|
摘要:随着各种技术发展,很多人都在吹捧大数据。然而如同股市一样,越是高涨,越是需要警醒,在大数据热火朝天前行的路上,多一点反思,多一份冷静,或许能让这路走的更好、更远。本文的10个小故事,或许能让你有所得。
自2011年以来,大数据旋风以“迅雷不及掩耳之势”席卷中国。毋庸置疑,大数据已然成为继云计算、物联网之后新一轮的技术变革热潮,不仅是信息领域,经济、政治、社会等诸多领域都“磨刀霍霍”向大数据,准备在其中逐得一席之地。
中国工程院李国杰院士更是把大数据提升到战略的高度,他表示【1】,数据是与物质、能源一样重要的战略资源。从数据中发现价值的技术正是最有活力的软技术,在数据技术与产业上的落后,将使我们像错过工业革命机会一样延误一个时代。
在这样的认知下,“大数据”日趋变成大家“耳熟能详”的热词。图1所示的是谷歌趋势(Google Trends)显示的有关大数据热度的趋势,从图1中可以看到,在未来的数年里,“大数据”的热度可能还是“高烧不退”(图1中虚线为未来趋势)。
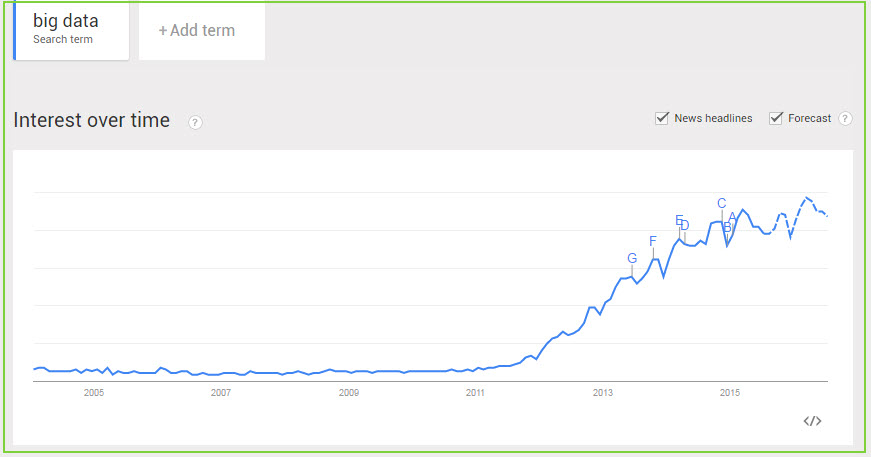
图1 大数据趋势(图片来源:作者截图)
在大数据热火朝天前行的路上,多一点反思,多一份冷静,或许能让这路走的更好、更远?例如,2014年4月,大名鼎鼎的《纽约时报》发表题为《大数据带来的八个(不,是九个!)问题》(Eight (No, Nine!) Problems With Big Data)”的反思文章【2】,其中文中的第九个问题,就是所谓的“大数据的炒作(we almost forgot one last problem: the hype)”。同样为重量级的英国报刊《财经时报》(Financial Times,FT)也刊发了类似反思式的文章“大数据:我们正在犯大错误吗?(Big data: are we making a big mistake?)”【3】
在大数据热炒之中,大数据的价值是否被夸大了?是否存在人造的“心灵鸡汤”?大数据技术便利带来的“收之桑榆”,是否也存在自己的副作用――“失之东隅”――个人的隐私何以得到保障?大数据热炒的“繁华过尽”,数据背后的巨大价值是否还能“温润依旧”?在众声喧哗之中,我们需要冷静审慎地思考上述问题。
太多的“唐僧式”的说教,会让很多人感到无趣。下文分享了10个从“天南地北”收集而来的小故事(或称段子),从这些小故事中,可对热炒的大数据反思一下,这或许能让读者更加客观地看待大数据。有些小故事与结论之间的对应关系,或许不是那么妥帖,诸位别太较真,读一读、乐一乐、想一想就好!
故事01:大数据都是骗人的啊――大数据预测得准吗?
从前,有一头不在风口长大的猪。自打出生以来,就在猪圈这个世外桃源里美满地生活着。每天都有人时不时地扔进来一些好吃的东西,小猪觉得日子惬意极了!高兴任性时,可在猪圈泥堆里打滚耍泼。忧伤时,可趴在猪圈的护栏上,看夕阳西下,春去秋来,岁月不争。“猪”生如此,夫复何求?
根据过往数百天的大数据分析,小猪预测,未来的日子会一直这样“波澜不惊”地过下去,直到它从小猪长成肥猪……在春节前的一个下午,一次血腥的杀戮改变了猪的信念:尼玛大数据都是骗人的啊……惨叫嘎然而止。

图2 大数据预测:都是骗人的
这则“人造寓言”是由《MacTalk・人生元编程》一书作者池建强先生“杜撰”而成的【4】。池先生估计是想用这个搞笑的小寓言“黑”一把大数据。
我们知道,针对大数据分析,无非有两个方面的作用:(1)面向过去,发现潜藏在数据表面之下的历史规律或模式,称之为描述性分析(Descriptive Analysis);(2)面向未来,对未来趋势进行预测,称之为预测性分析(Predictive Analysis)。把大数据分析的范围从“已知”拓展 到了“未知”,从“过去” 走向 “将来”,这是大数据真正的生命力 和“灵魂” 所在。
那头“悲催”的猪,之所以发出“大数据都是骗人的啊”呐喊,是因为它的得出了一个错误的“历史规律”:根据以往的数据预测未来,它每天都会过着“饭来张口”的猪一般的生活。但是没想到,会发生“黑天鹅事件”――春节的杀猪事件。
黑天鹅事件(Black Swan Event) 通常是指,难以预测的但影响甚大的事件,一旦发生,便会引起整个局面连锁负面反应甚至颠覆。读者可阅读纳西姆・尼古拉斯・塔勒布(Nassim Nicholas Taleb)所著的畅销书《黑天鹅》,来获得对“黑天鹅事件”更多的理解。
其实,我们不妨从另外一个角度来分析一下,这个搞笑的小寓言在“黑”大数据时,也有失败的地方。通过阅读知道,舍恩伯格教授在其著作《大数据时代》的第一个核心观点就是:大数据即全数据(即n=All,这里n为数据的大小),其旨在收集和分析与某事物相关的“全部”数据,而非仅分析“部分”数据。
那头小猪,仅仅着眼于分析它“从小到肥”成长数据――局部小数据,而忽略了“从肥到没”的历史数据。数据不全,结论自然会偏,预测就会不准。
要不怎么会有这样的规律总结呢:“人怕出名,猪怕壮”。猪肥了,很容易先被抓来杀掉。这样的“猪”血泪史,天天都上演的还少吗?上面的小寓言,其实是告诉我们:数据不全,不仅坑爹,还坑命啊!
那么,问题来了,大数据等于全数据(即n=All),能轻易做到吗?
故事02:颠簸的街道――对不起,“n=All”只是一个幻觉
波士顿市政府推荐自己的市民,使用一款智能手机应用――“颠簸的街道(Street Bump,网站访问链接:http://www.streetbump.org/)”。这个应用程序,可利用智能手机中内置的加速度传感器,来检查出街道上的坑洼之处――在路面平稳的地方,传感器加速度值小,而在坑坑洼洼的地方,传感器加速度值就大。热心的波士顿市民们,只要下载并使用这个应用程序后,开着车、带着手机,他们就是一名义务的、兼职的市政工人,这样就可以轻易做到“全民皆市政”。市政厅全职的工作人员就无需亲自巡查道路,而是打开电脑,就能一目了然的看到哪些道路损坏严重,哪里需要维修,如图3所示。
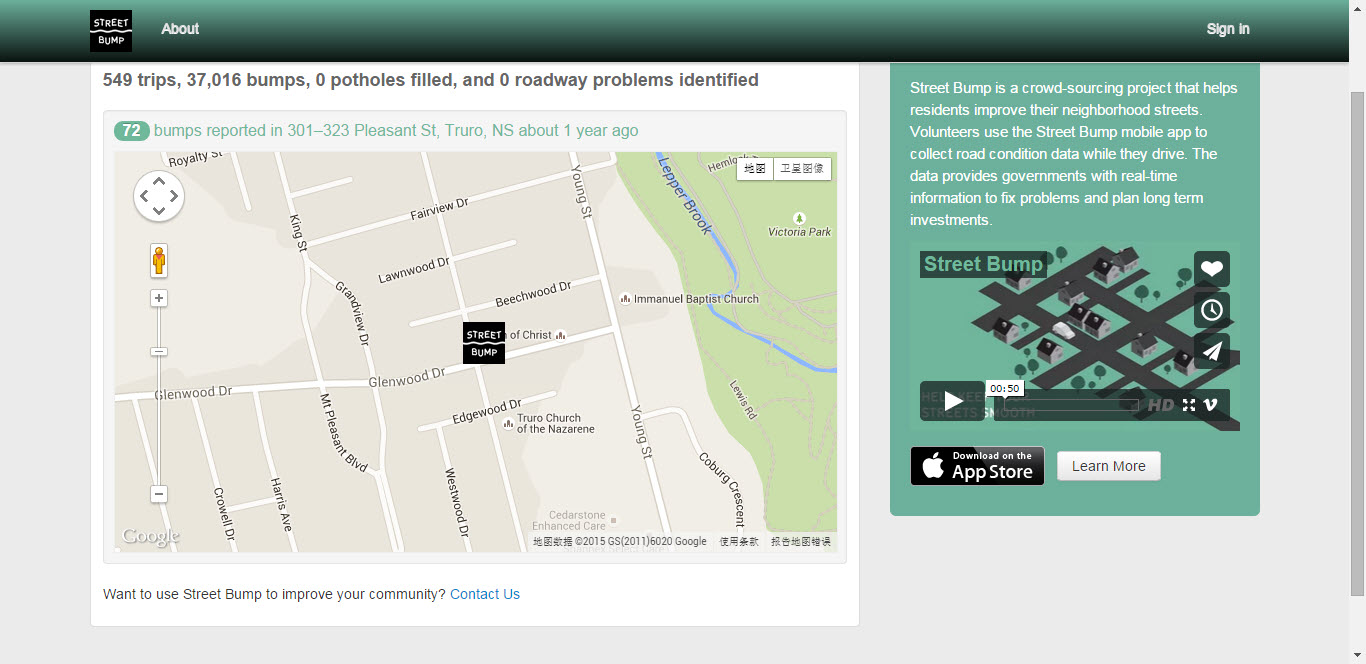
图3 颠簸的街道 (图片来源:作者截图)
波士顿市政府也因此骄傲地宣布,“大数据,为这座城市提供了实时的信息,它帮助我们解决问题,并提供了长期的投资计划”。著名期刊《连线》(Wired)也毫不吝啬它的溢美之词【5】:这是众包(Crowdsourcing)改善政府功能的典范之作。
众包是《连线》杂志记者Jeff Howe于2006年发明的一个专业术语,用来描述一种新的商业模式。它以自由自愿的形式外包给非特定的大众网络的做法。众包利用众多志愿员工的创意和能力――这些志愿员工具备完成任务的技能,愿意利用业余时间工作,满足于对其服务收取小额报酬,或者暂时并无报酬,仅仅满足于未来获得更多报酬的前景。
然而,从一开始,“颠簸的街道”的产品设计就是有偏的(bias),因为使用这款App的对象,“不经意间”要满足3个条件:(1)年龄结构趋近年轻,因为中老年人爱玩智能手机的相对较少;(2)使用App的人,还得有一部车。虽然有辆车在美国不算事,但毕竟不是每个人都有;(3)有钱,还得有闲。前面两个条件这还不够,使用者还得有“闲心”, 想着开车时打开“颠簸的街道”这个App。想象一下,很多年轻人的智能手机安装的应用程序数量可能两位数以上,除了较为常用的社交软件如Facebook或Twitter(中国用户用得较多的是微博、微信等)记得开机运行外,还有什么公益软件“重要地”一开车就记得打开?
“颠簸的街道”的理念在于,它可以提供 “n=All(所有)”个坑洼地点信息, 但这里的“n=All(所有)”也仅仅是满足上述3个条件的用户记录数据,而非“所有坑洼点”的数据,上述3个条件,每个条件其实都过滤了一批样本,“n=All”注定是不成立的。在一些贫民窟,可能因为使用手机的、开车的、有闲心的App用户偏少,即使有些路面有较多坑洼点,也未必能检测出来。
《大数据时代》的作者舍恩伯格教授常用“n=All”,来定义大数据集合。如果真能这样,那么就无需采样了,也不再有采样偏差的问题,因为采样已经包含了所有数据。
畅销书《你的数字感:走出大数据分析与解读的误区》(Numbersense: How to Use Big Data to Your Advantage)的作者、美国纽约大学统计学教授Kaiser Fung,就毫不客气地提醒人们,不要简单地假定自己掌握了所有有关的数据: “N=All(所有)”常常仅仅是对数据的一种假设,而不是现实。
微软-纽约首席研究员Kate Crawford也指出,现实数据是含有系统偏差的,通常需要人们仔细考量,才有可能找到并纠正这些系统偏差。大数据,看起来包罗万象,但“n=All”往往不过是一个颇有诱惑力的假象而已。
“n=All”,梦想很丰满,但现实很骨感!
但即使具备全数据,就能轻易找到隐藏于数据背后的有价值信息吗?请接着看下面的故事。
故事03:醉汉路灯下找钥匙――大数据的研究方法可笑吗?
一天晚上,一个醉汉在路灯下不停地转来转去,警察就问他在找什么。醉汉说,我的钥匙丢了。于是,警察帮他一起找,结果路灯周围找了几遍都没找到。于是警察就问,你确信你的钥匙是丢到这儿吗?醉汉说,不确信啊,我压根就不知道我的钥匙丢到哪儿。警察怒从心中来,问,那你到这里来找什么?醉汉振振有辞:因为只有这里有光线啊!

图4 醉汉路灯下找钥匙(图片来源:经济学人)
这个故事很简单,看完这个故事,有人可能会感叹醉汉的“幼稚”、“可笑”。但不好笑的是,“乌鸦笑猪黑,自己不觉得”,这个故事也揭示了一个事实:在面临复杂问题时,我们的思维方式也常同这个醉汉所差无几,同样也是先在自己熟悉的范围和领域内寻找答案,哪怕这个答案和自己的领域“相隔万里”!
还有人甚至认为,醉汉找钥匙的行为,恰恰就是科学研究所遵循的哲学观。前人的研究成果,恰是是后人研究的基石,也即这则故事中的“路灯”。到路灯下找钥匙,虽看来有些荒唐,但也是“无奈之下”的明智之举。
数据那么大,价值密度那么低,你也可以去分析,但从何分析起?首先想到的方法和工具,难道不是当下你最熟悉的?而你最熟悉的,就能确保它就是最好的吗?
沃顿商学院著名教授、纽约时报最佳畅销书作者乔纳?伯杰(Jonah Berger)从另外一个角度,解读这个故事【6】:在这里,浩瀚的黑夜就是如同全数据,“钥匙”就好比是大数据分析中我们要找到的价值目标,他认为,“路灯”就好比我们要达到这个目标的测量“标尺”,如果这个标尺的导向有问题,顺着这个标尺导引,想要找到心仪的“钥匙”,是非常困难的!在我们痴迷于某项自己熟悉的特定测量标尺之前,一定要提前审视一下,这个测量标尺是否适合帮助我们找到那把“钥匙”,如果不能,赶快换一盏“街灯”吧!
如果在黑暗中丢失的钥匙,是大数据中的价值,那这个价值也太稀疏了吧。下面的故事,让我们聊聊大数据的价值。
故事04:园中有金不在金――大数据的价值
人们在描述大数据时,通常表明其具备4个V特征,即4个以V为首字母的英文描述:Volume(体量大)、Variety(模态多)、Velocity(速度快)及Value(价值大)。前三个V,本质上,是为第四个V服务的。试想一下,如果大数据里没有我们希望得到的价值,我们为何还辛辛苦苦这么折腾前3个V?
英特尔中国研究院院长吴甘沙先生说,“鉴于大数据信息密度低,大数据是贫矿,投入产出比不见得好。”《纽约时报》著名科技记者Steve Lohr,在其采访报道“大数据时代(The Age of Big Data)”中表明【7】,大数据价值挖掘的风险还在于,会有很多的“误报”发现,用斯坦福大学统计学教授Trevor Hastie的话来说,就是“在数据的大干草垛中,发现有意义的“针”,其困难在于“很多干草看起来也像针(The trouble with seeking a meaningful needle in massive haystacks of data is that “many bits of straw look like needles)”
针对大数据的价值,李国杰院士借助中国传统的寓言故事《园中有金》,从另外一个角度,说明大数据的价值,寓言故事是这样的【8】:
有父子二人,居山村,营果园。父病后,子不勤耕作,园渐荒芜。一日,父病危,谓子曰:园中有金。子翻地寻金,无所得,甚怅然。是年秋,园中葡萄、苹果之属皆大丰收。子始悟父言之理。
人们总是期望,能从大数据中挖掘出意想不到的“大价值”。可李国杰院士认为【8】,实际上,大数据的价值,主要体现在它的驱动效应上,大数据对经济的贡献,并不完全反映在大数据公司的直接收入上,应考虑对其他行业效率和质量提高的贡献。
大数据是典型的通用技术,理解通用技术的价值,要懂得采用“蜜蜂模型”:蜜蜂的最大效益,并非是自己酿造的蜂蜜,而是蜜蜂传粉对农林业的贡献――你能说秋天的累累硕果,没有蜜蜂的一份功劳?
回到前文的小故事,儿子翻地的价值,不仅在于翻到园中的金子,更是在于翻地之后,促进了秋天果园的丰收。在第03个小故事中,醉汉黑暗中寻找的钥匙,亦非最终的价值,通过钥匙打开的门才是。
对于大数据研究而言,一旦数据收集、存储、分析、传输等能力提高了,即使没有发现什么普适的规律或令人完全想不到的新知识,也极大地推动了诸如计算机软硬件、数据分析等行业的发展,大数据的价值也已逐步体现。
李国杰院士认为,我们不必天天期盼奇迹出现,多做一些“朴实无华”的事,实际的进步就会体现在扎扎实实的努力之中。一些媒体总喜欢宣传一些抓人眼球的大数据成功案例。但从事大数据行业的人士,应保持清醒的头脑:无华是常态,精彩是无华的质变。
如果把“大数据”比作农夫父子院后的那片土地,那么土地的面积越大,会不会能挖掘出的“金子”就越多呢?答案还真不是,下面的故事我们说说大数据的大小之争。
故事05:盖洛普抽样的成功――大小之争,“大”数据一定胜过小抽样吗?
1936年,民主党人艾尔弗雷德?兰登(Alfred Landon)与时任总统富兰克林・罗斯福(Franklin Roosevelt)竞选下届总统。《文学文摘》(The Literary Digest)这家颇有声望的杂志承担了选情预测的任务。之所以说它“颇有声望”,是因为《文学文摘》曾在1920年、1924年、1928年、1932年连续4届美国总统大选中,成功地预测总统宝座的归属。
1936年,《文学文摘》再次雄赳赳、气昂昂地照办老办法――民意调查,不同于前几次的调查,这次调查把范围拓展得更广。当时大家都相信,数据集合越大,预测结果越准确。《文学文摘》计划寄出1000万份调查问卷,覆盖当时四分之一的选民。最终该杂志在两个多月内收到了惊人的240万份回执,在统计完成以后,《文学文摘》宣布,艾尔弗雷德?兰登将会以55比41的优势,击败富兰克林・罗斯福赢得大选,另外4%的选民则会零散地投给第三候选人。
然而,真实的选举结果与《文学文摘》的预测大相径庭:罗斯福以61比37的压倒性优势获胜。让《文学文摘》脸上挂不住的是,新民意调查的开创者乔治・盖洛普(George Gallup),仅仅通过一场规模小得多的问卷――一个3000人的问卷调查,得出了准确得多的预测结果:罗斯福将稳操胜券。盖洛普的3000人“小”抽样,居然挑翻了《文学文摘》240万的“大”调查,实在让专家学者和社会大众跌破眼镜。
显然,盖洛普有他独到的办法,而从数据体积大小的角度来看,“大”并不能决定一切。民意调查是基于对投票人的大范围采样。这意味着调查者需要处理两个难题:样本误差和样本偏差。
在过去的200多年里,统计学家们总结出了在认知数据的过程中存在的种种陷阱(如样本偏差和样本误差)。如今数据的规模更大了,采集的成本也更低了,“大数据”中依然存在大量的“小数据”问题,大数据采集同样会犯小数据采集一样的统计偏差【3】。我们不能掩耳盗铃,假装这些陷阱都已经被填平了,事实上,它们还都在,甚至问题更加突出。
盖洛普成功的法宝在于,科学地抽样,保证抽样的随机性,他没有盲目的扩大调查面积,而是根据选民的分别特征,根据职业、年龄、肤色等在3000人的比重,再确定电话访问、邮件访问和街头调查等各种方式所在比例。由于样本抽样得当,就可以做到“以小见大”、“一叶知秋”。
《文学文摘》的失败在于,取样存在严重偏差,它的调查对象主要锁定为它自己的订户。虽然《文学文摘》的问卷调查数量不少,但它的订户多集中在中上阶层,样本从一开始就是有偏差的(sample bias),因此,推断的结果不准,就不足为奇了。而且民主党人艾尔弗雷德兰登的支持者,似乎更乐于寄回问卷结果,这使得调查的错误更进了一步。这两种偏差的结合,注定了《读者文摘》调查的失败。
我们可以类比一下《文学文摘》的调查模式,试想一样,如果在中国春运来临时,在火车上调查,问乘客是不是买到票了,即使你调查1000万人,这可是大数据啊,结论毫无意外地是都买到了,但这个结果无论如何都是不科学的,因为样本的选取是有偏的。
当然,采样也是有缺点的,如果采样没有满足随机性,即使百分之几的偏差,就可能丢失“黑天鹅事件”的信号,因此在全数据集存在的前提下,全数据当然是首选(但从第02故事中,我们可以看到,全数据通常是无法得到的)。对针对数据分析的价值,英特尔中国研究院院长吴甘沙先生给出了一个排序:全数据>好采样数据>不均匀的大量数据。
大数据分析技术运用得当,能极大地提升人们对事物的洞察力(insight),但技术和人谁在决策(decision-making)中起更大作用?在下面的“点球成金”小故事,我们聊聊这个话题。
故事06:点球成金――数据流PK球探,谁更重要?
《点球成金》(Moneyball)又是一例数据分析的经典故事:
长期以来,美国职业棒球队的教练们依赖惯例规则是,依据球员的“击球率(Batting Average, AVG)”(其值等于安打数/打数),来挑选心仪的球员。而奥克兰“运动家球队”的总经理比利?比恩(Billy Beane)却另辟新径,采用上垒率指标(On-Base Percentage, OBP)来挑选球员,OBP代表一个球员能够上垒而不是出局的能力。
采用上垒率来选拔人才,并非毫无根据。通过精细的数学模型分析,比利?比恩发现,高“上垒率”与比赛的胜负存在某种关联(corelation),据此他提出了自己的独到见解,即一个球员怎样上垒并不重要,不管他是地滚球还是三跑垒,只要结果是上垒就够了。在广泛的批评和质疑声中,比恩通过自己的数据分析,创立了“赛伯计量学”(Sabermerrics)。据此理论,比恩依据“高上垒率”选取了自己所需的球员,这些球员的身价远不如其他知名球员,但比利?比恩却能带领这些球员在2002年的美国联盟西部赛事中夺得冠军,并取得了20场连胜的战绩。

图5 点球成金(图片来源:wikipedia.org)
这个故事讲得是数量化分析和预测对棒球运动的贡献,吴甘沙先生认为,它在大数据背景下出现了传播的误区:
第一,它频繁出现在诸如舍恩伯格《大数据时代》之类的图书中,其实这个案例并非大数据案例,而是早已存在的数据思维和方法。在“点球成金”案例中的数据,套用大数据的4V特征,基本上,无一符合。
第二,《点球成金》无论是小说,还是拍出来的同名电影,都刻意或无意忽略了球探的作用。从读者/观众的角度来看,奥克兰“运动家球队”的总经理比利・比恩完全运用了数据量化分析取代了球探。而事实上,在运用这些数据量化工具的同时,比恩也增加了球探的费用,“军功章里”有数据分析的一半,也有球探的一半。
目前的大数据时代,就有这么两个流派,一派是技术主导派,他们提出“万物皆数”,要么数字化,要么死亡(孙正义在对日本企业界的演讲上所言),他们认为技术在决策中占有举足轻重地作用。另一派是技术为辅派,他们认为,技术仅仅是为人服务的,属于为人所用的众多工具的一种,不可夸大其作用。
针对《点球成金》这个案例,比利?比恩的拥趸者就属于“数据流党”,而更强调球探作用的则归属于“球探党”。
球探党Bill Shanks在其所著的《球探的荣耀:论打造王者之师的最勇敢之路》(Scout’s Honor: The Bravest Way To Build A Winning Ballteam)中【9】,对数据流党的分析做出了强有力地回应。他认为,球探对运动员定性指标(如竞争性、抗压力、意志力,勤奋程度等)的衡量,是少数结构化数据(如上垒率等)指标无法量化刻画的。
和《点球成金》观点针锋相对的是,Bill Shanks更认可球探的作用,他把球探的作用命名为“勇士”哲学。对于勇士来说,数据分析只是众多“刀枪棍棒”兵刃中的一种,无需奉之如圭臬,真正能“攻城略地”的还是需要勇士。比如说,运动家棒球队虽然在数据分析的指导下,获得了震惊业界的好成绩,然而他们并没有取得季后赛的胜利,也没有夺取世界冠军,这说明,数据分析虽重要,但人的作用更重要!
从第01故事的分析中,我们知道,大数据分析的第一层作用就是,面向过去,发现潜藏在数据表面之下的历史规律或模式,也就是说达到描述性分析。而为了让读者相信数据分析的能力,灌输一些“心灵鸡汤(或称洗脑)”,是少不了的,哪怕它是假的!
故事07:啤酒和尿布:经典故事是伪造的,你知道吗?
这是一个关于零售帝国沃尔玛的故事。 在一次例行的数据分析之后, 研究人员突然发现: 跟尿布一起搭配购买最多的商品,竟是啤酒!
尿布和啤酒,听起来风马牛不相及,但这是对历史数据进行挖掘的结果,反映的是数据层面的规律。这种关系令人费解,但经过跟踪调查,研究人员发现,一些年轻的爸爸常到超市去购买婴儿尿布,有30%~40%的新爸爸,会顺便买点啤酒犒劳自己。随后,沃尔玛对啤酒和尿布进行了捆绑销售,不出意料,销售量双双增加。
上面这个案例,出自于涂子沛先生的所著的大数据畅销书《数据之巅》,在这个案例中,要情节有情节,要数据,有数据,誓言旦旦,不容你置疑。但是,这个故事虽经典,但是让你意想不到的是:
1.案例是编造的
这个经典的“啤酒和尿布” (Beer and Diapers)的案例,不仅是《大数据》类图书的常客,事实上,它更是无数次流连于“数据挖掘”之类的书籍中,特别是用来解释“关联规则(Association Rule)”的概念,更是“居家旅行,必备之良药(周星驰语)”。当前,基本上所有讲大数据应用,都会捎带讲上这个经典案例,要求大家多研究“相关性”,少研究因果关系!但实在扫兴的是,这个案例仅是一碗数据分析的“心灵鸡汤”――听起来很爽,但信不得!
实践是检验真理的唯一标准。如果这个故事是真的,按理说,应该给超级市场以无限启发才对,可实际上,不管是中国,还是在美国,在超市里面观察一下,就会发现,根本没有类似的物品摆放,相近的都很少。
故事性强,事出有因。据吴甘沙先生透露,它是Teradata公司一位经理编出来的“故事”,目的是让数据分析看起来更有力,更有趣,而在历史上从没有发生过,感兴趣的读者可以自己参阅文献。但公平地讲,这个故事对数据挖掘的普及意义重大,仅从教育意义上看,仍不失为一个好故事。
2.相关性并非什么大事
即便真的有这个案例,也不说明数据分析出来的“相关性”,有什么特别的神奇之处。舍恩伯格教授的《大数据时代》核心观点之一就是:趾高气扬的因果关系光芒不再,卑微的相关关系将被“翻身做主人”,知道“是什么”就够了,没必要知道“为什么”。但需要我们更为深入了解的事实是:
“要相关,不要因果”,这个观点其实并非舍恩伯格首先提出的。最早的提出者应为《连线》(Wired)主编Chris Anderson ,2008年他在题为 “理论的终结:数据洪流让科学方法依然过时(End of Theory: the Data Deluge Makes the Scientific Method Obsolete)【9】” 文章中,率先提出:在PB时代,我们可以说,有相关性足够了(Petabytes allow us to say: "Correlation is enough)"。

图6 连线杂志:理论的终结
“要相关,不要因果”的观点,并不受学术界待见。甚至,《大数据时代》的中文版翻译者周涛亦在序言里说,“放弃对因果关系的追求,是人类的堕落”。对于这个观点,李国杰院士认为【10】:在大数据中,看起来毫不相关的两件事同时或相继出现的现象比比皆是,相关性本身并没有多大价值,关键是找对了“相关性”背后的理由,才是新知识或新发现。
大数据分析的第二个功能,或者说更为的核心功能在于,预测。预测主要用于对未来进行筹划,大到产业的布局,小到流感的预警,均可用预测。但是对未来的预测,能准吗?
故事08:谷歌流感预测:预测是如何失效的?
2009年2月,谷歌公司的工程师们在国际著名学术期刊《自然》上发表了一篇非常有意思的论文【11】:《利用搜索引擎查询数据检测禽流感流行趋势》,并设计了大名鼎鼎的流感预测系统(Google Flu Trends,GFT,访问网址为:www.google.org/flutrends/)。
GFT预测H1N1流感的原理非常朴素:如果在某一个区域某一个时间段,有大量的有关流感的搜索指令,那么,就可能存在一种潜在的关联:在这个地区,就有很大可能性存在对应的流感人群,相关部门就值得发布流感预警信息。
GFT监测并预测流感趋势的过程仅需一天,有时甚至可缩短至数个小时。相比而言,美国疾病控制与预防中心(Center for Disease Control and Prevention,CDC)同样也能利用采集来的流感数据,发布预警信息。但CDC的流感预测结果,通常需要滞后两周左右才能得以发布。但对于一种飞速传播的疾病(如禽流感等),疫情预警滞后发布,后果可能是致命的。
GFT一度被认为是大数据预测未来的经典案例,给很多人打开了一扇未来的窗口。根据这个故事,大数据的布道者们给出了4个令自己满意的结论:
由于所有数据点都被捕捉到,故传统的抽样统计的方法完全可以被淘汰。换句话说,做到了“n=All”;
无需再寻找现象背后的原因,只需要知道某两者之间的统计相关性就够用了。针对这个案例,只需知道“大量有关流感的搜索指令”和“流感疫情”之间存在相关性就够了。
不再需要统计学模型,只要有大量的数据就能完成分析目的,印证了《连线》主编Chris Anderson 提出的“理论终结”的论调。
大数据分析可得到惊人准确的结果。GFT的预测结果和CDC公布的真实结果相关度高达96%。
但据英国《财经时报》(FT)援引剑桥大学教授David Spiegelhalter毫不客气的评价说 [3],这四条 “完全是胡说八道(complete bollocks. Absolute nonsense)”。
针对前3条观点的不足之处,前文故事已经涉及到了,不再赘言。针对第4条,我们有必要再解析一下――GFT预测是如何失效的?
谷歌工程师们开发的GFT,可谓轰动一时,但好景不长,相关论文发表4年后,2013年2月13日,《自然》发文指出【12】,在最近(2012年12月)的一次流感爆发中谷歌流感趋势不起作用了。GFT预测显示某次的流感爆发非常严重,然而疾控中心(CDC)在汇总各地数据以后,发现谷歌的预测结果比实际情况要夸大了几乎一倍,如图7所示。
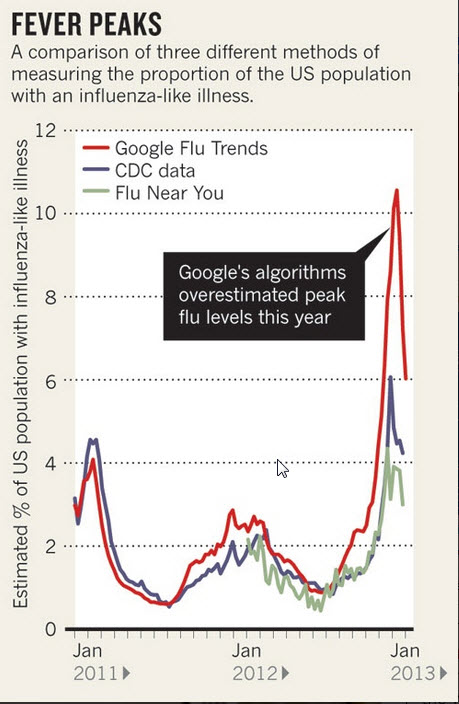
图7 GFT流感预测失准 (图片来源:自然期刊)
研究人员发现,问题的根源在于,谷歌工程师并不知道搜索关键词和流感传播之间到底有什么关联,也没有试图去搞清楚关联背后的原因,只是在数据中找到了一些统计特征――相关性。这种做法在大数据分析中很常见。为了提高GFT的预测准确性,谷歌工程师们不断地微调预测算法,但GFT每一次算法微调,都是为了修补之前的测不准,但每次修补又都造成了另外的误差。
谷歌疫情之所以会误报,还因为大数据分析中存在“预测即干涉”的问题。量子物理创始人之一维尔纳?海森堡(Werner Heisenberg),曾在1927年的一篇论文中指出,在量子世界中,测量粒子位置,必然会影响粒子的速度,即存在“测不准原理”。也就是说,在量子尺度的微距世界中,“测量即干涉”。如今,在媒体热炒的“大数据”世界中,类似于“测不准原理”,即存在“预测即干涉”悖论。
这个“预测即干涉”悖论和“菜农种菜”的现象有“曲艺同工”之处:当年的大白菜卖价不错(历史数据),预计明年的卖价也不错(预测),于是众多菜农在这个预测的指导下,第二年都去种大白菜(采取行动),结果是,菜多价贱伤农(预测失败)。
进一步分析就可发现,GFT预测失准在很大程度上是因为,一旦GFT提到了有疫情,立刻会有媒体报道,就会引发更多相关信息搜索,反过来强化了GFT对疫情的判定。这样下去,算法无论怎么修补,都无法改变其愈发不准确的命运。
对GFT预测更猛烈的攻击,来自著名期刊《科学》【13】。2014年3月,该杂志发表由哈佛大学、美国东北大学的几位学者联合撰写的论文“谷歌流感的寓言:大数据分析中的陷阱(The parable of Google Flu: traps in big data analysis)”,他们对谷歌疫情预测不准的问题做了更为深入地调查,也讨论了大数据的“陷阱”本质。《科学》一文作者认为:大数据的分析是很复杂的,但由于大数据的收集过程,很难保证有像传统“小数据”那样缜密,难免会出现失准的情况,作者以谷歌流感趋势失准为例,指出“大数据傲慢(Big Data Hubris)”是问题的根源。
《科学》一文还认为,“大数据傲慢(Big Data Hubris)”还体现在,存在一种错误的思维方式,即误认为大数据模式分析出的“统计学相关性”,可以直接取代事物之间真实的因果和联系,从而过度应用这种技术。这就对那些过度推崇“要相关,不要因果”人群,提出了很及时的警告。毕竟,在某个时间很多人搜索“流感”,不一定代表流感真的暴发,完成有可能只是上映了一场关于流感的电影或流行了一个有关流感的段子。
果壳网有一篇对《科学》一文深度解读的文章:“数据并非越大越好:谷歌流感趋势错在哪儿了?”,感兴趣的读者可以前去围观。
苏萌、柏林森和周涛等人合著的《个性化:商业的未来》【14】,他们强调,“个人化”服务是未来最有前途的商业模式。可这里有个问题,提供“个人化”服务,就需要了解顾客的“个性化信息”,如果顾客许可使用个人信息的,那么这种个性化服务是贴心的,如果没有许可呢?
下面这个故事就是一则有关商品个性化推荐的,但它体现出来的是数据分析的智慧,还是愚蠢呢?
故事09:Target超市预测女孩怀孕:“大数据”智慧,还是愚蠢?
2012年2月16日,《纽约时报》刊登了Charles Duhigg撰写的一篇题为《这些公司是如何知道您的秘密的》(How Companies Learn Your Secrets)的报道【15】。文中介绍了这样一个故事:
一天,一位男性顾客怒气冲冲地来到一家折扣连锁店Target(中文常译作“塔吉特”,为仅次于沃尔玛的全美第二大零售商),向经理投诉,因为该店竟然给他还在读高中的的女儿,邮寄婴儿服装和孕妇服装的优惠券。
但随后,这位父亲与女儿进一步沟通发现,自己女儿真的已经怀孕了。于是致电Target道歉,说他误解商店了,女儿的预产期是8月份。

图8 《纽约时报》:这些公司是如何知道您的秘密的
一家零售商是如何比一位女孩的亲生父亲更早得知其怀孕消息的呢?这里就需要用到“关联规则+预测推荐”技术。
事实上,每位顾客初次到Target刷卡消费时,都会自动获得一个唯一顾客识别编号(ID)。以后,顾客再次光临Target消费时,计算机系统就会自动记录顾客购买的商品、时间等信息。再加上从其它管道取得的统计资料,Target便能形成一个庞大数据库,运用于分析顾客的喜好与需求。
有了数据,特别是有了“大”容量的数据,后面的问题就简单了。Target的数据分析师,开发了很多预测模型,其中怀孕预测模型(pregnancy-prediction model)就是其中的一个。Target通过分析这位女孩的购买记录――无味湿纸巾和补镁药品,就预测到了这为女顾客可能怀孕了,而怀孕了,未来就有可能需要购置婴儿服装和孕妇服装,多么贴心的商店啊。但是需要我们注意的是:
1.这是“大”数据的傲慢,而非聪慧。
由于故事极其具戏剧性――亲生爸爸居然比不上一台电脑更了解自己的女儿,因此,这个故事往往被用来作为“数据比人更了解人”的证明,并在当下,被用来论证大数据的功力。国内有的新闻媒体,对大数据的理解似是而非,针对这个案例的报道标题就是《大数据的功力:比父亲更了解女儿冲击大卖场》【16】。大数据的无所不能的“傲慢”,跃然纸上。
或许“旁观者清”,信息领域外的上海金融与法律研究院研究员刘远举认为【17】,这案例并不能说明,数据比人更“聪慧”,更了解人,恰好相反,这证明计算机是“愚蠢的”:还在读高中的女儿,显然想保护自己的隐私,并不想父亲知道,但“愚蠢的”计算机却自作主张,把孕妇优惠卷寄寄到了她家里,结果被爸爸逮个正着。
这正是(大)数据的另一种傲慢――好像有了(大)数据,就可以“君临天下”,对顾客的理解就可做到出神入化,对顾客的隐私就可以肆无忌惮。
2.这并非大数据的案例
进一步分析,我们可以发现,实际上这个例子并不属于大数据的案例,它不需要太强的计算能力,甚至用一台普通的电脑就能实施类似的关联规则分析。很多有关大数据的图书和文章都把这个案例当作大数据的案例来讲,其实是不恰当的。
大数据一般要具备典型的4个V特征,Target收集的消费数据属于典型的结构化数据,即使数量再大,也仅仅满足4V特征之一――Volume(体积大)。但是,“数据大”不等于“大数据”。如果光拼体积“大”,那么早在20年前,天文、物理和生物信息学的数据,也够得上是“大数据”了。《纽约时报》的原文【15】,非常“厚道”,通篇没有提及“big data(大数据)” 字样。
3.更重要的是,这个神奇的数据预测故事被人为地灌入了很多“心灵鸡汤”。
数据挖掘界的数据分析师、咨询师们有时候同样也需要 “心灵鸡汤”,励志自己,忽悠客户。对此,美国纽约大学统计学教授Kaiser Fung认为[3],很多人在看到这个故事时,都误认为Target的预测算法是非常可靠的――几乎每个收到婴儿连体服和湿纸巾优惠券的人,都是孕妇。但这是不可能的!更为实际的情况是,孕妇之所以能收到这些购物券,是因为Target给非常多客户都邮寄了这种购物券。在众多客户中,碰巧有那么一位高中女生“不太可能但却又真地”怀孕了,碰巧那位父亲发现并投诉了,碰巧那位父亲发现自己错了并道歉了,这么多巧合,“无巧不成书”。因为极具有故事性,所以大家都爱听。
各位读者在相信Target这类读心术般的故事之前,首先应该先想想,这类商家的预测命中率到底有多高。这里并不说,数据分析一无是处,相反,数据分析极具商业价值,即使能够把“直邮(Direct Mail,DM)”的准确度提高一点点,哪怕是1%,对商家而言,都将是有利可图的。但能赚钱并不意味着这种工具无所不能、永远正确。
商家能够提供个性化服务,确实很贴心,但倘若在利益的趋势下,商家对顾客的个性化信息运用不当或越界,就会给顾客带来不能承受的隐私之痛。下面我们聊聊有关大数据隐私的故事。
故事10:你的一夜情我知道――大数据的隐私之痛
Uber(优步,著名的打车软件服务公司,乘客可以通过发送短信或是使用移动应用程序来预约车辆,利用移动应用程序时还可以追踪车辆的位置)曾在官网上发布一篇题为“荣耀之旅(Rides of Glory,RoG)”的博客。文中写到,“我知道,我们不是你们生命中唯一的爱人,我们也知道,你们会在别的什么地方寻找爱情(we know we’re not the only ones in your life and we know that you sometimes look for love elsewhere)。” Uber称作的“荣耀之旅(RoG)”――实际上就是所谓的一夜情(one-night stand)代名词。
Uber利用数据分析技术,专门筛选出那些在晚上10点到凌晨4点之间的用车服务,并且这些客户会在四到六小时之后(这段时间足够完成一场快速的RoG),在距离上一次下车地点大约1/10英里(约160米)以内的地方再次叫车。
图9 美国大城市一夜情发生率的对比(图片来源:Uber)
根据对这些数据的分析,Uber推断出那些发生一夜情的时间和地点,并将这些地点在纽约(NYC)、旧金山(SF)、波士顿(Boston)以及其他美国城市的地图上进行标注,得出一夜情频繁的高发区。数据分析发现,波士顿位于美国“一夜情”之首,而纽约人则显得比较保守,“一夜情”的比率仅仅为波士顿的1/5。在时间节点上,一夜情“发作”的高频发段是在周五和周六晚上,如果你的另一半在这个时间点上说自己工作忙要加班,你就要“悠着点”相信。
当然,Uber此处虽多为开玩笑之举,但也确实严重侵犯了用户的隐私,在遭到了很多用户及媒体的的抗议,例如,《纽约时报》发表题为《我们不能信任优步》(We Can’t Trust Uber)【18】。
在遭到用户和媒体抗议以后,Uber迅速删除了这篇博客,但在这个数字时代,一旦上网,“侯门一入深似海”,踏雪无痕梦难成”。感兴趣的读者仍可访问互联网文档收录网站https://archive.org/,找到这篇文章。
不可否认的是,大数据时代的到来,为我们的学习、生活带来诸多便利。但是,收之桑榆,失之东隅。任何事情都有两面性。目前,人的行为(诸如购物、乘车、甚至游戏等)已经被数字化了,隐私已经无处可藏!不论是美国斯诺登“棱镜门”监听项目的曝光,还是层出不穷的诸如Uber等公司企业泄露客户资料事件,都向我们发出大数据时代下个人隐私保护的预警。
中国著名生命伦理学家邱仁宗先生认为【19】,大数据技术,与所有技术一样它本身无所谓“好”“坏”,故它本身在伦理学上是中性的。然而使用它的个人、公司、机构有价值取向的,大数据犹技术如一把双刃剑,它可以给我们的生活、科研带来便利,但也能带来诸如侵犯隐私的消极影响。
完善的立法,对保护用户隐私来说极其重要。例如,规定只有用户需要个性化服务定制的时候,提出需求,大数据公司才能调用该用户的信息,其他情况下的信息调用都采取匿名的方式,否则就视作侵犯隐私。
网上有个以“恐怖的大数据”为题的段子,用定披萨饼的流程,把用户的隐私披露地“一览无遗”,虽有夸张成分,但在大数据时代,隐私保护的必要性,已经不容置疑了。
小结
《旧约・箴言篇》18章17节里有句话:“先诉情由的,似乎有理。但邻舍来到,就察出实情”。
随着诸如舍恩伯格教授的《大数据时代》、涂子沛先生的《数据之巅》等大作的面世,对世人带来了“醍醐灌顶”式的教育洗礼,在教育民众和政府官员接纳大数据时代的普及意义上,这些著作,居功至伟。他们书中的很多思维,已被很多大数据的拥趸者奉为圭臬,但任何事情都有两面性,一味的热捧,就会带来认知的偏颇。
诸如《纽约时报》、《财经时报》、《自然》及《科学》等重量级的反思“邻舍”的到临,能让我们对“大数据”有更为客观的认知。从他们给出的一各个小故事(小案例或小段子)中,可以促使我们对大数据的热炒有所反思,从而告诫我们之间,一定保持清醒头脑,批判性地接受大数据布道者的思维,切不可将其当作放之四海而皆准的真理。对大数据的过分依赖,就有可能重蹈伊卡洛斯(Icarus)的覆辙。

图 10 伊卡洛斯之殇(图片来源:百度百科)
在希腊神话中,伊卡洛斯是个自负的天神,他是代达罗斯的儿子,一天,在与父亲代达罗斯使用蜡和羽毛制造的羽翼逃离克里特岛时,由于他过分相信自己的飞行技,故而飞得太高,双翼上的蜡在太阳照射下融化,羽翼脱落,最终导致自己葬身大海。
大数据技术就犹如那 “蜡和羽毛”做的翅膀,它可以助我们飞得更高,但倘若过分依赖它,就有葬身大海的风险。我们要学会如何让大数据为我所用,而不是成为大数据的奴隶。 |






