|
���������Ƽ���ʷѧ��÷����?�����Ȳ���Melvin Kranzberg��������������������ĿƼ������ɣ����е�����������������[1]���������������䡰�ס������ģ���������ס��д���С��Technology comes in packages, big and small������
����������ڵ��£��Ƿdz�Ӧ���ġ���Ϊ������������һ���������ݣ�big data����ʱ���������������ġ�С���ݣ�small data���������������������˷���ȥ��������������𣿴���Ȼ���ǡ�Ŀǰ�������ݵ�ǰ;�ƺ����ǹ���á�����С���ݵļ�ֵ��Ȼ��������ޡ��������Ȳ���ĵ��������Ǹ������ǣ��¼������ϼ��������Ҹ����ݱ䣬�ǽ�֯��һ��ġ������ݺ�С���ݣ����ǡ�������������ͬ�������ݼ�����Data Technology��DT��ʱ����δ����
�Դ����ݵġ�����֮�ʡ����ѱ����������ڡ�Ϳ���������������������߿�÷��ij��֡�����������֪���κ����鶼�������ԡ������˶������ݺܺõ�ʱ������Ҳ��˵��˵�������ݿ������ٵ����壬ֻ��Ϊ���ô��������ߵø��ȡ����ڴ����ݵĹ����£����н�Զ����С����ʱ������Ҳ����С����֮����Ϊ���ǡ���С���У�����ƫ�ϡ������д�ĺã�С��С�����ͬһ���ˣ��ĵ�������İ���˼���������¿ꡣ
���IJ��־��ǹ����ߡ�˼�����IJ��ϣ���Ҫ��Ϊ4�����֣���1���ĸ�V���Ǵ���������Ҫ������������һ������������Ĵ����ݵ�4V�����У��ĸ�V���Ǵ����������е������������������µ����Ļ�������2�������ݵ����������塣����һ���֣��������Ĵ��������������֮�����������ٵ�3�����塣��3��������л��ǰ�࣬��δ������ռң�����һ���֣�����Ҫ˵������������Ȼ�ܻ𣬵����������ݷ���������ʵ˵�������������û����ô�ռ���С����Ŀǰ������������4���������ã��������졣����һ���֣�����˵˵��С����֮��������á�n=all�������������ݣ���ô�Ϳ����á�n=me����˵��С���ݣ�����n��ʾ���ݴ�С�������ǽ��ῴ����С���ݸ��ǹ�ϵ�����ǵ��������档
1.�ĸ�V���Ǵ���������Ҫ��������
��̸��������ʱ������ͨ����4V����������������4����VΪ����ĸ��Ӣ�ģ�Volume����������Variety����������Velocity���ٿ죩��Value����ֵ������� ���������¡������Ƿ�Ҫ����4��V�ڡ������ס������������ĸ����Ǵ����ݵ����е������أ��������Ǽ�Ҫ��˵��˵������ͼ˵�������⣬�����Ľ�������������������֮�⡣
1.1 �����в�ͬ����Volume��������
����������˵˵�����ݵĵ�һ��V����Volume������������Ȼ���ݹ�ģ���ҳ������ָ���������ͨ����Ϊ�����ݵĵ�һ������������ʵ�ϣ�����20��ǰ���ڵ�ʱ��IT�����£����ġ����������������̵�����Ŀ�����������������Щ���������ܵġ������֮ʹ����ʱʵʱ������ѶȲ�������С����Ϊ��ʱ�Ĵ洢�����������û�г�����Ƽ���ܹ��ͳ�ֵļ�����Դ��
���ң�����������һ����Եĸ�����ݵĴ���С��ͨ�������ź�ǿ��ʱ����ӡ��Ϊ��˵������۵㣬�������Ȼع�һ�±ȶ�?�Ǵĵľ��䡰����Ԥ�⡣

ͼ1 �ȶ��Ǵ���1981����ڴ��С��Ԥ��
����1981�꣬��Ϊ��ʱ��IT��Ӣ���ȶ�?�Ǵ���Ԥ��˵����640KB���ڴ��ÿ���˶�Ӧ���㹻�ˣ�640KB ought to be enough for anybody��������30�����Ľ��죬�ܶ��˶���Ц���Ǵģ���ô�������ˣ���ô��Ԥ�����˲����ף��������һ�������ֻ�����ʼDZ����ԣ����ڴ�Ĵ�С����4GB��8GB�ġ�
���ǣ���Ҫע�����ʵ�ǣ���1981�꣬��ʱ�ĸ��˼������PC���ǻ���Ӣ�ض�CPU 8088оƬ�ģ�����CPU�ǻ���8/16λ��bit����Ϲ��ܵĴ���������ˣ�640KB�Ѿ�������CPU����֧�ֵ�Ѱַ�ռ�����ۼ��ޣ�64KB����10��[2]�����仰˵��640K�ڵ�ʱ�Ƿdz��dz����Ӵ��ˣ��ٻص����ڣ���ǰPC����CPU��������64bit�ģ�������֧�ֵ�Ѱַ�ռ���2^64�������ڵ�4G�ڴ棬���������ۼ���(2^32)/(2^64)= 1/(2^32)������
����������С���µ�ԭ�����ڣ��������ݴ�С����������ʱ������������������ҵ���������⣬�����ݲ�������������������������������ʱ������ָ��[3]����������ij�̶ֳ��ϣ�������Ϊ��ȫ���ݣ���n=all��������ʱ,һ����ν�ġ�ȫ�����ݿ⣬������Ҫ����TB/PB�Ƶ����ݡ�����Щ�����У�ij����ȫ�����ݿ��С�����ܻ�����һ����ͨ�Ľ��м������ֽڣ�MB��������Ƭ���������ǰ�ġ����֡����ݣ����ֻ�м������ֽڣ�MB����С�ġ�ȫ�����ݣ����Ǵ����ݡ��ʴˣ�������֮����ȡ��Ϊ������壬���Ǿ������塣
������������������ͷ��PB�����ݣ������Ǵ����ݣ�����MB��ȫ����Ҳ�����Ǵ����ݣ����һ���� ������֮�����������в�ͬ���ɴ��С����˲������ס��������������������������е�������
1.2 ���ݹ���������Velocity�����٣����롰Value����ֵ����
Ӣ�ض��й��о�ԺԺ�����ɳ������ָ���������ݵ�������Velocity�����٣��������硰�����书��Ψ�첻�ơ�һ����Ҫ���������족�֡�ΪʲôҪ���족����Ϊʱ����ǽ�Ǯ�����˵��ֵ�Ƿ��ӣ���ôʱ����Ƿ�ĸ����ĸԽС����λ��ֵ��Խ������ͬ��������ݡ���ɽ�������ڿ�Ч���Ǿ������ơ�
����������ѧ�����ν���ȴ��Ϊ[4]��1��������������Ͳ��Ǵ����ݵ���������Ϊ�����Խ��Խ�á����������Դ��м������������������û�б仯���������ڣ�ȴ������Ϊһ����ʱ������Ҫ��������ȫ����̸֮�� ����Ҳ�����������˵������һ�������ϵġ�ͨʶ��Ҫ������һ�����������������ȷʵǷ�ס�
���Ʋ��Ļ��д����ݵ�����һ����������Value����ֵ������ʵ�ϣ������ݼ���ֵ���ļ�ֵ�۹�����֮�����磬�ڡ����ӱ���?ʼ��ƪ���У�������������۶ϡ�����ʤ�����㲻ʤ������������������˴� ���㡱�������Ҳ��Ҳ���Ǽ����õij��룬�����þ��ǣ�����������֣������Ƹ������أ��Ӷ��������ߡ�
������֮ս�У�����ͨ�����조�����κ��Ϊʮ�������Ϊ�����������Ϊ�����ʷ�ǡ����������д����������ݣ�������丵����ݷ���ϰ�ߣ����������֮�������ʵʩ��ɱ��
��˵����һ�������ֱ뽫���Ķ��ӣ���ٲ��ɿ�����������ս���У��ִ�ͨ�������ɻ�Ķ�ǹ�볤ǹ�������ɻ�ͻ���С����������Լ���²�ͻ��еľ�����ʿ���ı������쳣������˵ó����ۣ����˵�ָ�������ڸ�����������Ȼ��ͨ�����Ӻ����������ߵ��Dz��ֵ��ˣ���������˧������������ҫ�档
��ս���ϣ����ݵļ�ֵ�������Ǹ�����������ʤ������һ��ֵ��ע����ǣ�������İ����У�ս���ϵ����ݣ��������ľ�ʦ�ǣ����ܡ���ָһ�㡱��������Ȼ����ʮ���С���ݣ�������ȴ�����кܶ����硰�ֱ�Ҳ������ݡ����������ֱ�ѧϰ�����ݡ������Ƶ����£���ʹ��������ˡ���������е����ݷ���˼ά�İ������������ڴ����ݵĻ����Ǵ����ݵİ�������������������������ʤ���ˡ�
��ˣ�Value����ֵ��ʵ�ڲ������Ǵ�����ר������������С���ݡ�Ҳ���м�ֵ�ġ������ĵ�4�ڵķ����У����ǿ��Կ�����С���ݶԸ��˶��ԣ�����ֵ�����Dz���С�����һ���������С���ݶ��м�ֵ�����ԡ���ֵ����Ϊ�����ݵ������أ� ��ʵ�ϣ���ǵ�IBM���ڶԴ����ݵ����������У�ѹ����û�С�Value�����V����ͼ2��ʾ����
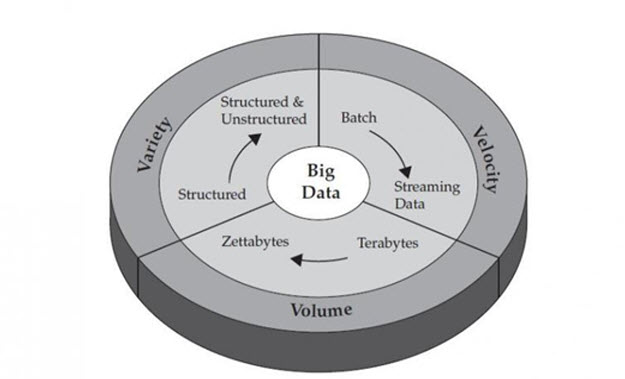
ͼ2 IBM��˾�����Ĵ�����3V������ͼƬ��Դ��disquscdn.com��
����֪������ν���������ߣ���������������֮�ص㡱������ȷ����������˵���б������������˵��������������ܾͻ���ò��ף����ѵ�Ů�˾�û�б���û���۾��𣿡��ǵģ����б������ۡ������˺�Ů�˵ġ������������ǡ���������ͬ���ĵ�����Velocity ��Value������V��ͷ�ʻ㣬�Ǵ�С���ݶ����еġ��������� ʵ��Ҳ���㲻���Ǵ����������е�������
1.3����͡��ס�����Variety��������
ͨ����Ϊ�������ݵĶ����ԣ�Variety������ָ����������������������֣�Ī���ڷ�Ϊ�����ࣺ�ṹ�������ݺͷǽṹ�����ݣ����ڡ��ǽṹ�����ݡ�ռ���������ݱ�����70%~80%�����ڵķǽṹ�����ݣ�����ҵ���ݵ��ᄈ���������������ʼ����ĵ���������ҽ�Ƽ�¼�ȷǽṹ���ı������Ż���������������Internet of things��IoT���Ŀ��ٷ�չ�����ڵķǽṹ����������չ��������ҳ���罻ý�塢��Ƶ����Ƶ��ͼƬ����֪���ݵȣ���ڹ�������ݵ���ʽ�����ԡ�
���������ȥ���ͻᷢ�֣����ǽṹ����δ�ؾ��Ǹ������ĸ������Ϣ�У����ṹ����������ġ�����ν�ġ��ǽṹ������������ijЩ�ṹ��δ���������������������ѡ�����IT��ѯ��˾Alta Plana�ĸ����ݷ���ʦSeth Grimes����IT�������������Ϣ�ܿ�����Information Week����ָ������������ν�ķǽṹ����������˵�ġ��ǽṹ������Ӧ���Ƿ�ģ�ͻ���unmodeled�����ṹ���ڣ�ֻ�����Ǵ������ݵĹ���δ����δ��ģ���ѣ�Most unstructured data is merely unmodeled��[5]����ͼ3��ʾ����
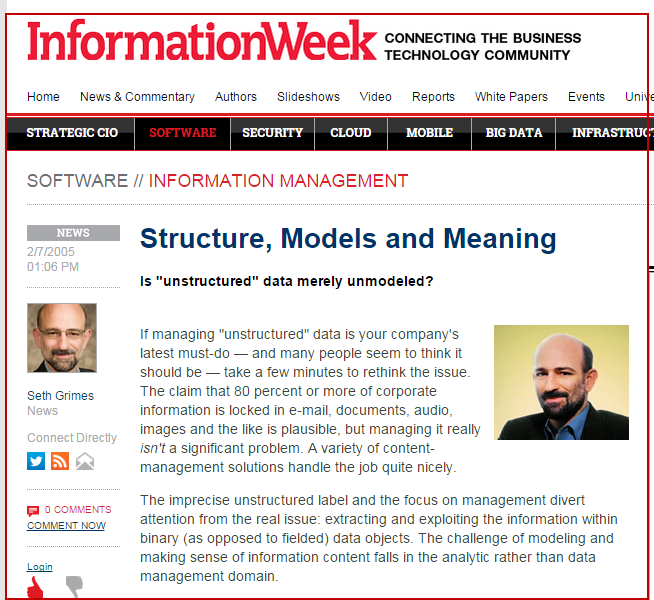
ͼ3 Seth Grimes���ǽṹ����������Ӧ�Ƿǽ�ģ
�����ݵĶ����ԣ�Variety���������������������IJβ���ϡ����仰˵������ᄈ�µĶ����Ծ��ǻ����ԣ�Messy������������������ʣ�����������������ݵĻ����ԣ��������Dz��ɱ���ģ��ȿ��������ݲ������ڲ������ݹ��̳��������⣬Ҳ�����Dzɼ���洢���̴������⡣�����Щ����������żȻ�ģ���ô�ڴ������У���һ���ᱻ�������ȷ������û����������ʹ�ô����ݾ߱�һ�����ݴ��ԣ�����������ڹ����ԣ���ô�ھ߱��㹻������ݺ��л��ᷢ��������ɣ��Ӷ����й��ɵġ���ϴ���ݡ������������˵������ɳ������Ϊ[15]����Ԫ���Ƶ����ݣ��ܹ�����������ȥα���棬��Ϊ�������йػ����Եľ��������������������Եز������������ڵĴ�����������ʱ����[3]��
��ʵ�ϣ������ݵĶ����ԣ�Variety��������Ҫ��һ�棬���DZ��������ݵ���Դ�����;���ϡ�ÿһ��������Դ��������һ����Ƭ���Ժ;����ԣ�ֻ���ںϡ����ɶ������ݣ����ܷ�ӳ�����ȫò������ı��ʺ��������ڸ���ԭʼ���ݵ������֮�С���ͬһ�����⣬��ͬ���������ṩ������Ϣ���ɶ������и�Ϊ��������⡣����ڴ����ݷ����У��㼯����������Դ�������ǹؼ����й�����Ժ�����Ժʿ��Ϊ[6]����dz�������Ǯѧɭ����������ġ�����ǻ�ѧ�������ؼ���ɣ����ܵ��ǻۡ���
������ʷѧ����پ��������վ����ʷ�ĸ߶ȣ�Ҳ�������Լ��Ĺ۵㣬��˵�������ݡ�֮�����ܳ�֮Ϊ�������ݡ��������ڣ��佫���ַ�ɢ�����ݣ��˴���ϵ���ɵ���ߣ����߶��棬�������Σ���հ���������ĸ����棬Ҳ���������������ı��ʺ�δ��ȡ��
Ӣ����ѧ�Ҽ�����ѧ������˹�������գ�Thomas Crump��������������������ѧ��The��Anthropology of Numbers��ָ��[7]�����ݵı������ˣ��������ݾ����ڷ���������Ⱥ���������ݱ���һ��Ҫ��ԭΪ�ˡ����ϴ�ѧ֪����ѧ�������˻�������Ϊ[8]����Ȼÿ��������Դ���䵥����Ե�ģ����Ȼ���ɡ�����ģ�����������ľ۽�����ȡ����ľ�ȷ����ȷ������������ϵ���ܺͣ�����˼����������������Լ��ġ������ԡ����������κ�ʱ�����ڽ�ʾ�����ġ��ܺ͡���
��ˣ������Ժʿ��Ϊ[6]�����ݵĿ��Ź������ṩ�˶�����Դ�������ںϻ��ᣬ�����ǽ����������£����Ǿ��������ݳɰܵı�Ҫǰ�ᡣ
���Ϸ����ɼ�����Ȼ�������кܶ���������������������11��V�������������ݵĶ����ԣ�Variety��������������������С���ݵ�����Ҫ������
2. �����ݵ�����������
�����ݵĶ����ԣ��������ݷ����������Ӵ�������������������Ҳ�����˴����ݵ����壬�������Ǿ�����������⡣
2.1 �����ݵ�����
�ܶ�С���ʡ���Ӱ����¼�����������¼������ڵ�һ��С���ݻ����£��ܿ������Է��֡������ɡ��˷����͡��㼯�����Ĵ����ݣ�ȴ���л����ṩ��Ϊ��̵Ķ��죨insight�������磬��֢����һ�β��֢������������Ŭ������֢�����ʽ������˲���8%������һ����Ҫԭ���ǣ�������֢�����ƻ����İ�֢������������������ޡ���С�������ó����о����ۣ��ó��йء���֢��ϡ��Ľ��ۣ����п����ǡ�ä��������[9]��
���ǣ�Ӣ�ض���˾����ġ����ݿ��ȹݡ�������ɳ��������һ���������ȣ���˵���ȹݵĺô����ڡ�Let ideas have sex�����������ݲ�����ֵ�����������Ĺؼ��ǡ�Let data have sex����ȡ����ˣ����ݿ��ȹݡ��ĺ����������ڣ��Ѳ�ͬҽ�ƻ����İ�֢�������ݻ�۵�һ���γɴ����ݼ��ϣ�����ͬ����������ݣ�����굫����ʶ�����ö�Դͷ�ġ�С���ݡ��㼯��������ʵ������֮�䡰1+1>2���ļ�ֵ���Զ������ں��á�have sex������������Ƿdz�����˼�ģ���Ϊ����������Ҫ�ﵽ��1+1> 2����Ч�����Ͳ��ܴ��š����ӡ����ţ���Ҫ���ơ��������ĸ�ݡ����ѹ���Ժʿһֱǿ�������ݵ���ͨ�ԣ��Ǿ��������ݳɰܵ�ǰ�ᣬ������ģ�������٩�����ɽ��棩��
���Ƶģ�2014��������ͳ�칫�ҷ�������Ϊ�������ݣ�ץס��������ס��ֵ��Big Data:Seizing Opportunities, Preserving Values�����ı���[10]�������о���һ��������
Broad �о�Ժ������һ������ʡ����ѧԺ�����ѧ���ϴ�������������Ļ����о����������о���Ա���֣������Ļ������ݣ���ʶ���Ŵ�����Լ����������У����ż�����Ҫ�����á�������о��У������������� 3,500 ʱ���뾫�����֢�йص��Ŵ����죬����������������ʹ�� 10,000 ������ʱ��Ҳֻ����ϸ��ʶ�𣻵��ǵ������ﵽ 35,000 ʱ��ͳ��ѧ�ϵ�ͳ�������ԣ�statistically significant����ͻȻ��ʾ����������һ���о���Ա���۲쵽��������������һ���յ㣬һ����Խ��һ�нԱ䣡��There is an
inflection point at which everything changes����[11]����ͼ4��ʾ��������������У������ݰ���ѧ�еġ����������ʱ䡱��������쾡�¡�
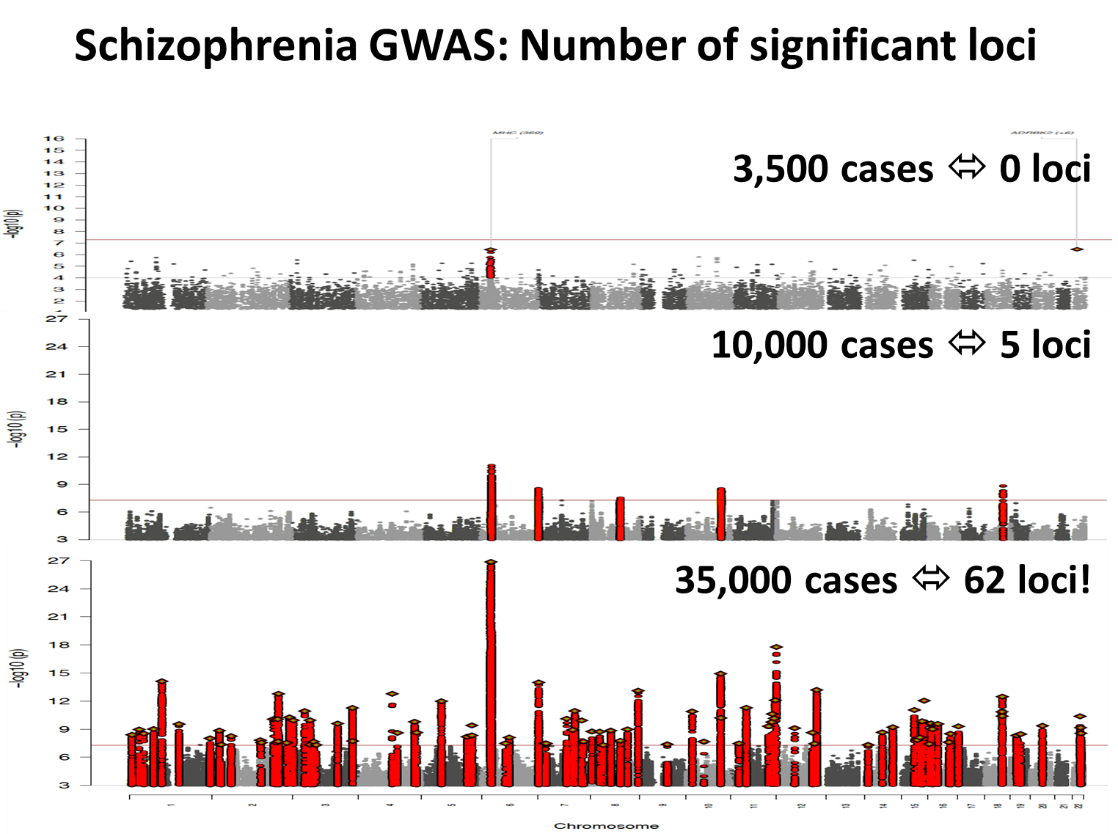
ͼ4 �������֢�йص��Ŵ����췢�֡��������ݵġ��㼯����������ͼ��loci��ʾ�������������ֳ���λ����������Ⱦɫ������ռ��λ�á��ڷ���ˮƽ�ϣ������Ŵ�ЧӦ��DNA���С�ͼƬ��Դ��MIT��
2.2 �����ݵ�����
�����ݵĶ����ԣ����������ˡ��������������ǻۡ�Ȼ��������Ӣ�����ƣ�:��һ��Ӳ�������棨Every coin has two sides������ ���������Ҳ�����һЩ���˲���ġ����塱���á���Ҳ���Σ���Ҳ���Ρ������������ݵ����ѣ���ǡ�������ˡ�
2.2.1 DIKW��������ϵ
1989�꣬����ѧ�����ء����ɷ�Russell .L. Ackoff��д�ˡ������ݵ��ǻۡ���From Data to Wisdom����ϵͳ�ع�����DIKW��ϵ[12]�����ӵ͵�������Ϊ���ݣ�Data������Ϣ��Information����֪ʶ��Knowledge�����ǻۣ�Wisdom��������ѧ�������ᣨZeleny�������4��Know��֪��������[12]���Ƚ������������DIKW��ϵ�е�Ԫ�أ���ͼ5��ʾ��
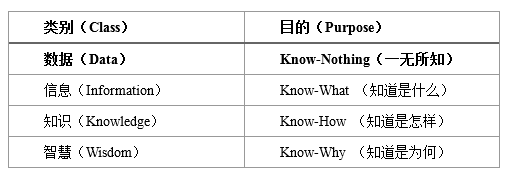
ͼ5 �������DIKW��ϵ��4��Know����
�������DIKW��ϵ��ע�⣬���˸д�����Ŀ������ڣ����������ʵʩ��һ���ش�������ʹ�ռ����ݵ������١���Ҳ����ֵ����Ϊ���������ݱ����������ǡ�һ����֪(Know-Nothing)���ġ��������ļ�ֵ�������γ���Ϣ�����֪ʶ����������Ϊ�ǻۡ�
�������������������������ʱ�����и����Ĺ۵��ǣ���Ҫ��أ���Ҫ���������֪������ʲô�����ˣ�û��Ҫ֪����Ϊʲô��������DIKW��ϵ��֪�����������Ϊʲô����Ѱ����ʵ�ϣ��ͷ����˶Խ���������ˡ����ǻۣ�Wisdom���������ǻ���������ͻ�����ʵ�����
�Դˣ�����ѧ�����ν����ܽ�÷dz����ʣ�������������Ե����Ƿ�������������ڼ����֮�ϵ��������ƣ������������ķ��ݺͶ��䡣���δ��ijһ������ͼ�����ȫ�ӹ���������磬��ô���ַ�������ĩ��֮ʼ�����Դ����ݵ�����Ժ�����Ե�̽�֣������Ѿ��ڡ����Դ����ݵķ�˼����Ҫ�������10��С���¡�һ����[14]�������漰���ڴ˲����ԣ�����������̽�ֵ��ǣ���ʵ�ϣ��������ϵ��Ѱ����������е�˼ά�����������˼ά�ƶ��£���������ѡ���ء������������������������Ҫ����Ĵ��������塣
2.2.2 ��ѡ���ء����������
��ν������ԡ���ָ�������������ϱ�����ȡֵ֮�����ij�ֹ����ԡ���������A��B������ԣ�ֻ��ӳA��B��ȡֵʱ���Ӱ�죬��������˵����Ϊ����A��һ����B�����߷�������Ϊ��B��һ����A��
������������У��ƺ�һֱ��˵������ԡ��IJ��㡣����ʵ�ϣ�������ںܶೡ���Ǽ������õġ����磬�ڴ�������С�����ϣ�����Ծ������õģ�����ѷ�ĵ���������Ի��Ƽ���������������ԣ��������˿��Ƽ���صĻ�������Ʒ�������˿�������Ʒ�����ˣ�����ѷҲ��ø��ò���������
Ȼ��������С�����Ĵ���ߣ�������Ե�����Ȼ�dz���Ҫ�����ɳ�����á�����ҩ��ҩ������ȣ�������һ���ܾ��ʵ����ӣ���˵������Ժ�����ԵĹ�ϵ[15]��������ҩ�������ԣ����ǡ���ũ���ٲݡ�ʽ�ľ��鴦����Ŀǰ��������֪���������һ��������û�пɽ����ԣ����ó�����Щ��Ƥ�ͳ�ǵ���Ϊʲô���ǵ���ijЩ���������Ĺ������仰˵����ҩ�������ˡ�֪��Ȼ���Σ�����ʲô������������ǵĹ���ֹ���ڡ�֪������Ȼ������Ϊʲô��������ô��ҽ��Ҫ�߳��й����������磬�Ƿdz����ѵģ�ע������������ҽ�������ߣ��벻Ҫ�������ں���ҽ����
����ҩ��ͬ���ڷ�������Ժ�û��ֹ�������ǽ�һ��Ҫ������������飬�����п��ܵ��¡������Ĺ����ĸ��������ų����������ԺͿɽ����ԡ�����ҵ������Ҳ�����ƣ������ֻ�Ǿ��ߵĿ�ʼ����ȡ�������Դ�������ֱ����õļ��裬��������֤����ԵĹ�����Ȼ����Ҫ��
�ڴ�����ʱ����������ԡ����ܶ�����ݷ�˿��Ϊ������ǰ��Ҳ�ᵽ��������ԡ�Ҳ��ȷ���ã�����ʱ������վ����ᱻ���ɡ����ս𡱣���֮���壬����ǧ��ܶ�ʱ�����ǻ�Ծ��ذѡ�����ԡ����Ծ��ص���������ԡ���
���ô����Ŵ�ѧ����ѧԺ���½�����ָ��[16]���ڴ�����ʱ����ֻҪ�г��������ͳ�����������Ƕ������ҵ�����ͷʽ������ԡ���������ÿ�깫��4.5���ྭ�����ݡ������Ҫ��ʧҵ�ʺ�������ʲô����Ӱ�죬���������10�ڸ����衣ֻҪ�㷴�����Բ�ͬ��ģ�ͣ���ǧ�κ���һ�������ҵ�ͳ��ѧ�����ϳ���������ԡ��������ǽ�����С���£����ӣ���˵������۵㡣
��С����ʱ����1992�꣬���������һ�����������硶��ʱ����������������Ա֣�������ݶ�з����з��һ������Ĺ��ɺ����ڣ�����ƣ�����������á���1992������20�����ֻҪ����̨һ����֣�������ݵ������磬��ۺ���ָ�������в�ͬ�̶ȵ��µ����˳ơ���зЧӦ��������ЧӦ����������������֧�ֵģ���ͼ6��ʾ��ÿ��֣�������ݵĵ��Ӿ粥��Ԥ��ʱ��������۹����绰������̨��ϣ����Ҫ���ţ���Ϊ���Ŀ�Ǯ��
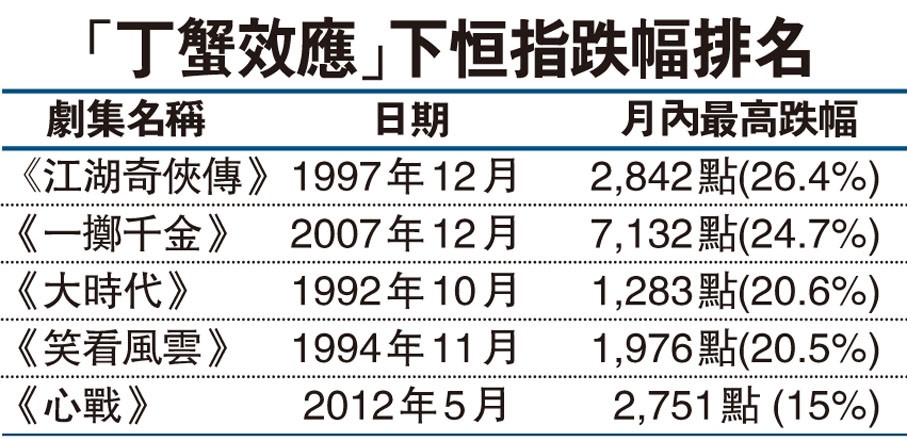
ͼ6 ��зЧӦ����۹��У�ͼƬ��Դ���Ļ㱨��
������ͷ���ǣ�������Ի������й��˶�Ա���������ˣ������Ǹ��������д桱���ӣ��������������ģ�
2008��8��18�� �������˻ᣬ��������������������д��5.3%������һ�����ڴ��20%��
2014��9�����������һ���º��оͿ�ʼ���ǣ���2300���ǵ�5178�㡣
2015��6��26�գ�������飬���м��������8%�����е��ǵ�ԭ��������Ϊ���谡��
��ˣ�������ǿ��Ҫ�����辡�������ٴν�顣
��۵Ĺ���Ϊʲô��ϣ��֣�������ݵĵ��Ӿ粥�ţ�����Ϊ�µ��Ӿ�һ���ţ����о��µ�����½�Ĺ���Ϊʲôϣ�������ٴν�飬��Ϊ������ϲ�ˣ����Թ��о���ϲ�ˡ�ע�ǰ�����������ֳ����ġ������ϵ����
��ʵ�ϣ�����ʱ�������������֮���к������ϵ���������������ˣ��������ˣ�ͳ���ϵġ�����ԡ��ͻ�ð�������ѡ�������ȴ��DZ��Ĭ�����ذѹ۲쵽�ġ���ء����������ﱳ��ġ��������
���˿��ܲ��Ͽ������۵㣬��Ϊ��������С���£��������ڶ��Ӽ���İ�����������˵�����⣿�����Ǿ;�һ���Ŷ���֮�İ�����˵������۵㡣������Կ���������֣�
��÷ʱ�ڼҼ���,��ݳ��������ܡ�
�����侢���裬��ҹ������������
�������꽿�εΣ���������һƬ����
�������磬����������������Ϯ��Զ���������Բԡ�
�ʰ��꣬�㻹�ǵõ����������ߵ��������
����֪������ѧ��Ȼ�����������Դ�����������ӹ�����ġ�����ī�͡���ʫ�黭���У�������ϡ�ɿ���һ�������ԡ����������Ⱦ������ڹ۲췢�֣�����������������ͬʱ�����������ij��ڹ۲�������Ҳ�ɳƵ����ǡ������ݡ������ǣ���������Ĺ��ˣ��ڴ��ڣ��ͻ�����������ԡ�����������ԡ��ˣ���ͼͨ��ѧ���������ꡣ�ڶ��ʧ��֮�����������������ڽ�[8]����ͼ7��ʾ������С����һ�����ڴ������У��ɽ����ԣ������ϵ��ʼ������Ҫ�ġ�

ͼ7 ӡ���������������ϰ�ף�ԴԶ�������������棨ͼƬ��Դ����������
�����۴�ʼ��֮һ����ż������ѧ��ŵ����(John von Neumann)��Ϸ�Գƣ���������ĸ����������ܻ�ͷ��������ٸ�һ�������ô���ı������������������ݵ���Դ�����ԣ����������ԣ�Ϊ���� ����ӱ��������ԣ����������ܡ��������ϣ����Ƕ������ϵ������ʵ�ϣ��Ѿ�����ٹ̣�����˼ά�����������ı䣬���ڴ�����ʱ������������ð�����������ԣ����һ����������ۡ��������ݵ�ӵ������˵����Ҫ��أ���Ҫ�����������ʵ�ϣ��ںܶ�ʱ���ر��������ڶ�δ�����ѿص�ʱ�����װѡ���ء�����������������Ǵ�����ʱ����һ���ܴ�����壬�ر�ֵ��ע�⡣
2.2.3 �����ݵ���������
���棬����������һ��С�����¡���˵�������ݵĵڶ������壺
��������һλ����ǧ�����¹ʵĺ�˾������ؽ�������Ȥ��Ȼ�������ѼҺ��˵�С�ƣ���ʱ���ƾ���Ҳ���°�����ˣ����������Լ������ؼң���������ƺ�ݳ����¹ʵĸ���Ҳ����ǧ��֮һ�ɡ���������㣬��ͷ���һ��ȡ��������Ϊǰһǧ�γ�������û�Ⱦƣ����Dz��ܺ���Ρ��ƺ�ݳ�������һ����㣨������Դ���ο�����[16]����
���Ǵ����ݷ����еĵڶ���������������塣�����ݵĶ���������������������ϵġ������ԡ���ijЩ��Ƶ������Ҫ�����źţ������ױ������������˵��ˣ��Ӷ�ʹʧ���֡�����족�¼��Ŀ����ԡ�
�����磬��������ѧϰ�ɻ���ʻ�Ǽ���˾�ռ��ߡ����£��ڼ�ʮ��ѧϰ�ɻ���ʻ�ļ�¼�У���������йص�����ע�������ô��λѧԱֻѧϰ���ɻ���ɡ�������ѧϰ���ɻ����䡱����ô9/11�¼������Ϳ��Ա��⣬����ĸ�ֿ��ܾʹ˷��������Եı仯����Ȼ������¼�ҲΪ�й�Ӯ����10��Ļƽ�չ�ڣ����ڱ��ĵ����۷�Χ���Ͳ�չ��˵�����ڴ�����ʱ���ķ����У����������Ծ�ȷ���������Ի������ݵĽ��ɣ�������ġ����ӷ��ݡ����ͻ��γ�һ����������塣��ˣ����衰δ����ѡ������������
�ڴ�����ʱ���������ֵ��ע��������ǣ������ݵ�ӵ������Ϊ�������ݿ���������n=all��������n���ݵĴ�С����������������������Ҳ�Ͳ������в���ƫ������⣬��Ϊ�����Ѿ��������������ݡ�����ʵ�ϣ���n=all������������ͳ��ѧ���ǻ���200���꣬�ܽ����֪���ݹ����е��������壨��ͳ��ƫ��ȣ�����Щ���岻��������������������Զ���ƽ�����ڡ����Դ����ݵķ�˼����Ҫ�������10��С���¡�һ���У��������ۣ������ԡ�
3.������л��ǰ�࣬��δ������ռҡ���������û��ô�ռ���
Ŀǰ����Ȼ�����ݱ����û��ȣ���������Ʊ���״����Ĵ�ү���趼�������ϼ��䡰�����ݡ�����ɣ����Ǵ������������ô�ռ���
��ʵ�ϣ�������Ҫ������ô����ݣ�����Ҫ�߱�3����������1��ӵ�д����ݱ�������2���߱�������˼ά����3���䱸�����ݼ��������������ż�����ʵ�ϣ��Ѿ��Ѻܶ˾��ҵ��֮���⣬�����������Ǿ�ʫ��������л��ǰ�࣬����Ѱ�����ռҡ�����������Ȼ������ô�ߴ��ϣ�ԶԶû����ô�ռ���
ͼ8��ʾ���ǣ�����IT��ѯ��˾�ߵ��ɣ�Gartner����2014�깫���ļ�����������ߣ�hype cycle�������ڽ���hype cycle������ɡ���������ߡ���ʵ����̫�������ˣ�ֱ��Ϊ���������ڡ�Ҳ����Ϊ������ͼ8���Կ������������Ѿ����˳����ĸ߷��ڣ�Ŀǰ������ĭ���ĵ��� (Trough of Disillusionment)��
������ǰ��ĿƼ������ٶ��� (Technology Trigger)����������ֵ�ڣ�Peak of Inflated Expectations���������Σ���ĭ���ĵ��ڴ�������ĿƼ���������ݣ�����Ҫ����������������������ߣ�Ҫôҧ����ִ��£�Ҫô������̭���֣��ܳɹ���������ļ�������Ӫģʽ�����������ʵ����׳�ɳ���
�����Ժʿ�ڽ��ܡ������ձ����IJɷ�ʱ��Ҳ���������ƵĹ۵㣬�������ݸոչ��˳����ĸ߷��ڡ�[17]���侲�����Ĵ����ݣ����������ߵø�Զ��
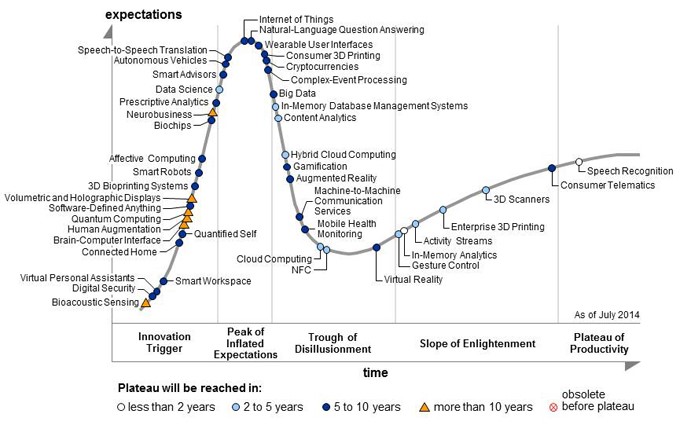
ͼ8 �ߵ��ɼ�����������ߣ�ͼƬ��Դ��Gartner��
�����Ժʿ����ʾ����������������Ϣ����һ������һ��ʱ������ѭָ����չ���ɡ�ָ�����ɷ�չ���ص��ǣ���һ��ʱ�ں����ڣ�����30�꣩��ǰ�ڷ�չ���������൱��ʱ�䣨������Ҫ20�����ϣ��Ļ��ۣ������һ���յ㣬���˹յ��Ժͻ���ֱ�ըʽ�����������κμ�����������Զ���֡�ָ���ԡ����������Ľ�֣�Ҫô�������Է�չ���ȶ�״̬��Ҫô����������
�����ݵIJ������ǣ��ſڱտ��Գƴ����ݽ���PBʱ���ˡ����磬�����ߡ���־��ǰ�������˹������ɭ����2008��˵������PBʱ���������Ӵ�����ݻ�ʹ���Dz�����Ҫ���ۣ�����������Ҫ��ѧ�ķ������������������Ҳ�Ƿdz������ģ�����Ҫ����ˮ���д����ݡ�
�ڴ�����ʱ��������Ҫϰ�������ݷ����������ͳ���������Դ���������ѧ���ڿ�����ѧ����Science����2011�꣬����ѧ�����鷢��[18]���ڡ�����Ŀ����У���ʹ�õģ��������������ݼ��Ƕ�����ʾ������У���ͼ9��ʾ����48.3%���ܷ�����Ϊ�����ճ�����������С��1GB��ֻ��7.6%���ܷ���˵�����ճ��õ����ݴ���1TB��1TB=1024GB��1PB=1024TB����Ҳ����˵������������ʾ��92.4%�û����õ�����С��1TB��һ����������ͨӲ�̾���װ�ص��£�������Щ�����Գ�PB����Ĵ����ݵIJ�����������Կ��������������ضȹĴ���IDC��Ŀǰ����Ϊҵ����ҡ���ź�ZBʱ����1ZB=1024PB��������һ��Ҫ���ۿ����磬���������ưɣ�
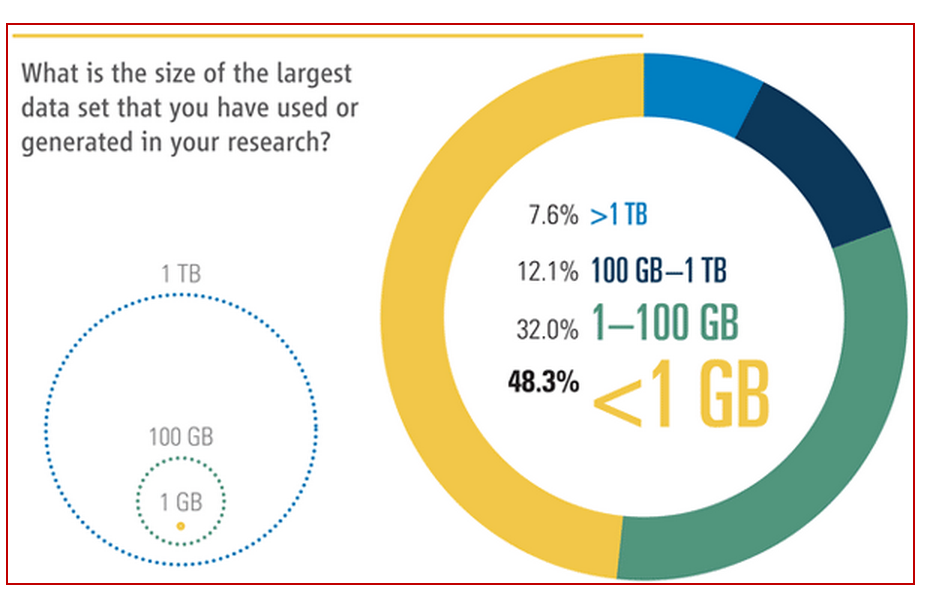
ͼ9 ����Ŀ����У���ʹ�õģ��������������ݼ��Ƕ��ͼƬ��Դ����ѧ�ڿ���
���ڡ�������洢��ʵ���Ҳ��������ݻ�����õ����ݣ����ʾ������У�50.2%���ܷ��ش������Լ���ʵ���ҵ�����洢��38.5%�ܷ��ش����ڴ�ѧ�ķ������ϴ洢���ɴ˿ɼ����ֵ�������Ȼ�������ݹµ�״̬����������ͨ�Եĵ�·�ǣ���Ȼ��·��������Զ�⡱�������ݵ���ͨ�Ժ����ԣ���ǰ���������Ǵ����ݳɰܵ�ǰ�ᡣ
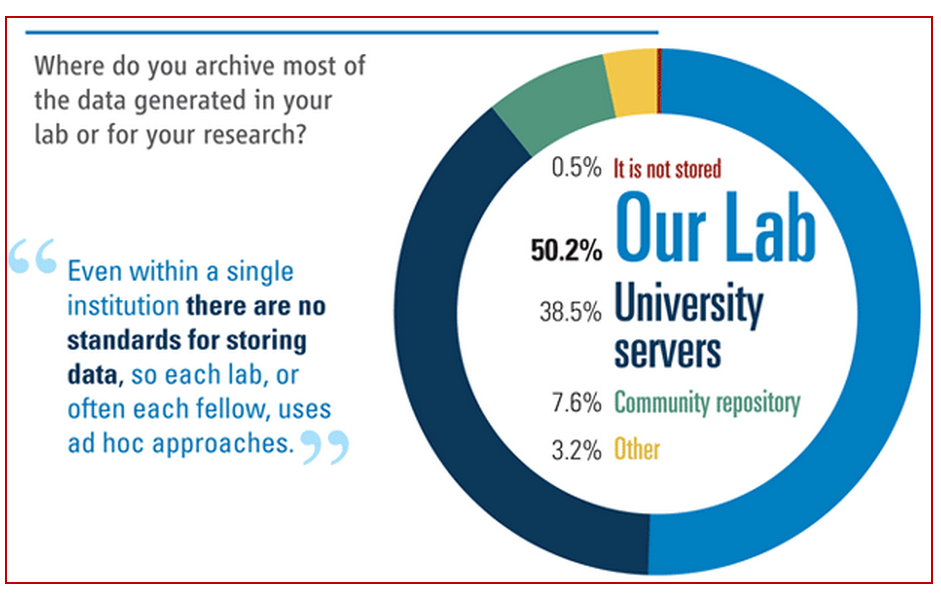
ͼ10 ����Ҫ������洢��ʵ������Ļ�������ݣ���ͼƬ��Դ����ѧ�ڿ���
����Ҳ�ж��߲���ΪȻ��˵�Ҿ��������Dz���С��7.6%���ˣ���ʹ�û���������ݴ���1TB��������С�ڣ����Ժ��������������������ˣ�������������Ļ�������˾����Google��Yahoo������Facebook�ȣ����ڹ��ڵ���Ȼ��BATĪ���ˡ���ʵ�ϣ���ʹ���������˾���ճ�ҵ�������ݼ�Ҳ������ô��ġ���Ŀ���ġ���
���о�Ժ�����о�ԱAntony Rowstron������ָ��[19]����������Yahoo��ͳ�ƣ�����Hadoop����ҵ��һ��ȡ���м�ֵ�����������ݼ��Ĵ�СҲ������14GB����ʹ���ڴ����ݴ�Facebook����90%����ҵ�������ݼ���Ҳ��С��100GB�ģ�clusters (at Microsoft and Yahoo) have median job input sizes under 14 GB, and 90% of jobs on a Facebook cluster have input sizes under 100 GB������Щ������ij����������ͷ����������ܺͣ��������ơ���ҵĴ����ݲ������ǣ���Ӧ�ý����������ǡ�һ˫���ۡ��������ǡ�������ſ���������������װ��������С���
��Ȼ��Antony Rowstron����ƪ���ġ��ⲻ�ڴˡ������е���Ҫ�����ǣ���Ȼ�����ճ�����������û����ô��������ͳ������û�б�Ҫ��ij̨����������ָ��һζ��������չ��scale up����������ڴ��8G����Ϊ16GB��32GB��64GB���������ߣ�����Ӧ��ѡ����ӡ�����ʵ�ݡ��ĺ�����չ��Scale-out�����ԣ����罫���ɸ�8GB�����õĻ���������һ�����һ�����۵ļ�Ⱥ��cluster����Ȼ������Hadoop����Ⱥ��������������ƪ���ĵı����ǡ�û���˻����ڼ�Ⱥ��ʹ��Hadoop������ͣ�Nobody ever got fired for using Hadoop on a cluster����������֮�⣬��Ŀǰ�������ᄈ�£�ʹ�á���Hadoop��Hadoop-like�������߷���������������������֮һ����ҵ�г�һƬ������
������ķ������Կ��������Dz����ϣ���������ǰ�أ������Ǹ����ܶ�Ŀǰ����״�����á���С������Ȼ��������Ŀǰ�������˾����ҵ��ʵ�Դ��ڡ�С���ݡ������Ρ���ֻҪ����������һ����ʱ����ۣ��ں������нϷḻ�ļ�¼ϸ�ڣ�ͨ�����Դͷ��ͬһ������ɼ��ĸ��������л����ϣ�ʵʩ���������ݷ������Ϳ��ܲ������ֵ�����ڴˣ������Ժʿָ�����ڴ�����ʱ���������Dz���������С���ݡ���[9]��
�Ծ�ȷ���������Ǵ�ͳ��С���ݷ�����ǿ�����һ���̶����ֲ������ݵġ������ԡ�ȱ�ݡ������о��ʳ�������������ʶ�����ѣ����������ѡ����ڴ�����ʱ��������Ҳ��������С���ݡ��������д����ݵ�������С������С���ݵ������������Ǿ�����������⡣
4.�������ã��������졪��С����֮��
С���ݣ���ʵ�Ǵ����ݵ�һ����Ȥ���棬�����ڶ�ά�ȵ�һά����ʱ��������Ҫ�����ݵ�ȫά�ȿ��ӣ����ν��������ѡ�ȫϢ�ɼ�����Ϊ�����ݵ�����������������ڶ��û����֡�����ʱ���dz����ã���Ϊ���������dz��������̼��ƹ㡰��Ӫ������
����������ٴ�ǿ������˹�������յ���ѧ�ۡ������ݵı������ˡ�����Ҳ��Ϊ�˷���ġ����� �������ڡ����ԣ���ʱ�����Dz���ϣ���Լ������ֻ�����ȫϢ����������漰��������˽�����ˡ���������ݼ����ַ����˵���˽�������ڲ������ˣ������������Ӧ���������ƺ淶�����ⲻ�ڱ��ĵ����۷�Χ���Ͳ�չ��˵�ˡ�
���еġ������ݡ������ǣ�����ͨ��Ŀǰ�������������ں���ʱ���ڲɼ����洢�����������ݼ��������Ǻ������������֮���������С���ݣ�small data������ ��ͨ��Ŀǰ�����������߿����ں���ʱ���ڲɼ����洢�����������ݼ���������Ǵ�ͳ�����ϵ�С���ݣ����������ͳ�ƺ������ھ�֪ʶ�����ԽϺõؽ���������⡣��������С���ݣ�����������̸�����Ա��IJ�̸��
�����������۵�С���ݣ���һ�����˵����ݣ�����Χ�Ƹ���Ϊ����ȫ��λ�����ݣ�������ÿ����������ֻ���Ϣ����ˣ�Ҳ���˳�֮Ϊ��iData��������С���ݸ������ݵĸ����������ڣ�С������Ҫ�Ե�����Ϊ�о������ص�������ȣ��Ը�����������ľ�ȷ���ھԱȶ��ԣ��������������ij�������棬�ڴ�Χ�����ģȫ�������ռ����������� �������ڹ�ȡ�
С�����Ǵ����ݵ�ij�����棬��ʵ�ϣ��ܶ�ʱ���ڸ��˶��ԣ������ν�IJ�����п������ض����˵�ȫ�档����������������Ŀʱ�����¼������������ֻ��������ֻ������������ȣ�Ҳ��С���ݡ������˵�����������Quantified Self��QS���� ���泯����ů��������
�������������Բ��������١����������ճ������е��εΡ����磬���������������˶��ٿ�·�Χ�Ųٳ���һȦ�������˶������������ֻ���ij��App(����)���Һķ��˶���ʱ�䣿�ȵ�������ࡣ��ij�̶ֳ��ϣ���С���ݣ����Ǵ����ݣ�������������İ��֡���С���ݡ����ȴ�����������嫷��ӣ�ȴ�����Լ�������Ҫ����������������С������˵��С���ݵ�Ӧ�á�
��˵һ�����ߴ��ϵİ������ݿƼ�����Emily Waltz��IEEE Spectrum����ָ��[20]��Ŀǰ������˶�Ա��������С�����Biometric gadget��ͨ��ָ�������������ڸı����羫Ӣ���˶�Ա��ѵ����ʽ����Щ�ɴ����������豸���ṩʵʱ������������������ǰ������Ҫ��ȡ���������ݣ���Ҫ���غͰ����ʵ�����豸����ͬ40��ǰ������һʱ�ĸ���ѵ�������������˶�Ա�������ԣ��ɴ���װ���ܰ����˶�Ա��߳ɼ���ͬʱ�������ˡ�һЩ�����֡����г��˶�Ա�������Ⱦ����˶�Ա����װ��Ѱ�����ơ�
ͼ11 �˶�Ա���ÿɴ����豸ѵ����ʽ�����ͼƬ��Դ��IEEE��
���磬����ͼ11��ʾ��װ���У��˶�Ա���ϵĴ������ܹ���ȷ��¼�������ⳡ�ݵ��˶���������Щ���������豸���ɷ������˶�Ա������ѹ�����У����ܹ�����˶�Ա�ļ��١����١�����ı��Լ���Ծ�߶Ⱥ��˶������ָ�ꡣ����Ա�ܹ�ͨ��������ݣ������ÿ���˶�Աѵ��ǿ�ȣ�����ֹ����ѵ�����������˺�����Щ���������豸�Ĺ���ԭ���ǣ�Эͬʹ�úܶ�С�豸������ټơ������ơ������ǡ�GPS�����ǵȡ�����Щ�豸ÿ���ܹ�����100�����ݵ㡣ͨ���������ӣ����������ʵʱ�ɼ���Щ���ݡ��������������������ɶ��˶��������ض�λ��ʵʩ�����������ר��ϵͳ�е��㷨�����Լ��˶�Ա��������ʲô��������ʲô�����ڴˣ��������Ը�������������Ե�ѵ����Ŀǰ�����豸��ʹ���ߣ�����һ�����ϵ�NFL(���������)������֮һ��NBA�˶�Ա��һ�����ϵ�Ӣ������Լ�������ص�����ӡ������Ӻͻ����˶��ӵȡ�
���������豸���ɴ����豸��ͨ���Ǻ���������Internet of things��IoT�����й����ġ������ڻ����ڳ����۷������������ͼ8��ʾ����ͨ���Ǻʹ����ݳ���һ��ģ����Ǿ�ij��������������豸���ԣ���һ�����Dz����������������������ݣ�Ҳ����˵��������������С���ݣ�Ȼ����ܻ㼯�ɴ����ݡ��ֶ���ѧԺ���ڡ�ŦԼʱ����ѳ������������ɡ����ܣ�Jonah Berger���Ʋ�[21]�����˵������������ݣ����������Ǵ����ݸ�������һ���ݽ������ɴ˿ɼ�����С����֮�䲢�����ԵĽ��ޡ��ٴ������Ҳ������һ��һ�ξ�ɳ��������Ҹ���õġ�û��С���ݵĻ��ٳɶࡢ�ٴ��麣��������Ҳ����Դ֮ˮ���ޱ�֮ľ��
����ͬ�й��Ǿ��ϻ�˵�ģ���һ�ݲ�ɨ������ɨ���¡������С���ݶ����ܺܺõش�����������ܺõش������㼯�������Ĵ����ݣ�
˵��ߴ��ϵİ�������������������һ����ƽ�����桱����С����[22]:
���µ��������������ζ���ѧ���ڵ²���������˹͡��Deborah Estrin����Estrin�ĸ�����2012��ȥ���ˣ������ڸ���ȥ��֮ǰ�ļ��������λ�������ѧ���ھ�ע�һЩ����˿�������� ��ȴ�ǰ���������������������social pulse���У�����Щ���仯���������ٲ��ĵ����ʼ���������ɢ���ľ���ҲԽ��Խ�̣�Ҳ��ȥ��������ˡ�
Ȼ����������˥���ļ�������ȥҽԺ���еij������ಡ��cardiologist������У���һ���ܿ������������Dz����������Dz鲡������λ90������˶�û�б��ֳ��ر����Ե��쳣������ʵ�ϣ���������ÿʱÿ�̵ĸ��廯���ݣ���Щ������С����Ҳ�㹻�̻��ó������˵�������ʵ��Ȼ������֮ǰ��ͬ��
�����ճ�����������С���ݣ�����������ѶϢ�ľ�ʾ�Ͷ��죬��������λ�������ѧ���ڣ�Estrin�������ڿ��ζ���ѧ�����ˡ�С����ʵ�飨the small data lab @CornellTech���������ӣ�http://smalldata.io/��������Estrin������С���ݿ��Կ�����һ���µ�ҽѧ֤�ݣ��������ǡ��������������������һ�У�your row of their data����[23] ��
��������������������������ʱ�����У��������ݶ���Ϊȫ���ݣ���n=All��nΪ���ݵĴ�С������ּ���ռ��ͷ�����ij������صġ�ȫ�������ݡ����Ƶģ� Estrin��С���ݶ���Ϊ����small data where n=me��������ʾ��С���ݾ���ȫ���й����ң�me��������[24]��
����һ�������Կ�����С���ݸ��ӡ�����Ϊ������������Ϊ�����ṩ�����о��Ŀ����ԣ��ܲ���ͨ���������ϸ�ĸ�ļ������ݣ�����������ǵĽ�����Ϣ���ܲ���ͨ����Щ�������ݣ��Ƚϲ�ͬ��ҽѧ���Ʒ����������Щ��ʵ�֣����������ã��������족���㲻����һ��ն��ġ�����ǻ��������һϯ��������������������
�ˣ���һ�����ݴ��ڵĸ������˵����������пƼ���չ�Ķ���������Ԥ������Զ�Ľ��������ݸ�����һ������������Ϊ����С���ݵĴ�ʱ������Ȼ���Ⲣ��˵�����ݾͲ���Ҫ��һ����˵���Ӵ����ݵõ����ɣ���С����ȥƥ����ˡ����ɳ�����á�һ����ʦ����̨���������С���ݵ����֣���Ҳ����ǡ������˵��С���ݡ������������˿̻������á�һ����ʦ���С����Լ�������֮���������ݡ�֪��������ӳ��Ȼ��Ⱥ������������ƣ����á�һ����ʦ���е� ������ء�������������֮��
�����Ƽ�ʷѧ�������ġ������Ȳ���(Melvin Kranzberg)����ġ������Ȳ����һ���ɡ�ָ�������������û��������������������ȷʵ��һ�������������������̬����������ã�ʹ�ü�����չ���������⣬ԶԶ�����˼����豸��ֱ��Ŀ�ĺ�ʵ���Լ��Ļ����������ͷų����ļ������������౾�������ĸ��Ӿ������д�̽�������⣬���DZ�Ȼ���ˡ���
ǰ������˵�������ݿ��ܴ������ݰ�ȫ����˽���⣬��ʵ�ϣ�С����ͬ���������Ƶ����⣬������Ϊ�Ͼ�������Ӧ�������������ݡ�С���ݵĿƼ����ȿ���Ϊ����ı������Ҳ���ܶ�������˺����ؼ����ǣ�����ڻ�������ս��Ѱ�ҵ���ѵ�ƽ�⡣
5.��
�����ݵĽ�������в���׳���Ĵ����ݣ�Ҳ��ϸ��������С���ݣ������ศ��ɣ�������ӳ���ԡ��������ӵ�������ʦЭ���ʿ��Fellow�����й���ѧԺ���㼼���о����о�Ա��Ӧ���ʾ[25]��Ŀǰ���������У����Ǿ͡��Աسƴ����ݡ����ⲻ����ѧ�ʵ�̬�ȣ���Ҫ�������������ݣ���������һ��ñ�ӡ������ݡ���Ŀǰ�����и�ҵ���������ݴ����������ǡ�С���ݡ����⡣�����Ǵ����ݻ���С���ݣ�����Ӧ�ó���˼�룬�о�ʵ�����⣬�мɿ�̸������λ����������ҵ�����⣬��Ӧ��Ϊ�������Լ���Ϊ����Ҫ�ĸ������ȣ����ĸ���
��Fierce Big Data���༭Pam Baker����[26]��������Ѱ˼��ξ�������ݣ�����С����ʱ���ȸ������¶���˼��һ�£���Ĺ�˾�Ƿ��ó��������ݴ����ֵ�������Ĺ�˾��û�дﵽ������磬���Ȱ����½������˵��
ǰ���������г������ż��ż��³���С��Ҳ��˵[27]�������ݱ���С�����������ݵ�����ȴ�ִ�С����ν�����ݡ�������ΪȻ��
�ھ��硶ɳ��亡��о侭�䳪�ʣ����ڿ����������д�ʮ����������������ݡ�С�������⡰���������ϵIJˣ����ԡ�ʮ���������������¿�֮ǰ��һ��Ҫ��ȷ�����ĵ�������IJˣ���Ȼ����ԩ��Ǯ����û�гԺã��ǿɾ͡������˶������ˡ���
�����
[1]Kranzberg, Melvin . Technology and History: "Kranzberg's Laws", Technology and Culture, Vol. 27, No. 3, pp. 544�C560. 1986
[2] Eric Lai.The '640K' quote won't go away -- but did Gates really say it?
[3]ά���С��������������, ����˼�����Ү. ʢ���࣬������.������ʱ��[M].�㽭���������.���ݣ�2013
[4] ����.ʲô�Ǵ����ݣ���ѧ������. http://blog.sciencenet.cn/blog-3075-603325.html
[5] Seth Grimes. InformationWeek. Structure, Models and Meaning �� is "unstructured" data merely unmodeled?
[6] �����. �Դ����ݵ�����ʶ[J]. ������, 2015, 1(1): 2015001.
[7] Thomas Crump. The Anthropology of Numbers (Cambridge Studies in Social and Cultural Anthropology) .Cambridge University Press, 1992
[8]���˻�. ����������ʶ��[J]. �й�����ѧ, 2014, (9):34-45. DOI:10.3969/j.issn.1002-9753.2014.09.004.
[9] Bernard Marr.������ר��Bernard Marr������������ζԿ���֢�ģ�CSDN. http://www.csdn.net/article/2015-07-14/2825204/1
[10] Executive Office of the President . Big Data:Seizing Opportunities, Preserving Values, May 2014
[11] Manolis Kellis,��Importance of Access to Large Populations,�� Big Data Privacy Workshop: Advancing the State of the Art in Technology and Practice, Cambridge, MA, March 3, 2014.
[12] Ackoff, Russell (1989). "From Data to Wisdom". Journal of Applied Systems Analysis 16: 3�C9.
[13] Zeleny, M. "From knowledge to wisdom: On being informed and knowledgeable, becoming wise and ethical." International Journal of information technology & decision making 5.04 (2006): 751-762.
[14] �����.���Դ����ݵķ�˼����Ҫ�������10��С����, CSDN. http://www.csdn.net/article/2015-07-28/2825312/1
[15] ���ɳ.��̸�����ݵ�˼���γ����ֵά�ȣ�2014
[16] ���½�.��һ�ƾ��ձ�.�����ݵ����� ΪʲôС���ݸ���Ҫ��
[17] �����ձ�.����ܣ������ݸոչ��˳����ĸ߷���. 2015-3-30
[18] Challenges and Opportunities. Science. 11 February 2011: Vol. 331 no. 6018 pp. 692-93 DOI: 10.1126/science.331.6018.692.
[19]Rowstron A, Narayanan D, Donnelly A, et al. Nobody ever got fired for using Hadoop on a cluster[C]//Proceedings of the 1st International Workshop on Hot Topics in Cloud Data Processing. ACM, 2012: 2.
[20] Emily Waltz. The Quantified Olympian: Wearables for Elite Athletes. http://spectrum.ieee.org/biomedical/devices/the-quantified-olympian-wearables-for-elite-athletes. 28 May 2015.
[21] Jonah Berger. Is Little Data The Next Big Data? https://www.linkedin.com/pulse/20130908184001-5670386-is-little-data-the-next-big-data
[22] Jonah Comstock . Why small data, data donation should be healthcare��s future. http://mobihealthnews.com/21681/why-small-data-data-donation-should-be-healthcares-future/ . Apr 17, 2013
[23]Valerie Barr.The Frontier of Small Data. Communications of the ACM .http://cacm.acm.org/blogs/blog-cacm/168268-the-frontier-of-small-data/fulltext. September 29, 2013
[24] Estrin D. Small data, where n= me[J]. Communications of the ACM, 2014, 57(4): 32-34.
[25] Pam Baker.Small data vs big data: the battle that never was. Fierce Big Data.http://www.fiercebigdata.com/story/small-data-vs-big-data-battle-never-was/2014-06-02
[26] ��Ӧ��.������ʱ������С����.���������걨��. 2014��04��16��http://zqb.cyol.com/html/2014-04/16/nw.D110000zgqnb_20140416_3-11.htm
[27] Ϳ����. ����֮��: �����ݸ���, ��ʷ, ��ʵ��δ��[M]. ���ų�����, 2014.
���߽��ܣ�����꣬��ʿ��2012���ҵ�ڵ��ӿƼ���ѧ����ִ���ں��Ϲ�ҵ��ѧ���й������Э�ᣨCCF����Ա��ACM/IEEE��Ա����Ҫ�о�����Ϊ�����ܼ��㡢������Ϣѧ�������С�Java�����ŵ���ͨ��һ�顣 |






