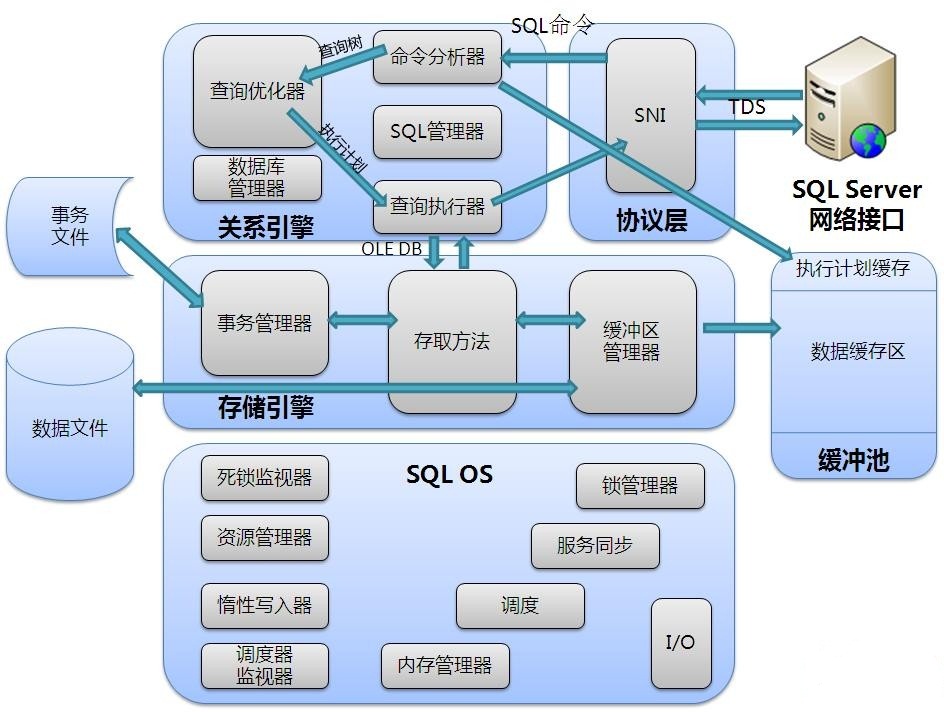
| 执行(Execution)
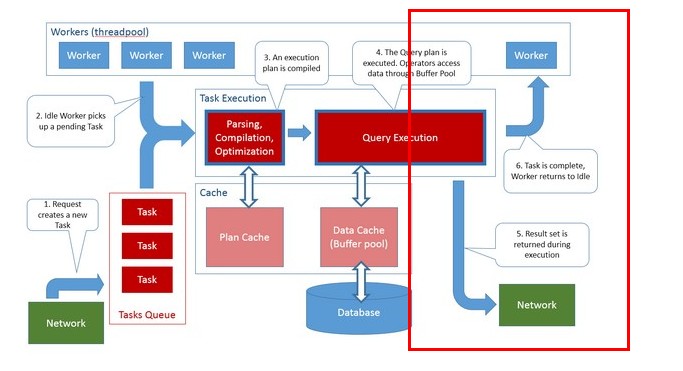
一旦查询优化器选择了一个执行计划,请求(request)就可以开始执行了。执行计划会被翻译成为一棵实际的执行树
每个树节点都是一个操作符,所有操作符都会实现一个有3个方法的抽象接口,分别是open(),
next(), close()
如果阁下是C#程序员或者是JAVA程序员,一定不难理解什么是接口,什么是方法,什么是抽象接口
MSDN里有相关的资料:Showplan 逻辑运算符和物理运算符参考
查询计划是由物理运算符组成的一个树(执行树)
逻辑运算符
逻辑运算符描述了用于处理语句的关系代数操作。 换言之,逻辑运算符从概念上描述了需要执行哪些操作。
物理运算符
物理运算符实施由逻辑运算符描述的操作。 每个物理运算符都是一个执行某项操作的对象或例程。
例如,某些物理运算符可访问表、索引或视图中的列或行。 其他物理运算符执行其他操作,如计算、聚合、数据完整性检查或联接。
物理运算符具有与其关联的开销。
物理运算符初始化、收集数据,然后关闭。 具体来讲,物理运算符可以响应下列三种方法调用:
Init():Init() 方法使物理运算符初始化自身并设置所有需要的数据结构。
尽管一个物理运算符通常只接收一次 Init() 调用,但也可以接收许多次调用。
GetNext():GetNext() 方法使物理运算符获得数据的第一行或后续行。
物理运算符可以不接收 GetNext() 调用,也可以接收许多次调用。
Close():Close() 方法使物理运算符执行某些清除操作,然后关闭。
一个物理运算符只接收一个 Close() 调用。
GetNext() 方法返回一个数据行,它的调用次数作为 ActualRows
显示在使用 SET STATISTICS PROFILE ON 或 SET STATISTICS XML
ON 生成的显示计划输出中。 有关这些 SET 选项的详细信息,请参阅 SET STATISTICS
PROFILE (Transact-SQL) 和 SET STATISTICS XML (Transact-SQL)。
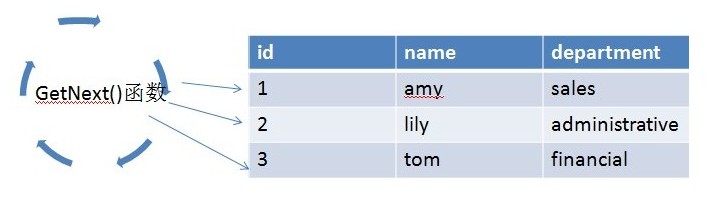
文中说的操作符实际上指的就是物理运算符:三个方法指的是open()=init(),next()=getnext(),close()=close()
每个物理运算符就是调用自己的三个方法
在SQLSERVER执行请求的过程中,执行树的根节点会不断循环的调用open(),然后重复调用next()直到返回false值
最后调用close()。树的根节点的运算符会依次调用他的子节点的同样的运算符,而子节点又会依次调用他的子节点的同样的运算符
一直调用下去。在树的叶子节点一般都会是读取表数据或表索引的物理运算符。而执行树的中间节点一般都是一些实现不同数据操作的运算符
例如:过滤表数据、join连接、对数据排序。那些使用并行的查询会使用一个特别的运算符叫做:Exchange
Oprators(交换操作)
交换操作运算符在执行的过程中会使用多线程(tasks =>
workers),调用每个线程去执行子树的执行计划,
然后聚合这些运算符的输出结果,在这个过程中会使用典型的(多生产者《-》一个消费者模式)。
关于Exchange Oprators(交换操作) 可以参考这篇文章:SQL
Server 2000中的并行处理和执行计划中的位图运算符
我们使用 SET STATISTICS PROFILE ON 就可以看到执行树,下面是一些列的名称,更详细的就不说了,网上有很多资料
NodeId:树节点
Parent:父节点
PhysicalOp:物理运算符
LogicalOp:逻辑运算符

这种执行树的执行模型不单只应用于查询,插入,删除,更新的执行都是同样利用执行树来执行的
插入记录、删除记录、更新记录都会有相应的运算符



一个执行树没有子树的情况

一个执行树具有子树的情况
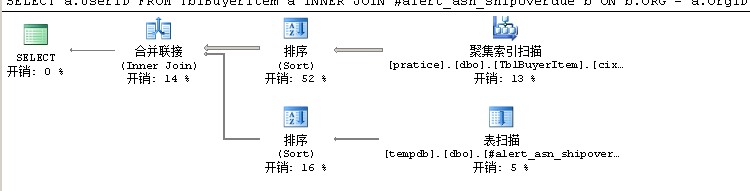

如果执行树具有子树,他的执行方式也是从子树的叶子节点开始执行,一直执行到树的根节点
特别要介绍一下,这些运算符也有停止-继续的行为特性,意思是说除非他们的子节点运算符已经吸收完所有的输入,他们才能产生输入
例如:排序运算符,排序运算符在最初调用next()函数的时候不会返回任何结果因为这时候他的子节点还没有读取完所有数据,
这时候需要停止执行next()函数(每个运算符创建出来就会不停调用next函数),直到他的子节点读取完所有数据他才能对这些数据
进行排序(继续调用next()函数),取出结果集并排序
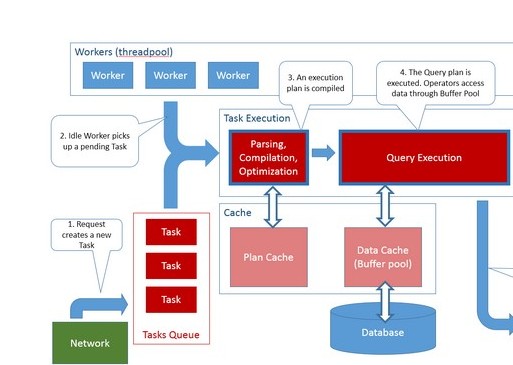
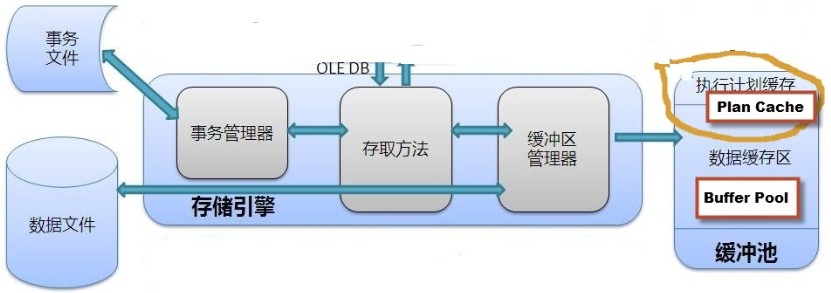
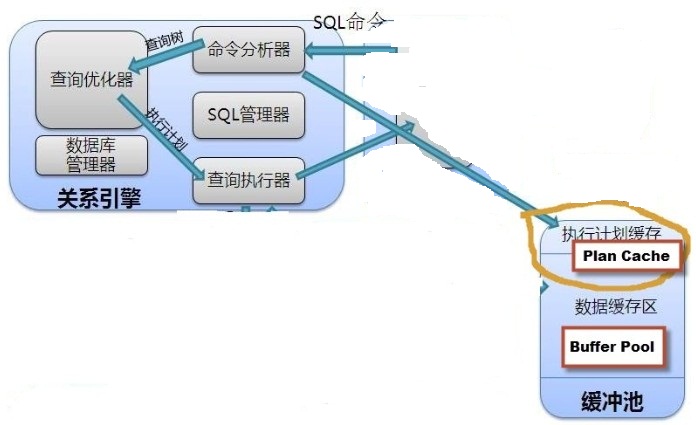
如果数据已经缓存在内存里了,SQLSERVER就不需要去磁盘里取数据,直接在内存里取数据,内存里的这块空间,
SQLSERVER官方术语叫:Buffer pool
而在内存里缓存执行计划的这块空间,SQLSERVER官方术语叫:Plan
Cache
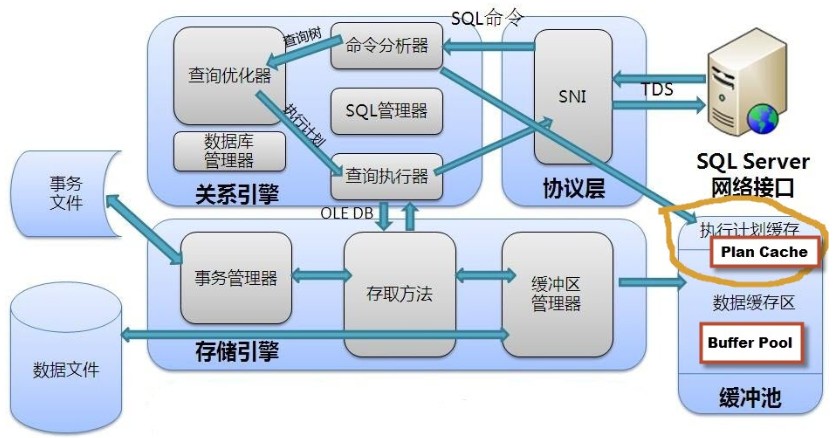
执行模块(模块化)
结果(Results)
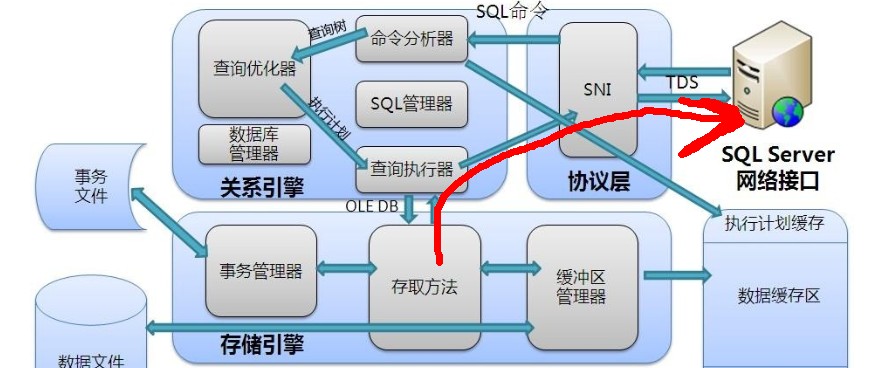
在执行完毕之后,SQLERVER会将结果集返回给客户端应用程序
当执行到执行树的根节点的时候,根节点通常负责将结果集写入到网络缓冲区(network
buffers)
然后将这些结果集发送回客户端。一个完整的结果集还没有创建完毕,一部分的结果首先会存放到中间存储(内存或磁盘)
然后逐段逐段发送给客户端,例如一个SQL语句查询的结果需要返回10条记录,有3条记录已经生成好了,可以返回给客户端了
SQLSERVER首先将这3条记录放入中间存储(内存或磁盘),也可以叫网络缓冲区,等客户端来取走这3条记录,如此类推。
返回结果集给客户端的时候,SQLSERVER用的是网络流控制协议。
如果客户端没有积极地将这些结果集取走(例如调用SqlDataReader.Read())。最终会导致网络流控制组件不得不阻塞
结果集发送端并且会挂起查询的执行。
只有网络流控制组件协调和缓解了网络资源的需求(网络没有阻塞),查询才会恢复,并且继续生成结果集
不知道大家有没有遇到过等待类型:ASYNC_NETWORK_IO的等待
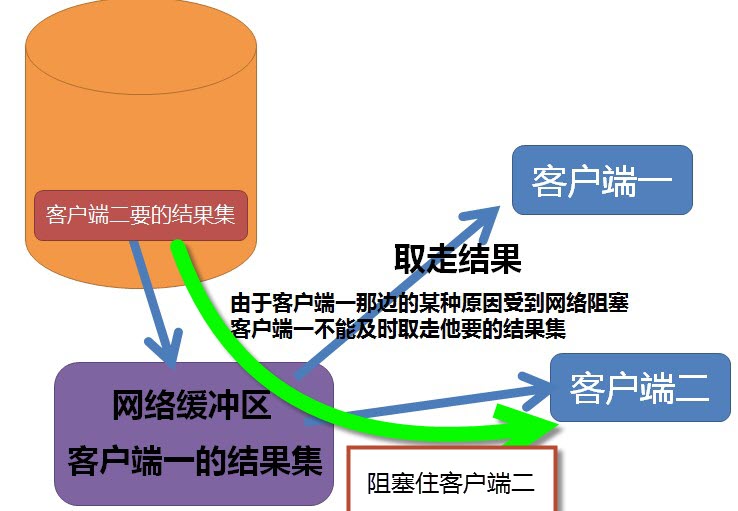
上图里,客户端二就要等待,在SQLSRVER里查询就会显示ASYNC_NETWORK_IO类型的等待
有趣的是,OUTPUT参数的返回,OUTPUT参数的值会被插入到返回给客户端的结果集的网络数据流中。
当请求完成的时候,OUTPUT参数值只能在查询执行的最后写到结果集中,这就是为什麽OUTPUT参数值
只有当所有的结果集都返回了才能检查OUTPUT参数的值
查询执行过程中要赋予的内存(Query Execution Memory
Grant)
一些运算符需要固定的内存去执行他们的工作。排序运算符为了进行排序需要内存去存储输入到排序运算符的数据
Hash join和hash聚合必须建立大型的hash表去执行他们的工作。执行计划知道那些未完成的运算符需要多少内存
根据运算符类型,预估的行记录,运算符必须要处理统计信息提供给他的表中的字段的大小。
那些在执行计划里的运算符所需要的总的内存我们通常称为内存赋予。
试想一下,当非常多的并发查询被执行的时候,因为大量的昂贵的运算符(这些运算符一般都需要很多内存,所以称之为昂贵的)
需要请求内存,在同一时间里面他们能够用尽计算机的内存。
为了阻止这种情况的发生,SQLSERVER使用一种叫“资源信号量”的东西。这个东西能够确保正在执行的查询的总内存分配不会超过
当前计算机中的内存总和。当总的内存分配就快耗尽当前服务器里的可用内存的时候,正在执行的查询必须要等待那些就快执行完毕
的查询去释放他们拥有的内存。
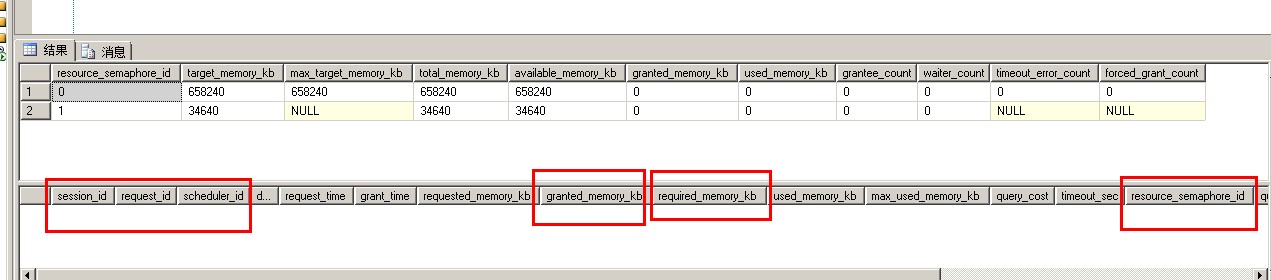
您可以查询sys.dm_exec_query_memory_grants这个DMV视图来获取当前的内存分配(请求的内存,分配了的内存)
当一个查询必须要等待内存的赋予/分配,在SQL PROFILER里可以看到Execution
Warnings 事件类型
Execution Warnings 事件类型指出了当SQL语句或者存储过程执行的过程中的内存分配警告
这个事件类型能够监视必须要等待一秒或更多内存的某些查询,或者获取内存失败的查询
在SQL PROFILER里,一些与内存有关的事件类型
Exchange Spill 事件类型
Sort Warnings 事件类型:排序的时候所需内存不足
Hash Warning 事件类型
相关语句
select * from sys.dm_exec_query_resource_semaphores
select * from sys.dm_exec_query_memory_grants
|

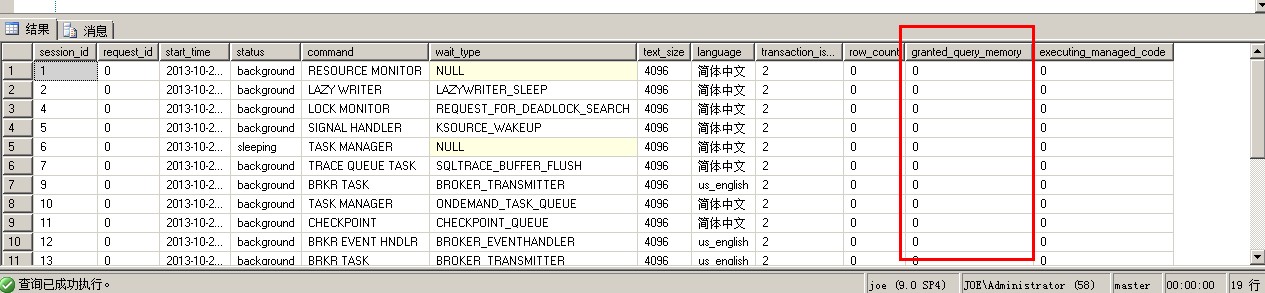
SELECT [session_id],
2 [request_id],
3 [start_time],
4 [status],
5 [command],
6 [wait_type],
7 [text_size],
8 [language] ,
9 [transaction_isolation_level],
10 [row_count],
11 [granted_query_memory],
12 [executing_managed_code]
13 FROM sys.[dm_exec_requests] |
我如何利用这些信息(How can I use all this
information)
上面的信息有可能帮您解决performance troubleshooting
problems(性能问题)
一旦您明白了您的客户端正在发送多个请求到SQLSERVER,SQLSERVER端正在创建多个任务(task)去处理
您发给他的请求,性能的谜题就可以很简单地解决了:很多时候,您的任务不是正在执行(正在占领CPU)就是处于正在等待
每次等待,SQLSERVER都会依靠内部等待统计信息去收集等待的信息(等待什么和等了多久)。
利用收集回来的统计信息去解决性能瓶颈是非常好的方法
附上两张完整的图
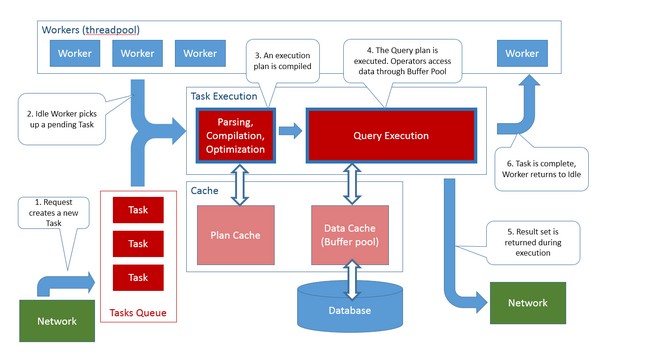
总结
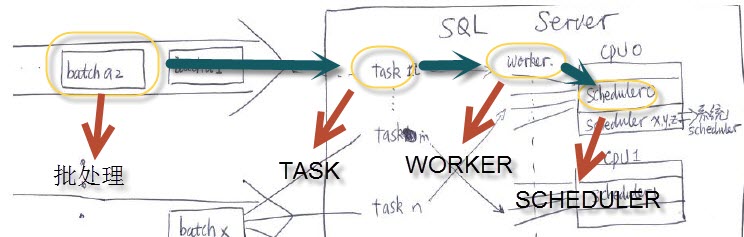
文中好像遗漏了Scheduler
Scheduler
对于每个逻辑CPU,SQLSERVER会有一个scheduler与之对应,在SQL层面上代表CPU对象,
只有拿到scheduler所有权的worker才能在这个逻辑CPU上运行
优化(Optimization)
刚才说到选择一种数据访问路径(执行计划),现在继续说一个请求(request)的生命周期的下一步:优化
在SQLSERVER里面,优化意味着从多个选择条件中选择最佳的数据访问路径。
考虑一下,如果你有一个简单的涉及到两个表的join查询,每个表都有额外的索引,
这里就有4种可选的执行方案,去访问表中的数据
因为有这麽多的可选方案,查询复杂度已经比较高了,如果这时候表中的索引继续增多的话,查询复杂度有可能以指数的方式增长
再加上JOIN联接本来就有三种联接方式:nested loops join、merge
join、hash join
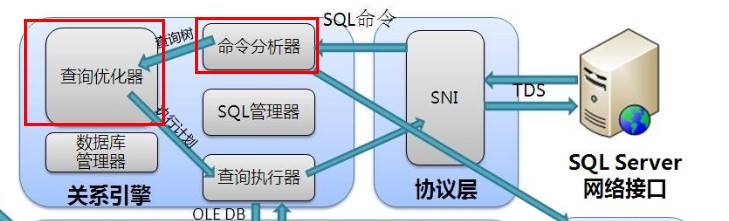
可想而知,优化这个名词在SQLSERVER里是多么重要,SQLSERVER使用一个查询优化器来预估这中间要消耗的时间,IO,CPU
查询优化器会考虑各种执行方案,SQLSERVER会尽力基于每种执行方案的开销去作出评估,然后尽可能选择一个开销最低的
执行方案。SQLSERVER首先会计算在现有的表数据量下各种执行方案各自需要多少的开销。为了选出一个开销最低的执行方案,
SQLSERVER需要知道做联接的每张表的数据量和表里面各个字段的数据的分布,这就需要靠统计信息,
因为统计信息本来就是用来统计这些数据的。另外一个要考虑的因素就是,每种执行方案所需要的CPU消耗和内存消耗
综合以上各种因素,SQLSRVER会在每种执行方案里算出一个cost值
SQLSERVER会在这些执行方案里选出一个cost值最低的执行方案作为执行计划执行
大家看一下,SQLSERVER要对上面各种因素进行考虑,这里考虑是需要时间的,所以为什麽SQLSERVER
需要将执行计划缓存到内存里以便将来继续使用这个执行计划,就是为了节省编译时间
将来同样的请求进入到SQLSERVER,并且这些请求能够在CACHE里找到一个已经编译了和优化了的执行计划
他们就能跳过查询优化器的优化阶段
这里一定要注意:同样的请求进来SQLSERVER的时候,无论CACHE里有没有可以重用的执行计划,SQLSERVER都需要
对请求里的SQL语句进行解析,所以我上面才说:就是为了节省编译时间
而不是 就是为了节省解析/编译时间
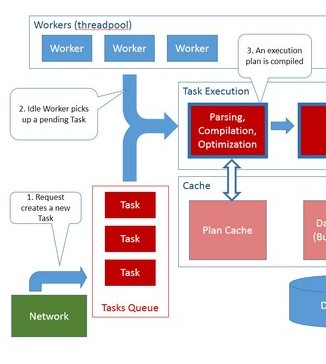
解释和编译模块(模块化)
|









