|
摘要:伴随着系统性能、成本及扩展性的新时代需要,以HBase、MongoDB为代表的NoSQL数据库和以阿里DRDS、VoltDB、ScaleBase为代表的分布式NewSQL数据库如雨后春笋般不断涌现出来。本文详细介绍了阿里分布式数据库服务DRDS。
随着互联网时代的到来,计算机要管理的数据量呈指数级别地飞速上涨,而我们却完全无法对用户数做出准确预估。我们的系统所需要支持的用户数,很可能在短短的一个月内突然爆发式地增长几千倍,数据也很可能快速地从原来的几百GB飞速上涨到了几百个TB。如果在这爆发的关键时刻,系统不稳定或无法访问,那么对于业务将会是毁灭性的打击。
伴随着这种对于系统性能、成本以及扩展性的新需要,以HBase、MongoDB为代表的NoSQL数据库和以阿里DRDS、VoltDB、ScaleBase为代表的分布式NewSQL数据库如雨后春笋般不断涌现出来。
本文将会介绍阿里DRDS的技术理念、发展历程、技术特性等内容。
DRDS设计理念
从20世纪70年代关系数据库创立开始,其实大家在数据库上的追求就从未发生过变化:更快的存取数据,可以按需扩缩以承载更大的访问量和更大的数据量,开发容易,硬件成本低,我们可以把这叫做数据库领域的圣杯。
为了支撑更大的访问量和数据量,我们必然需要分布式数据库系统,然而分布式系统又必然会面对强一致性所带来的延迟提高的问题,因为网络通信本身比单机内通信代价高很多,这种通信的代价就会直接增加系统单次提交的延迟。延迟提高会导致数据库锁持有时间变长,使得高冲突条件下分布式事务的性能不升反降(这个具体可以了解一下Amdahl定律),甚至性能距离单机数据库都还有明显的差距。
从上面的说明,我们可以发现,问题的关键并不是分布式事务做不出来,而是做出来了却因为性能太差而没有什么卵用。数据库领域的高手们努力了40年,但至今仍然没有人能够很好地解决这个问题,Google Spanner的开发负责人就经常在他的Blog上谈论延迟的问题,相信也是饱受这个问题的困扰。
面对这个难题,传统的关系数据库选择了放弃分布式的方案,因为在20世纪70~80年代,我们的数据库主要被用来处理企业内的各类数据,面对的用户不过几千人,而数据量最多也就是TB级别。用单台机器来处理事务,用个磁盘阵列处理一下磁盘容量不够的问题,基本上就能解决一切问题了。
然而,信息化和互联网的浪潮改变了这一切,我们突然发现,我们服务的对象发生了根本性变化,从原来的几千人,变成了现在的几亿人,数据量也从TB级别到了PB级别甚至更多。存在单点的单机系统无论如何努力,都会面对系统处理能力的天花板。原来的这条路,看起来是走不下去了,我们必须想办法换一条路来走。
可是,分布式数据库所面对的强一致性难题却像一座高山,人们努力了无数个日日夜夜,但能翻越这座山的日子看来仍然遥遥无期。
于是,有一群人认为,强一致性这件事看来不怎么靠谱,那彻底绕开这个问题是不是个更好的选择?他们发现确实有那么一些场景是不需要强一致事务的,甚至连SQL都可以不要,最典型的就是日志流水的记录与分析这类场景。而去掉了事务和SQL,接口简单了,性能就更容易得到提升,扩展性也更容易实现,这就是NoSQL系统的起源。
虽然NoSQL解决了性能和扩展性问题,但这种绕开问题的方法给用户带来了很多困扰,系统的开发成本也大大提升。这时候就有另外一群人,他们觉得用户需要SQL,觉得用户也需要事务,问题的关键在于我们要努力地往圣杯的方向不断前进。在保持系统的扩展性和性能的前提下,付出尽可能小的代价来满足业务对数据库的需要。这就是NewSQL这个理念的由来。
DRDS也是一个NewSQL的系统,它与ScaleBase、VoltDB等系统类似,都希望能够找到一条既能保持系统的高扩展性和高性能,又能尽可能保持传统数据库的ACID事务和SQL特性的分布式数据库系统。
DRDS发展历程
在一开始,TDDL的主要功能就是做数据库切分,一个或一组SQL请求提交到TDDL,TDDL进行规则运算后得知SQL应该被分发到哪个机器,直接将SQL转发到对应机器即可(如图1)。
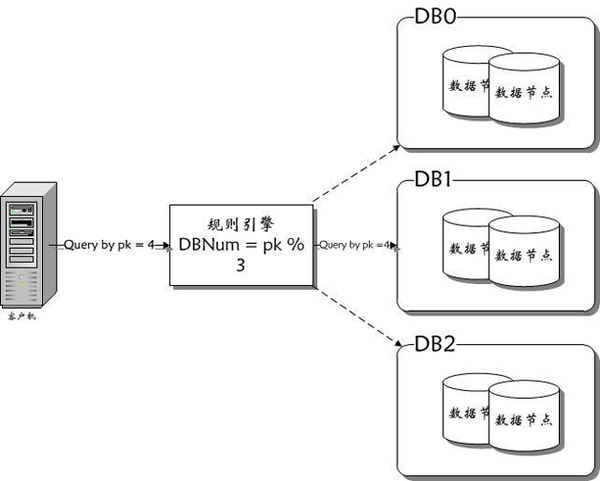
图1 TDDL数据库切分
开始的时候,这种简单的路由策略能够满足用户的需要,我们开始的那些应用,就是通过这样非常简单的方式完成了他所有的应用请求。我们也认为,这种方案简单可靠,已经足够好用了。
然而,当我们服务的应用从十几个增长到几百个的时候,大量的中小应用加入,大家纷纷表示,原来的方案限制太大,很多应用其实只是希望做个读写分离,希望能有更好的SQL兼容性。
于是,我们做了第一次重大升级,在这次升级里,我们提出了一个重要的概念就是三层架构,Matrix对应数据库切分场景,对SQL有一定限制,Group对应读写分离和高可用场景,对SQL几乎没有限制。如图2所示。
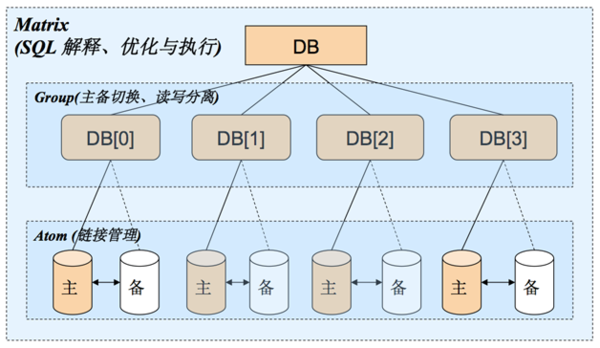
图2 数据库升级为三层架构
这种做法立刻得到了大家的认可,TDDL所提供的读写分离、分库分表等核心功能,也成为了阿里集团内数据库领域的标配组件,在阿里的几乎所有应用上都有应用。最为难得的是,这些功能从上线后,到现在已经经历了多年双11的严酷考验,从未出现过严重故障(p0、p1级别故障属于严重故障)。数据库体系作为整个应用系统的重中之重,能做到这件事,真是非常不容易。
随着核心功能的稳定,自2010年开始,我们集中全部精力开始关注TDDL后端运维系统的完善与改进性工作。在DBA团队的给力配合下,围绕着TDDL,我们成功做到了在线数据动态扩缩、异步索引等关键特征,同时也比较成功地构建了一整套分布式数据库服务管控体系,用户基本上可以完全自助地完成整套数据库环境的搭建与初始化工作。
大概是2012年,我们在阿里云团队的支持下,开始尝试将TDDL这套体系输出到阿里云上,也有了个新的名字:阿里分布式数据库服务(DRDS),希望能够用我们的技术服务好更多的人。
不过当我们满怀自信地把自己的软件拿到云上的时候,却发现我们的软件距离用户的要求差距很大。在内部因为有DBA的同学们帮助进行SQL review,所以SQL的复杂度都是可控的。然而到了云上,看了各种渠道提过来的兼容性需求,我们经常是不自觉地发出这样的感叹:“啊?原来这种语法MySQL也是可以支持的?”
于是,我们又进行了架构升级,这次是以兼容性为核心目标的系统升级工作,希望能够在分布式场景下支持各类复杂的SQL,同时也将阿里这么多年来在分布式事务上的积累都带到了DRDS里面。
这次架构升级,我们的投入史无前例,用了三年多才将整个系统落地完成。我们先在内部以我们自己的业务作为首批用户上线,经过了内部几百个应用的严酷考验以后,我们才敢拿到云上,给到我们的最终用户使用。
目前,我们正在将TDDL中更多的积累输出到云上,同时也努力优化我们的用户界面。PS:其实用户界面优化对我们这种专注于高性能后端技术的团队来说,才是最大的技术挑战,连我也去学了AngularJS,参与了用户UI编。
DRDS主要功能介绍
发展历史看完了,下面就由我来介绍一下目前我们已经输出到云上的主要功能。
【分布式SQL执行引擎】
分布式SQL引擎主要的目的,就是实现与单机数据库SQL引擎的完全兼容。目前我们的SQL引擎能够做到与MySQL的SQL引擎全兼容,包括各类join和各类复杂函数等。他主要包含SQL解析、优化、执行和合并四个流程,如图3中绿色部分。
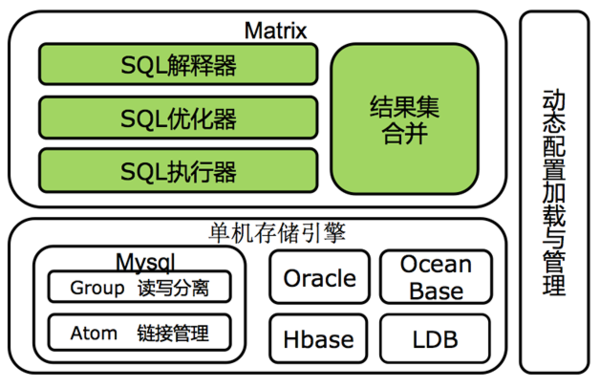
图3 SQL引擎实现的主要流程
虽然SQL是兼容的,但是分布式SQL执行算法与单机SQL的执行算法却完全不同,原因也很简单,网络通信的延迟比单机内通信的延迟大得多。举个例子说明一下,我们有份文件要从一张纸A上誊写到另外一张纸B上,单机系统就好比两张纸都在同一个办公室里,而分布式数据库则就像是一张纸在北京,一张纸在杭州。
自然地,如果两张纸在同一个办公室,因为传输距离近,逐行誊写的效率是可以接受的。而如果距离是北京到杭州,用逐行誊写的方式,就立刻显得代价太高了,我们总不能看一行,就打个“飞的”去杭州写下来吧。在这种情况下,还是把纸A上的信息拍个照片,【一整批的】带到杭州去处理,明显更简单一些。这就是分布式数据库特别强调吞吐调优的原因,只要是涉及到跨机的所有查询,都必须尽可能的积攒一批后一起发送,以减少系统延迟提高带来的不良影响。
【按需数据库集群平滑扩缩】
DRDS允许应用按需将新的单机存储加入或移出集群,DRDS则能够保证应用在迁移流程中实现不停机扩容缩容。
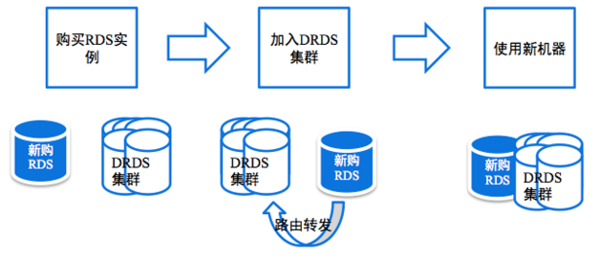
图4 DRDS按需进行平滑扩缩
在内部的数据库使用实践中,这个功能的一个最重要应用场景就是双11了。在双11之前,我们会将大批的机器加入到我们的数据库集群中,抗过了双11,这批机器就会下线。
当DRDS来到云上,我们发现双11其实不仅仅只影响阿里内部的系统。在下游的各类电商辅助性系统其实也面对巨大压力。在双11前5天,网聚宝的熊总就找到我说,担心撑不过双11的流量,怕系统挂。于是我们就给他介绍了这个自动扩容的功能怎么用,他买了一个月的数据库,挂接在DRDS上。数据库能力立刻翻倍,轻松抗过了双11,也算是我印象比较深刻的一个案例了。
因为我们完全无法预测在什么时间点系统会有爆发性的增长,而如果在这时候系统因为技术原因不能使用,就会给整个业务带来毁灭性的影响,风口一旦错过,就追悔莫及了。我想这就是云计算特别强调可扩展能力的原因吧。
【小表广播】
小表广播也是我们在分布式数据库领域内最常用的工具之一,他的核心目的其实都是一个――尽可能让查询只发生在单机。
让我们用一个例子来说明,小表广播的一般使用场景。
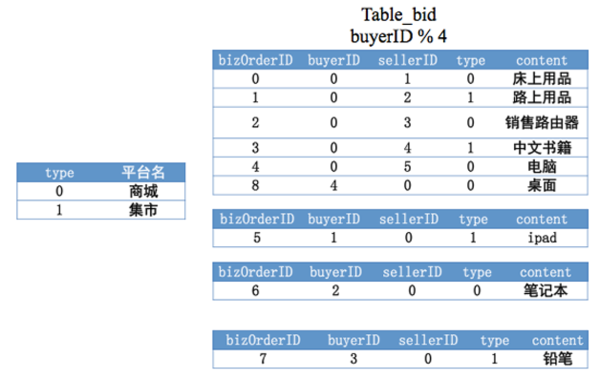
图5 小表广播场景
图5中,如果我想知道买家id等于0的用户在商城里面买了哪些商品,我们一般会先将这两个表join起来,然后再用where平台名=”商城” and buyerID = 0找到符合要求的数据。然而这种join的方式,会导致大量的针对左表的网络I/O。如果要取出的数据量比较大,系统延迟会明显上升。
这时候,为了提升性能,我们就必须要减少跨机join的网络代价。我们比较推荐应用做如下处理,将左表复制到右表的每一个库上。这样,join操作就由分布式join一下变回到本地join,系统的性能就有很大的提升了,如图6所示。

图6
【分布式事务套件】
在阿里巴巴的业务体系中存在非常多需要事务类的场景,下单减库存,账务,都是事务场景最集中的部分。
而我们处理事务的方法却和传统应用处理事务的方案不大一样,我们非常强调事务的最终一致性和异步化。利用这种方式,能够极大地降低分布式系统中锁持有的时间,从而极大地提升系统性能。
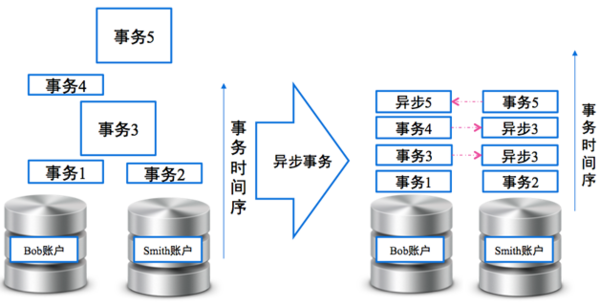
图7 DRDS分布式事务解决套件
这种处理机制,是我们分布式事务能够以极低成本大量运行的最核心法门。在DRDS平台内,我们将这些方案产品化,为了DRDS的分布式事务解决套件。
利用他们,能够让你以比较低的成本,实现低延迟,高吞吐的分布式事务场景。
DRDS的未来
阿里分布式数据库服务DRDS上线至今,大家对这款产品的热情超出了我们的预期,短短半年内已经有几千个申请。
尽管还在公测期,但是大家就已经把关系到身家性命的宝贵在线数据业务放到了DRDS上,我能够感受到这份沉甸甸的信赖,也不想辜负这份信赖。
经过阿里内部几千个应用的不断历练,DRDS已经积累出一套强大的分布式SQL执行引擎和和一整套分布式事务套件。
我也相信,这些积累能够让用户在基本保持单机数据库的使用习惯的前提下,享受到分布式数据库高性能可扩展的好处。
在平时的DRDS支持过程中,我面对最多的问题就是,DRDS能不能够在不改变任何原有业务逻辑和代码的前提下,实现可自由伸缩和扩展呢?十分可惜的是,关系数据库发展至今,还没有找到既能保留传统数据库一切特性,又能实现高性能可扩展数据库的方法。
然而,虽不能至,吾心向往之!我们会以“可扩展,高性能”为产品核心,坚定地走在追寻圣杯的路上,并坚信最终我们一定能够找寻到它神圣的所在。
作者简介:王晶昱,花名沈询,阿里巴巴资深技术专家。目前主要负责阿里的分布式数据库DRDS(TDDL)和阿里的分布式消息服务ONS(RocketMQ/Notify)两个系统。
|






