| cluster配置
1 namenode,4 datanode
namenode: compute-n
datanode: compute-0-1, compute-0-2,
compute-0-3, compute-0-4
安装的版本
Linux 版本
Linux compute-n 2.6.32-38-generic #83-Ubuntu SMP Wed Jan 4 11:12:07 UTC 2012 x86_64 GNU/Linux |
JDK
java version "1.8.0_40"
Java(TM) SE Runtime Environment (build 1.8.0_40-b26)
Java HotSpot(TM) 64-Bit Server VM (build 25.40-b25, mixed mode) |
Hadoop
Hadoop 2.6.0
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r e3496499ecb8d220fba99dc5ed4c99c8f9e33bb1
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using /home/hadoop/hadoop-2.6.0/share/hadoop/common/hadoop-common-2.6.0.jar |
1. 下载Spark和Scala
本人下载的是Spark-2.6.0 和 Scala 2.11.6
spark下载地址 http://spark.apache.org/downloads.html
scala下载地址 http://www.scala-lang.org/download/
2. 解压scala,配置scala的环境变量
tar -zxf scala-2.11.6.tgz</span> |
之后将文件移动到 /usr/lib/scala
mkdir /usr/lib/scala
sudo mv scala-2.11.6 /usr/lib/scala</span> |
将scala移动到其他的机器上去
sudo scp -r scala-2.11.6 hadoop@compute-0-1:/home/hadoop/Downloads/
ssh compute-0-1 |
3. 安装Spark
3.1 解压Spark,移动到对应目录
tar -zxf spark-1.3.1-bin-hadoop2.6.tgz |
拷贝spark文件到 /usr/local/spark

3.2 配置环境变量
进入/etc/profile
JAVA_HOME=/home/hadoop/jdk1.8.0_40
HADOOP_HOME=/home/hadoop/hadoop-2.6.0
SCALA_HOME=/usr/lib/scala/scala-2.11.6/
SPARK_HOME=/usr/local/spark/spark-1.3.1-bin-hadoop2.6l
CLASSPATH=.:$JAVA_HOME/lib.tools.jar
PATH=${SCALA_HOME}/bin:$JAVA_HOME/bin:${SPARK_HOME}
/bin:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export SPARK_HOME SCALA_HOME JAVA_HOME CLASSPATH PATH |
保存退出后,使配置生效
3.3 配置Spark
进入Spark的配置目录conf
cp spark-env.sh.templates spark-env.sh
cp slaves.templates slaves |
修改spark-env.sh文件
export JAVA_HOME=/home/hadoop/jdk1.8.0_40
export SCALA_HOME=/usr/lib/scala/scala-2.11.6/
export SPARK_MASTER_IP=10.119.178.200
export SPARK_WORKER_MEMORY=8G
export HADOOP_CONF_DIR=/home/hadoop/hadoop-2.6.0/etc/hadoop |
修改slaves
compute-0-1
compute-0-2
compute-0-3
compute-0-4 |
4. 拷贝同样的环境到其他的机器
之后进入/usr/local 目录下, 拷贝Spark到其他的机器上,因为直接拷贝到/usr/local不被允许,所以先拷贝到Downloads目录下
sudo scp -r spark hadoop@compute-0-1:/home/hadoop/Downloads/
sudo scp -r spark /usr/local/ |
5.启动Spark
5.1 进入spark安装目录下的sbin文件下
使用以下命令
但是提示以下错误
mkdir: cannot create directory `/usr/local/spark/spark-1.3.1-bin-hadoop2.6/sbin/../logs': Permission denied |
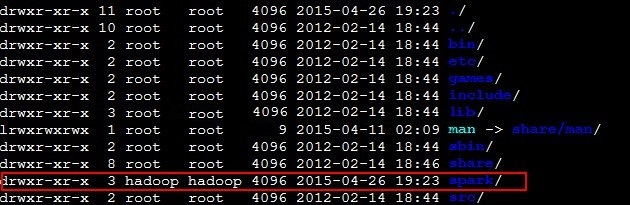
提示权限有问题,进入相对应的slave,查看发现spark的owner是root,更改spark的权限,进入
/usr/local 目录下进行修改
sudo chown -R -v hadoop:hadoop spark |
结果如下
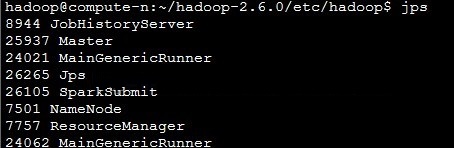
5.2 重新启动Spark, 之后用jps查看主节点和slave节点的进程
主节点的进程
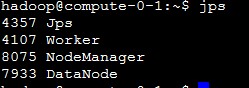
子节点的进程
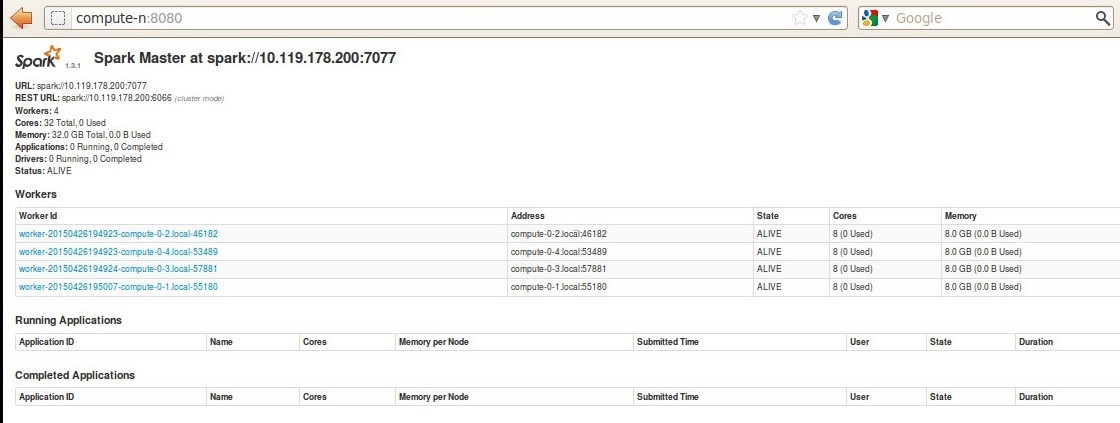
之后可以进入Spark集群的web页面,访问:compute-n:8080
5.3 进入Spark的bin目录,启动spark-sheel控制台
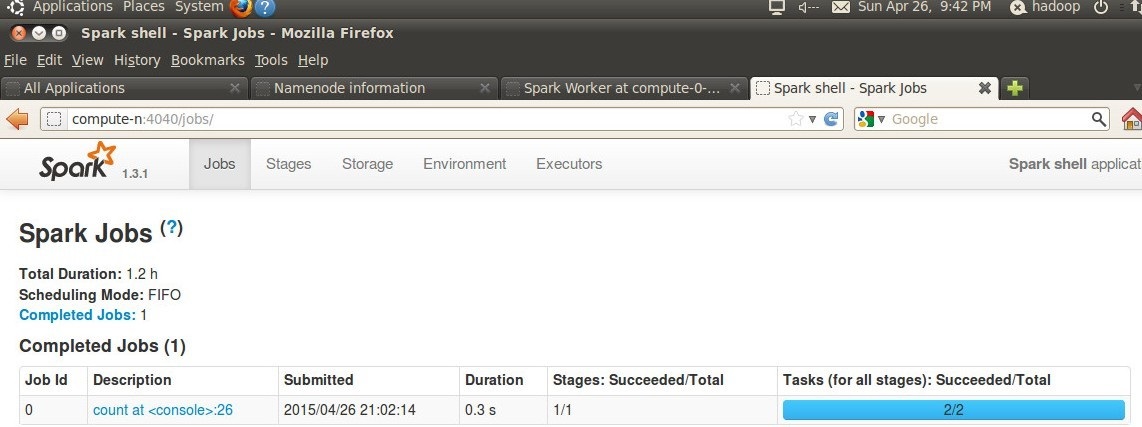
我们可以通过compute-n:4040, 从web的角度来看SparkUI的情况
6. 运行一个example,来验证
6.1 首先,我们知道在shell环境中生成了一个sc变量,sc是SparkContext的实例,这是在启动Spark
shell的时候系统帮助我们自动生成的。我们在编写Spark代码,无论是要运行本地还是集群都必须有SparkContext的实例
之后进入目录 /usr/local/spark/spark-1.3.1-bin-hadoop2.6中
hadoop fs -copyFromLocal README.md ./ |
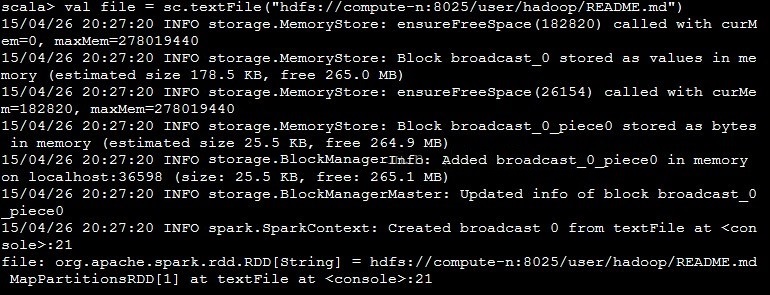
之后去读这个文件
val file = sc.textFile("hdfs://compute-n:8025/user/hadoop/README.md") |
结果
之后从读取的文件中过滤出所有的的“Spark”这个词,运行
val sparks = file.filter(line => line.contains("Spark")) |
结果

此时生成了一个FilteredRDD
之后统计“Spark”一共出现了多少次,运行
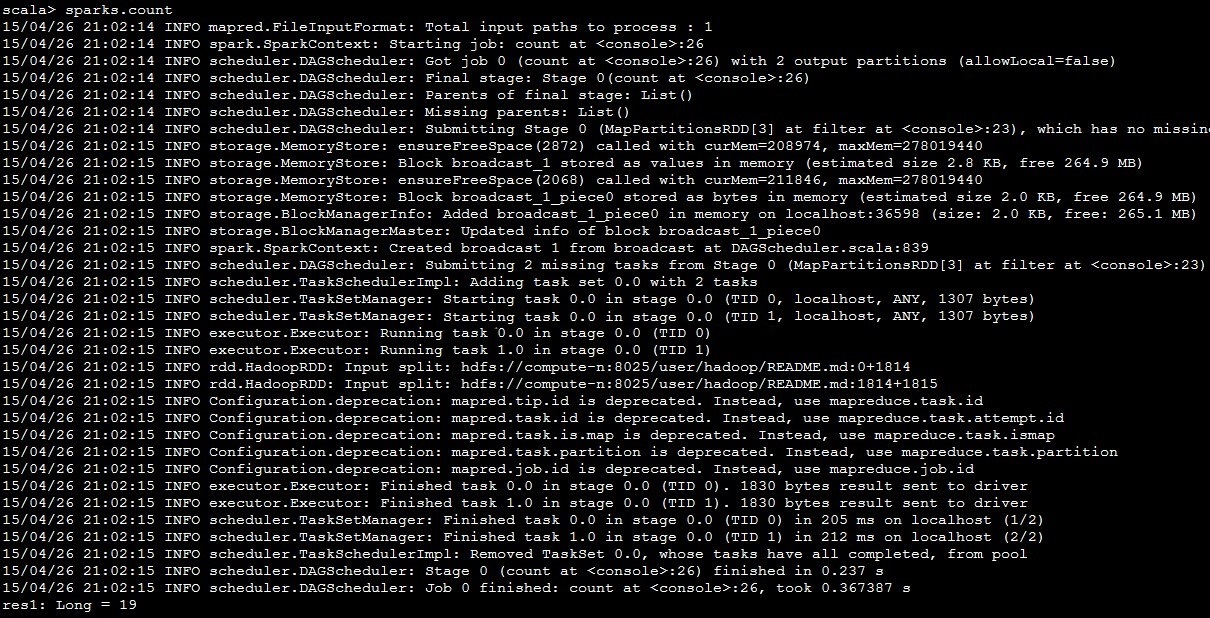
之后进入compute-n:4040网页查看
|






