| 摘要:为了筛选出最有可能转化的用户,京东DNN实验室结合大数据进行了相关研究。本文以新品手机为例,使用商品相似度和基于分类的手段进行用户群筛选,详解了基于余弦相似度的相似度模型构建和基于SVM的分类预测方法。
当电商网站发布一款新产品的时候,怎样找到一群最有可能购买该新品的用户进行营销是一种提高产品销量的重要手段。当然全网营销手段肯定能覆盖所有用户,但这样做一方面浪费资源,增加营销成本;另一方面用户收到过多不感兴趣的信息,会让用户反感,降低用户的体验度。
电商数字化营销成为了营销过程中必不可少的手段。为了筛选出最有可能转化的用户,京东DNN实验室结合大数据进行了相关研究。本文以新品手机为例,使用商品相似度和基于分类的手段进行用户群筛选。
余弦相似度的筛选方式
在实际应用中,我们为了找出相似的文章或者相似新闻,需要用到“余弦相似性”,下面我们举例说明什么是余弦相似性。为了简单起见,我们来看两个简单的句子。
句子A:我喜欢吃中餐,不喜欢吃西餐。
句子B:我不喜欢吃中餐,也不喜欢吃西餐。
我们怎样才能计算A,B句子的相似度呢?
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。下面是具体的实施步骤:
1. 分词
句子A:我/喜欢/吃/中餐,不/喜欢/吃/西餐。
句子B:我/不/喜欢/吃/中餐,也/不/喜欢/吃/西餐。
2. 列出所有的词
我,喜欢,中餐,西餐,吃,不,也
3. 计算词频
句子A:我 1,喜欢 2,中餐 1,西餐 1,吃 2,不 1,也 0
句子B:我 1,喜欢 2,中餐 1,西餐 1,吃 2,不 2,也 1
4. 构造词频向量
句子A:[1, 2, 1, 1, 2, 1, 0]
句子B:[1, 2, 1, 1, 2, 2, 1]
通过上面的步骤,问题就变成了如何计算两个向量的相似度。我们可以把它们想象成空间中的两条线段,都是从原点([0,
0, ...])出发,指向不同的方向。两条线段之间形成一个夹角,如果夹角为0度,意味着方向相同、线段重合;如果夹角为90度,意味着形成直角,方向完全不相似;如果夹角为180度,意味着方向正好相反。因此,我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。
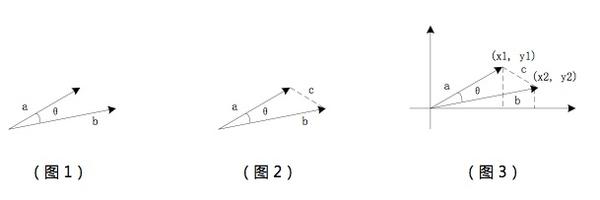
以二维空间为例,图1中的a,b是两个向量,我们要计算它的夹角θ,余弦定理表明可以用以下公式求得:
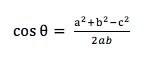
假定a是向量[x1, y1],b是向量[x2, y2],那么可以将余弦定理改写成如下形式:
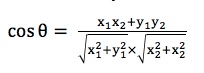
已经证明余弦定理对n维向量也成立。一般的,A,B是两个n维向量,A是 [A1, A2, ..., An]
,B是 [B1, B2, ..., Bn] ,则A与B的夹角θ的余弦等于:
使用公式3,可以计算出句子A和句子B夹角的余弦:
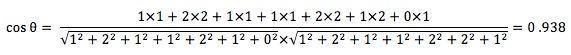
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。所以,上面的句子A和句子B是很相似的,事实上它们的夹角大约为20.3度。
基于以上,我们可以得出文本相似性的一种算法。
使用关键词提取算法(例如:TF-IDF),找出两篇文章的关键词。
每篇文章各取出若干个关键词(比如50个),合并成一个集合,计算每篇文章对应集合中的词频(为了避免文章长度的差异,可以使用相对词频)。
生成两篇文章各自的词频向量。
计算两个向量的余弦相似度,值越大就表示越相似。
基于余弦相似度的商品相似度模型
得出了余弦相似度的数值之后,如何利用它进行新品推荐呢?首先在余弦相似度计算中,我们需要构造两个向量进行相似度计算,在新品推荐中我们如何构造这两个向量呢?
结合大数据分析技术,基于用户的历史购买记录刻画出用户对于手机这个品类各特征的偏好程度,如品牌、价格、颜色、操作系统等偏好。经过计算之后每一个用户对手机这个品类都有一个特征偏好向量,这样将新品手机各个特征转换为一个向量即可进行余弦相似度计算,最后执行排序筛选出靠前的用户即可。下面是具体的实施方案。
1. 提取用户手机历史购买数据,基于统计计算出品牌特征,颜色特征等的偏好,计算公式如下:
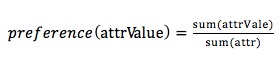
例如,计算华为品牌的偏好为:
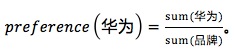
2. 将用户每一个特征偏好组合表示为特征偏好向量:
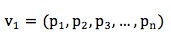
3. 将新品手机特征表示为向量:
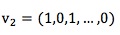
新品的特征向量维度值取值为0或者1,例如新品品牌为华为,则华为这个特征为1,其他品牌特征值为0。
4. 计算余弦相似度:
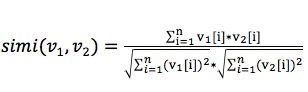
其中simi值越大表示越相似。
5. 执行排序:根据simi值进行排序,取最相似的一部分用户进行营销。
基于权重的余弦相似度
在前文中提到的算法,特征维度没有考虑特征的权重,所有特征的权重都是相同的。对于购买手机来说,价格、品牌和网络制式等特征权重设置为相同可能不合理,所以需要对用户购买手机的行为进行分析,分析主要特征,形成权重特征向量:
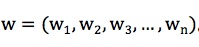
特征加权之后相似度计算公式如下:
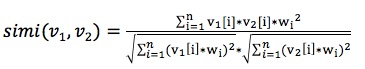
优化与改进
基于余弦相似度的新品用户营销有以下缺点:
用户之前必须购买过同品类商品,这样才能计算商品相关的偏好。对于没有购买过该品类的用户不会参与运算。可以考虑从用户浏览,关注数据统计出用户该品类的商品偏好。计算用户偏好没有考虑时间属性,只是基于统计概率。有可能用户最近购买了苹果手机,之前购买了几个华为手机,按照偏好计算公式,华为的偏好值高于苹果的偏好值,但是用户最近在手机上真实的偏好却是苹果。偏好计算可以考虑把时间因素加入,应该随时间增加而衰减。
用余弦相似度进行新品营销是基于这样一个假设:即用户通常会购买与之前商品相近或者说同类型的商品。然而有时候这样的假设是不合理的,所以需要针对具体的品类,提前做品类下哪些因素是决定用户购买的因素,用户对什么因素粘性度比较高。
基于SVM新品营销
下面我们换一种方式进行新品营销,我们采用分类算法。使用SVM进行分类预测,下面介绍SVM的具体流程。
特征筛选与特征表示
说到分类算法,首先我们需要解决的问题是特征怎么提取和表示。下面将介绍我们使用到的具体流程:
1. 提取行为数据。按照商品品类维度,时间维度以月为单位提取用户的品类PV,购物车和订单等行为数据。
2. 清洗数据,提取转换特征。将时间维度分为多个区间,每个区间内每一个维度的数据划分为多个区间。比如PV这个维度在品类category1下会形成以下特征。
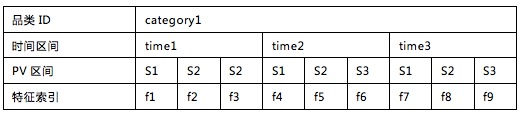
3. 特征向量化。根据步骤2提取的特征与特征的索引,将每一个用户用特征向量表示为:
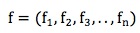
其中fi取值为0或则1,向量的维度表示特征的索引。
样本选取
样本选择有以下方式:
选择之前购买过和新品相似商品部分用户作为正样本,没有购买过的部分用户作为负样本。
选择新品发布后购买的用户作为正样本,没有购买过的部分用户作为负样本。
以上两种方案各有优缺点:方案1的难点在于寻找相似的商品A,且提取转换特征的时候需要注意时间维度,时间必须卡在A商品销售之前。方案2需要新品销售一段时间后才会有正样本数据。方案2适合于二次营销,方案1适合于首次营销。
模型训练
可以选用java版本的liblinear进行模型训练。
用户提取
根据模型训练得出的结果,再根据预测概率进行排序,取靠前的用户进行营销。
实验结果
在A/B test 实验中,分别应用以上方法筛选的用户集和基于经验(规则)方法筛选的用户集进行营销效果对比。最后实验结果表明:基于以上两种方法在订单转化率,促成总金额方面都比基于经验的方法效果好。可以广泛应用于数字化营销中,带来比较高的转化率。
展望与未来
这两种技术方案,可以很好的用于数字化的营销当中。对于数字化营销来说,精准的数据量可以很好的控制营销成本。因为一个热门商品和一个冷门商品需要的营销人员在数量上是存在差距的,造成的营销成本也有差异。对于这两种技术方案,仍然需要进一步优化以得到更为精准的数据量,在未来首先要优化并结合先进的DNN模型,提升模型效果;其次结合商品销量预测,确定最终需要营销的人数。 |






