| TDW��Tencent
distributed Data Warehouse����Ѷ�ֲ�ʽ���ݲֿ⣩���ڿ�Դ����Hadoop��Hive���й����������˴�ͳ���ݲֿⲻ��������չ���ɿ��Բ�ľ��ޣ����Ҹ�����Ѷ���������㸴�ӵ��ض���������˴����Ż����졣
TDW��������Ѷ����ҵ���Ʒ������Ⱥ��ģ�ﵽ4400̨��CPU�ܺ����ﵽ10�����ң��洢�����ﵽ100PB��ÿ����ҵ��100����ÿ�ռ�����4PB����ҵ������2000���ң�ʵ�ʴ洢������80PB���ļ����Ϳ����ﵽ6�ڶࣻ�洢������83%���ң�CPU������85%���ҡ����������ij���Ͷ��ͽ��裬TDW�Ѿ���Ϊ��Ѷ�����������ݴ���ƽ̨��
TDW�Ĺ���ģ����Ҫ������Hive��MapReduce��HDFS��TDBank��Lhotse�ȣ���ͼ1��ʾ��TDW
Core��Ҫ�����洢����HDFS����������MapReduce����ѯ����Hive���ֱ��ṩ�ײ�Ĵ洢�����㡢��ѯ�����Ҹ��ݹ�˾ҵ���Ʒ��Ӧ����������˺ܶ���ȶ��u��TDBank�������ݲɼ���ּ��ͳһ���ݽ�����ڣ��ṩ���������ݽ��뷽ʽ��Lhotse������ȂSͳ���������ݲֿ���ܹܣ��ṩһվʽ��������������
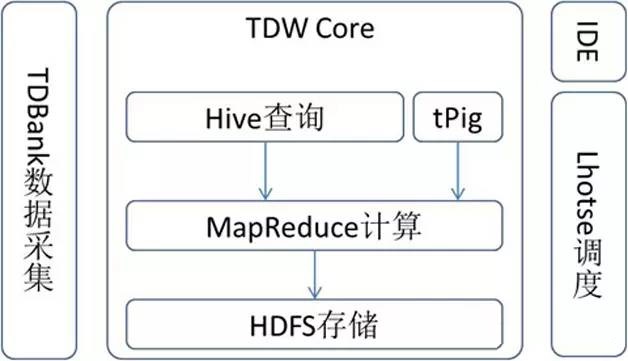
ͼ1 TDW�Ĺ���ģ��
���赥�����ģ��Ⱥ��ܫ��
����ҵ��Ŀ���������TDW�Ľڵ���Ҳ�����ӣ��Ե������ģHadoop��Ⱥ������ҲԽ��Խǿ�ҡ�TDW��Ҫ���������ģ��Ⱥ����Ҫ�Ǵ����ݹ�����������Դ������������Ӫ�����ͳɱ����������I���ǡ�
1. ���ݹ�����TDW֮ǰ�ڶ��IDC������ʮ����Ⱥ����Ҫ�Ǹ���ҵ��ֱ���������һ��ҵ����Ҫ����ҵ������ݣ�������Ҫ��������ʱ������Ҫ�缯Ⱥ���߿�
IDC�������ݣ�������ռ��IDC֮������������Ϊ�˼��ٿ�IDC�����ݴ��䣬��ʱ�Ὣ������������ֲ������IDC�ļ�Ⱥ�������ֻ�����洢�ռ��˷ѡ�
2. ������Դ��������һ����Ⱥ�ļ�����Դ����ijЩܫ���ý���ʱ��������Ҫ���ݲ�¼ʱ�������Ⱥ�ļ�����Դ������⣬��ͬʱ����һ����Ⱥ�ļ�����Դ���ܿ��У���������֮��û��������ͨ���ޡ�
3. ������Ӫ�����ͳɱ���ʮ������Ⱥͬʱ��Ҫ�ȶ���Ӫ�����ҵ�һ����Ⱥ��������ʱ��Ҳ��Ҫ���������Ⱥ�Ѿ����ֵĻ���DZ�ڵ����⡣һ��Hadoop�汾Ҫ��ʮ������Ⱥ��һ�������SͳҲҪ��ʮ������Ⱥ�ϲ�����Щ������Ӫ�����˺ܴ������⣬��ɢ�Ķ��С��Ⱥ����Դ�����ʲ��ߣ������ɱ��ϴ�
���赥�����ģ��Ⱥ�ķ������Ż�
�I�ٵ���ս
TDW�ӵ���Ⱥ400̨��ģ����ɵ���Ⱥ4000̨��ģ���I�ٵ������ս��Hadoop�ܹ��ĵ������⣺�������浥��JobTracker�����أ�ʹ�õ���Ч�ʵ͡���Ⱥ��չ�Բ��ã��洢���浥��NameNodeû�����֣�ʹ��������ʱ������֧�ֻҶȱ�������ж�ʧ���ݵķ��ա�TDW����ƿ������ƽ̨�ĸ߿����ԡ���Ч�ԡ�����չ�������I������Ƿȱ������֧��4000̨��ģ��Ϊ�˽������ƿ����TDW��Ҫ������JobTracker��ɢ����
NameNode�߿��������I��ʵʩ��
JobTracker��ɢ��
1.����JobTracker��ƿ��
TDW��ǰ�ļ��������Ǵ�ͳ������ܹ�������JobTracker����������Ⱥ����Դ������������Ⱥ����������TaskTracker��������ִ�С�JobTracker����������ģ�������һ�𣬶���ȫ����һ��Master�ڵ㸺��ִ�У�����Ⱥ��������������ʱ�����ּܹ������������У�������Ⱥ�����������ﵽ2000���ڵ����ﵽ4000ʱ��������Ⱦͻ����ƿ�����ڵ����������ٻ�����Ⱥ��չҲ������ƿ����
2.JobTracker��ɢ������
TDW���YARN��Facebook��corona��Ʒ����������˼������������ܹ��Ż�����ͼ2��ʾ��������Դ������������Ⱥ����������������ģ����JobTracker�b��������������ܣ�����һ��JobTracker�b����һ��Job�����Ƚ���������Դ��������ģ�������������µij�ΪClusterManager��Master����ִ�У��������Ҳ�������������������Դ��Ϣ��ClusterManager����ִ�У�������Ҫ��ϸߵ��������ģ����ø��Ӿ�ϸ�ĵ��ȷ�ʽ��
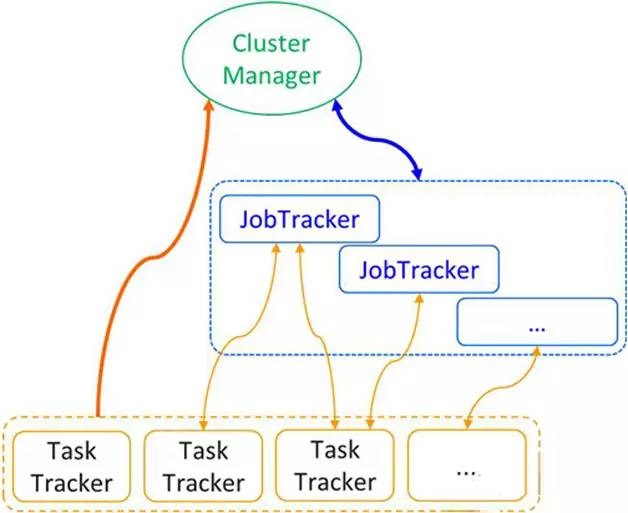
ͼ2 JobTracker��ɢ���ܹ�
�¼ܹ���������ɫ�ֱ��ǣ�ClusterManager����������Ⱥ����Դ������������ȣ�JobTracker����Job�Ĺ�����TaskTracker���������ִ�С�
��1����·������֮ǰ�ļܹ��£�TaskTracker��JobTracker�ϱ�������JobTracker���еش�����Щ���������������н��нڵ���������������������ȵȣ��������أ�Ӱ��������Ⱥͼ�Ⱥ��չ�ԡ��¼ܹ��£���������ֳ���·�������ֱ��ϱ��������Դ��Ϣ��
JobTracker��֪������Ϣͨ�������ϱ������ķ�ʽ�������ϱ�������ͨ���������ڵ�TaskTracker����һ���µĶ����߳����Ӧ��
JobTracker�ϱ���������;������ͬһ��TaskTracker�ϣ���ͬJob������ʹ�ò�ͬ���߳���ͬ��JobTracker�ϱ�������;����ɢ�������������ϱ�Ч�ʡ�
TaskTrackerͨ���ϱ������ķ�ʽ����Դ��Ϣ�㱨��ClusterManager��ClusterManager��TaskTracker
�������л�ȡ�ڵ����Դ��Ϣ��CPU�������ڴ�ռ��С�����̿ռ��С�ȵ���ֵ��ʣ��ֵ��������Щ��Ϣ�жϽڵ��Ƿ���ִ�и��������ͬʱ��ClusterManagerͨ��TaskTracker����֮��ά�S�������������ڵ������������
��ǰ���ص�һ·��������ֳ�����·���������������������40s�Ż���1s����Ⱥ�Ŀ���չ�Եõ���������
��2����Դ���֮ǰ�ܹ��b��slot���һ����ݺ���������slot���������ڴ桢���̿ռ��û�п��u���¼ܹ�������slot�����ǿ����Դ�ĸ��
ÿ����Դ������������������Դ���������������ڴ桢���̺�CPU�ȡ���ClusterManager������Դ�������������Դ���ͣ�Map��
Reduce��JobTracker��ÿ����Դ��Ҫ�ľ�����Դ����ͬ����CPU��Դ�ϣ���������Ȼ����slot����������������Դ��֤���Թ̶�����Դñ��
���磬����24�˵Ľڵ㣬����13���˸�Map�á�6���˸�Reduce�á�1���˸�JobTracker�ã�����Ϊ�ýڵ�����1��
JobTracker slot��13��Map slot��6��Reduce slot��ij��Map�������Դ��Ҫ2���ˣ�����Ϊ��Ҫ����Map
slot����һ���ڵ��Map slot����֮��ʹ��ʣ���CPU��Ҳ�����������Map����ִ���ˡ��ڴ�ռ䡢���̿ռ����Դû��slot���ʣ��ռ��С����������Ϊ���Է��䡣�ڲ���������Դ����Ľڵ�ʱ����ȽϽڵ����Щʣ����Դ�Ƿ����������һ�������ѡ���ص��ڼ�Ⱥƽ��ֵ�Ľڵ㡣
��3����������ʽ�����Ƶ��ȡ�֮ǰ�ܹ��£����������õ��ǻ�������ģ�͵���ȡ���ȣ��������������������Map��Reduce�ĵ��������һ�𣬶��Ҷ��������ȼ���ȡȫ����ʽ��ʱ�临�Ӷ�Ϊnlog(n)���������Ч�ʵ��¡�
�¼ܹ����ö�������ʽ�����Ƶ��ȡ�Map��Reduce��JobTracker������Դ����ʹ�������߳̽��ж������ȣ����������ȼ���ȡ������ķ�ʽ��ʱ�临�Ӷ�Ϊlog(n)��������Դ��������ʱ��ClusterManagerֱ�ӽ���Դ���Ƶ������ߣ������ٱ����صȴ�TaskTrackerͨ�������ķ�ʽ��ȡ�������Դ��
���磬һ��Job��10��Map��ÿ��Map��Ҫ1���ˡ�2GB�ڴ�ռ䡢10GB���̿ռ䣬������㹻����Դ��Map�����̲߳��ҵ���������10
��Map�Ľڵ��б���ClusterManager��ѽڵ��б����Ƶ�JobTracker�����Map�����̵߳�һ���b���ҵ�������5��Map�Ľڵ��б���ClusterManager�������б����Ƶ�JobTracker�����Map�����̲߳��ҵ���ʣ��5��Map�Ľڵ��б���ClusterManager�ٰ�����б����Ƶ�JobTracker��
��ǰ��������ģ�͵���ȡ���ȱ��Ż��ɶ�������ʽ�����Ƶ���֮��ƽ�����ȴ���ʱ����80ms�Ż���1ms����Ⱥ�ĵ���Ч�ʵõ���������
3. Job�ύ����
�¼ܹ��£�һ��Job�ύ���̣���ҪClient��ClusterManager��TaskTracker�����н�������ͼ3��ʾ����JobClient����ClusterManager��������JobTracker����Ҫ����Դ�����뵽֮��JobClient��ָ����
TaskTracker������JobTracker���̣���Job�ύ��JobTracker��JobTracker����ClusterManager����Map��Reduce��Դ�����뵽֮��JobTracker���������������ύ��ָ����TaskTracker��
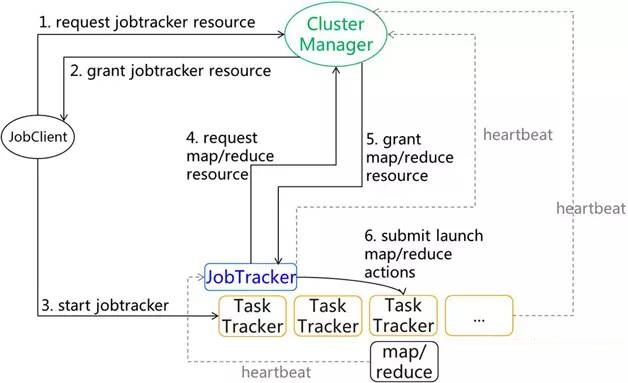
ͼ3 Job�ύ����
4. ���ڵ����⼰Ӧ�Դ�ʩ
JobTracker��ɢ���������������������Ч�Ժ���չ�ԣ���û�д����߿����ԣ���һ���ϵ�������ڴ˷�������Ȼ���ڣ���ʱ�ĵ�һ���ϵ������б�����ǰ������������
��1��ClusterManager����������ϣ��������Job״̬��ʧ�����ڶ�ʱ���ڼ��ɻָ������b�洢��Դ��������洢״̬��ClusterManager�ں̵ܶ�ʱ���ڿ���������ɡ�����֮��TaskTracker������ClusterManager�㱨��Դ��ClusterManager����������ȫ��ü�Ⱥ����Դ��������ο�����10������ɡ�
��2��JobTracker����������ϣ��b��Ӱ�쵥��Job��������Job�������Ӱ�졣
�����������㣬��Ϊ�·����ĵ�һ���ϵ�����Ӱ�첻���ҿ��Ƿ���ʵʩ�ĸ��ӶȺ�ʱЧ�ԣ�TDW��JobTracker��ɢ��������û����Ƹ߿��÷���������ͨ����Χ�Sͳ������Ӱ�죺��Sͳ��֤ClusterManager���ϼ�ʱ���ֺͻָ���Lhotse���ȂSͳ���û�����֤Job���ԡ�
NameNode�߿���
1. ����NameNode������
TDW��ǰ�Ĵ洢�����ǵ���NameNode����һ��ҵ���Ӧһ����Ⱥ������£�NameNodeѹ����С�������ϵļ���Ҳ��С������
NameNode������ϴ�����Ӱ�첻�Შ��ȫ��ҵ�����Ѹ���С��Ⱥͳһ����Ⱥ������ҵ�洢֮��ʱ��NameNodeѹ��������ϵļ���Ҳ���NameNode���������ɵ�Ӱ�콫��dz����ء���ʹ�Ǽƻ��ڱ����ֹͣNameNode�����ʱ����2��Сʱ���ƻ��ڵ�ֹͣ������Ҳ���û������˽ϴ��Ӱ�졣
2. NameNode�߿��÷���
TDW�����һ��һ�����ȱ���NameNode�߿��÷������¼ܹ���NameNode��ɫ��������һ����ActiveNameNode�����ȱ���BackupNameNode����ActiveNameNode����namespace��block��Ϣ����DataNode�·�������ҶԿͻ����ṩ����BackupNameNode����standby��newbie����״̬��standby�ṩ��ActiveNameNodeԪ���ݵ��ȱ�����
ActiveNameNodeʧЧ�����������ṩ����newbie״̬��������ѧϰ�Σ�ѧϰ���֮���Ϊstandby��
��1��ReplicatonЭ�顣Ϊ��ʵ��BackupNameNode��ActiveNameNode��Ԫ����һ�£���ʱ�ʱ��ӹ�
ActiveNameNode��ɫ��Ԫ���ݲ������I��Ҫ��������ͬ�����ͻ��˶�Ԫ���ݵ��IJ�ֹ��ActiveNameNode��¼�������I���������I����Ҫ��ActiveNameNodeͬ����BackupNameNode���ͻ��˵�ÿһ��д�������b�гɹ�д��ActiveNameNode�Լ�����һ��
BackupNameNode������ZooKeeper��ʱ���ŷ��ؿͻ��˲����ɹ�����û��BackupNameNode��д��ʱ�����������Iͬ����
ZooKeeper����֤������һ���������I���ݡ�
�ͻ���д������¼�������I��ѭ���¼���ܫ��
��д��ActiveNameNode�����д��ʧ�ܣ����ز���ʧ�ܣ�ActiveNameNode�Զ��ճ���
�ڵ�д�����������ڵ㣨Active-NameNode��Standby/ZooKeeper/LOG_SYNC
newbie��ʱ���ز����ɹ�����������ʧ�ܣ�LOG_SYNC newbie��ʾnewbie�Ѿ���ActiveNameNode��ȡ��ȫ�����I���״̬��
�۵��b�ɹ�д��ActiveNameNode���˺��Standby��ZooKeeper��д��ʧ��ʱ������ʧ�ܣ�
�ܵ��b����ActiveNameNodeʱ�������b��״̬��
��2��LearningЭ�顣newbieѧϰ���uȷ��newbie������ͨ����ActiveNameNodeѧϰ��ȡ���µ�Ԫ������Ϣ��ѧϰ����
ActiveNameNodeͬ��ʱ���standby״̬��newbie��ActiveNameNode��ȡ���µ�fsimage��edits�ļ��б���ActiveNameNode�����newbie֮�佨���������I����ͨ�����������������Iͬ����newbie��newbie����Щ��Ϣ�����ڴ棬�������µ�Ԫ����״̬��
��3���������I��š�Ϊ����֤�������I�Ƿ�ʧ�����ظ���Ϊ�������Iָ�����������ļ�¼��txid�����������I�ļ�edits�м���txid����֤
txid�������ԣ����I����ͼ���ʱ��֤txid���������������ڴ��е�Ԫ������Ϣ��fsimage�ļ�ʱ������ǰtxidд��fsimageͷ��������
fsimage�ļ����ڴ���ʱ������Ԫ���ݵ�ǰtxidΪfsimageͷ����txid����ȫ���I��ţ�safe
txid��������ZooKeeper�ϣ�ActiveNameNode�����Եؽ�txidд��ZooKeeper��Ϊsafe
txid����BackupNameNodeת��ΪActiveNameNodeʱ����Ҫ���BackupNameNode��ǰ��txid�Ƿ�С��safe
txid����С�����ֹ��ν�ɫת����
��4��checkpointЭ�顣�¼ܹ���Ȼ����checkpoint���ܣ��Լ������I�Ĵ�С����������ʱ����Ԫ����״̬�ĺ�ʱ����
ActiveNameNodeά��һ��checkpoint�̣߳������Ե�֪ͨ����standby��checkpoint��ָ�����е�һ����������
fsimage�ļ��ϴ���ActiveNameNode��
��5��DataNode˫����Block�������ڵĽڵ��б���NameNodeԪ������Ϣ��һ���֣�Ϊ�˱�֤�ⲿ����Ϣ��������һ���ԣ�DataNode����˫�����u��DataNode�Կ�ĸĶ���ͬʱ�㲥���������������·������DataNode����Դ����bִ�������·�����������Ե������·������
��6������ZooKeeper����Ҫ���������ڵ�ѡ�ٺͼ�¼������I��NameNode�ڵ�״̬����ȫ���I��š���Ҫʱ��¼edit
log��
3. ���������
�����ճ�ʱ����״̬�л��Ĺ��̣���ͼ4��ʾ������ActiveNameNode�ڵ�IP1����ijЩܫ���ճ�ʱ���������ڵ�IP2��IP3ͨ����
ZooKeeper�����������ڵ��ɫ��IP2��������ΪActiveNameNode���ͻ��˴�ZooKeeper�����»�ȡ���ڵ���Ϣ����IP2���н�������ʱ��ʹIP1����ָ���Ҳ��newbie״̬���������I��������ͬ����newbie
IP1ͨ�������ڵ�IP2ѧϰ��Ϊstandby״̬��
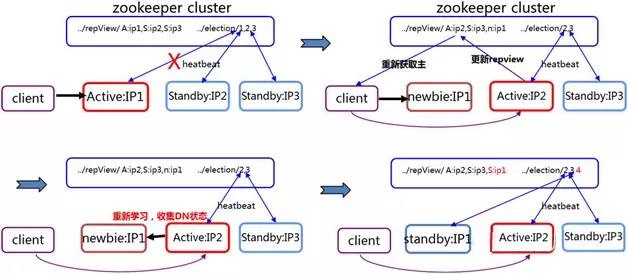
ͼ4 ���ճ�ʱ����״̬�л�
4. ���ڵ�����
NameNode�߿��÷������洢��������˸߿����ԣ����ڸ�Ч�Է��I������һЩ�����������������I��Ҫͬ����д������20%���ҵ��½���
�����Ż�
TDW��ʵʩ��Ⱥ�����У�������ҪʵʩJobTracker��ɢ����NameNode�߿���������������������һЩ�����Ż���
1. NameNode��ɢ��
���Ŵ洢����ҵ��IJ���������һ��HDFSԪ���ݿռ�ķ���ѹ�����վ�����ͨ��NameNode��ɢ��������һ��Ԫ���ݿռ�ķ���ѹ����
NameNode��ɢ����Ҫ��Ԫ������Ϣ���зֲ𣬶��û������û�������Ϊ����ͬһ���洢���棬�ײ���Բ�ֳɶ����Ⱥ��TDW��Hive�������û���
HDFS��Ⱥ��·�ɱ����û��������ݽ�д���Ӧ��HDFS��Ⱥ�����������û��b��ʹ�ñ�ʵĽ�����伴�ɡ�TDW���ݹ�˾ҵ���ʵ��Ӧ�ó���������ҵ���ߺ������ݵȰ����ݷ�ɢ������HDFS��Ⱥ�����������ݹ���ͬʱҲ������ܼ�Ⱥ������ݿ��������ü��Ķ����ٵķ��������ʵ�ʵ����⡣
2. HDFS����
TDW�ڲ�������HDFS�汾��0.20.1��CDH3u3��2.0�����������汾��CDH3u3������HDFS�汾ʹ�õ�RPC�����δ�Ż���Thrift����Protocol
Buffers�ȣ������汾�������ݣ������˻�����ʵ����ѡ�ͨ��RPC����ݷ�ʽʵ����CDH3u3��0.20.1֮��Ļ�ͨ��ͨ����ȫʵ�����ӿڷ�ʽʵ����CDH3u3��2.0֮��Ļ�ͨ��
3. ��ֹ������ɾ��
��Ҫ���ݵ���ɾ�����TDW�������ɹ�����Ӱ�죬TDWΪ�˽�һ���������ݴ洢�ɿ��ԣ���������NameNode����վ���ԣ��������������ԣ�
ɾ���ڰ�������ɾ���ӿ��ij��������ӿڣ��������е�Ŀ¼���Ա�ɾ�����������е�IP���Խ���ɾ�������������ɣ�DataNode����վ����ɾ�����������������д����ļ���ɾ��������ά���ڴ�ɾ�����������֮��Ž���ʵ�ʵ�ɾ���������������Ա�֤��һ��ʱ�������������Ҫ�����ݱ���ɾ��ʱ���Խ������ݻָ��������Է�ֹNameNode����֮��Ԫ��������ȱʧ���������ֱ�ӱ�ɾ���ķ��ա�
����
TDW��ʵ�������������ȡ��һ�S�е��Ż���ʩ���ɹ�ʵʩ�˵������ģ��Ⱥ�Ľ��衣Ϊ�������û����������ļ�������TDW���ڽ��и����ģ��Ⱥ�Ľ��裬����ʵʱ������Լ������չ��TDW�ʱ�����YARN��Ϊͳһ����Դ����ƽ̨���ڴ˻����Ϲ���������ģ�ͺ�Storm��Spark��Impala
�ȸ���ʵʱ����ģ�ͣ�Ϊ�û��ṩ���ӷḻ�ķ���
|






