| YARN是开源项目Hadoop的一个资源管理系统,最初设计是为了解决Hadoop中MapReduce计算框架中的资源管理问题,但是现在它已经是一个更加通用的资源管理系统,可以把MapReduce计算框架作为一个应用程序运行在YARN系统之上,通过YARN来管理资源。如果你的应用程序也需要借助YARN的资源管理功能,你也可以实现YARN提供的编程API,将你的应用程序运行于YARN之上,将资源的分配与回收统一交给YARN去管理,可以大大简化资源管理功能的开发。当前,也有很多应用程序已经可以构建于YARN之上,如Storm、Spark等计算框架。
YARN整体架构
YARN是基于Master/Slave模式的分布式架构,我们先看一下,YARN的架构设计,如图所示(来自官网文档):
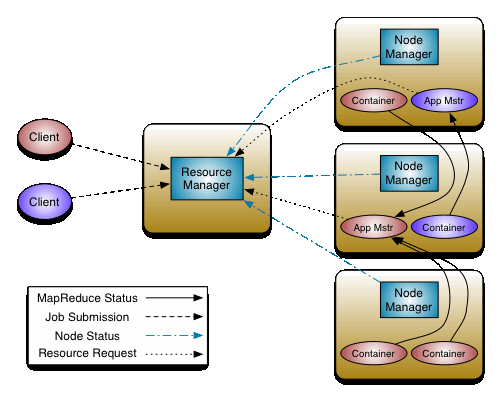
上图,从逻辑上定义了YARN系统的核心组件和主要交互流程,各个组件说明如下:
YARN Client
YARN Client提交Application到RM,它会首先创建一个Application上下文件对象,并设置AM必需的资源请求信息,然后提交到RM。YARN
Client也可以与RM通信,获取到一个已经提交并运行的Application的状态信息等,具体详见后面ApplicationClientProtocol协议的分析说明。
ResourceManager(RM)
RM是YARN集群的Master,负责管理整个集群的资源和资源分配。RM作为集群资源的管理和调度的角色,如果存在单点故障,则整个集群的资源都无法使用。在2.4.0版本才新增了RM
HA的特性,这样就增加了RM的可用性。
NodeManager(NM)
NM是YARN集群的Slave,是集群中实际拥有实际资源的工作节点。我们提交Job以后,会将组成Job的多个Task调度到对应的NM上进行执行。Hadoop集群中,为了获得分布式计算中的Locality特性,会将DN和NM在同一个节点上运行,这样对应的HDFS上的Block可能就在本地,而无需在网络间进行数据的传输。
Container
Container是YARN集群中资源的抽象,将NM上的资源进行量化,根据需要组装成一个个Container,然后服务于已授权资源的计算任务。计算任务在完成计算后,系统会回收资源,以供后续计算任务申请使用。Container包含两种资源:内存和CPU,后续Hadoop版本可能会增加硬盘、网络等资源。
ApplicationMaster(AM)
AM主要管理和监控部署在YARN集群上的Application,以MapReduce为例,MapReduce
Application是一个用来处理MapReduce计算的服务框架程序,为用户编写的MapReduce程序提供运行时支持。通常我们在编写的一个MapReduce程序可能包含多个Map
Task或Reduce Task,而各个Task的运行管理与监控都是由这个MapReduce Application来负责,比如运行Task的资源申请,由AM向RM申请;启动/停止NM上某Task的对应的Container,由AM向NM请求来完成。
下面,我们基于Hadoop 2.6.0的YARN源码,来探讨YARN内部实现原理。
YARN协议
YARN是一个分布式资源管理系统,它包含了分布的多个组件,我们可以通过这些组件之间设计的交互协议来说明,如图所示:
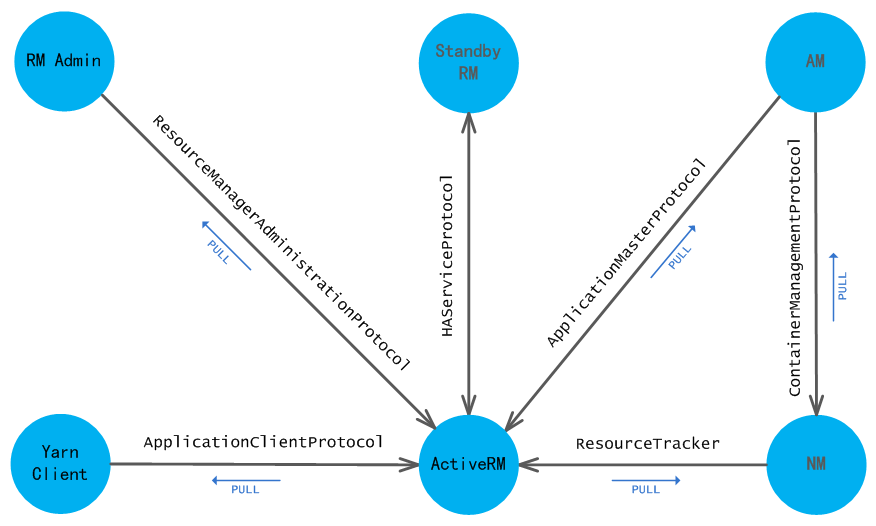
下面我们来详细看看各个协议实现的功能:
ApplicationClientProtocol(Client ->
RM)
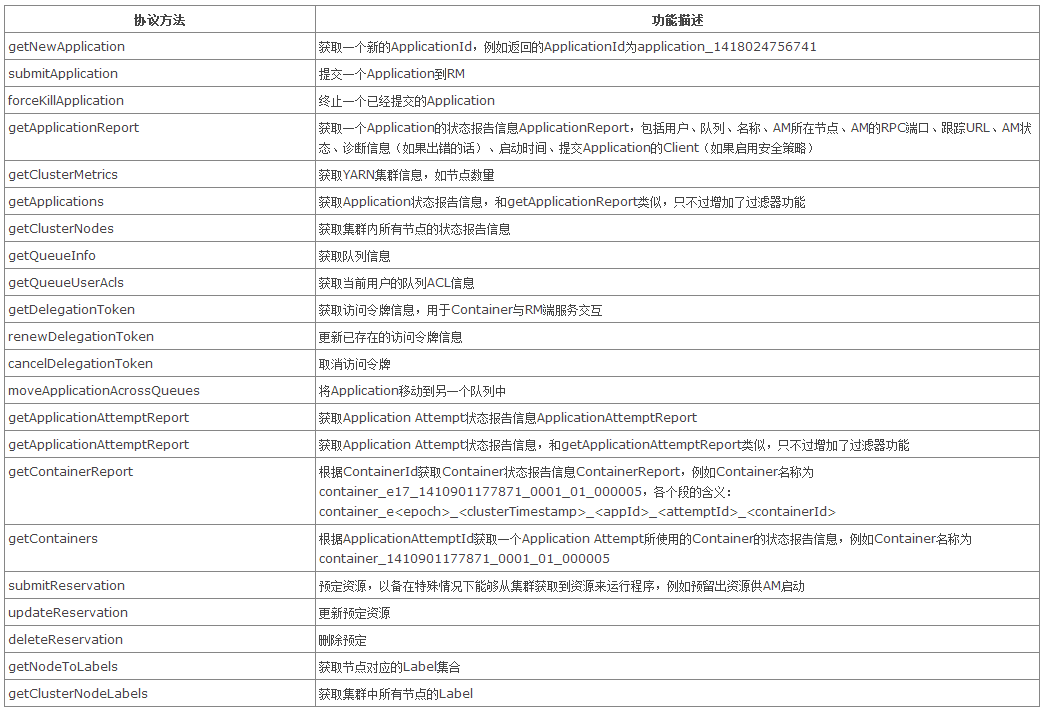
ResourceTracker(NM -> RM)

ApplicationMasterProtocol(AM -> RM)

ContainerManagementProtocol(AM -> NM)

ResourceManagerAdministrationProtocol(RM Admin ->
RM)
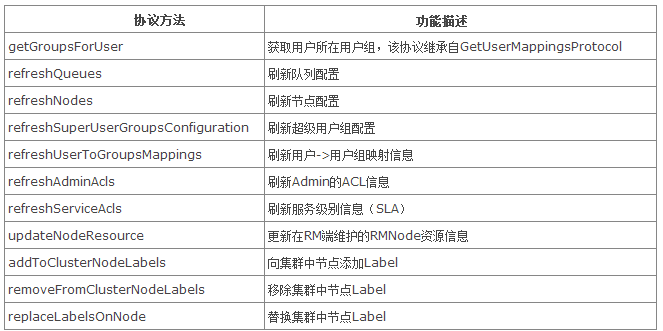
HAServiceProtocol(Active RM HA Framework Standby RM)

YARN RPC实现
1.X版本的Hadoop使用默认实现的Writable协议作为RPC协议,而在2.X版本,重写了RPC框架,改成默认使用Protobuf协议作为Hadoop的默认RPC通信协议。
YARN RPC的实现,如下面类图所示:
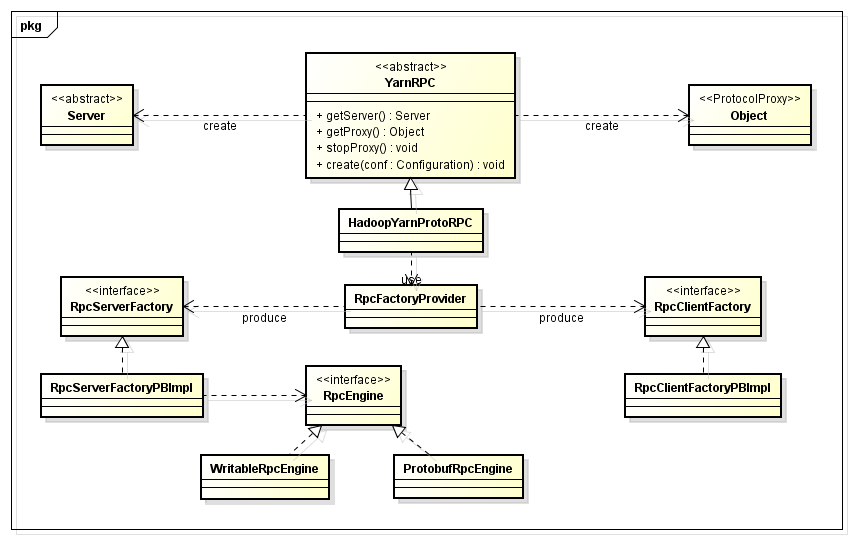
通过上图可以看出,RpcEngine有两个实现:WritableRpcEngine和ProtobufRpcEngine,默认使用ProtobufRpcEngine,我们可以选择使用1.X默认的RPC通信协议,甚至可以自定义实现。
ResourceManager内部原理
RM是YARN分布式系统的主节点,ResourceManager服务进程内部有很多组件提供其他服务,包括对外RPC服务,已经维护内部一些对象状态的服务等,RM的内部结构如图所示:
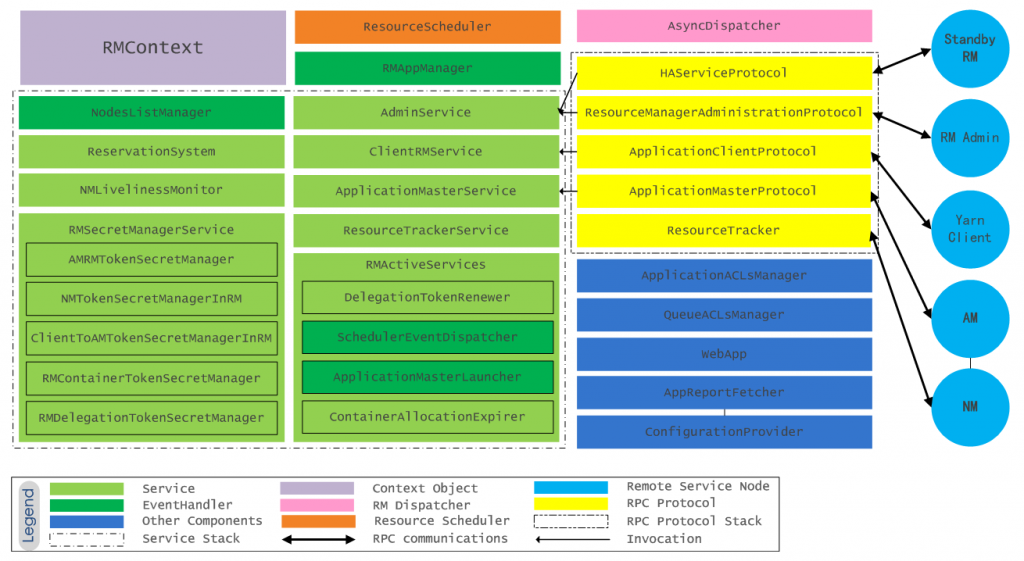
上图中RM内部各个组件(Dispatcher/EventHandler/Service)的功能,可以查看源码。
这里,说一下ResourceScheduler组件,它是RM内部最重要的一个组件,用它来实现资源的分配与回收,它提供了一定算法,在运行时可以根据算法提供的策略来对资源进行调度。YARN内部有3种资源调度策略的实现:FifoScheduler、FairScheduler、CapacityScheduler,其中默认实现为CapacityScheduler。CapacityScheduler实现了资源更加细粒度的分配,可以设置多级队列,每个队列都有一定的容量,即对队列设置资源上限和下限,然后对每一级别队列分别再采用合适的调度策略(如FIFO)进行调度。
如果我们想实现自己的资源调度策略,可以直接实现YARN的资源调度接口ResourceScheduler,然后修改yarn-site.xml中的配置项yarn.resourcemanager.scheduler.class即可。
NodeManager内部原理
NM是YARN系统中实际持有资源的从节点,也是实际用户程序运行的宿主节点,内部结构如图所示:
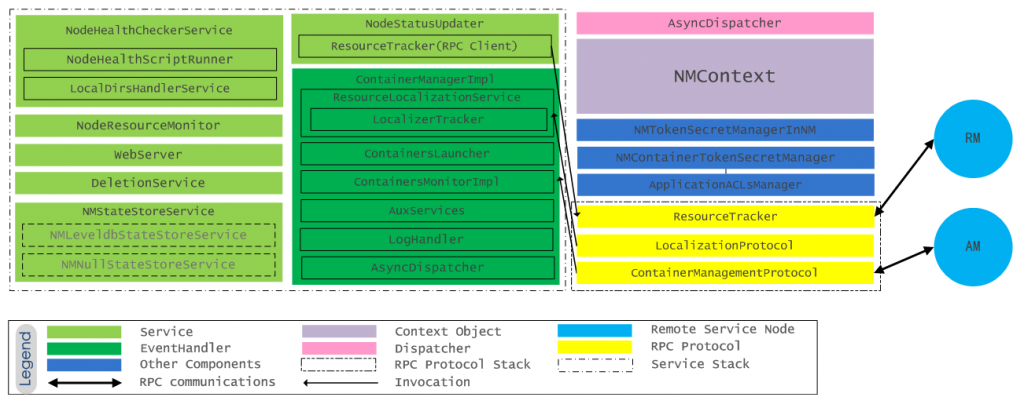
上图中NM内部各个组件(Dispatcher/EventHandler/Service)的功能,可以查看源码,不再累述。
事件处理机制
事件处理可以分成2大类,一类是同步处理事件,事件处理过程会阻塞调用进程,通常这样的事件处理逻辑非常简单,不会长时间阻塞;另一类就是异步处理处理事件,通常在接收到事件以后,会有一个用来派发事件的Dispatcher,将事件发到对应的事件队列中,这采用生产者-消费者模式,消费者这会监视着队列,并从取出事件进行异步处理。
YARN中到处可以见到事件处理,其中比较特殊一点的就是将状态机(StateMachine)作为一个事件处理器,从而通过事件来触发特定对象状态的变迁,通过这种方式来管理对象状态。我们先看一下YARN中事件处理的机制,以ResourceManager端为例,如下图所示:
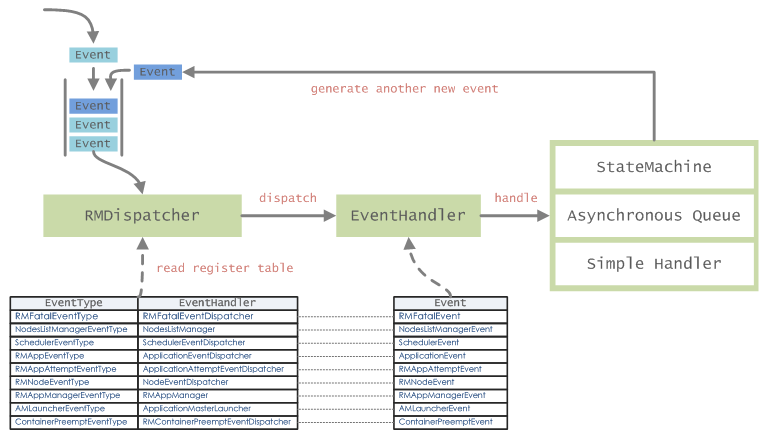
产生的事件通过Dispatcher进行派发并进行处理,如果EventHandler处理逻辑比较简单,直接同步处理,否则可能会采用异步处理的方式。在EventHandler处理的过程中,还可能产生新的事件Event,然后再次通过RM的Dispatcher进行派发,而后处理。
状态机
我们以RM端管理的RMAppImpl对象为例,它表示一个Application运行过程中,在RM端的所维护的Application的状态,该对象对应的所有状态及其状态转移路径,如下图所示:
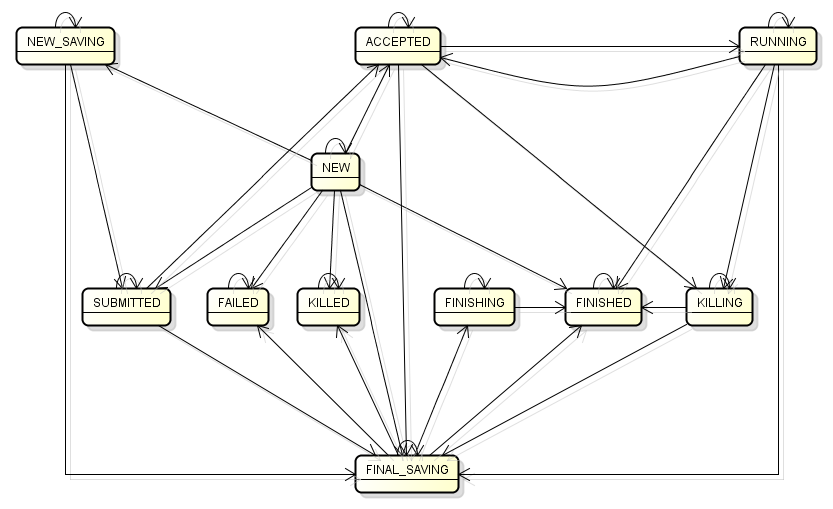
在上图中如果加上触发状态转移的事件及其类型,可能整个图会显得很乱,所以这里,我详细画了一个分图,用来说明,每一个状态的变化都是有哪种类型的事件触发的,根据这个图,可以方便地阅读源码,如下图所示:
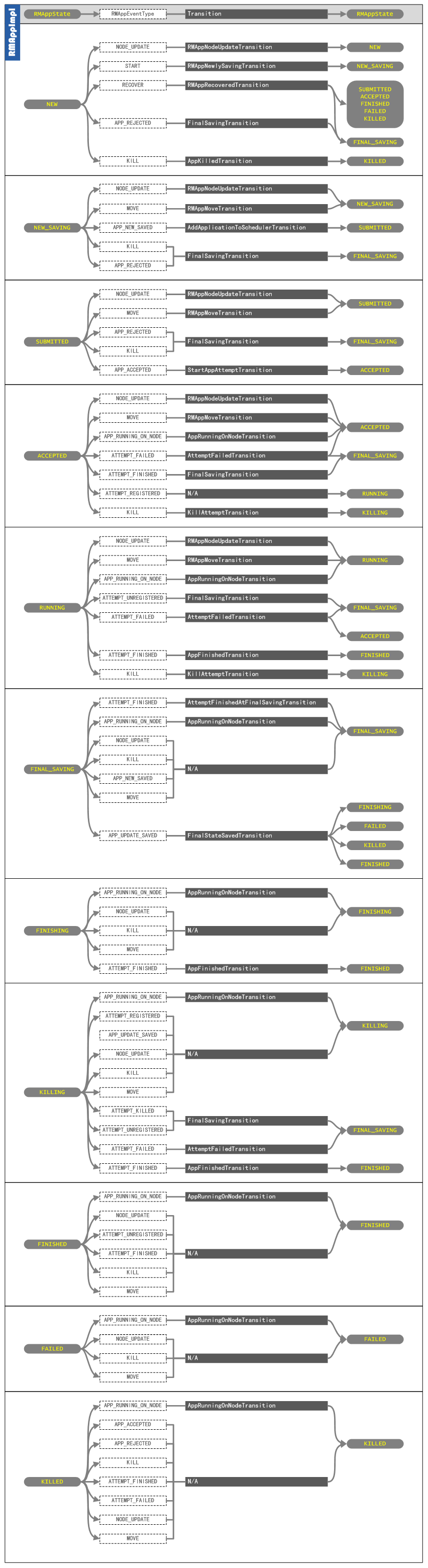
NMLivelinessMonitor源码分析实例
YARN主要采用了Dispatcher+EventHandler+Service这样的抽象,将所有的内部/外部组件采用这种机制来实现,由于存在很多的Service和EventHandler,而且有的组件可能既是一个Service,同时还是一个EventHandler,所以在阅读代码的时候可能会感觉迷茫,这里我给出了一个阅读NMLivelinessMonitor服务的实例,仅供想研究源码的人参考。
NMLivelinessMonitor是ResourceManager端的一个监控服务实现,它主要是用来监控注册的节点的Liveliness状态,这里是监控NodeManager的状态。该服务会周期性地检查NodeManager的心跳信息来确保注册到ResourceManager的NodeManager当前处于活跃状态,可以执行资源分配以及处理计算任务,在NMLivelinessMonitor类继承的抽象泛型类AbstractLivelinessMonitor中有一个Map,如下所示:
private Map<O, Long> running = new HashMap<O, Long>();
|
这里面O被替换成了NodeId,而值类型Long表示时间戳,也就是表达了一个NodeManager向ResourceManager最后发送心跳信息时间戳,通过检测running中的时间戳;来判断NodeManager是否可以正常使用。
在ResourceManager中可以看到,NMLivelinessMonitor的实例是其一个成员:
protected NMLivelinessMonitor nmLivelinessMonitor;
|
看一下NMLivelinessMonitor类的实现,它继承自抽象泛型类AbstractLivelinessMonitor,看NMLivelinessMonitor类的声明:
public class NMLivelinessMonitor extends AbstractLivelinessMonitor<NodeId>
|
在类实现中,有一个重写(@Override)的protected的方法expire,如下所示:
@Override
2
protected void expire(NodeId id) {
3
dispatcher.handle(
4
new RMNodeEvent(id, RMNodeEventType.EXPIRE));
5
}
|
我们可以通过该类NMLivelinessMonitor抽象基类中看到调用expire方法的逻辑,是在一个内部线程类PingChecker中,代码如下所示:
private class PingChecker implements Runnable {
02
03
@Override
04
public void run() {
05
while (!stopped && !Thread.currentThread().isInterrupted()) {
06
synchronized (AbstractLivelinessMonitor.this) {
07
Iterator<Map.Entry<O, Long>> iterator =
08
running.entrySet().iterator();
09
10
//avoid calculating current time everytime in loop
11
long currentTime = clock.getTime();
12
13
while (iterator.hasNext()) {
14
Map.Entry<O, Long> entry = iterator.next();
15
if (currentTime > entry.getValue() + expireInterval) {
16
iterator.remove();
17
expire(entry.getKey()); // 调用抽象方法expire,会在子类中实现
18
LOG.info("Expired:" + entry.getKey().toString() +
19
" Timed out after " + expireInterval/1000 + " secs");
20
}
21
}
22
}
23
try {
24
Thread.sleep(monitorInterval);
25
} catch (InterruptedException e) {
26
LOG.info(getName() + " thread interrupted");
27
break;
28
}
29
}
30
}
31
}
|
这里面的泛型O在NMLivelinessMonitor类中就是NodeId,所以最关心的逻辑就是前面提到的NMLivelinessMonitor中的expire方法的实现。在expire方法中,调用了dispatcher的handle方法来处理,所以dispatcher应该是一个EventHandler对象,后面我们会看到,它其实是通过ResourceManager中的dispatcher成员,也就是AsyncDispatcher来获取到的(AsyncDispatcher内部有一个组合而成的EventHandler)。
下面,我们接着看NMLivelinessMonitor是如何创建的,在ResourceManager.RMActiveServices类的serviceInit()方法中,代码如下所示:
nmLivelinessMonitor = createNMLivelinessMonitor();
2
addService(nmLivelinessMonitor);
|
跟踪代码继续看createNMLivelinessMonitor方法,如下所示:
private NMLivelinessMonitor createNMLivelinessMonitor() {
2
return new NMLivelinessMonitor(this.rmContext
3
.getDispatcher());
4
}
|
上面通过rmContext的getDispatcher获取到一个Dispatcher对象,来作为NMLivelinessMonitor构造方法的参数,我们需要看一下这个Dispatcher是如何创建的,查看ResourceManager.serviceInit方法,代码如下所示:
rmDispatcher = setupDispatcher();
2
addIfService(rmDispatcher);
3
rmContext.setDispatcher(rmDispatcher);
|
继续跟踪代码,setupDispatcher()方法实现如下所示:
private Dispatcher setupDispatcher() {
2
Dispatcher dispatcher = createDispatcher();
3
dispatcher.register(RMFatalEventType.class,
4
new ResourceManager.RMFatalEventDispatcher());
5
return dispatcher;
6
}
|
继续看createDispatcher()方法代码实现:
protected Dispatcher createDispatcher() {
2
return new AsyncDispatcher();
3
}
|
可以看到,在这里创建了一个AsyncDispatcher对象在创建的NMLivelinessMonitor实例中包含一个AsyncDispatcher实例。回到前面,我们需要知道这个AsyncDispatcher调用getEventHandler()返回的EventHandler的处理逻辑是如何的,NMLivelinessMonitor的代码实现如下所示:
public class NMLivelinessMonitor extends AbstractLivelinessMonitor<NodeId> {
02
03
private EventHandler dispatcher;
04
05
public NMLivelinessMonitor(Dispatcher d) {
06
super("NMLivelinessMonitor", new SystemClock());
07
this.dispatcher = d.getEventHandler(); // 调用AsyncDispatcher的getEventHandler()方法获取EventHandler
08
}
09
10
public void serviceInit(Configuration conf) throws Exception {
11
int expireIntvl = conf.getInt(YarnConfiguration.RM_NM_EXPIRY_INTERVAL_MS,
12
YarnConfiguration.DEFAULT_RM_NM_EXPIRY_INTERVAL_MS);
13
setExpireInterval(expireIntvl);
14
setMonitorInterval(expireIntvl/3);
15
super.serviceInit(conf);
16
}
17
18
@Override
19
protected void expire(NodeId id) {
20
dispatcher.handle(
21
new RMNodeEvent(id, RMNodeEventType.EXPIRE));
22
}
23
}
|
查看AsyncDispatcher类的getEventHandler()方法,代码如下所示:
@Override
2
public EventHandler getEventHandler() {
3
if (handlerInstance == null) {
4
handlerInstance = new GenericEventHandler();
5
}
6
return handlerInstance;
7
} |
可见,这里面无论是第一次调用还是其他对象已经调用过该方法,这里面最终只有一个GenericEventHandler实例作为这个dispatcher的内部EventHandler实例,所以继续跟踪代码,看GenericEventHandler实现,如下所示:
class GenericEventHandler implements EventHandler<Event> {
02
public void handle(Event event) {
03
if (blockNewEvents) {
04
return;
05
}
06
drained = false;
07
08
/* all this method does is enqueue all the events onto the queue */
09
int qSize = eventQueue.size();
10
if (qSize !=0 && qSize %1000 == 0) {
11
LOG.info("Size of event-queue is " + qSize);
12
}
13
int remCapacity = eventQueue.remainingCapacity();
14
if (remCapacity < 1000) {
15
LOG.warn("Very low remaining capacity in the event-queue: "
16
+ remCapacity);
17
}
18
try {
19
eventQueue.put(event); // 将Event放入到队列eventQueue中
20
} catch (InterruptedException e) {
21
if (!stopped) {
22
LOG.warn("AsyncDispatcher thread interrupted", e);
23
}
24
throw new YarnRuntimeException(e);
25
}
26
};
27
} |
将传入handle方法的Event丢进了eventQueue队列,也就是说GenericEventHandler是基于eventQueue的一个生产者,那么消费者是AsyncDispatcher内部的另一个线程,如下所示:
@Override
2
protected void serviceStart() throws Exception {
3
//start all the components
4
super.serviceStart();
5
eventHandlingThread = new Thread(createThread()); // 调用创建消费eventQueue队列中事件的线程
6
eventHandlingThread.setName("AsyncDispatcher event handler");
7
eventHandlingThread.start();
8
}
|
查看createThread()方法,如下所示:
Runnable createThread() {
02
return new Runnable() {
03
@Override
04
public void run() {
05
while (!stopped && !Thread.currentThread().isInterrupted()) {
06
drained = eventQueue.isEmpty();
07
// blockNewEvents is only set when dispatcher is draining to stop,
08
// adding this check is to avoid the overhead of acquiring the lock
09
// and calling notify every time in the normal run of the loop.
10
if (blockNewEvents) {
11
synchronized (waitForDrained) {
12
if (drained) {
13
waitForDrained.notify();
14
}
15
}
16
}
17
Event event;
18
try {
19
event = eventQueue.take(); // 从队列取出事件Event
20
} catch(InterruptedException ie) {
21
if (!stopped) {
22
LOG.warn("AsyncDispatcher thread interrupted", ie);
23
}
24
return;
25
}
26
if (event != null) {
27
dispatch(event); // 分发处理该有效事件Event
28
}
29
}
30
}
31
};
32
}
|
可以看到,从eventQueue队列中取出Event,然后调用dispatch(event);来处理事件,看dispatch(event)方法,如下所示:
@SuppressWarnings("unchecked")
02
protected void dispatch(Event event) {
03
//all events go thru this loop
04
if (LOG.isDebugEnabled()) {
05
LOG.debug("Dispatching the event " + event.getClass().getName() + "."
06
+ event.toString());
07
}
08
09
Class<? extends Enum> type = event.getType().getDeclaringClass();
10
11
try{
12
EventHandler handler = eventDispatchers.get(type);
// 通过event获取到事件类型,再根据事件类型获取到已经注册的EventHandler
13
if(handler != null) {
14
handler.handle(event); // 使用对应的EventHandler处理事件event
15
} else {
16
throw new Exception("No handler for registered for " + type);
17
}
18
} catch (Throwable t) {
19
//TODO Maybe log the state of the queue
20
LOG.fatal("Error in dispatcher thread", t);
21
// If serviceStop is called, we should exit this thread gracefully.
22
if (exitOnDispatchException
23
&& (ShutdownHookManager.get().isShutdownInProgress()) == false
24
&& stopped == false) {
25
LOG.info("Exiting, bbye..");
26
System.exit(-1);
27
}
28
}
29
}
|
可以看到,根据已经注册的Map<Class, EventHandler> eventDispatchers表,选择对应的EventHandler来执行实际的事件处理逻辑。这里,再看看这个EventHandler是在哪里住的。前面已经看到,NMLivelinessMonitor类的expire方法中,传入的是new
RMNodeEvent(id, RMNodeEventType.EXPIRE),我们再查看ResourceManager.RMActiveServices.serviceInit()方法:
// Register event handler for RmNodes
2
rmDispatcher.register(
3
RMNodeEventType.class, new NodeEventDispatcher(rmContext));
// 注册:事件类型RMNodeEventType,EventHandler实现类NodeEventDispatcher |
可见RMNodeEventType类型的事件是使用ResourceManager.NodeEventDispatcher这个EventHandler来处理的,同时它也是一个Dispatcher,现在再看NodeEventDispatcher的实现:
@Private
02
public static final class NodeEventDispatcher implements
03
EventHandler<RMNodeEvent> {
04
05
private final RMContext rmContext;
06
07
public NodeEventDispatcher(RMContext rmContext) {
08
this.rmContext = rmContext;
09
}
10
11
@Override
12
public void handle(RMNodeEvent event) {
13
NodeId nodeId = event.getNodeId();
14
RMNode node = this.rmContext.getRMNodes().get(nodeId);
// 调用getRMNodes()获取到一个ConcurrentMap<NodeId, RMNode>,
它维护每个NodeId的状态(RMNode是一个状态机对象)
15
if (node != null) {
16
try {
17
((EventHandler<RMNodeEvent>) node).handle(event);
// RMNode的实现为RMNodeImpl,它也是一个EventHandler
18
} catch (Throwable t) {
19
LOG.error("Error in handling event type " + event.getType()
20
+ " for node " + nodeId, t);
21
}
22
}
23
}
24
}
|
这个里面还没有真正地去处理,而是基于RMNode状态机对象来进行转移处理,所以我们继续看RMNode的实现RMNodeImpl,因为前面事件类型RMNodeEventType.EXPIRE,我们看状态机创建时对该事件类型的转移动作是如何注册的:
private static final StateMachineFactory<RMNodeImpl,
02
NodeState,
03
RMNodeEventType,
04
RMNodeEvent> stateMachineFactory
05
= new StateMachineFactory<RMNodeImpl,
06
NodeState,
07
RMNodeEventType,
08
RMNodeEvent>(NodeState.NEW)
09
...
10
.addTransition(NodeState.RUNNING, NodeState.LOST,
11
RMNodeEventType.EXPIRE,
12
new DeactivateNodeTransition(NodeState.LOST))
13
...
14
.addTransition(NodeState.UNHEALTHY, NodeState.LOST,
15
RMNodeEventType.EXPIRE,
16
new DeactivateNodeTransition(NodeState.LOST))
|
在ResourceManager端维护的NodeManager的信息使用RMNodeImpl来表示(在内存中保存ConcurrentMap),所以当前如果expire方法被调用,RMNodeImpl会根据状态机对象中已经注册的前置转移状态(pre-transition
state)、后置转移状态(post-transition state)、事件类型(event type)、转移Hook程序,来对事件进行处理,并使当前RMNodeImpl的状态由前置转移状态更新为后置转移状态。
对于上面代码,如果当前RMNodeImpl状态是NodeState.RUNNING,事件为RMNodeEventType.EXPIRE类型,则会调用Hook程序实现DeactivateNodeTransition,状态更新为NodeState.LOST;如果当前RMNodeImpl状态是NodeState.UNHEALTHY,事件为RMNodeEventType.EXPIRE类型,则会调用Hook程序实现DeactivateNodeTransition,状态更新为NodeState.LOST。具体地,每个Transition的处理逻辑如何,可以查看对应的Transition实现代码。
|






