| Spark
Streaming是大规模流式数据处理的新贵,将流式计算分解成一系列短小的批处理作业。本文阐释了Spark
Streaming的架构及编程模型,并结合实践对其核心技术进行了深入的剖析,给出了具体的应用场景及优化方案。
提到Spark Streaming,我们不得不说一下BDAS(Berkeley
Data Analytics Stack),这个伯克利大学提出的关于数据分析的软件栈。从它的视角来看,目前的大数据处理可以分为如以下三个类型。
1.复杂的批量数据处理(batch data processing),通常的时间跨度在数十分钟到数小时之间。
2.基于历史数据的交互式查询(interactive query),通常的时间跨度在数十秒到数分钟之间。
3.基于实时数据流的数据处理(streaming data processing),通常的时间跨度在数百毫秒到数秒之间。
目前已有很多相对成熟的开源软件来处理以上三种情景,我们可以利用MapReduce来进行批量数据处理,可以用Impala来进行交互式查询,对于流式数据处理,我们可以采用Storm。对于大多数互联网公司来说,一般都会同时遇到以上三种情景,那么在使用的过程中这些公司可能会遇到如下的不便。
1.三种情景的输入输出数据无法无缝共享,需要进行格式相互转换。
2.每一个开源软件都需要一个开发和维护团队,提高了成本。
3.在同一个集群中对各个系统协调资源分配比较困难。
BDAS就是以Spark为基础的一套软件栈,利用基于内存的通用计算模型将以上三种情景一网打尽,同时支持Batch、Interactive、Streaming的处理,且兼容支持HDFS和S3等分布式文件系统,可以部署在YARN和Mesos等流行的集群资源管理器之上。BDAS的构架如图1所示,其中Spark可以替代MapReduce进行批处理,利用其基于内存的特点,特别擅长迭代式和交互式数据处理;Shark处理大规模数据的SQL查询,兼容Hive的HQL。本文要重点介绍的Spark
Streaming,在整个BDAS中进行大规模流式处理。
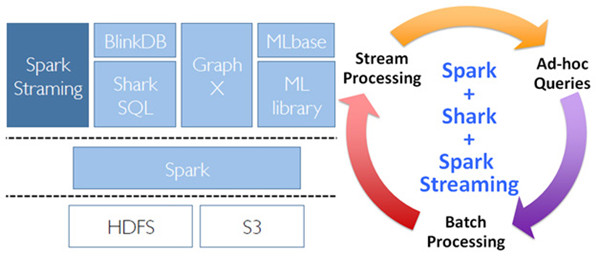
图1 BDAS软件栈
Spark Streaming构架
计算流程:Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark,也就是把Spark
Streaming的输入数据按照batch size(如1秒)分成一段一段的数据(Discretized
Stream),每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将Spark
Streaming中对DStream的Transformation操作变为针对Spark中对RDD的Transformation操作,将RDD经过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行叠加,或者存储到外部设备。图2显示了Spark
Streaming的整个流程。

图2 Spark Streaming构架图
容错性:对于流式计算来说,容错性至关重要。首先我们要明确一下Spark中RDD的容错机制。每一个RDD都是一个不可变的分布式可重算的数据集,其记录着确定性的操作继承关系(lineage),所以只要输入数据是可容错的,那么任意一个RDD的分区(Partition)出错或不可用,都是可以利用原始输入数据通过转换操作而重新算出的。
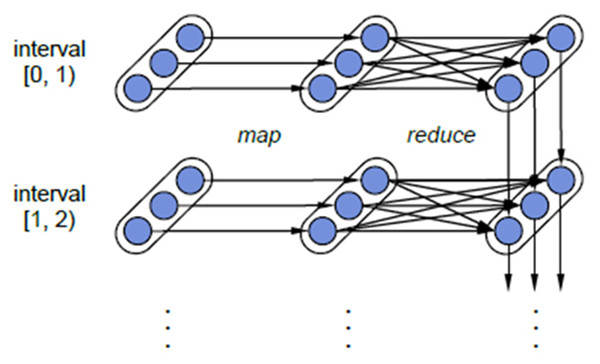
图3 Spark Streaming中RDD的lineage关系图
对于Spark Streaming来说,其RDD的传承关系如图3所示,图中的每一个椭圆形表示一个RDD,椭圆形中的每个圆形代表一个RDD中的一个Partition,图中的每一列的多个RDD表示一个DStream(图中有三个DStream),而每一行最后一个RDD则表示每一个Batch
Size所产生的中间结果RDD。我们可以看到图中的每一个RDD都是通过lineage相连接的,由于Spark
Streaming输入数据可以来自于磁盘,例如HDFS(多份拷贝)或是来自于网络的数据流(Spark Streaming会将网络输入数据的每一个数据流拷贝两份到其他的机器)都能保证容错性。所以RDD中任意的Partition出错,都可以并行地在其他机器上将缺失的Partition计算出来。这个容错恢复方式比连续计算模型(如Storm)的效率更高。
实时性:对于实时性的讨论,会牵涉到流式处理框架的应用场景。Spark Streaming将流式计算分解成多个Spark
Job,对于每一段数据的处理都会经过Spark DAG图分解,以及Spark的任务集的调度过程。对于目前版本的Spark
Streaming而言,其最小的Batch Size的选取在0.5~2秒钟之间(Storm目前最小的延迟是100ms左右),所以Spark
Streaming能够满足除对实时性要求非常高(如高频实时交易)之外的所有流式准实时计算场景。
扩展性与吞吐量:Spark目前在EC2上已能够线性扩展到100个节点(每个节点4Core),可以以数秒的延迟处理6GB/s的数据量(60M
records/s),其吞吐量也比流行的Storm高2~5倍,图4是Berkeley利用WordCount和Grep两个用例所做的测试,在Grep这个测试中,Spark
Streaming中的每个节点的吞吐量是670k records/s,而Storm是115k records/s。
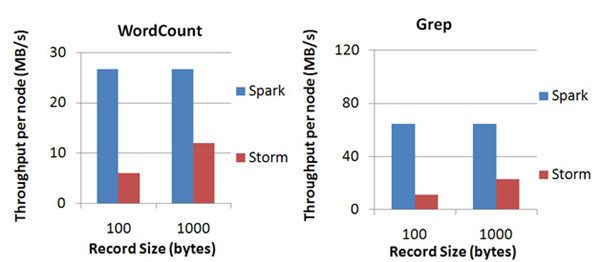
图4 Spark Streaming与Storm吞吐量比较图
Spark Streaming的编程模型
Spark Streaming的编程和Spark的编程如出一辙,对于编程的理解也非常类似。对于Spark来说,编程就是对于RDD的操作;而对于Spark
Streaming来说,就是对DStream的操作。下面将通过一个大家熟悉的WordCount的例子来说明Spark
Streaming中的输入操作、转换操作和输出操作。
Spark Streaming初始化:在开始进行DStream操作之前,需要对Spark
Streaming进行初始化生成StreamingContext。参数中比较重要的是第一个和第三个,第一个参数是指定Spark
Streaming运行的集群地址,而第三个参数是指定Spark Streaming运行时的batch窗口大小。在这个例子中就是将1秒钟的输入数据进行一次Spark
Job处理。
val ssc = new StreamingContext(“Spark://…”, “WordCount”, Seconds(1), [Homes], [Jars]) |
Spark Streaming的输入操作:目前Spark Streaming已支持了丰富的输入接口,大致分为两类:一类是磁盘输入,如以batch
size作为时间间隔监控HDFS文件系统的某个目录,将目录中内容的变化作为Spark Streaming的输入;另一类就是网络流的方式,目前支持Kafka、Flume、Twitter和TCP
socket。在WordCount例子中,假定通过网络socket作为输入流,监听某个特定的端口,最后得出输入DStream(lines)。
val lines = ssc.socketTextStream(“localhost”,8888) |
Spark Streaming的转换操作:与Spark RDD的操作极为类似,Spark
Streaming也就是通过转换操作将一个或多个DStream转换成新的DStream。常用的操作包括map、filter、flatmap和join,以及需要进行shuffle操作的groupByKey/reduceByKey等。在WordCount例子中,我们首先需要将DStream(lines)切分成单词,然后将相同单词的数量进行叠加,
最终得到的wordCounts就是每一个batch size的(单词,数量)中间结果。
val words = lines.flatMap(_.split(“ ”))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _) |
另外,Spark Streaming有特定的窗口操作,窗口操作涉及两个参数:一个是滑动窗口的宽度(Window
Duration);另一个是窗口滑动的频率(Slide Duration),这两个参数必须是batch
size的倍数。例如以过去5秒钟为一个输入窗口,每1秒统计一下WordCount,那么我们会将过去5秒钟的每一秒钟的WordCount都进行统计,然后进行叠加,得出这个窗口中的单词统计。
val wordCounts = words.map(x => (x, 1)).reduceByKeyAndWindow(_ + _, Seconds(5s),seconds(1)) |
但上面这种方式还不够高效。如果我们以增量的方式来计算就更加高效,例如,计算t+4秒这个时刻过去5秒窗口的WordCount,那么我们可以将t+3时刻过去5秒的统计量加上[t+3,t+4]的统计量,在减去[t-2,t-1]的统计量(如图5所示),这种方法可以复用中间三秒的统计量,提高统计的效率。
val wordCounts = words.map(x => (x, 1)).reduceByKeyAndWindow(_ + _, _ - _, Seconds(5s),seconds(1)) |
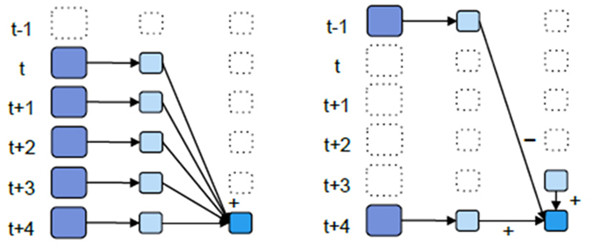
图5 Spark Streaming中滑动窗口的叠加处理和增量处理
Spark Streaming的输入操作:对于输出操作,Spark提供了将数据打印到屏幕及输入到文件中。在WordCount中我们将DStream
wordCounts输入到HDFS文件中。
wordCounts = saveAsHadoopFiles(“WordCount”) |
Spark Streaming启动:经过上述的操作,Spark Streaming还没有进行工作,我们还需要调用Start操作,Spark
Streaming才开始监听相应的端口,然后收取数据,并进行统计。
Spark Streaming案例分析
在互联网应用中,网站流量统计作为一种常用的应用模式,需要在不同粒度上对不同数据进行统计,既有实时性的需求,又需要涉及到聚合、去重、连接等较为复杂的统计需求。传统上,若是使用Hadoop
MapReduce框架,虽然可以容易地实现较为复杂的统计需求,但实时性却无法得到保证;反之若是采用Storm这样的流式框架,实时性虽可以得到保证,但需求的实现复杂度也大大提高了。Spark
Streaming在两者之间找到了一个平衡点,能够以准实时的方式容易地实现较为复杂的统计需求。 下面介绍一下使用Kafka和Spark
Streaming搭建实时流量统计框架。
1.数据暂存:Kafka作为分布式消息队列,既有非常优秀的吞吐量,又有较高的可靠性和扩展性,在这里采用Kafka作为日志传递中间件来接收日志,抓取客户端发送的流量日志,同时接受Spark
Streaming的请求,将流量日志按序发送给Spark Streaming集群。
2.数据处理:将Spark Streaming集群与Kafka集群对接,Spark
Streaming从Kafka集群中获取流量日志并进行处理。Spark Streaming会实时地从Kafka集群中获取数据并将其存储在内部的可用内存空间中。当每一个batch窗口到来时,便对这些数据进行处理。
3.结果存储:为了便于前端展示和页面请求,处理得到的结果将写入到数据库中。
相比于传统的处理框架,Kafka+Spark Streaming的架构有以下几个优点。
1.Spark框架的高效和低延迟保证了Spark Streaming操作的准实时性。
2.利用Spark框架提供的丰富API和高灵活性,可以精简地写出较为复杂的算法。
3.编程模型的高度一致使得上手Spark Streaming相当容易,同时也可以保证业务逻辑在实时处理和批处理上的复用。
在基于Kafka+Spark Streaming的流量统计应用运行过程中,有时会遇到内存不足、GC阻塞等各种问题。下面介绍一下如何对Spark
Streaming应用程序进行调优来减少甚至避免这些问题的影响。
性能调优
优化运行时间
增加并行度。确保使用整个集群的资源,而不是把任务集中在几个特定的节点上。对于包含shuffle的操作,增加其并行度以确保更为充分地使用集群资源。
减少数据序列化、反序列化的负担。Spark Streaming默认将接收到的数据序列化后存储以减少内存的使用。但序列化和反序列化需要更多的CPU时间,因此更加高效的序列化方式(Kryo)和自定义的序列化接口可以更高效地使用CPU。
设置合理的batch窗口。在Spark Streaming中,Job之间有可能存在着依赖关系,后面的Job必须确保前面的Job执行结束后才能提交。若前面的Job执行时间超出了设置的batch窗口,那么后面的Job就无法按时提交,这样就会进一步拖延接下来的Job,造成后续Job的阻塞。因此,设置一个合理的batch窗口确保Job能够在这个batch窗口中结束是必须的。
减少任务提交和分发所带来的负担。通常情况下Akka框架能够高效地确保任务及时分发,但当batch窗口非常小(500ms)时,提交和分发任务的延迟就变得不可接受了。使用Standalone模式和Coarse-grained
Mesos模式通常会比使用Fine-Grained Mesos模式有更小的延迟。
优化内存使用
控制batch size。Spark Streaming会把batch窗口内接收到的所有数据存放在Spark内部的可用内存区域中,因此必须确保当前节点Spark的可用内存至少能够容纳这个batch窗口内所有的数据,否则必须增加新的资源以提高集群的处理能力。
及时清理不再使用的数据。上面说到Spark Streaming会将接收到的数据全部存储于内部的可用内存区域中,因此对于处理过的不再需要的数据应及时清理以确保Spark
Streaming有富余的可用内存空间。通过设置合理的spark.cleaner.ttl时长来及时清理超时的无用数据。
观察及适当调整GC策略。GC会影响Job的正常运行,延长Job的执行时间,引起一系列不可预料的问题。观察GC的运行情况,采取不同的GC策略以进一步减小内存回收对Job运行的影响。
总结
Spark Streaming提供了一套高效、可容错的准实时大规模流式处理框架,它能和批处理及即时查询放在同一个软件栈中,降低学习成本。如果你学会了Spark编程,那么也就学会了Spark
Streaming编程,如果理解了Spark的调度和存储,那么Spark Streaming也类似。对开源软件感兴趣的读者,我们可以一起贡献社区。目前Spark已在Apache孵化器中。按照目前的发展趋势,Spark
Streaming一定将会得到更大范围的使用。 |






