|
本文将介绍多个在 Mesos 上进行复杂数据分析的框架。我们会介绍如何在
Mesos 上搭建 Storm 和 Spark Streaming 来处理实时数据流,以及如何在 Mesos
上运行 NoSQL 数据库 Canssandra。
复杂数据和 Lambda 架构的兴起
大数据的爆炸式增长不仅体现在生产的数据量上,也体现在要求处理海量数据得到有意义结果的速度和多样性上。因此,数据和计算的速度推动开发人员开发实时流处理框架,同时,数据天然的多样性和松散性也促进了NoSQL的演进。
随着物联网(Internet of Things,IoT)的兴起,传感器、社交媒体、机器事务、监控等都在大规模地高速产生数据。这些数据能够提供的信息非常有价值,但是如果数据的分析结果有延迟,或者仅能分析过期数据,那么这些数据就会丧失价值。前一章我们介绍了使用
Hadoop 和 Spark 可以处理的数据量。这些传统工具很适合被用来完成批处理或离线分析,但是它们不是为实时流分析或低延时应用程序设计的,比如,类SQL查询处理。
当流处理在现代数据架构中日益重要时,现代数据架构出现了其他一些组件。现代数据架构包括服务不同需求的不同组件。Lambda
架构(http://en.wikipedia.org/wiki/Lambda_architecture)是十分流行的设计数据架构的方式。
它主要包括三层:
批处理层
速度层
服务层
在 Mesos 上运行 Lambda 架构不仅可以共享资源,而且可以帮助容错。批处理层的理念是通过随时处理收集到的数据来导出处理结果的,比如,构建预测模型。前一章已经演示了在
Mesos 上如何使用 Hadoop 和 Spark 进行数据处理。Apache Hama(https://hama.apache.org)是批处理层的另一种框架。它是通用的块同步处理(Bulk
Synchronous Processing,BSP)框架,在图像处理和矩阵计算领域非常有用。
随着多样化新数据的产生速度不断加快,仅依赖离线模型,周期性地离线处理数据已经不能满足需求。速度层的理念是在数据生成时就完成处理。该层主要进行流处理,也被称为复杂事件处理(Complex
Event Processing,CEP)或实时处理。Mesos 支持 Apache Samza、Apache
Storm 和 Spark streaming 框架来实现速度层。Apache Samza(http://samza.apache.org)是构建在
Apache Kafka 框架之上的流处理框架。有项目正在将 Samza 集成到 Mesos 里(https://github.com/Banno/samza-mesos)。下一节会讨论
Apache Storm 和 Spark Streaming。注意不同的流处理框架使用不同的架构,在速度、支持的操作、一致性语义和可扩展性之间采用不同的权衡措施。
服务层负责存储批处理和速度层的输出,并且基于这些输出提供查询服务。Mesos
提供了越来越多的选择,为存储和服务数据构建可扩展层。
HDFS(Hadoop 分布式文件系统)在普通硬件上提供分布式文件系统,第 2 章里有过详细介绍。有项目正试图在
Mesos 上运行 HDFS 来提供高可用的 HDFS。
Tachyon(http://www.tachyonproject.org)是以内存为中心的存储系统。在
https://github.com/mesosphere/tachyon-mesos 处有 Mesos
上 Tachyon 的原型版本。
Riak(https://github.com/basho/riak)是分布式的键值存储。有项目正试图让其能在
Mesos 上工作(https://github.com/edpaget/riak-mesos)。
Elasticsearch(https://elasticsearch.org)是分布式全文本搜索引擎。ElasticSearch
可以在 Mesos 上运行(https://github.com/mesosphere/elasticsearch-mesos)。
Apache Canssandra(http://cassandra.apache.org)是
NoSQL 数据库,下文会讲述如何将其运行在 Mesos 上。
除了这三个层次之外,还需要三层之间的连接器来接收数据,发送到其他层。Apache
Kafka(http://kafka.apache.org)是分布式发布-订阅(也称为pub/sub)消息系统。Pub/sub系统是现代数据架构的后台机制。它们以松散的方式将不同的数据处理框架连接起来,适用于多种应用场景。有项目正在积极地将Kafka集成到Mesos里(https://github.com/stealthly/kafka-mesos)。另外,随着越来越多的框架使用即将发布的
Mesos 里的持久化存储(https://issues.apache.org/jira/browse/MESOS-1554),Mesos
上的复杂数据处理会越来越健壮。这并不意味着,复杂数据分析需要复杂的工具集,Mesos 支持许多其他架构来满足复杂数据处理的多样化需求。本书撰写时,很多这样的项目还处在早期发展阶段,但是都已经取得了实质性进展。
Storm
Apache Storm 是实时分布式流事件处理引擎(https://storm.apache.org)。Storm
特点是事务性、可靠、可扩展、可容错,并且提供了易用的 API。和 MapReduce 相比,它的架构完全不同。MapReduce
系统,比如 Hadoop、Spark 等都将代码移动到数据附近。这意味着在 MapReduce 架构里,每个节点都有一些数据,每个节点也拥有完全相同的代码来生成结果。但是在
Storm 里,每个节点完成不同类型的处理,处理不同的数据流。
Storm 的主要抽象概念是流过节点的流(元组流),每个节点完成一些处理。元组非常通用,可以包含一系列任意类型的可序列化的对象。在
Storm 里,处理序列用拓扑来描述。拓扑永远在运行,在流数据到达时完成处理。
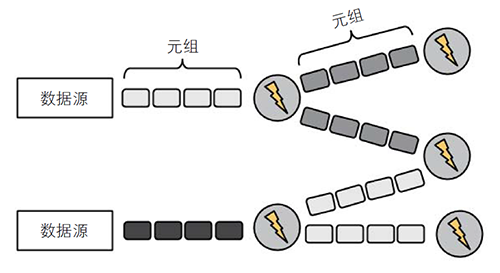
Storm 拓扑
上图展示了基本拓扑概念。拓扑包含数据源(spout)和数据操作(bolt)。Spout
是数据源。它们侦听数据源,将元组发送到拓扑里。每一次循环代表一次数据操作,完成一些处理,这些流动的元组和数据操作构成的
DAG(有向无环图)就是拓扑。
Storm 是主-从架构。Numbus 是主节点守护进程,负责协调和监控。工作节点运行
supervisor,执行拓扑的一部分。Nimbus 和 supervisor 通过 ZooKeeper
或者本地磁盘相互通信。
Storm有很多高级特性,比如,支持精细监控、事务语义使用 Trident
等,这些不在本书讨论范围。更多Storm 的内容,参考 Quinton Anderson 的《Storm
实时数据处理》。
Mesos 上的 Storm
Nathan Marz 开发了调度器和执行器的第一个版本,随后项目在社区(https://github.com/mesos/storm)里进一步发展。在
Mesos 上运行任意框架,都需要调度器来代表框架的任务向 Mesos 申请资源,也需要执行器运行这些任务。如下步骤可以完成
Mesos 上 Storm 的安装:
1.安装 Mesos。
2.克隆 storm-mesos 的存储库,并且进入根目录:
ubuntu@master:~ $ git clone https://github.com/mesos/storm
ubuntu@master:~ $ cd storm |
3.存储库的 bin 目录下包含 build-release.sh 脚本。该脚本包含很多子命令,可以通过
-h 参数查看。先下载未更改的 Apache Storm 发行版。该脚本会下载 pom.xml 文件里
version 属性指定的版本。默认下载最新版,一般适用于大多数情况。如果需要 Storm 的特定版本,需要将
version 属性设置为所需版本。本书撰写时,默认版本是 0.9.3。也可以通过设置 MIRROR 环境变量指定下载镜像:
ubuntu@master:~/storm $ ./bin/build-release.sh downloadStormRelease |
4.上一步命令会下载名为 apache-storm-VERSION.zip
的文件。将下载的压缩文件作为脚本的参数:
ubuntu@master:~/storm $ ./bin/build-release.sh apache-storm-*.zip |
5.上一步命令会在当前目录创建名为 storm-mesos-VERSION.tgz
的 storm-mesos 发行版。
6.需要更新 Storm 的配置来匹配集群设置。Storm 使用 YAML
配置文件格式。更新 conf/storm.yaml,添加如下设置:
mesos.master.url: "zk://master:2181/mesos"
storm.zookeeper.servers:
- "master"
nimbus.host: "master" |
mesos.master.url 参数指定为 <host:pair>,这是
Mesos 主节点运行的 url。storm.zookeeper.servers 列出 Storm 使用的
ZooKeeper 服务器。nimbus.host 指定 Storm 集群的主节点。下节会详细介绍 storm-mesos
的所有配置选项。
7.运行如下命令启动 Storm 的 master-nimbus。
ubuntu@master:~/storm-mesos $ bin/storm-mesos nimbus |
8.也可以选择启动 Storm UI,在 <storm-master:port>
处访问,本例中,是 http://master:8080。
ubuntu@master:~/storm-mesos $ bin/storm ui |
至此,Storm 已经运行在 Mesos 上了。Storm Web UI
如下图所示,显示集群配置有 0 个 supervisor,因为 supervisor 是在运行拓扑时按需创建的。
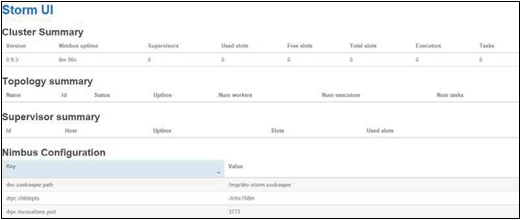
另外,在 Mesos UI 上,Storm 会被列为活动框架。现在就可以运行多种流处理作业了。Storm
项目在 examples/storm-starter 目录下有丰富的样例拓扑。运行 ExclamationTopology,该拓扑会在输入的单词后加上感叹号。ExclamationTopology
是一个基本拓扑,带有一个数据源 word,两个数据操作 exclaim1 和 exclaim2,以线性方式链接:
ubuntu@master:~/storm-mesos $ bin/storm-mesos jar examples
/storm -starter/storm-starter-topologies-*.jar storm.starter.ExclamationTopology mytopology
|
注意:Storm 要求给定集群里,拓扑名称是唯一的。
上述命令会将 ExclamationTopology 提交到 Storm
集群,命名为 mytopology。可以使用如下命令行接口验证该拓扑正在运行:
ubuntu@master:~/storm-mesos $ bin/storm list |
还可以使用 Storm Web 接口查看拓扑的各种信息。输出以及其他日志存储在
logs 目录下,感叹号之后会显示 Storm 项目的贡献者。https://storm.apache.org/documentation
可以帮助理解更多 Storm 理念及各种 Storm 命令。
Storm-Mesos 配置Storm-mesos 使用基于 YAML
的配置。至少需要设置如下配置参数:
1.mesos.executor.uri:这是执行器的 URI。
2.mesos.master.url:这是 Mesos master 的地址。
3.storm.zookeeper.servers:这是 Storm 主节点使用的
ZooKeeper 服务器。
4.nimbus.host:这是运行 Storm nimbus 的主机名。
控制资源配置十分重要,因为这会严重影响到 Storm 的可扩展性和延时。Storm-mesos
使用如下配置调优资源:
1.topology.mesos.worker.cpu 和 topology.mesos.worker.mem.mb:这两个参数分别指定每个工作节点的
CPU 和内存。默认值分别为 1 和 1000MB。该值必须设置得比 worker.childopts
高 25%,来适应任务的额外消耗。比如,如果 worker.childopts 设置为 -Xmx1000m,那么
topology.mesos.worker.mem.mb 必须至少设为 1250。
2.topology.mesos.executor.cpu 和 topology.mesos.executor.mem.mb:这两个参数分别指定每个执行器的
CPU 和内存。默认值分别为 1 和 1000MB。
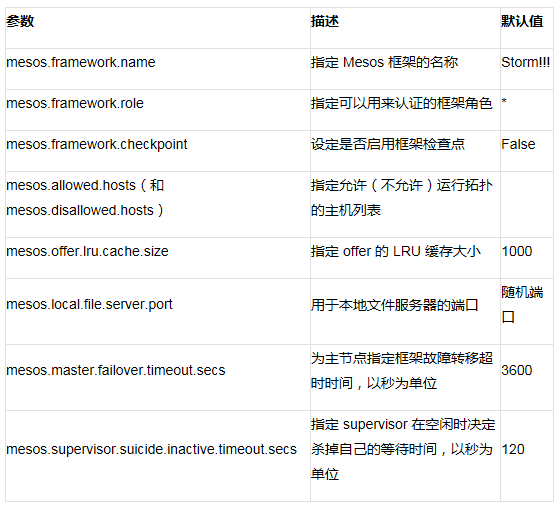
Storm-mesos 还指出下表可选的配置参数:
Spark Streaming
我们已经了解到 Spark 可以用来处理大量数据。Spark Streaming
是 Spark API 的扩展,用来处理流数据。它支持各种各样的输入数据源,包括 Twitter、HDFS、Kafka、Flume、Akka
Actor、TCP socket 和 ZeroMQ。Spark Streaming 将输入数据流分解成小批量,然后
Spark 程序处理这些离散化的流。已处理的小批量数据可以流转做进一步处理,或者保存到 HDFS、数据库等上。
Spark Streaming 有 DStream 或者离散流(http://www.cs.berkeley.edu/~matei/papers/2012/hotcloud_spark_streaming.pdf)的基础抽象。Spark
内部,DStream 以 RDD 序列的形式存在,DStream 上的操作被转化为 Dstream 里
RDD 的操作。这样自然拥有了 RDD 的所有优势,比如一致性、检查点等。下图展示了 Spark 是如何启动流处理的。
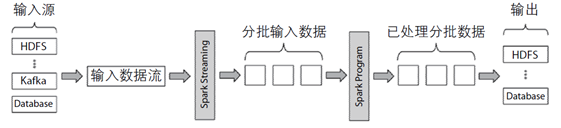
Spark Streaming 架构
Spark Steaming 支持很多不同的操作,无状态和有状态操作都支持。
下表列出了目前支持的操作:
Spark Streaming 支持的转化
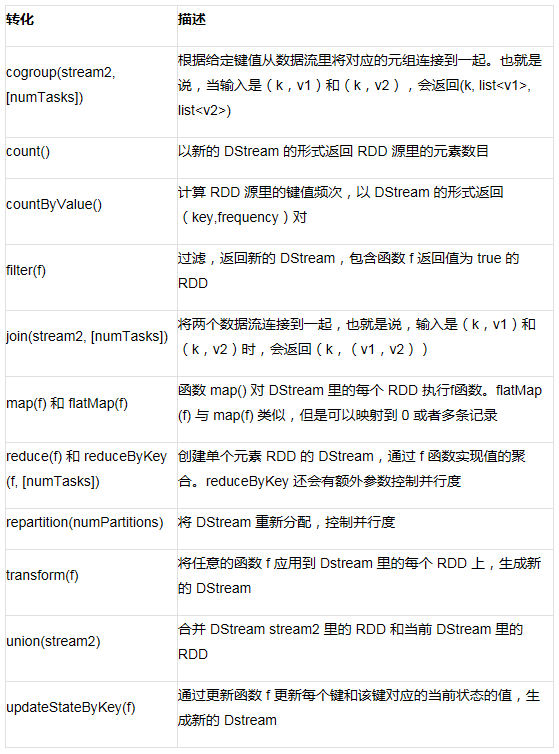
Spark Streaming 也支持基于窗口的操作,也就是说可以操作数据的滑动窗。WindowLength
和 slideInterval 参数控制窗口和操作间隔。下表列出了支持的基于窗口的操作:
Spark Steaming 支持的基于窗口的转化

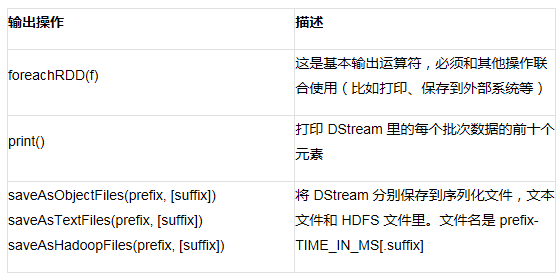
和 Spark 类似,这些操作是惰性执行的,如下输出操作才会触发计算:
Spark Streaming 支持的输出操作
在 Mesos 上运行 Spark Streaming
如果已经在 Mesos 上运行了 Spark,那么随时都可以开始使用 Spark
Steaming。无须为 Spark Streaming 做任何特殊配置。Spark 发行版在 examples
目录下包含多种样例,包括 Spark Streaming 样例。让我们运行 Spark Stream 样例之一,NetworkWordCount。该样例统计每秒给定网络流里给定单词出现的数量。
首先,需要创建网络流,可以在 TCP 端口使用 Netcat 发送文本。打开终端,键入如下命令,在端口
9999 启动 Netcat 服务器:
ubuntu@master:~ $ nc -lk 9999 |
现在在另一个终端,启动 Spark Steaming 样例:
ubuntu@master:~ $ cd spark
ubuntu@master:~ $ ./bin/run-example streaming.NetworkWordCount localhost 9999 |
NetworkWordCount 已经在运行了,会侦听第一个终端启动的 Netcat 里的输入。它会打印单词及每秒该单词出现的频率。比如,如果我们在
Netcat 窗口键入 hello world,就会在 Spark Streaming 窗口看到如下输出:
Spark Streaming 调优
Spark Streaming 在 Mesos 里开箱即用。但是,对系统进行调优以满足实时流处理的需求和优化资源的使用是至关重要的。如下是调优需要考虑的几个方面。
选择批量大小
选择流数据的批量大小是能否及时处理输入数据的决定性因素。批量大小不能设置过小,否则集群资源可能被浪费。另一方面,如果批量大小设置过大,流计算可能跟不上。因此,推荐的方式是从对于应用程序而言比较保守的批量大小开始,然后逐步检测出更小的数值。如果每个批次数据端到端处理的速度能够比输入批次数据的速度快,那么就说明系统可以胜任当前的处理速度。要度量该时间,可以使用
Spark 提供的org.apache.spark.scheduler.StreamingListener
接口。持续增加的延时是系统不能处理当前数据的信号。
垃圾回收
在生产环境运行 Spark Streaming 时,需要格外注意的重要配置参数是
spark.cleaner.ttl。该参数控制 Spark 记忆的元数据的长度。Spark 默认不会移除任何元数据,有太多元数据时,就会影响到流处理应用程序。另外,如果该值设置得过低,窗口操作可能就无法处理窗口长度内的
RDD。因此,spark.cleaner.ttl 的值必须设置得比流处理应用程序的最大窗口长度更大。如果没有设置
spark.cleaner.ttl,Spark 会用最近最少使用(LRU)的方式清除所有 RDD。另外,将
spark.streaming.unpersist 设置为 true 可以启动一种更为智能的反持久化方案,系统会计算出哪些
RDD 可以从内存里移除。另外,推荐使用 Java 虚拟机的并发标记和移除式垃圾回收器,因为这样允许很多小型的
GC 暂停,而不是一个大型的,这会让流处理延时更稳定。
并发
使用可用集群资源并行化处理十分重要。必须给操作传输合适的 numTask
参数,默认值是 8。也可以通过 spark.default.parallelism 来改变该默认值。
故障处理
必须考虑到如果驱动节点和工作节点发生故障时该如何处理,因为所有的中间数据都可以根据
RDD 处理链重新计算出来。为了确保驱动器节点的恢复,必须启动检查点(通过 ssc.checkpoint
参数),应用程序必须检查前一个检查点状态是否存在。如果输入源是网络链接而工作节点在复制前失败了,还可以将数据复制到其他节点上,但是可能会丢失一小部分数据。对于持久化输入存储,比如
HDFS,工作节点失败不会造成任何数据的丢失。Spark Streaming文档(http://spark.apache.org/docs/latest/streaming-programming-guide.html)详细讨论了
Spark Streaming 所提供的容错语义。
任务额外开销
Mesos 任务启动的额外开销对于低延时应用程序,比如 Spark Streaming,可能是致命的。Spark
Streaming 必须运行在细粒度 Mesos 模式下,来减少任务启动的额外开销,第 3 章对此有详细解释。另外,为了减少
GC 暂停,Spark Streaming 将 RDD 以序列化二进制的格式持久化存储下来。这样,序列化/反序列化的额外开销可能很大,推荐使用快速序列化框架,比如
Kryo(https://github.com/EsotericSoftware/kryo)。另外,序列化任务也可能减少任务的网络传输时间,从而降低任务启动的额外开销。
Mesos 上的 NoSQL
数十年里,SQL 一直是数据分析的主要工具。随着大数据的兴起,很多系统尝试将数据库应用到大规模复杂数据分析领域。这样的系统包括
Hive、Shark、Spark SQL 和 NoSQL 数据库,比如 Cassandra、Hypertable
等。可以将这些类型的工作负载都运行在 Mesos 上,同时利用 Mesos 的优势,包括资源共享、容错等。下节详细介绍在
Mesos 上安装 Cassandra 的步骤。
Mesos 上的 Cassandra
Apache Cassandra(http://cassandra.apache.org)是流行的
NoSQL 数据库。Cassandra 由 Facebook 发起,在很多大规模部署环境上起着重要作用。通过在
Mesos 上运行 Cassandra,可以利用 Mesos 的容错和扩展能力。Cassandra 非常适合
Mesos,因为其架构是完全去中心化的。
要想在 Mesos 上运行 Cassandra,需要调度器和 Mesos
协调 Cassandra 所需的资源,执行器实际运行 Cassandra 的守护进程。调度器还需要将所有发行版和配置文件复制到所有节点上。Cassandra
配置需要定制种子节点,一旦调度器接受了来自 Mesos 的 offer,种子节点就会包含到调度器里。下列是在
Mesos 上运行 Cassandra 的步骤:
1.安装 Mesos。
2.登入 Mesos 主节点,从 Mesosphere 下载最新的预构建的
Cassandra-mesos 发行版。本书撰写时,最新版是 2.0.5:
ubuntu@master:~ $ wget http://downloads.mesosphere.io/cassandra/cassandra-mesos-2.0.5-1.tgz |
3.解压缩该文件,cd 到目录下:
ubuntu@master:~ $ tar xzf cassandra-mesos-*.tgz
ubuntu@master:~ $ cd cassandra-mesos-* |
4.需要编辑 conf/mesos.yaml 来反应集群配置。默认配置针对和
ZooKeeper 一起运行的本地 Mesos 集群。下表列出配置选项:
配置选项

在 Mesos 调度器上启动 Cassandra:
ubuntu@master:~/cassandra-mesos $ bin/cassandra-mesos
set -o errexit -o pipefail
FRAMEWORK_HOME='dirname $0'/..
dirname $0
export MESOS_NATIVE_LIBRARY=$(sed -e 's/:[^:\/\/]/="/g;s/$/"/g;s/
*=/=/g' "$FRAMEWORK_HOME"/conf/mesos.yaml
| tr -d $'\'' | grep -v \# | grep java.library.path
| sed 's/java.library.path=// g;s/"//g')
…
# Start Cassandra on Mesos
…
0 [main] INFO mesosphere.cassandra.Main$ - Starting
Cassandra on Mesos.
…
114 [Thread-0] INFO mesosphere.cassandra.CassandraScheduler
- Starting Cassandra cluster ${clusterName} for
the first time. Allocating new ID for it.
…
I0429 19:36:36.742849 27508 sched.cpp:391] Framework
registered with 20140429-193514-580538634-5050-25835-0000
175 [Thread-1] INFO mesosphere.cassandra.CassandraScheduler
- Framework registered as 20140429-193514-580538634-5050-25835-0000
437 [Thread-2] INFO mesosphere.cassandra.CassandraScheduler
- Got new resource offers ArrayBuffer(slave1)
455 [Thread-2] INFO mesosphere.cassandra.CassandraScheduler
- resources offered: List((cpus,2.0), (mem,6489.0),
(disk,7935.0), (ports,0.0))
455 [Thread-2] INFO mesosphere.cassandra.CassandraScheduler
- resources required: List((cpus,0.1), (mem,2048.0),
(disk,1000.0))
464 [Thread-2] INFO mesosphere.cassandra.CassandraScheduler
- Accepted offer: slave1
… |
这里,被截断的输出显示 Cassandra 集群已经注册到 Mesos 上了,并且从 slave1 接收到了资源
offer。现在 Cassandra 已经启动并运行了,在 Web UI 里应该能看到列出的框架里有 Cassandra
Test Cluster。可以通过 Cassandra 查询语言(Cassandra Query Language
(CQL))shell 与之交互。从命令行或者通过 Web UI(UI上 的Host 字段),选择运行
Cassandra 的任意主机,使用如下命令连接到 CQL 会话中:
ubuntu@master:~/cassandra-mesos $ bin/cqlsh <cassandra-host> |
应该能够看到 Cassandra 提示符(>cqlsh)。现在就可以运行
Cassandra 查询了。另外注意 Mesos 上的 Cassandra 支持很多场景和功能(比如扩展性),本文对此没有深入介绍。
小结
批量处理系统不再是开发人员可用的唯一数据处理工具,新的应用程序及要求不同类型数据的分析用例层出不穷,而不是只有传统ETL工具和框架,比如
Hadoop,支持的一种场景。因此,与其尝试让批量处理系统更快或扩展传统数据库来处理非结构化数据,倒不如使用正确的工具来完成这些工作,从而让这些应用程序的开发和扩展更为容易。
本章探讨了使用运行在 Mesos 上的 Storm 和 Spark Streaming
处理实时和流数据的可选方案。也讲解了如何使用运行在 Mesos 上的 Cassandra 实现更多探索性数据分析。Cassandra
也是 Mesos 上更为通用的应用程序实例之一。
|






