| ����
��ͳ�����ݿ����ϵͳ���������ݶ����ڴ����Ͻ��й��������Գ����������ݿ⣨DRDB:
Disk-Resident Database�����������ݿ���ҪƵ���ط��ʴ������������ݵIJ��������̵Ķ�д�ٶ�ԶԶС��CPU�������ݵ��ٶȣ����Դ������ݿ��ƿ�������ڴ��̶�д�ϡ�
���ڴˣ��ڴ����ݿ�ĸ��������ˡ��ڴ����ݿ�(MMDB:Main Memory
Database��Ҳ���������ݿ�)[1]�����ǽ�����ȫ�����ߴַ����ڴ��н��в��������ݿ����ϵͳ���Բ�ѯ����������������ָ����㷨�����ݽṹ����������ƣ��Ը���Ч��ʹ��CPU���ں��ڴ档����ڴ��̣��ڴ�����ݶ�д�ٶ�Ҫ�߳������������������ݱ������ڴ�����ȴӴ����Ϸ����ܹ���������Ӧ�õ����ܡ�
��ʮ���������ڴ�ķ�չһֱ��ѭĦ������[2]���ڴ�ļ۸�һֱ�½������ڴ������һֱ�����ӡ����ڵ�����������������GB����TB���ڴ涼�ܳ������ڴ�ķ�չʹ���ڴ����ݿ����ʵ�֡�
�����ڴ����ݿ��봫ͳ�Ĵ������ݿ�����ƺͼܹ��϶�����ͬ�����Դ�ͳ�����ݿ��������������ڴ����ݿ⡣�о���Ϊ�Ľ��ڴ����ݿ�������ṹ�����൱����о������������У�Ӱ��ϴ�����������ڵ�T�������ڻ�������(cacheconscious)��CSS/CSB+����Trie-tree��Hash�ȵȡ����ľ��⼸���д����Ե������㷨�����о��ͷ�����Ϊ��һ���Ľ��ڴ����ݿ������㷨������������ܴ��¼�ʵ�Ļ�����
2��T-tree
2.1 T-tree
T-tree�������������Ż�����������[3]��T-tree��һ��һ���ڵ��а������������Ŀ��ƽ���������T-tree�������������ǴӴ�С�����㷨�϶���B-tree����öࡣT-tree�������㷨����������ֵ�ڵ�ǰ�Ľڵ㻹�����ڴ��е������ط���ÿ���ʵ�һ���µ������ڵ㣬�����ķ�Χ����һ�롣

ͼ2-1T-Tree�Ľ��
T-tree��������ʵ�ֹؼ��ֵķ�Χ��ѯ��T-tree��һ������ƽ��Ķ�������AVL��������ÿ���ڵ�洢�˰���ֵ�����һ��ؼ��֡�T-tree���˽ϸߵĽڵ�ռ�ռ���ʣ�����һ�����IJ����㷨�ڸ��ӳ̶Ⱥ�ִ��ʱ����Ҳռ�����ơ�����T-tree������Ϊ�ڴ����ݿ�������Ҫ��һ��������ʽ��
T-tree���������ص㣺1����������������֮�����1��2����һ���洢�ڵ���Ա�������ֵ���������������Ҽ�ֵ�ֱ�Ϊ����ڵ����С������ֵ����������������������Щ��ֵС�ڻ������С��ֵ��һ��¼��ͬ��������ֻ������Щ��ֵ���ڻ��������ֵ�ļ�¼��3��ͬʱӵ�����������Ľڵ㱻��Ϊ�ڲ��ڵ㣬ֻӵ��һ�������Ľڵ㱻��Ϊ��Ҷ�ڵ㣬û�������Ľڵ㱻��ΪҶ�ӣ�4��Ϊ�˱��ֿռ�������ʣ�ÿһ���ڲ��ڵ㶼��Ҫ����һ����С��Ŀ�ļ�ֵ���ɴ˿�֪T-tree��һ��ÿ����㺬�ж���ؼ��ֵ�ƽ���������ÿ���ڵ��ڵĹؼ����������У���������Ҫ�ȸ��ڵ�ؼ���С����������Ҫ�ȸ��ڵ�ؼ��ִ�
������T-tree���ṹ�У�����������Ϣ:
(1)balance(ƽ������)�������ֵ������1��balance=�������߶�-�������߶ȣ�
(2)Left_child_ptr��Right_child_ptr�ֱ��ʾ��ǰ������������������ָ�룻
(3)Max_Item��ʾ������������ɵļ�ֵ���������
(4)Key[0]��K[Max_Item-1]Ϊ����ڴ�ŵĹؼ��֣�
(5)nItem�ǵ�ǰ�ڵ�ʵ�ʴ洢�Ĺؼ��ָ�����
����T-tree������������
(1)��AVL�����ƣ�T-tree���κν������������ĸ߶�֮�����Ϊ1��
(2)��AVL����ͬ��T-tree�Ľ���пɴ洢�����ֵ��������Щ��ֵ��������
(3)T-tree���������������ɵļ�ֵ�����ڸý���е������ֵ�������������ɵļ�ֵ��С�ڸý���е����Ҽ�ֵ��
(4)Ϊ�˱�֤ÿ�������нϸߵĿռ�ռ���ʣ�ÿ���ڲ�����������ļ�ֵ��Ŀ���벻С��ij��ָ����ֵ��ͨ��Ϊ(Max_Item-2)(Max_ItemΪ���������ֵĿ)��
2.2 T-tree�����IJ���
��T-tree��Ϊ������ʽ��Ҫ����������������ң����룬ɾ�������в����ɾ�������Բ���Ϊ����������ֱ�������ֲ��������̡�
2.2.1 ����
T-tree�IJ��������ڶ���������֮ͬ����Ҫ����ÿһ����ϵıȽϲ�����Խ���еĸ���Ԫ��ֵ���������ȼ����Ҫ���ҵ�Ŀ���ֵ�Ƿ�����ڵ�ǰ���������ֵ�����Ҽ�ֵ��ȷ���ķ�Χ�ڣ�����ǵĻ������ڵ�ǰ���ļ�ֵ�б���ʹ�ö��ַ����в��ң����Ŀ���ֵС�ڵ�ǰ���������ֵ�������Ƶ�������ǰ�������ӽ�㣻���Ŀ���ֵ���ڵ�ǰ�������Ҽ�ֵ�������Ƶ�������ǰ�����Һ��ӽ�㡣
2.2.2 ����
T-tree�IJ������Բ���Ϊ������Ӧ�ò��Ҳ�����λĿ���ֵ����λ�ã������²��ҹ���������������㡣������ҳɹ����жϴ˽�����Ƿ����㹻�Ĵ洢�ռ䡣����У���Ŀ���ֵ�������У�����Ŀ���ֵ����˽�㣬Ȼ����е������ֵ���뵽������������(��ʱ�ǵݹ�������)��֮���������������½�㣬������Ŀ���ֵ��Ȼ�����Ŀ���ֵ����������С��ֵ֮��Ĺ�ϵ�����·���Ľ������Ϊ�������ӻ��Һ��ӣ��������м�飬�ж�T-tree��ƽ�������Ƿ��������������ƽ�����Ӳ�������ִ����ת������
2.2.3 ɾ��
T-tree��ɾ������Ҳ���Բ���Ϊ������Ӧ�ò��Ҳ�����λĿ���ֵ���������ʧ�ܣ��������������NΪĿ���ֵ���ڵĽ�㣬���ӽ��N��ɾ��Ŀ���ֵ��ɾ���ڵ��������NΪ�գ���ɾ�����N����������ƽ�����ӽ��м�飬�ж��Ƿ���Ҫִ����ת������������N�еļ�ֵ����������Сֵ�������N��ƽ�����Ӿ����ӽ��N�����������Ƴ����ļ�ֵ�������������Ƴ���Сֵ����䡣
2.3 T-tree����ʵ�ֹؼ�����
ʵ��T-tree������Ҫʵ��T-tree�IJ��ң������ɾ�����������Բ���Ϊ��������T-tree��ά��Ҳ����T-tree����תΪ�ؼ��������ڲ����ɾ����ֵ��������ʧ�⣬��Ҫ����T-tree����ת��ʹ֮���´ﵽƽ�⡣
�ڲ�������£���Ҫ���ζ��������Ŵ��´�����㵽�����·���еĽ����м�飬ֱ�����������������֮һʱ��ֹ��ij�������������������߶���ȣ���ʱ����Ҫִ����ת������ij�������������������ĸ߶�֮�����1����ʱ�Ըý�����ִ��һ����ת�������ɡ�
��ɾ������£����Ƶ���Ҫ���ζ��������ŴӴ�ɾ�����ĸ���㵽�����·���еĽ����м�飬�ڼ������е�����ij���������������߶�֮��Խ��ʱ����Ҫִ��һ����ת����������������ͬ���ǣ�ִ������ת����֮�����̲�����ֹ�����DZ���һֱִ�е���������㡣
�ɴ˿��Կ��������ڲ�����������ֻ��Ҫһ����ת��������ʹT-tree�ָ���ƽ��״̬��������ɾ����������ܻ��������ϵ�������Ӧ��ʹ�߲��㷢����ת�����������Ҫ���ж����ת������
Ϊ�˶�T-tree����ƽ�⣬��Ҫ������ת��������ת��T-tree����ؼ�Ҳ�����ѵĵIJ������������T-tree��ת�ļ�������ת�ɷ�Ϊ��������������ӵ��������IJ��루����ɾ�����������ת��ΪLL��ת��������LR��RR��RL��ת������ʱ�������ɾ�����ơ�
3��CSS/CSB+��
3.1 CSS-trees
3.1.1 Introduction
CSS-trees(Cache-SensitiveSearch Trees),�����ṩ�ȶ��ֲ��Ҹ�ΪѸ�ٵIJ�ѯ�������ֲ����������Ŀռ�[4]���ü�������һ�����ź�������鶥�˴洢һ��Ŀ¼�ṹ���Ҹ�Ŀ¼�ṹ�Ľڵ��С�����cache-line��С��ƥ�䡣����Ŀ¼�ṹ�洢�������ж�����洢�ڲ��ڵ��ָ�룬�ӽڵ��ͨ������ƫ������λ������B+-trees��ͬ��
3.2 FULL CSS-Tree
����һ�ý�����m����ֵ�IJ�ѯ�������������d����ôһֱ��d-1������������һ����ȫ(m+1)-��ѯ��������d��Ҷ�ӽ��������ҷֲ���һ��m=4��ʵ����ͼ3-1��ʾ�����з��������ǽ��������ÿ��������ĸ���ֵ��
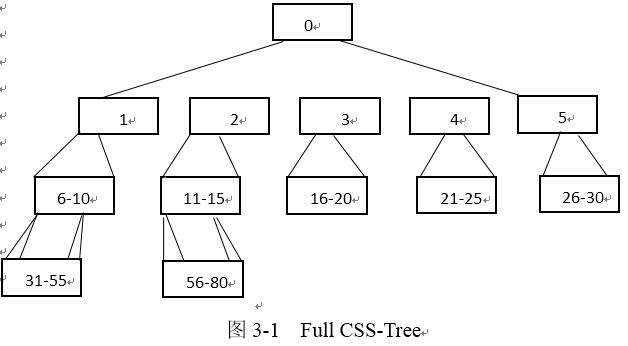
CSS-Tree�Ľ����Դ洢�������У���ͼ3-2��ʾ��
3.2.1 ����FULL CSS-Tree
��һ�����ź�������鹹��һ����Ӧ��Full CSS-Tree�����Ƚ������Ϊ�����֣�������Ҷ�ӽڵ������Ԫ�ؼ佨��ƥ�䡣Ȼ������һ���ڲ��ڵ㿪ʼ�����ڵ�ֱ��������������ֵ��Ϊ�ڵ���ڡ�����ijһЩ�ڲ��ڵ㣬Ҳ������������һ��Ҷ�ӽڵ�����ȣ�������ȫ��ֵ������������ǰ�벿������һ��Ԫ���������Щ��ֵ��������ijЩ�ڲ��ڵ����һЩ���Ƶļ�ֵ������Ҫ��������һ��Full
CSS-Tree���Ǻ����ѵģ�����������һ�������Ѳ�����ʵ���������������ǧ������ֵ�����飬��������Ӧ��Full
CSS-Tree���ѵ�ʱ�䲻��һ�롣
3.2.2 ��ѯFull CSS-Tree
�Ӹ��ڵ㿪ʼ��ÿ�ζ���ѯһ���ڲ��ڵ㣬���ö��ֲ���������������һ����֧���ظ�������Ϊֱ��Ҷ�ӽڵ㣬���Ҷ�ӽڵ����ź�����������ƥ�䡣
�ڽڵ������еIJ�ѯ����if-else���ɣ����ڲ��ڵ���ж��ֲ���ʱ��һֱ�Ƚ���ߵļ�ֵ�Ƿ�С��Ҫ��ѯ�ļ�ֵ�����ҵ���һ����Ҫ��ѯ�ļ�ֵСʱ��ֹͣ�Ƚϲ������ұߵķ�֧������Ҳ���������ֵ���ͽ�������ߵķ�֧�����������Ա�֤���ڽڵ����и��Ƶ�ֵʱ�����ǿ��������и��Ƶļ�ֵ���ҵ�����ߵļ�ֵ��
3.3 LevelCSS-Tree
����ÿ���ڵ���m����¼��Full CSS-Tree�����ϸ��m����ֵ�����еļ�¼���ᱻ���õ�������m=2t�����Ƕ���ÿ���ڵ�ֻ��ֻ��m-1����¼��������һ����֧����m��һ��Level
CSS-Tree����һ����Ӧ��Full CSS-Tree������ȴ���Ϊ��֧������m������m+1��Ȼ�����ÿһ���ڵ㣬��Ҫ��ͬ�������١���NΪһ�����ź��������Ԫ������Ӧ�Ľڵ�����Level
CSS-Tree��logmN�㣬��Full CSS-Tree��logm+1N�㡣ÿ���ڵ��ͬ������t����Full
CSS-tree��t*(1+2/(m+1))������Level CSS-tree���ܵ�ͬ������logmN*t=log2N,��Full
CSS-tree��logm+1N*t*(1+2/(m+1))=log2N*logm+1m*(1+2(m+1)).��ˣ�Level
CSS-Tree�����companion����Full CSS-tree�١���һ���棬Level CSS-Tree��ҪlogmN��cache
accesses������logmN���ڵ㣬��Full CSS-Tree��logm+1N��
����һ��Level CSS-Tree��Full CSS-Tree���ƣ�����Ҳ��������ÿ���ڵ�Ŀղۣ����洢���һ����֧�����ֵ�����������������������ȡ���Ԫ��ֵ����ѯһ��Level
CSS-TreeҲ���ѯFull CSS-Tree���ƣ�Ψһ�IJ�ͬ�����ӽڵ�ƫ�����ļ��㡣
3.4 CSB+-Tree
3.4.1 Introduction
����CSS-Tree��ȶ��ֲ��Һ�T-Trees��ѯ���ܸ��ã������������ھ���֧�ֵ�������Ծ�̬���ݵĹ���������Ƶġ�CSB+-Tree(CacheSensitive
B+-Trees)[4],��B+-Trees�ı��壬�����洢�����ڵ���ӽڵ㣬����ֻ�洢�ڵ�ĵ�һ���ӽڵ�ĵ�ַ�������ӽڵ�ĵ�ַ����ͨ���������ӽڵ��ƫ���������á�����ֻ�洢һ���ӽڵ��ָ�룬cache���������Ǻܸߵģ���B+-Tree���ƣ�CSB+-Tree֧���������¡�
CSB+-Tree�����ֱ��壬�ֶ�CSB+-Tree(SegmentedCSB+-tree)����ȫCSB+-tree(FullCSB+-Tree).�ֶ�CSB+-Tree���ӽڵ�ֶΣ���ͬһ�ε��ӽڵ������洢����ÿ���ڵ��У�ֻ��ÿһ�ε���ʼ��ַ�Żᱻ�洢�����з���ʱ���ֶ�CSB+-Tree���Լ��ٸ��ƿ�������Ϊֻ��һ���ֶ���Ҫ�ƶ�����ȫCSB+-TreeΪ�����ڵ����·���ռ䣬��˼����˷��ѿ�����
3.4.2 CSB+-Tree�ϵIJ���
1�� Bulkload.
����CSB+-Tree����һ����Ч��bulkload��������һ��һ��Ľ��������ṹ��Ϊÿһ��Ҷ�ڵ����ռ䣬�����ڸ߲���Ҫ�Ľڵ����������ò���������Ĵ洢�ռ䡣ͨ�����Ͳ�ÿһ���ڵ�����ֵ����߲�Ľڵ㣬������ÿһ���߲�ڵ�ĵ�һ���ӽڵ�ָ�롣�ظ���������ֱ���߲�ֻ��һ���ڵ㣬������ڵ�Ϊ���ڵ㡣��Ϊͬһ������нڵ��������ģ����Թ���ڵ����������ĸ��Ʋ�����
2�� Search
��ѯCSB+-Tree���ѯB+-Tree���ƣ������ұ߽ڵ�ļ�ֵK��Ҫ��ѯ�ļ�ֵС������һ���ӽڵ�����K��ƫ����������ӽڵ�ĵ�ַ�����磬K�ǽڵ�ĵ�������ֵ��������һ��c����ҵ��ӽڵ㣺child=first_child+3������child��first_child�ǽڵ��ָ�롣
3�� Insertion
��CSB+-Tree�IJ������Ҳ��B+-Tree���ƣ�����Ҫ���Ҽ�ֵ�IJ���ڣ�һ����λ����ӦҶ�ڵ㣬�жϸ�Ҷ�ڵ��Ƿ����㹻�Ŀռ䣬����У��ͼĽ���ֵ�����ڸ�Ҷ�ڵ��У�������Ҫ���Ѹ�Ҷ�ڵ㡣
����Ҫ����Ҷ�ڵ�ʱ�����ڸ��ڵ��Ƿ����㹻�Ŀռ��ż�ֵ�����������������踸�ڵ�p���㹻�Ŀռ䣬��fΪp�ĵ�һ���ӽڵ��ָ�룬gΪfָ��Ľڵ��飬����һ���µı�g����һ���ڵ�Ľڵ���g������g�����еĽڵ㸴�Ƶ�g����g��Ҫ���ѵĽڵ���g���б�Ϊ�����ڵ㣬����p�е�һ���ӽڵ��ָ��f��ʹ��ָ��g�����������·���g��
�����ڵ�û�ж���Ŀռ䲢��������Ҫ����ʱ�������Եø�Ϊ���ӡ���fΪp�е�һ���ڵ��ָ�룬��Ҫ�����µĽڵ���g������g�еĽڵ������g����g�У�p��һ��ļ�ֵת����g���С�Ϊ�˽�p����Ϊp��p��������p�Ľڵ�����Ҫ���һ�����һ�����и��ƣ����ߣ�����ڵ���Ҳ�����ģ�������Ҫ�ݹ�ķ���p�ĸ��ڵ㡣���ڵ����ظ�����������
4��Deletion
ɾ�����������ڲ��������һ��ģ��Ķ�λ������ڲ��Ҽ���ɾ���������������֤50%��occupancy[5]
3.4.3 Segmented CSB+-Tree
����128�ֽڵ�cache-line��CSB+-Tree��ÿ���ڵ������30����ֵ����ζ��ÿ���ڵ������31���ӽڵ㣬��ôһ���ڵ������ɴ�31*128��4KB�����ÿһ�����ѣ���Ҫ����4KB������������һ���ڵ��飬��cache-line������һ���ڵ�Ŀ����������
�Ľڵ�ṹ���Լ��ٷ���ʱ�ĸ��Ʋ��������Խ��ӽڵ�ֶΣ���ÿһ�εĵ�ַ�洢�ڽڵ��У�ÿһ���γ���һ���ڵ��飬ֻ����ͬһ�ε��ӽڵ㱻�����洢����һ�ֿ����ǹ̶�ÿһ���ֶεĴ�С������һ���ֶεĽڵ㣬һ����һ���ֶ����ˣ��ͽ��ڵ���ڵڶ����ֶΡ���һ���ڵ����ڵڶ����ֶΣ�����ֻ�轫�ڶ����ֶεĽڵ㸴�Ƶ��µĶ��У�������ܵ�һ���ֶΣ����µĽڵ����ڵ�һ���ֶ�(�Ѿ�����)��������Ҫ�����ݴӵ�һ���ֶ������ڶ����ֶΣ������������У����������룬���Ѳ��������ݸ��ƽ��������1/2(1/2+3/4)*4KB=2.5KB.��һ�־�������ÿ���ֶεĴ�С��ͬ�����ս��ڵ��Ϊ���Ρ����нڵ����ʱ��Ϊ����ڵ������ķֶδ���һ���µķֶΣ���������Ӧ�ֶεĴ�С�������ַ����У��ϸ���˵ÿ�β���ֻ�漰��һ���ֶ�(�������ڵ�Ҳ��Ҫ���ѣ���ʱ�����ֶζ�Ҫ����)����һ���µĽڵ�ȿ��ܵ���������һ���ֶΣ�һ�����Ѳ��������ݸ�����Ϊ1/2*4KB=2KB�����ַ������Խ�һ���ļ������ݸ��������������ֶε�SegmentedCSB+Tree��ͼ3-3��ʾ(ÿ��Ҷ�ڵ�ֻ��������ֵ)��

�ֶ�CSB+-Tree��֧�����ж����IJ�����������Ƿֶ�CSB+-Tree���ƣ�Ȼ��������ÿ���ڵ���Һ��ӱ���Ƿֶε�CSB+-Tree�Ŀ�������Ϊ��Ҫ�ҵ��������ڵķֶΡ�
3.4.4 FULLCSB+-Tree
��FULLCSB+-Tree�У��ڵ���ѵĿ�����CSB+-TreeС����CSB+-Tree�У����ڵ����ʱ����Ҫ���ڵ����������Ƶ��µ����У�����FullCSB+-Tree�У�ֻ����ʽڵ����һ�롣��������ת�Ʋ�����Դ��ַ��Ŀ�ĵ�ַ�д�Ľ��棬���ʵ�cache-line����Ŀ������s�ڡ�FULLCSB+-Tree�ڷ����ϵ�ƽ��ʱ�俪����0.5s����CSB+-Tree��ʱ2s��
3.5 ʱ��ռ����
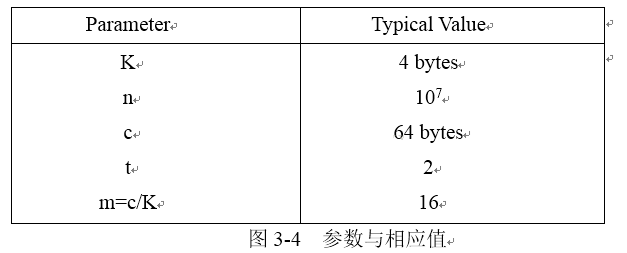
�ٶ���ֵ���ӽڵ�ָ�롢Ԫ��ID������ͬ�Ŀռ��СK��nΪҶ�ڵ�����cΪcache-line���ֽ�����tΪ�ֶ�CSB+-Tree�ķֶ�����ÿ���ڵ�IJ�ֵΪm������m=c/K���ٶ��ڵ��С��cache-line��ͬ����������������Ӧ��ֵ��ͼ3-4��ʾ��
ͼ3-5��ʾ�˸��ַ������֧���ӡ���ֵ��������cacheδ��������ÿ���ڵ���������ıȽϡ�B+-Tree�ķ�֧���ӱ�CSS-TreeС����CSB+-Tree�洢���ӽڵ�ָ���٣�����ķ�֧������CSS-Tree��������ÿ��������cacheδ���д�����һ�����ڵ�ķ�֧����Խ��cacheδ���д�����Ӧ��ԽС����CSB+-Treeÿ����һ���ֶΣ���֧���Ӿͻ����2������������Ҫһ�������洢�ӽڵ�ָ�룬��һ�������洢�����ֶεĴ�С��һ����ԣ�B+-Tree�нڵ��70%�ռ������ģ���Ҫ��Ӧ�ĵ�����֧���Ӵ�С��[6]
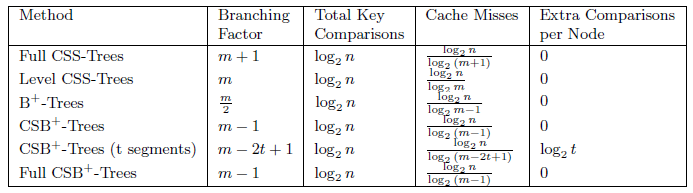
ͼ 3-5 CSB+-Tree��ѯʱ�����
ͼ3-6��ʾ���ڷ���ʱԤ��Ҫ���ʵ�cache-line�������ڸ���ʱԴ��ַ��Ŀ�ĵ�ַ�н��棬����FullCSB+-Tree�������ĿС�����ѿ����Dz�������ܿ�����һ���֣���һ�����Ƕ�λ��Ҷ�ӽڵ�����IJ�ѯ���������ѿ�����Զ�����������ȣ��������ڴ�����ķ��Ѷ�������Ҷ�ڵ㡣Ȼ���������Ĺ�ģԽ��Խ��ʱ����Ӧ�IJ�ѯ�����Ŀ���Ҳ������CSB+-Tree�ķ��ѿ�����B+-Tree���Dz���������ܿ����������Ĺ�ģ�йء�

ͼ3-7 ��ʾ�˲�ͬ�㷨�Ŀռ����ٶ����нڵ�70%�Ŀռ�������[6]���ҷֱ�����ڲ��ڵ��Ҷ�ڵ�Ŀռ��С���ٶ�ÿ��Ҷ�ڵ���2���ֵܽڵ�ָ�롣�ڲ��ڵ�ռ��С����Ҷ�ڵ�ռ����1/(q-1)(qΪ��֧����),���ﲻ�Ƚ�CSS-Tree����ΪCSS-Tree�����ܲ�������

4 Trie-tree����
4.1 Trie-tree
Trie-Tree[7]�ֳƵ��ʲ��������������һ�����νṹ����һ�ֹ�ϣ���ı��֡�����Ӧ��������ͳ�ƺ�����������ַ����������������ַ����������Ծ�������������ϵͳ�����ı���Ƶͳ�ơ������ŵ��ǣ�����ȵؼ�����ν���ַ����Ƚϣ���ѯЧ�ʱȹ�ϣ���ߡ�
4.1.1 Trie-tree����
�����������������ʣ�
1�����ڵ㲻�����ַ��������ڵ�����ÿһ���ڵ㶼ֻ����һ���ַ�
2���Ӹ��ڵ㵽ijһ�ڵ㣬·���Ͼ����ĵ��ַ�����������Ϊ�Ľڵ��Ӧ���ַ�����
3��ÿ���ڵ�������ӽڵ�������ַ�������ͬ��
��ͼ4-1 tire-tree
4.1.2 Trie���Ļ���ʵ��
��ĸ���IJ��롢ɾ���Ͳ��Ҷ��dz�����һ��һ��ѭ�����ɣ�����i��ѭ���ҵ�ǰi����ĸ����Ӧ��������Ȼ�������Ӧ�IJ�����ʵ�������ĸ������������������鱣�棨��̬�����ڴ棩���ɣ���ȻҲ���Կ���̬��ָ�����ͣ���̬�����ڴ棩�����ڽ��Զ��ӵ�ָ��һ�������ַ�����
1����ÿ����㿪һ����ĸ����С�����飬��Ӧ���±��Ƕ�������ʾ����ĸ����������������Ӷ�Ӧ�ڴ������ϵ�λ�ã�����ţ�
2����ÿ������һ����������һ��˳���¼ÿ��������˭��
3��ʹ����������ֵܱ�ʾ����¼�������
���ַ����������ص㡣��һ����ʵ�֣���ʵ�ʵĿռ�Ҫ��ϴڶ��֣�����ʵ�֣��ռ�Ҫ����Խ�С�����ȽϷ�ʱ�������֣��ռ�Ҫ����С������Է�ʱ�Ҳ���д��
4.1.2.1 ʵ�ַ���
�����ֵ�[8]��Ŀ�ķ���Ϊ��
1) �Ӹ���㿪ʼһ��������
2) ȡ��Ҫ���ҹؼ��ʵĵ�һ����ĸ�������ݸ���ĸѡ���Ӧ��������ת���������������м�����
3) ����Ӧ�������ϣ�ȡ��Ҫ���ҹؼ��ʵĵڶ�����ĸ,����һ��ѡ���Ӧ���������м�����
4) �������̡���
5) ��ij����㴦���ؼ��ʵ�������ĸ�ѱ�ȡ�������ȡ���ڸý���ϵ���Ϣ������ɲ��ҡ�
�����������ƴ���
4.1.2.2 Trieԭ��
Trie�ĺ���˼���ǿռ任ʱ�䡣�����ַ����Ĺ���ǰ�����Ͳ�ѯʱ��Ŀ����Դﵽ���Ч�ʵ�Ŀ�ġ�
4.1.3 Trie���ĸ�ʵ��Double-Array ʵ��
���Բ���˫���飨Double-Array��ʵ��,��ͼ1.3������˫������Դ���С�ڴ�ʹ����������ʵ��
�������飬һ����base[]����һ����check[]���������±�Ϊi�����base[i],
check[i]��Ϊ0����ʾ��λ��Ϊ�ա����base[i]Ϊ��ֵ����ʾ��״̬Ϊ��ֹ̬���������check[i]��ʾ��״̬��ǰһ״̬��
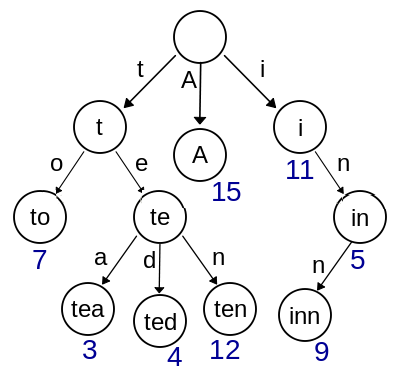
���� 1. ���������ַ� c,��״̬ s ת�Ƶ�״̬ t,˫�����ֵ���������������(ͼ4-2):
check[base[s] + c] = s
base[s] + c = t

�Ӷ���1�У������ܵõ������㷨�����ڸ�����״̬ s �������ַ� c ��
t := base[s] + c; if check[t] = s then next state := t else fail endif
����֪��˫�����ʵ�ַ����ǵ�״̬����ת��ʱ�ŷ���ռ����״̬������Ա���Ϊֻ������Ҫת�Ƶ�״̬�Ŀռ䡣��������������������ʱ�ٽ��е�����ʹ����
base ֵ�����������������ֵ���ֻӰ�쵱ǰ�ڵ���һ��ڵ���ط��䣬��Ϊ���нڵ�ĵ�ַ�����ǿ� base
����ָ������ʼ�±��������ġ�����IJ�����������ij�ַ���ͷ�� base ֵΪi���ڶ����ַ����ַ�����������Ϊc1,
c2, c3��cn����϶�Ҫ����base[i+c1], check[i+c1], base[i+c2],
check[i+c2], base[i+c3], check[i+c3]��base[i+cn],check[i+cn]��Ϊ0��
ͼ4-3 Double Array ʵ��
���裬Tire����n���ڵ㣬�ַ�����СΪm����DATrie�Ŀռ��С��n+cm��c��������Trieϡ��̶ȵ�һ��ϵ��������·�������Ŀռ��С��nm��
ע�⣬����ĸ��Ӷȶ��ǰ������㷨��offline algorithm������ģ�������ʱ�Ѿ��õ������ʿ⡣�����㷨��online
algorithm���Ŀռ临�ӶȻ��͵��ʳ��ֵ�˳���йأ�Խ����ĵ���˳��ռ�ռ��ԽС��
�����㷨�ĸ��ӶȺͱ����ҵ��ַ���������صģ�������ӶȺͶ�·��������һ���ġ�
�����㷨�У���������ط�������������Ҫ������ɨ���ӽڵ��ʱ�临�Ӷȣ�������baseֵȷ�����㷨���Ӷȡ�����������Ƕ����ñ����㷨��forѭ��ɨ�裩���Dz����㷨ʱ�临�Ӷ���O(nm
+ cm2)����
ʵ�ʱ�������У�DATrie�����Ѷȴ����·����������Ҫ��״̬�ı�ʾ�������ṹ�������������±����������
�и��ط���Ҫע����ǣ�baseֵ������ʾ��ʼƫ������������ʾ��״̬Ϊ��ֹ̬�������ڲ�����baseֵʱ��Ҫ��֤�鵽��ֵ��������
�磺��Trie״̬�£�����dʱ����Ϊ��һ���յ�ַ��1�����Եõ�base=1-4=-3������base�����ĺ���ͱ��ƻ��ˡ�
4.1.4 Trie����Ӧ��
Trie��һ�ַdz���Ч�����ݽṹ�����д�����Ӧ��ʵ����
��1���ַ�������
���Ƚ���֪��һЩ�ַ������ֵ䣩���й���Ϣ���浽trie�����������һЩδ֪�ַ����Ƿ���ֹ����߳���Ƶ�ʡ����磺 1������N��������ɵ���ʱ����Լ�һƪȫ��СдӢ����д�����£����㰴������ֵ�˳��д�����в�����ʱ��е����ʡ� 2������һ���ʵ䣬���еĵ���Ϊ�������ʡ����ʾ�ΪСд��ĸ���ٸ���һ���ı����ı���ÿһ��Ҳ��Сд��ĸ���ɡ��ж��ı����Ƿ����κβ������ʡ����磬��rob�Dz������ʣ���ô�ı�problem���в������ʡ�
��2���ַ��������ǰ
Trie�����ö���ַ����Ĺ���ǰ����ʡ�洢�ռ䣬��֮�������ǰѴ����ַ����洢��һ��trie����ʱ�����ǿ��Կ��ٵõ�ijЩ�ַ����Ĺ���ǰ�� ���磺����N��СдӢ����ĸ�����Լ�Q��ѯ�ʣ���ѯ��ij�������������ǰ�ij����Ƕ��٣� ������������ȶ����еĴ��������Ӧ����ĸ������ʱ���֣������������������ǰ�ij��ȼ��������ڽ��Ĺ������ȸ��������ǣ������ת��Ϊ�����ߣ�Offline��������������ȣ�LeastCommon
Ancestor�����LCA�����⡣ �����������������ͬ����һ���������⣬���������漸�ַ����� 1�����ò��鼯��Disjoint Set�������Բ��ò��þ����Tarjan�㷨�� 2�������ĸ����ŷ�����У�Euler Sequence���Ϳ���תΪ�������Сֵ��ѯ��Range
Minimum Query�����RMQ������
��3������
Trie����һ�ö������ֻҪ��������������������Ӧ���ַ������ǰ��ֵ�������Ľ�������磺����N��������ͬ�Ľ���һ�����ʹ��ɵ�Ӣ���������㽫���ǰ��ֵ����С�������������
��4����Ϊ�������ݽṹ���㷨�ĸ����ṹ���������AC�Զ�����
4.1.5 Trie�����Ӷȷ���
��1�����롢���ҵ�ʱ�临�ӶȾ�ΪO(N)������NΪ�ַ������ȡ� ��2���ռ临�Ӷ���26^n����ģ��dz��Ӵɲ���˫����ʵ�ָ��ƣ���
4.1.6 �ܽ�
Trie����һ�ַdz���Ҫ�����ݽṹ��������Ϣ�������ַ���ƥ��������й㷺��Ӧ�ã�ͬʱ����Ҳ�Ǻܶ��㷨�������ݽṹ�Ļ������������AC�Զ����ȡ�
4.2 TrieMemory
Trie Memory[9]��һ�����ڴ��д洢�ͼ�����Ϣ�ķ�ʽ�����ַ�ʽ���ŵ��Ƿ����ٶȿ죬��������洢��Ϣ���ŵ㣬��Ҫ��ȱ���Ǵ洢�ռ������ʺܵ͡�
4.2.1 ������Trie Memoryģ��
����������Ҫ����һϵ�еĵ��ʼ��ϣ���Щ��������ĸ��ɵ����С���Щ���������и��ָ����ij��ȣ����DZ����ס������Щ��ĸ��ɵ�������������������С��ܵ���˵��������Ҫ�ж�һ�������Dz���������ϵij�Ա�� �տ�ʼtrie������register��ɵ�һ�����ϣ�����֮�������register��һ���Ǧ���һ���Ǧģ�ÿһ��register����cell���洢������ĸ�����������Ҫ�洢��space���Ļ���ÿ��register����ӵ��27��cell�� ÿһ��cell���пռ����洢����register���ڴ��еĵ�ַ��trie�е�cell��û�������洢��Ϣ��ͨ����������register
���ĵ�ַ��Ϣ��һ��cell��������˷�register ����register��ַ��������ʾ�洢����Ϣ����Щ��Ϣ���������cell�����ƣ���A����ʾA
cell,��B����ʾB cell����һ��register�ĵ�ַ�������С� ������һ������(ͼ2.1)��˵����Ϊ�������Ӽ�Щ������ʹ����ĸ����ǰ5���ַ�����ʾ���塣Ȼ���è���ʾ��space��������������洢DAB,BAD,BADE,BE,BED,BEAD,CAB,CAD��A����������ͼ��˵���������̡���ͼ��ÿһ�д���һ��register��ÿ��register��6��cell,���һ�д��������������register����portal
register,�����ǽ���ϵͳ�ڴ��ͨ��������������⣬Ҳ������register��һ���ġ�����register�DZ�ŵġ�register
������ѡ�����ǡ��տ�ʼ��ʱ�� register ����register 2��

ͼ4-4 ����Tire Memoryģ��
Ϊ�˴洢DAB�����������ַ��2������portal register��D ��Ԫ��Ȼ�������ƶ���register
2Ȼ�������ַ��3����A��Ԫ��Ȼ�����ǽ��뵽register 3��ѵ�ַ��4�����뵥Ԫ��B����������ƶ���register
4 ���Ұѵ�ַ��1�����먌��Ԫ��������ֹ����������DAB�洢������Ȼ������ת���ڶ�������BAD�������ַ��5������portal
register��B��Ԫ������ʾ��ĸB��Ȼ��register 5��A��Ԫ��д���ַ��6�����ٵ�register
6��D��Ԫ��д���ַ��7�������register 7�Ĩ���Ԫ��д���ַ��1���������ǿ�ʼ�洢BADEʱ�����Ƿ���B,A,D�Ѿ���trie���ˣ�������������Ѿ����ڵ�BAD��·����register
7Ȼ�������ַ��8������Ԫ��E��ȥ��Ȼ��ѵ�ַ��1������register 8�Ĩ���Ԫ��
4.2.2 Register������
�ڸղ��ᵽ�Ľṹ�����ǿ���register��Ϊ4�����ͣ� 1����(address) register��ָ����һ���洢��Ϣ�ĵ�ַ 2����(deletion) register 3����(next) register����һ����Ҫ�洢����Ϣ(�ڿ��ڴ��У�����portal register) 4����(exterior)���ͦ�������register�л�û�н��ܴ洢��Ϣ����û�б�ָ��Ϊ��һ���洢λ�õ�register�� 5����(occupied)���ͦ��Ǵ�����Ϣ��register
4.2.3 Trie�Ķ���д
�����������е�register�г��˦ֶ���trie�У��洢�Ͷ�ȡ���������ܹ����Ĺ�ƽ�Ķ������¡�
4.2.3.1 ���
1���ѵ�i�������ַ�������һ��register������ǵ�һ���ַ�������portal register 2��ѡ���Ӧ�ַ����ĵ�cell,�����i�������ַ�����ĸ���ĵ�j���ַ���ѡ���j��cell�� 3��������Ե�i����Ԫ������ 4�������������ʹ��register ���� a�� ͨ����register������Ͷ�䵽���ӵ�ͷ���������Ϳ��Դ洢��Ϣ�� b)Ͷ��Ӧ�register������ͷ��������������һ����next��register(��) c)������еĴӦͷ�����������ָ���register�� 5�����Դ�ڵ�j��cell������ָ��� ��register�Ļ����ƶ����Ǹ�registerȥ�� a�� ����ǵ�һ��register���������һ���洢���ϵij�Ա(��������)�� b���������register 1�Ļ���i��1����ת���ڶ���ȥ��
4.2.3.2 ������
ʹ����ͬ�����̣����Dz�Ҫʹ��Ͷ�䣬��ҪͶ���κι�ϵ���������ָ��register 1������������Ǵ洢���ϵ�һ����Ա������κε������ָ���register,���仰˵����������Ǵ洢���ϵij�Ա��
5 HASH����
HASH���ǰѹؼ���ֱ��ӳ��Ϊ�洢��ַ���ﵽ����Ѱַ��Ŀ�ģ���Addr=H(key)������keyΪ�ؼ��ʣ�HΪ��ϣ��������Ҫ�����¼��ֳ��õĹ�ϣ������ 1)����������(DivisionMethod)��H(key)=keyMOD p��pһ��Ϊ������ 2)�������(RandomMethod)��H(key)=random(key)��randomΪ��������� 3)ƽ��ȡ�з�(MidsquareMethod)�� HASH�����ṹ����Ҫ����Ĵ洢�ռ䣬�����ܹ���O(1)��ʱ�临�Ӷ���ȷ��λ�������ҵ����ݣ����������ݿ��е����ݲ���ʱ������Ż�����С��Hash�����ṹ���������ŵ��ڴ������ݿ��й㷺�����á��������õ��о����Ⱥ�չ��������Ͱ��ϣ(chainedbucket
hash)[10]������չ��ϣ(extendible hash)[11]�����Թ�ϣ(linearhash)[12]�����������Թ�ϣ(modified
linear hash)[13]��������Щ��ϣ�㷨��Ȼ����ڴ����ݿ�����������Ż��������봫ͳ���ݿ������õĹ�ϣ�㷨û�����Բ�ͬ������2007�꣬KennethA.
Ross����˻����ִ���������HashԤȡ�㷨[14]��SIMDָ����뵽Hash�㷨�У����������ڴ������ĽǶȸĽ��˹�ϣ�㷨������������֯��Ч�ʡ�
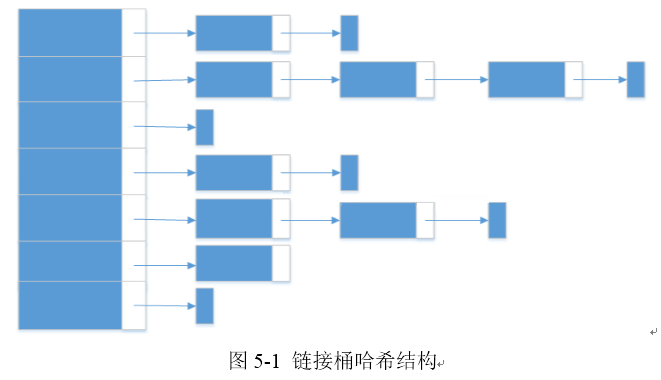
5.1 ����Ͱ��ϣ
����Ͱ��ϣ��ͼ5-1����һ����̬�Ľṹ���������ڴ���������С���Ϊ���Ǿ�̬�ṹ�����ö����ݽ�������֯���������ٶȺܿ졣����Ҳ������ȱ�ݣ���Զ�̬���ݣ����Եò������ˣ���Ϊ����Ͱ��ϣ������ʹ��֮ǰ֪����ϣ���Ĵ�С������ǡǡ����Ԥ�⡣���Ԥ��ı���С��С�������ܻ����Ӱ�죻������ռ��˷ѽ�Ϊ���ء��������£���ֻ��һЩ�ռ���˷ѣ��������ָ����һ��Ͱ��ָ�롣
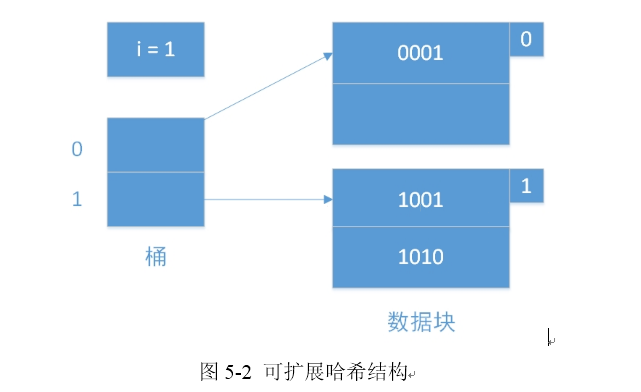
5.2 ����չ��ϣ
����չ��ϣ��ͼ5-2��������Ŀ¼�ļ��ĸ�����ÿ������������Ķ�̬��ϣ������˿˷�������Ͱ��ϣ��ȱ�ݣ����ϣ����С����ҪԤ��֪����һ����ϣ�ڵ�����������ڵ��������ʱ�������Ϊ�����ڵ㡣Ŀ¼��2��ָ������������һ���ڵ�װ�����ҵ�����һ���ض���Ŀ¼��СĿ¼�ͻᱶ������ϣ����Ϊÿ��������һ��Kλ�Ķ��������У�Ͱ����������ʹ�ô����е�һλ�������һλ���������λ[]�����ǿ���չ��ϣ��һ������������һ���ڵ㶼������Ŀ¼�ķ��ѣ�����ϣ�����������ʱ��Ŀ¼�ܿ��������ĺܾ�
5.3 ���Թ�ϣ
���Թ�ϣ��ͼ5-3��Ҳʹ�ö�̬�Ĺ�ϣ��������ͬ����չ��ϣ�нϴ������Թ�ϣѡ��Ͱ������ʹ�洢���ƽ����¼������������һ���̶��ı��������ҹ�ϣͰ�����ǿ��Է��ѣ�����������顣������ļ�¼û�ж�Ӧ��Ͱ�������ϣֵ��λ��Ϊ0���ٴβ��룬����ֱ�Ӳ����ӦͰ����������С�����¼�����������ﵽһ����ֵ������һ��Ͱ���ٷ��䡣����ڿ���չ��ϣ�����Թ�ϣ��������Ϊ����������֯�Ĵ����ʹ��۶���С��ͬʱ������ɢ�в���Ҫ�������Ͱָ���ר��Ŀ¼����ܸ���Ȼ�Ĵ�������Ͱ���������������������ѡ��Ͱ���ѵ�ʱ����

5.4 ���������Թ�ϣ
���������Թ�ϣ��������Թ�ϣ��Ҫ�����ڴ滷����ͨ��ʹ�ø���������ڵ����Ŀ¼����ͨ�����Թ�ϣ�����пսڵ���˷ѿռ䡣���ң�������һ������ķ������DZ�ڵ������ڴ�ӳ��������⣬��Ȼÿ��Ŀ¼����ʱ�Ǹ������Ľڵ㶼Ҫ��������һ��������ڴ�顣���������Թ�ϣ���ø�����չ��ϣһ����Ŀ¼������Ŀ¼Ϊ���������ģ����ӵ��ǵ�����Ŀ�Ľڵ�ͷ����ڴ��Ǵ�һ��������ڴ�ء�����㷨�ڵ���ѵ����ǻ������ܣ�������˵����ع�ϣ����ƽ�����ȱȼ�ش洢�������ܹ���ֱ�ӵĿ���ƽ����������ʱ��[13]��
5.5 HashԤȡ�㷨
HashԤȡ�㷨������Ǽ���ϣֵ����32λ�ij������صض��ڴ滷���������Ż������㷨ʹ�ó˷�ɢ�У����ַ���ʮ���ձ顢�����Ч������Ҫ����������ʸ�����ﵽ��һ�μ�������ϣ������Ŀ��[14]������ִ���������SIMD�ܹ�������ֵ���ϣֵ��ͬ����һ��ָ��У��ﵽ������ָ������Ŀ�ģ���ÿ����������ݳ���ǡ�õ���L2��cacheline����������ܴ��ۣ����ڴ滷���У���������cache�����ܡ� |






