|
ժҪ��Spark Streaming��Spark����õ����֮һ��������Խ��Խ�����������������û�̤��Spark��ʹ��֮·������������Spark Streaming�ļܹ����������ȥ�ṩ�������ƣ��Լ�һЩĿǰ���е����Ҹ���Ȥ����غ���������
���������ϴ����ڶ���õ����������棬���Ǿ���ѯ������Spark Streaming�кζ��ص����ƣ���ô����Ҫ˵�ľ���Apache Spark���������Լ����������ṩ��ԭ��֧�֡�������ϵͳ��֮ͬ����������ϵͳ�Ĵ�������Ҫôֻרע����������Ҫôֻ�����������ҽ��ṩ��Ҫ�ⲿʵ�ֵ�������API�ӿڶ��ѡ�Spark ƾ����ִ�������Լ�ͳһ�ı��ģ�Ϳ�ʵ������������������������봫ͳ������ϵͳ���Spark Streaming���߱���һ�������ơ������ر������������ĸ���Ҫ���֣�
- ���ڹ��ϱ�����straggler�������Ѹ�ٻָ�״̬��
- ���õĸ��ؾ�������Դʹ�ã�
- ��̬���ݼ��������ݵ����ϺͿɽ�����ѯ��
- ���÷ḻ���㷨�����⣨SQL������ѧϰ��ͼ��������
���ģ����ǽ�����Spark Streaming�ļܹ����������ȥ�ṩ�������ơ����������ǻ�������һЩĿǰ���ڽ������Ҹ���Ȥ����غ���������
�������ܹ�-��ȥ������
��ǰ�ֲ�ʽ�������ܵ�ִ�з�ʽ����������
- ������������Դ�������ݣ�����ʱ��־��ϵͳң�����ݡ��������豸���ݵȵȣ���������Ϊ������ȡϵͳ������Apache Kafka��Amazon Kinesis�ȵȡ�
- �ڼ�Ⱥ�ϲ��д������ݡ���Ҳ���������������Ĺؼ����ڣ����ǽ���������������ϸ���Ե����ۡ�
- ���������������ϵͳ������HBase��Cassandra, Kafka�ȵȣ���
Ϊ�˴�����Щ���ݣ��ִ�ͳ��������ϵͳ�����Ϊ�������� ģ�ͣ��乤����ʽ���£�
- ��һϵ�еĹ����ڵ㣬ÿ��ڵ�����һ������������ӣ�
- ���������ݣ�ÿ����������һ�δ���һ����¼�����ҽ���¼������ܵ��б�����ӣ�
- Դ���Ӵ�����ϵͳ�������ݣ����ų��������������ϵͳ��
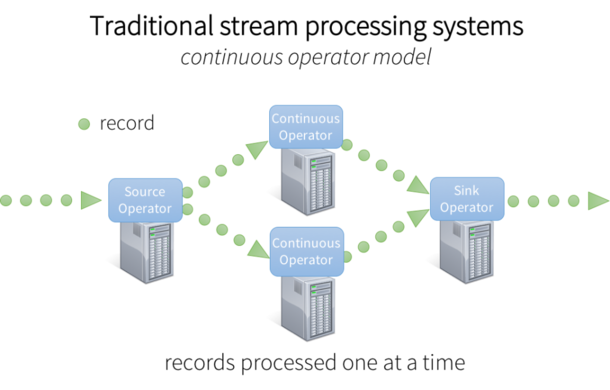
ͼ1����ͳ������ϵͳ�ܹ�
����������һ�ֽ�Ϊ����Ȼ��ģ�͡�Ȼ��,������������ʱ���£����ݹ�ģ�IJ��������Լ�Խ��Խ���ӵ�ʵʱ�����������ͳ�ļܹ�Ҳ�������Ͼ�����ս����ˣ��������Spark Streaming����Ϊ�˽�����¼�������
- ����Ѹ�ٻָ��C����Խ�Ӵ��ֽڵ������ڵ����б���������straggler������ĸ���ҲԽ��Խ�ߡ���ˣ�ϵͳҪ���ܹ�ʵʱ�������,�ͱ����ܹ��Զ������ϡ���ϧ�ڴ�ͳ������ϵͳ�У�����Щ�����ڵ㾲̬�������������ҪѸ������������Ȼ�Ǹ���ս��
- ���ؾ���C����������ϵͳ�й����ڵ�䲻ƽ�������ػ���ɲ��ֽڵ����ܵ�bottleneck������ƿ��������Щ����������ڴ��ģ�����붯̬�仯�Ĺ�������ǰ��Ϊ�˽��������⣬��ôҪ��ϵͳ�����ܹ����ݹ�������̬�����ڵ�����Դ���䣻
- ͳһ�����������������Լ����������C�����������У��������ݵĽ����Ǻ��б�Ҫ�ģ��Ͼ�������ϵͳ�����������ڴ��У������뾲̬���ݼ���ϣ�����pre-computed model������Щ����������������ϵͳ��ʵ�֣���ϵͳ��̬������������ʱ����û��Ϊ�������ʱ��ѯ���ܣ����������������û���ϵͳ�Ľ������������������Ҫһ�������ܹ��������������������뽻����ѯ��
- ���������������ѧϰ��SQL��ѯ�ȵȣ��CһЩ�����ӵĹ�����Ҫ����ѧϰ��������ģ�ͣ���������SQL��ѯ�����������µ�������Ϣ����ˣ���Щ������������Ҫ��һ����ͬ�ļ��ɳ���������ÿ�����Ա������ȥ������ǵĹ�����
Ϊ�˽����ЩҪ��Spark Streamingʹ����һ���µĽṹ�����dz�֮Ϊdiscretized streams����ɢ���������ݴ�������������ֱ��ʹ��Spark�����зḻ�ĿⲢ��ӵ������Ĺ����ݴ����ơ�
Spark Streaming�ܹ�����ɢ���������ݴ���
���ڴ�ͳ��������һ�δ���һ����¼�ķ�ʽ���ԣ�Spark Streamingȡ����֮���ǽ���������ɢ��������ʹ֮�ܹ������뼶���µ�����������ͬʱSpark Streaming��Receiver���н������ݣ������ݻ�����Spark�����ڵ���ڴ��С������ӳ��Ż���Spark����Զ�����ʮ���룩�ܹ��������������ҿɽ������������ϵͳ�С�ֵ��ע������봫ͳ��������ģ�Ͳ�ͬ�����д�ͳģ���Ǿ�̬�����һ���ڵ���м��㣬��Spark task�ɻ������ݵ���Դ�Լ�������Դ�����̬����������ڵ㡣���ܹ����õ���������ڽ�������Ҫ�������������ԣ����ؾ�������ٹ��ϻָ���
����֮�⣬ÿ���������Ƕ���֮Ϊ���Էֲ�ʽ���ݼ���RDD��������Spark���ݴ����ݼ���һ����������������ˣ���Щ�����ݲ��ܴ���Spark������ָ����⡣
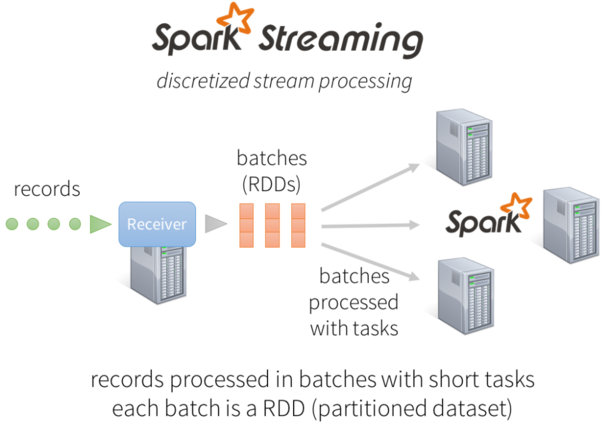
ͼ2��Spark Streaming�ܹ�
��ɢ�������ݴ������ŵ�
��������������ܹ����ͨ��Spark Streaming���������֮ǰ������Ŀ�ꡣ
��̬���ؾ���
Sparkϵͳ�����ݻ���ΪС��������������Դ����ϸ���ȷ��䡣���磬���ǵ�������������Ҫ��һ����ֵ�����������������ּ�����£����ϵͳ��Ĵ�ͳ��̬����task���ڵ㷽ʽ�У��������һ����������ȱ�ĸ��ܼ�����ô�ýڵ㴦��������������ƿ����ͬʱ��������ܵ�����������Spark Streaming�У���ҵ���ᶯ̬��ƽ�����������ڵ㣬һЩ�ڵ�ᴦ�����������Һ�ʱ�ϳ�task����Ľڵ㽫�ᴦ�����������Һ�ʱ���̵�task��
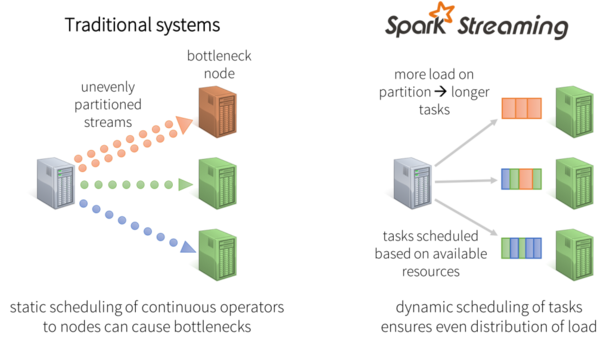
ͼ3����̬���ؾ���
���ٹ��ϻָ�����
�ڽڵ���ϵİ����У���ͳϵͳ���ڱ�Ľڵ�������ʧ�ܵ��������ӡ�Ϊ�����¼��㶪ʧ����Ϣ�������ò���������һ����ǰ�������������̡�ֵ��ע����ǣ��˹���ֻ��һ���ڵ��ڴ������¼��㣬���ҹܵ����������й����������µĽڵ���Ϣ�Ѿ��ָ�������ǰ��״̬����Spark�У����㽫����ֳɶ��С��task����֤�����κεط����ж��ֲ�Ӱ��ϲ�������ȷ�ԡ���ˣ�ʧ�ܵ�task����ͬʱ�����ڼ�Ⱥ�ڵ��ϲ��д������Ӷ����ȵķֲ����������¼�������µ��ڶ�ڵ��У���������ڴ�ͳ�����ܹ�����شӹ����лָ�������
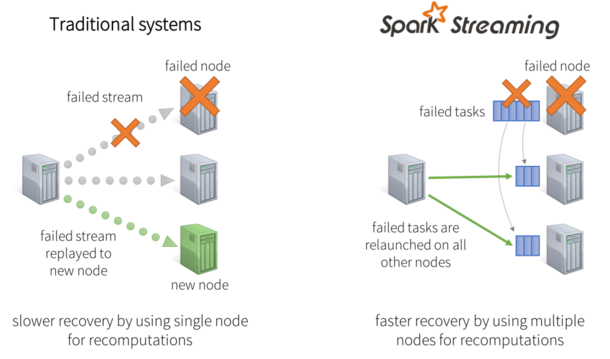
ͼ4�����ٹ��ϻָ�ԭ��
���������������뽻��ʽ������һ�廯
��ɢ��������DStream����ΪSpark Streaming��һ���ؼ��ij�����������ڲ���DStream��ͨ��һ��ʱ��������������RDD����ʾ�ģ�ÿһ��RDD���������ض�ʱ�����ڵ������������ֳ��ñ�ʾ�����������������������콻���������Ӷ��û����Զ�ÿһ�������ݽ���Spark��ز��������磺����DStream��Ԥ�ȴ��������ݼ������ӡ�
// Create data set from Hadoop file
val dataset = sparkContext.hadoopFile(��file��)
// Join each batch in stream with the dataset
kafkaDStream.transform { batchRDD =>
batchRDD.join(dataset).filter(...)
} |
������������ÿһ����������Spark�ڵ��е��ڴ�����DZ��ܸ���������н�����ѯ�����磬�����ͨ��Spark SQL JDBC server����ѯ����stream��״̬���������������½���Ҳ��չʾ������ΪSpark����Щ��������һ�����еij����������ֽ����������������뽻��ʽ���������һ����������Spark���Ƿdz�����ʵ�ֵģ�������Щû�й�ͬ�����ϵͳ��ȴ���ѡ�
������-����ѧϰ��SQL��ѯ
��ΪSpark���л������ԣ����������ḻ�Ŀ�û�ʹ�ã����磺MLlib������ѧϰ����SQL��DataFrames��Graphx������������һ��̽��һЩ������
- Streaming + SQL and DataFrames
DStream�ڲ�ά����RDD���п��Ա�ת����DataFrame��Spark SQL�ı�̽ӿڣ���������ͨ��SQL�����в�ѯ���������磺ʹ��Spark SQL��JDBC server,�ⲿ�������ͨ��SQL��ѯstream��״̬��
val hiveContext = new HiveContext(sparkContext)
...
wordCountsDStream.foreachRDD { rdd =>
// Convert RDD to DataFrame and register it as a SQL table
val wordCountsDataFrame = rdd.toDF("word��, ��count")
wordCountsDataFrame.registerTempTable("word_counts")
}
...
// Start the JDBC server
HiveThriftServer2.startWithContext(hiveContext)
|
�����ͨ��JDBC serverʹ��Spark������beeline client����tableau���߽�����ѯ�������µġ�word_counts������
1: jdbc:hive2://localhost:10000> show tables;
+--------------+--------------+
| tableName | isTemporary |
+--------------+--------------+
| word_counts | true |
+--------------+--------------+
1 row selected (0.102 seconds)
1: jdbc:hive2://localhost:10000> select * from word_counts;
+-----------+--------+
| word | count |
+-----------+--------+
| 2015 | 264 |
| PDT | 264 |
| 21:45:41 | 27 |
|
����ѧϰģ�Ϳ�ͨ��MLlib�����������ɣ���Ӧ�����������С����磬������Ĵ����þ�̬�����γ�һ��KMeans����ģ�ͣ�Ȼ��ʹ��ģ�Ͷ�Kafka���������з��ࡣ
// Learn model offline
val model = KMeans.train(dataset, ...)
// Apply model online on stream
val kafkaStream = KafkaUtils.createDStream(...)
kafkaStream.map { event => model.predict(featurize(event)) }
|
������Spark Summit 2014 Databricks demo��֤�������֡�����ѧϰ����Ԥ�⡱�ķ����������Ժ�����Ҳ��MLlib�����ӹ������Ļ���ѧϰ�㷨���������ܳ����γ�һЩ�����������������Spark ��չ��Ҳͬ������Spark Streaming�ϱ������á�
���ܷ���
����Spark Streaming��һ������ƣ���ô�����е��ٶ��ж���أ�ʵ����Spark Streaming�������������������������Լ�����Spark ��������������ϵͳ���൱���߸��ߵ������������ӳٷ��棬Spark Streaming����ʵ�ֵ������ٺ�����ӳ١���������ʱ�����������Ƿ��н϶���ӳ١���ʵ���У��������ӳ�ֻ�Ƕ˵��˹ܵ��ӳٵ�һС���֡���������Sparkϵͳ������������ϵͳ�£�����Ӧ�ó���������Ǹ���һ�������Ĵ���������õ�����������õ��ģ�������ڵĸ���Ҳ�Ƕ�ʱ�ģ����細�ڼ����Ϊ20�룬���������Ϊ2�룬��ʾÿ��2��������һ�δ���ǰ20�����Ϣ������Ҫ�ܵ��ռ����Զ����Դ�ļ�¼���ҵȴ�һ���̵�ʱ���ڴ����ӳٻ��������ݡ�����Զ������㷨�����ȴ�һ��ʱ��Ŵ�������ˣ�����ڶ˵��˵��ӳ٣��������ӳٺ��ٻ����Ӻܶ�ķ��ã���Ϊ�������ӳ�������С�����⣬��DStream����������������һ����ζ�����ǿ����ø��ٵĻ���ȥ����ͬ���Ĺ��������������������������������
Spark Streaming�������
Spark Streaming��Spark����õ����֮һ��������Խ��Խ�����������������û�̤��Spark��ʹ��֮·��һЩ�����Ŷ������о���������ȼ�����Ŀ�����������б����۵����������Spark�����¼����汾���ڴ���Щ���Եij��֣�
- Backpressure�C������ҵ�п��ܾ�������������������������:�ڰ�˹���佱�ڼ伤���������������ϵͳ�����ܹ������Ĵ��������ǡ���Spark 1.5�汾�У�Spark�������Ӹ��õ�Backpressure���ƣ���Spark Streming�ܶ�̬�ؿ������ֱ����� �����ʡ��˹���������Databricks��Typesafe�Ĺ���ʦ�ǹ�ͬ��ɵģ�
- Dynamic scaling �C�������ƹ̶������ݶ�ȡingestion rate������ȥ��������ʱ�䷶Χ�����ݱ仯��������:�����ҹ�䣬������ڳ����ϸߵķ����ʣ��������������Ҫ�� ����Щ�仯���Ա���̬�����ż�Ⱥ����Դ����Spark Streaming�ܹ��У����Ǻ�����ȥʵ�ֵģ���Ϊ�����Ѿ����ֳ�һϵ��С��task�������Ⱥģʽ������YARN, Mesos, Amazon EC2�ȵ� ����Ҫ����Ľڵ�ȥ���м��㣬��ô�����ܶ�̬�ط��䵽һ������ļ�Ⱥ������Ϊ�����ǽ�����֧���Զ�����Dynamic scaling��
- �¼�ʱ����������ݨCʵ���У��û���ʱ���¼������������Ϣ��Spark Streaming�����û�ͨ���Զ���ʱ����ȡ������֧���¼�ʱ������
- UI������ǿ�C�������ϣ��ʹ������Ա�ܹ����ɵ������ǵ�Streaming?applications���������Ŀ�ģ���Spark 1.4�У����������µĿ��ӻ�Spark Streaming UI���ÿ�����Ա�����м�������Ӧ�ó�������ܡ���Spark 1.5�У�����ͨ��չʾ�����������Ϣ������Kafka��Ϣƫ��������һ�����������ܡ�
|






