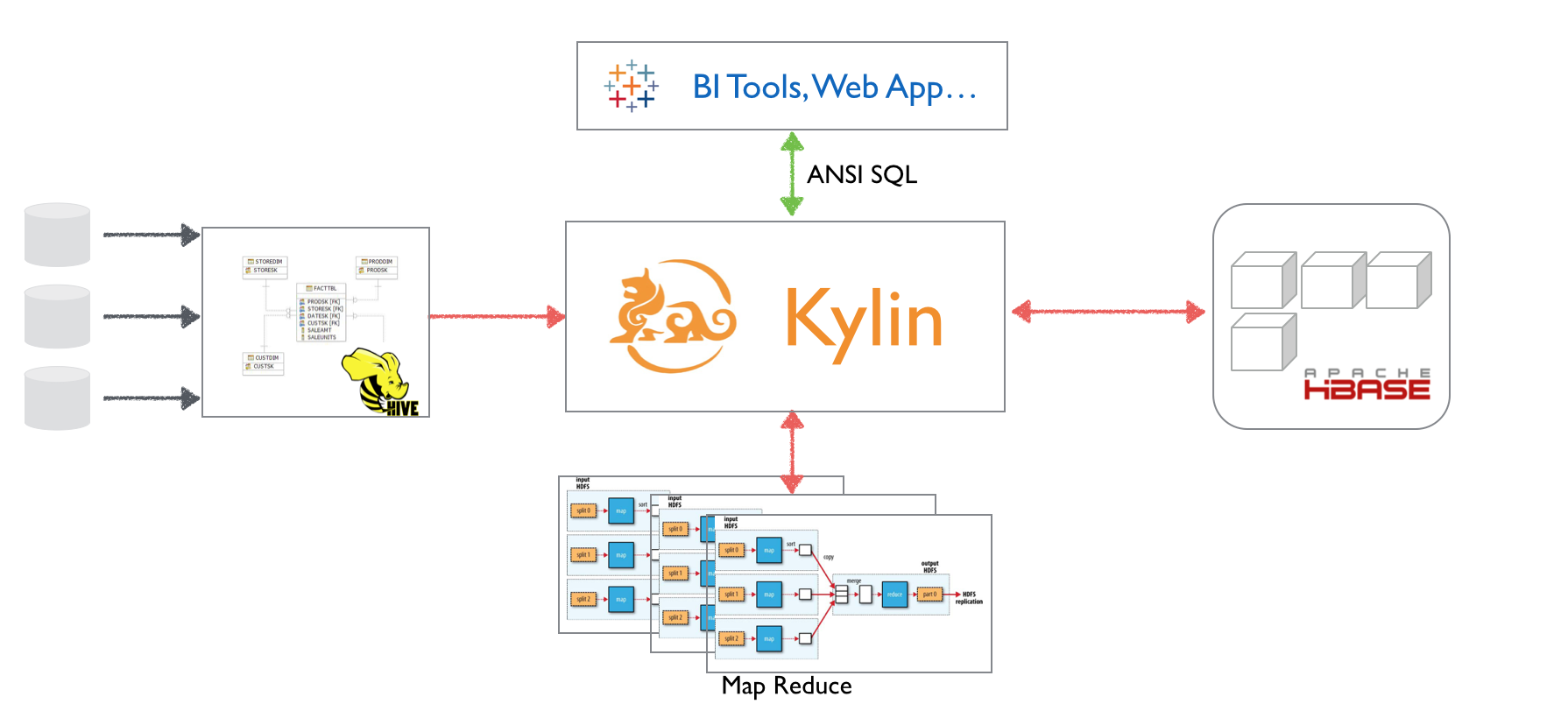
Apache Kylin通过映射Hive中星型结构的表,由建模者定义相关维度和度量及其他设置而生成元数据,构建引擎基于元数据自动生成相关的Hive查询,一系列的MapReduce 任务及HBase操作,从而将数据从Hive中读出并进行预先计算,将结果存放到HBase。之后,相同数据模型的查询都将直接读取已经被计算好的存放于HBase中的数据,从而实现秒级甚至亚秒级查询延迟。
在该项目初始阶段调研和评估过包括Impala,Stinger,Phoenix on HBase, Teradata,MicroStrategy等多种开源和商业选项,最后发现没有一种可以满足eBay实际业务需求,为超大规模数据集提供秒级交互式查询能力。开发团队在研究过众多技术、论文和参考实现后,最终选择了MOLAP的方式,即为数据模型作预先计算,以空间换时间的方式,为前端业务用户和分析师提供在TB甚至PB级别数据集上交互式的查询能力。

在上面的拓扑图中,最下面的节点为实际数据,而之上的每一个节点则代表了一种维度组合,理论上所有的SQL查询都能被该拓扑图覆盖,因此进行相关的预先计算后,只要引擎能正确解析查询语句并访问正确的数据存放地址就可以在极短的时间内获得结果。在实际开发过程中,Kylin系统有效地降低了维度,减少了非必要组合的计算,增加了多种压缩和编码算法,例如Trie字典编码技术、Partial Cube计算、分组聚合等等。实际生产环境中,90%ile的查询延迟在1.5秒,95%ile小于5秒(最近30天)。
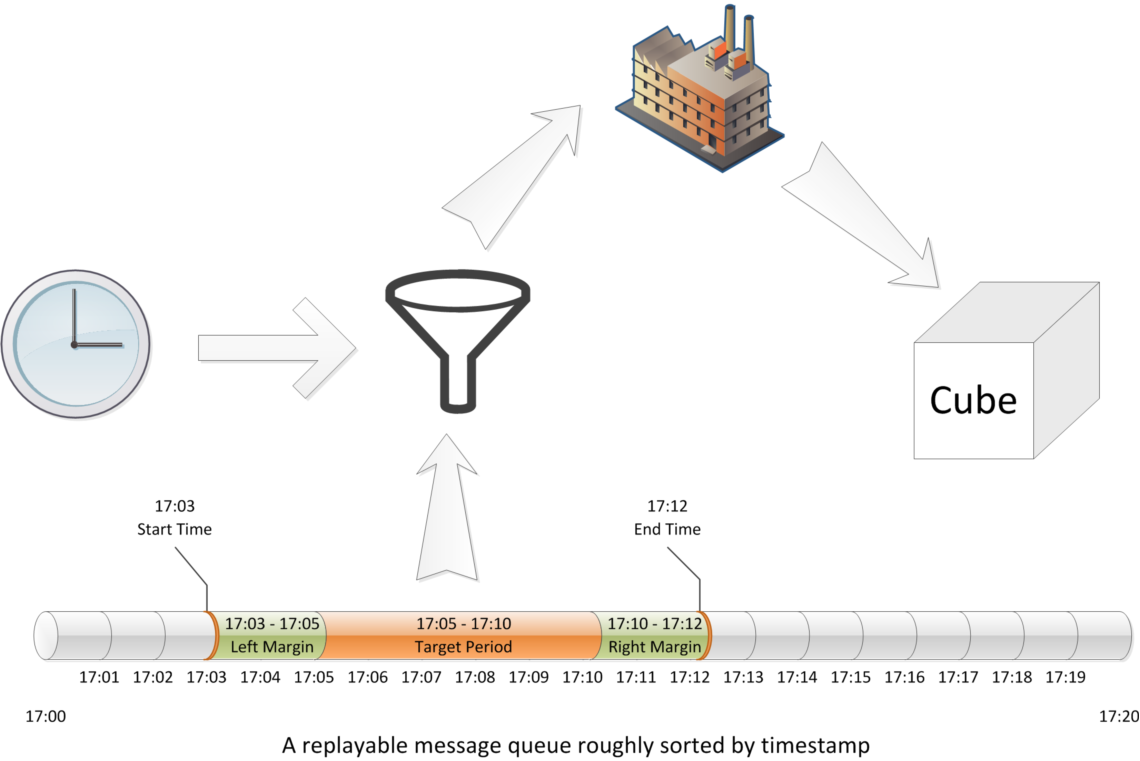
虽然基于MOLAP的应用系统已经为相关的业务用户提供了在大规模数据集上的查询应用,但由于构建Cube需要花费大量的系统资源和时间,一方面对集群带来了较大的压力,另一方面很难满足对实时型要求高的需求。因此,Kylin团队为此研发了下一代架构,通过Micro Batch模式对流数据进行支持,如下图所示,每隔固定的时间读取来自上层数据流中的数据并促发聚合,最终导入到目标Cub俄中,目前已经在eBay内部上线相关案例并取得了良好的反馈。
另外,对于Cube引擎也引入了新的算法,实测结果表明能够提供一倍以上的构建速度,并大大降低对系统资源的要求。此外,我们对Spark也投入了相关的研究,第一版的Spark Cubing引擎业以完成并准备上线实测。
5. 数据生态
以上简要介绍了eBay最近几年在大数据平台方面的发展和主要实践,基础平台的发展和建设离不开用户,合作伙伴以及管理层帮助和指导,在这个过程中,也逐渐构建起基于Hadoop及企业级数据仓库的数据生态,各个业务单位,分析团队利用相关平台和数据为支持极速变化的业务和快速增长的数据提供丰富的分析和决策支持,共同构建eBay的大数据生态。
连接每个人
通过大数据平台及应用,eBay能为买家和卖家提供更加良好的用户体验和服务,不断满足日益变化的市场和环境,并通过创新的技术来降低对环境的影响和依赖。今天,eBay知道你,明天,eBay将理解你并连接你与未来。
关于作者:韩卿(Luke)
eBay 分析平台基础架构部产品负责人,带领团队构建eBay全球分析平台及产品,包括Hadoop/Spark,OLAP,商务智能等。韩卿也是Apache Kylin 的co-creator & PMC member, 负责Kylin产品的设计,规划,战略和执行,构建开源社区及开拓内外部客户,合作伙伴等。
eBay 分析平台基础架构部(Analytics Infrastructure)是eBay的全球数据及分析基础架构部门,负责eBay在数据库,数据仓库,Hadoop,商务智能及机器学习等各个数据平台的开发,管理等,支持eBay全球各部门运用高端的数据分析解决方案作出及时有效的业务决策,为遍布全球的业务用户提供数据分析解决方案。 |






