|
摘要:RebornDB是一个基于代理的分布式Redis集群解决方案,有点像twemproxy。它有一个杀手锏:动态的切分数据集,即透明的重新切分数据而不影响目前正在运行的服务。
现实世界有许多的Key-Value数据库,它们都被广泛应用于很多系统。比如,我们能够用Memcached数据库存储一个MySQL查询结果集给后续相同的查询使用,用MongoDB存储文档以得到更好的查询性能等等。
针对不同的场景,我们应该选不同的Key-Value数据库,没有一个Key-Value数据库适用于所有解决方案,但是如果你仅仅想要一个简单、易于使用、快速、支持多种强大数据结构的Key-Value数据库,Redis可能是你作为开始的一个很好的选择。
Redis是一个先进的Key-Value缓存和数据库,它基于BSD许可证。它的速度很快,支持许多数据类型(String、Hash、List、Set、Sorted Set……),使用RDB或AOF持久化和复制来保证数据的安全性,并且支持多种语言的客户端库。
最重要的是市场选择了Redis,有许多公司正在使用Redis并且它证明了自身的价值。
虽然redis是相当不错的,它仍然有一些缺点,最大的缺点就是内存限制,Redis将所有数据驻留内存,这就限制了整个数据集的大小,让我们不可能保存更多的数据。
官方的Redis集群通过将数据分发到多个Redis服务器来解决这个问题,但是这个方法并没有在许多实际环境中被证明。同时,它需要我们改变自己的客户端库来支持“MOVED”重定向和其它特殊命令,而这在正在运行的生产环境同样是不可接受的。所以,Redis集群现在看来并不是一个好的解决方案。
QDB
我们喜欢Redis,并且希望超越它的局限,因此我们创建了一个服务叫做QDB,它兼容Redis,将数据保存在磁盘来越过内存大小的限制并且将热点数据保存在内存中以提高性能。
介绍
QDB是一个类似Redis的快速Key-Value数据库,它有以下优点:
- 兼容Redis:如果你对Redis很熟悉,你就能轻松使用QDB,它支持大多数的Redis命令和数据结构(String、Hash、List、Set、Sorted Set等);
- 将数据保存在磁盘:(超越内存大小限制)可以将热点数据在内存中保存,利用了后端存储;
- 支持多种后端存储:你可以选择RocksDB、LevelDB或者GoLevelDB(稍后,我们将用RocksDBs作为例子讲解);
- 和Redis双向同步:我们可以作为一个从节点从Redis同步数据,也可以作为一个主节点复制数据到Redis。
后端存储
QDB使用LevelDB、RocksDB、GoLevelDB作为后端存储。这些存储都是基于有着很好的快速读写性能的日志结构的合并树(LSM树),同时他们都使用布隆过滤器和LRU缓存(LRU:最少使用页面置换算法)来提高读的性能。
LevelDB是由Google开发的最早的版本,RocksDB是由Facebook维护的一个优化版本,GoLevelDB是一个纯粹用GO语言实现的LevelDB。如果你仅仅想要一个快速试验并且不想构建和安装RocksDB或者LevelDB,你可以直接使用GoLevelDB,但是我们不推荐你将其使用在生产环境中,因为它的性能比较差。
LevelDB和RocksDB对于你的生产环境来说都是非常不错的,但是鉴于RocksDB绝佳的性能,我们更喜欢RocksDB,之后我们将只支持RocksDB和GoLevelDB,一个用于生产环境,另一个用于试验和测试环境中。
RebirnDB
QDB是很棒的,我们能够在一个机器上存储巨大的数据,并且获得较好的读写性能,但是随着数据集的增长,我们仍然会面临这样的问题,即:我们不能将所有数据都保存在一个机器上。同时,QDB服务器将变成一个瓶颈并且面临单点失败的风险。
现在我们必须要考虑集群解决方案了。
介绍
RebornDB是一个基于代理的分布式Redis集群解决方案。它有点像twemproxy,一个几乎是最早的、最著名的基于代理的Redis集群解决方案。
但是twemproxy有它自己的问题,它仅仅支持静态的集群拓扑,因此我们不能动态的添加或者删除redis节点来重新切分数据。如果我们运行着许多的twemproxy并且希望添加一个Redis后端节点,另一个问题是如何让所有的twemproxy安全的更新配置,而这将增加IT操作的复杂性。同时,Twitter(正在开发twemproxy的公司)目前已经放弃并不再将其应用于生产环境。
不同于twemproxy,RebornDB有一个杀手锏:动态的切分数据集,这将非常有用,特别是在你的数据集增长很快,你不得不增加更多的存储节点来扩展集群的情况下。总之,RebornDB将会透明的重新切分数据而不影响目前正在运行的服务。
架构
我们可以将RebornDB想象成一个黑盒,像一个单节点的Redis服务器一样用任何现有的Redis客户端去和它通信。下面的图片展示了RebornDB的架构。
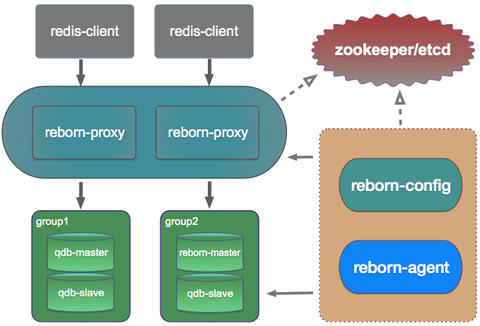
RebornDB有以下组件:reborn-proxy, backend store, coordinator, reborn-config, and reborn-agent.
reborn-proxy为客户端提供单一的外部服务。任何redis客户端都能连接到任一reborn-proxy并运行命令。
reborn-proxy用RESP解析来自客户端的命令,将其分发至对应的后端存储,接收到后端存储的答复并返回客户端。
Reborn-proxy是无状态的,意思是说你可以很容易的水平扩展redis-proxy来处理更多的服务请求。
我们可以有许多的Reborn-proxy,在分布式系统设计的时候怎么让客户端发现它们是另一个主题,但是我们不会在这里深入探讨这个问题,一些实用的方法是使用DNS,LVS,HAProxy等等。
后端存储器是reborn-server(一个修改的redis版本)或者QDB。我们引入一个概念叫做组(group)来管理一个或者多个后端存储。一个组(group)必须有一个主节点和零个、一个或者多个从节点形成复制拓扑结构。
我们将整个数据集分成1024个slots(我们用hash(key)24来决定这个key属于哪个slot),并且将不同的slot保存到不同的组。如果你想重新切分数据,你可以增加一个新的组并让RebornDB从另一个组迁移一个slot的所有数据到新的组。
我们也可以让不同的组采用不同的后端存储器。例如:我们希望group1来保存热点数据,group2来保存大量的冷数据,那么我们就能使用reborn-server构成group1,QDB构成group2.Reborn-server比QDB快很多,因此我们能够保证热点数据的读写性能。
我们使用zookeeper或者etcd作为协调服务器,当我们需要做一些写操作的时候,例如重新切分,故障转移等,它们会协调所有的服务。
所有RebornDB的信息都被保存在协调器中,例如关键路由规则,reborn-proxy可以根据它将命令正确的分发至后端存储器。
Reborn-config是一个管理工具,我们可以使用它增加或删除组,例如增加或删除组中的存储,从一个组迁移数据至另一个组等等。
如果我们想要改变RebornDB集群的信息,就必须使用Reborn-config。例如:我们不能直接使用“SLAVE NO ONE”命令将后端存储器提升为主节点,而必须使用“reborn-config server promote groupid server”我们必须不仅仅改变组内的复制拓扑结构,而且要更新协调器中的信息,而这些只有Reborn-config能够做到。
Reborn-config也提供了一个网站服务,因此你可以很容易的管理RebornDB,如果需要更多的控制,你可以使用它的HTTP RESTFUL API。
Reborn-agent是一个高可用组件。你可以用它启动和停止应用(reborn-config, qdb-server, reborn-server, reborn-proxy)。我们将在接下来的高可用部分详细讨论。
重新切分(Resharding)
RebornDB支持动态的重新切分数据。我们是怎么做到的呢?
正如我们上面说的,我们将整个数据集分成1024个slots,并且将不同的slot保存到不同的组。当我们新增加一个组的时候,我们会将一些slots从旧的组迁移到新组中。在重新切分过程中我们将它叫做迁移。在RebornDB中最小的迁移单元是slot。
让我们从下面的一个简单的例子开始:
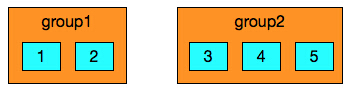
我们有两个组,group1有两个slot 1和2,group2有三个slot 3、4、5.现在group2的工作量比较大,我们将会增加group3并将slot5迁移进去。
我们可以使用下面的命令来将slot5从group2迁移至group3。
reborn-config slot migrate 5 2 3
|
(译者注:原文为reborn-config slot migrate 5 5 3有误)
这个命令看起来很简单,但是我们需要在内部做很多工作来保证迁移的安全性。我们必须使用两阶段提交协议(2PC)来告诉reborn-proxy我们将把slot5从group2迁移至group3。待所有reborn-proxy确认并且答复之后,我们将开始迁移操作。

迁移的流程比较简单:从slot5中得到一个key,从group2迁移它的数据至group3,然后删除group2中的key,如此循环。最后group2中就没有slot5的数据而所有slot5的数据都在group3中。
key的迁移是原子性的,因此无论这个key之前是否在group2或者group3中,我们能够确定的是在执行迁移命令之后它是在group3中的。
如果在group2中没有数据是属于slot5的,我们将停止迁移,拓扑结构看起来是下面这个样子:

高可用性(High Availability)
RebornDB使用reborn-agent来提供HA解决方案。
reborn-agent每时每刻都在检查它启动的应用是否是活动的,如果reborn-agent发现一个应用挂掉了,它会重新启动这个应用。
Reborn-agent有点像一个管理员,但是它有更多的特点。
Reborn-agent提供HTTP Restful API方便我们添加或删除需要被动态监控的应用程序。例如:我们能够使用HTTP “/api/start_redis” API来启动一个新的reborn-server,或者“/api/start_proxy” API来启动一个新的reborn-proxy,我们也能够用“/api/stop”来停止一个正在运行的应用并且从目前的监控列表中删除它。
Reborn-agent不仅仅应用于本地应用的监控,同样适用于后台存储的HA。多个Reborn-agent将首先通过协调器选择一个主reborn-agent,它会不断检查后端存储器是否是活动的,如果发现后端存储器宕机了,它就会进行故障转移。如果宕机的后端存储器是一个从节点,reborn-agent将只会在协调器中将它设置为离线,但是如果它是主节点,reborn-agent将会从现有的从节点中选择一个作为主节点并进行故障转移操作。
即将要做的......
尽管RebornDB有许多很棒的特性,我们仍然需要更多的工作去进一步提升它,我们后续可能做这些事情:
- 更好的用户体验:现在运行RebornDB并不是那么容易,我们将要做一系列工作诸如初始化slots、添加服务到group中、分配slots给一个组等等,在未来的工作中,如何降低用户的使用门槛是我们必须要考虑的问题;
- 复制迁移:现在我们迁移是逐个key迁移slot,如果一个slot包含许多数据的话速度就不是很快,使用复制迁移可能会好很多。在上面的例子中,group2首先产生一个快照,group3能够在那个时间点取得所有slot5的数据,之后group3将从group2增量同步变化的数据。当我们发现group3取得了group2中slot5所有变化的数据之后,我们将进行切换,并从group2中删除slot5;
- 精美的仪表板:为了提供更好的用户体验,我们希望通过仪表板控制和监控一切事务。基于P2P的集群:现在RebornDB是一个基于代理的集群解决方案,我们可能重新设计整个架构,之后将使用P2P,就像官方redis集群一样
总结
构建一个分布式Key-value数据库不是一件容易的事情,前方的路还很长,我们现在只是迈出了一小步。
如果你想要用一个像redis的、存储更多数据、支持在分布式系统中动态切分数据的Key-value数据库,RebornDB将是一个不错的选择。
|






