| �̳�
������̳��������ǽ�ѧϰ��δ���Topologies,���Ұ�topologies����storm�ļ�Ⱥ����ȥ��Java����������Ҫ��ʾ�����ԣ�
�������ӻ�ʹ��python����ʾstorm�Ķ��������ԡ�
������
����̳�ʹ��storm-starter��Ŀ��������ӡ����Ƽ��������������Ŀ�Ĵ��벢�Ҹ��Ž̳�һ�������ȶ�һ�£�����storm�����������½�һ��strom��Ŀ����ƪ���°���Ļ������úá�
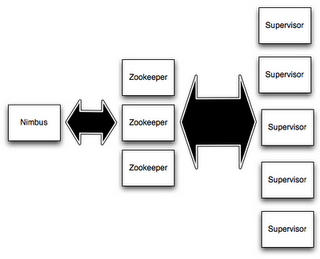
һ��Storm��Ⱥ�Ļ������
storm�ļ�Ⱥ�����Ͽ���hadoop�ļ�Ⱥ�dz�������Hadoop���������е���MapReduce��Job,
����Storm���������е���Topology�������Ƿdz���һ���� ��һ���ؼ��������ǣ� һ��MapReduce
Job���ջ��������һ��Topology����Զ���У���������ʽ��ɱ��������
��Storm�ļ�Ⱥ���������ֽڵ㣺 ���ƽڵ�(master node)�����ڵ�(worker
node)�����ƽڵ���������һ����̨���� Nimbus�� ������������Hadoop�����JobTracker��Nimbus�����ڼ�Ⱥ����ֲ����룬���乤�������������Ҽ��״̬��
ÿһ�������ڵ���������һ������Supervisor�Ľڵ㡣Supervisor��������������̨�����Ĺ�����������Ҫ
����/�رչ������̡�ÿһ����������ִ��һ��Topology��һ���Ӽ���һ�����е�Topology�������ںܶ�����ϵĺܶ��������ɡ�
storm topology�ṹ
Nimbus��Supervisor֮�������Э����������ͨ��һ��Zookeeper��Ⱥ����ɡ����ң�nimbus���̺�supervisor���ǿ���ʧ�ܣ�fail-fast)����״̬�ġ����е�״̬Ҫô��Zookeeper���棬
Ҫô�ڱ��ش����ϡ���Ҳ����ζ���������kill -9��ɱ��nimbus��supervisor���̣� Ȼ�����������ǣ����ǿ��Լ����������ͺ���ʲô��û�з������Ƶġ�������ʹ��storm����˼����ȶ���
Topologies
Ϊ����storm������ʵʱ���㣬 ��Ҫȥ����һЩtopologies��һ��topology����һ������ڵ�����ɵ�ͼ��Topology�����ÿ�������ڵ㶼������������
���ڵ�֮����������ʾ���������ķ���
����һ��Topology�Ǻܼġ����ȣ��������еĴ����Լ���������jar���һ��jar����Ȼ���������������������
storm jar all-my-code.jar backtype.storm.MyTopology arg1 arg2 |
����������������: backtype.strom.MyTopology,������arg1, arg2��������main�����������topology���Ұ����ύ��Nimbus��storm
jar�������ӵ�nimbus�����ϴ�jar�ļ���
��Ϊtopology�Ķ�����ʵ����һ��Thrift�ṹ����nimbus����һ��Thrift�����п������κ����Դ��������ύtopology������ķ�������JVM
-based�����ύ����ķ���, ��һ������: ��������Ⱥ������topologyȥ������ô�����Լ�ֹͣtopologies��
Stream
Stream��storm����Ĺؼ�����һ��stream��һ��û�б߽��tuple���С�storm�ṩһЩԭ�����ֲ�ʽ�ء��ɿ��ذ�һ��stream�����һ���µ�stream�����磺
�����һ��tweets�����䵽���Ż��������
storm�ṩ��������Ĵ���stream��ԭ����spout��bolt�������ʵ��Spout��Bolt��Ӧ�Ľӿ��Դ������Ӧ�õ�����
spout������Դͷ������һ��spout���ܴ�Kestrel���������ȡ��Ϣ���Ұ���Щ��Ϣ�����һ�������ֱ���һ��spout���Ե���twitter��һ��api���Ұѷ��ص�tweets�����һ������
bolt���Խ�������������stream����һЩ������ ��Щbolt���ܻ��ᷢ��һЩ�µ�stream��һЩ���ӵ���ת����
�����һЩtweet�����������Ż��⣬��Ҫ������裬 �Ӷ�Ҳ����Ҫ���bolt�� Bolt�������κ�����:
���к����� ����tuple, ��һЩ�ۺϣ� ��һЩ�ϲ��Լ��������ݿ�ȵȡ�
spout��bolt�����һ������ᱻ�����topology�� topology��storm�������һ���ij��������topology�ύ��storm�ļ�Ⱥ�����С�topology�Ľṹ��Topology��һ���Ѿ�˵���ˣ�����Ͳ������ˡ�
topology�ṹ
topology�����ÿһ���ڵ㶼�Dz������еġ� �����topology���棬 �����ָ��ÿ���ڵ�IJ��жȣ�
storm����ڼ�Ⱥ���������ô���߳���ͬʱ���㡣
һ��topology��һֱ����ֱ������ʽֹͣ����storm�Զ����·���һЩ����ʧ�ܵ����� ����storm��֤�㲻�������ݶ�ʧ����ʹ��һЩ��������ͣ��������Ϣ������������¡�
����ģ��(Data Model)
stormʹ��tuple����Ϊ��������ģ�͡�ÿ��tuple��һ��ֵ��ÿ��ֵ��һ�����֣�����ÿ��ֵ�������κ����ͣ�
���ҵ���������һ��tuple���Կ���һ��û�з�����java��������������storm֧�����еĻ������͡��ַ����Լ��ֽ�������Ϊtuple��ֵ��
�͡���Ҳ����ʹ�����Լ��������������Ϊֵ���ͣ� ֻҪ��ʵ�ֶ�Ӧ�����л���(serializer)��
topology�����ÿ���ڵ���붨����Ҫ�����tuple��ÿ���ֶΡ������������bolt�������������tuple���������ֶΣ����ͷֱ���:
double��triple��
public class DoubleAndTripleBolt extends BaseRichBolt {
private OutputCollectorBase _collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollectorBase collector) {
_collector = collector;
}
@Override
public void execute(Tuple input) {
int val = input.getInteger(0);
_collector.emit(input, new Values(val*2, val*3));
_collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("double", "triple"));
}
} |
declareOutputFields��������Ҫ������ֶ� �� ["double",
"triple"]�����bolt�������������ǽ���������͡�
һ����Topology
����������һ����topology�����ӣ� ���ǿ�һ��storm-starter�����ExclamationTopology:
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("words", new TestWordSpout(), 10);
builder.setBolt("exclaim1", new ExclamationBolt(), 3)
.shuffleGrouping("words");
builder.setBolt("exclaim2", new ExclamationBolt(), 2)
.shuffleGrouping("exclaim1"); |
���Topology����һ��Spout������Bolt��Spout���䵥�ʣ� ÿ��bolt��ÿ�����ʺ���Ӹ���!!!�����������ڵ㱻�ų�һ����:
spout���䵥�ʸ���һ��bolt�� ��һ��boltȻ��Ѵ����õĵ��ʷ�����ڶ���bolt�����spout����ĵ�����["bob"]��["john"],
��ô�ڶ���bolt�ᷢ��["bolt!!!!!!"]��["john!!!!!!"]������
����ʹ��setSpout��setBolt������Topology����Ľڵ㡣��Щ������������ָ����һ��id��
һ�������������Ķ���(spout����bolt), �Լ�������Ҫ�IJ��жȡ�
������������Ķ��������spout��ôҪʵ��IRichSpout�Ľӿڣ� �����bolt����ô��Ҫʵ��IRichBolt�ӿ�.
���һ��ָ�����жȵIJ����ǿ�ѡ�ġ�����ʾ��Ⱥ������Ҫ���ٸ�thread��һ��ִ������ڵ㡣������������ôstorm�����һ���߳���ִ������ڵ㡣
setBolt��������һ��InputDeclarer���������������������Bolt�����롣 �����һ��Bolt������Ҫ��ȡspout����������е�tuple
�� ʹ��shuffle
grouping�����ڶ���bolt��������ȡ��һ��bolt�������tuple��shuffle grouping��ʾ���е�tuple�ᱻ����ķַ���bolt������task����task�ַ�tuple�IJ����кܶ��֣��������ܡ�
�������ڶ���bolt��ȡspout�͵�һ��bolt����������е�tuple�� ��ô��Ӧ����������ڶ���bolt:
builder.setBolt("exclaim2", new ExclamationBolt(), 5)
.shuffleGrouping("words")
.shuffleGrouping("exclaim1"); |
����������ؿ�һ�����topology�����spout��bolt����ôʵ�ֵġ�Spout�������µ�tuple�����topology����
����TestWordSpout��["nathan", "mike",
"jackson", "golda", "bertels"]�������ѡ��һ�����ʷ��������TestWordSpout�����nextTuple()��������������ģ�
public void nextTuple() {
Utils.sleep(100);
final String[] words = new String[] {"nathan", "mike", "jackson", "golda", "bertels"};
final Random rand = new Random();
final String word = words[rand.nextInt(words.length)];
_collector.emit(new Values(word));
} |
���Կ�����ʵ�ֺܼ�
ExclamationBolt�ѡ�!!!��ƴ�ӵ�����tuple���档����������ExclamationBolt������ʵ�֡�
public static class ExclamationBolt implements IRichBolt {
OutputCollector _collector;
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
public void execute(Tuple tuple) {
_collector.emit(tuple, new Values(tuple.getString(0) + "!!!"));
_collector.ack(tuple);
}
public void cleanup() {
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
public Map getComponentConfiguration() {
return null;
}
} |
prepare�����ṩ��boltһ��Outputcollector��������tuple��Bolt�������κ�ʱ����tuple
�� ��prepare, execute����cleanup��������, ������������һ���߳������첽���䡣����prepare����ֻ�Ǽذ�OutputCollector��Ϊһ�����ֶα�������������execute����ʹ�á�
execute������bolt��һ���������tuple(һ��bolt�����ж������Դ). ExclamationBolt��ȡtuple�ĵ�һ���ֶΣ����ϡ�!!!��֮���ٷ����ȥ�����һ��bolt�ж������Դ�������ͨ������
Tuple#getSourceComponent������֪�����������ĸ�����Դ�ġ�
execute�������滹������һЩ����ֵ��һ� ����tuple����Ϊemit�����ĵ�һ����������������tuple�����һ�б�ack����Щ�ض���Storm�ɿ���API��һ���֣��������͡�
cleanup������bolt���رյ�ʱ����ã���Ӧ���������б�����Դ�����Ǽ�Ⱥ����֤�������һ���ᱻִ�С�����ִ��task�Ļ���down���ˣ���ô������û�а취�������Ǹ�������cleanup��Ƶ�ʱ���DZ�������local
mode��ʱ��ű�����(Ҳ����˵��һ����������ģ������storm��Ⱥ), ���������ڹر�һЩtopology��ʱ�������Դй©��
���declareOutputFields����һ��������word�����ֶε�tuple��
getComponentConfiguration ���������������������ô���С�����һ������������,����һ���Ľ��ͼ����á�
cleanup ������getComponentConfiguration ������һ��boltʵ���о������DZ���ġ������ͨ��ʵ��һ����������Ķ���һ��bolt���˻�����ṩ������������Ĭ��ʵ�֡�����ExclamationBolt����ͨ����չBaseRichBolt�Ӷ���ø����,��������:
public static class ExclamationBolt extends BaseRichBolt {
OutputCollector _collector;
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
_collector = collector;
}
public void execute(Tuple tuple) {
_collector.emit(tuple, new Values(tuple.getString(0) + "!!!"));
_collector.ack(tuple);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
} |
��local mode����ExclamationTopology
�����ǿ�����ô��local mode����ExclamationToplogy��
storm������������ģʽ:����ģʽ�ͷֲ�ʽģʽ. �ڱ���ģʽ�У� storm��һ������������߳���ģ�����е�spout��bolt.
����ģʽ�Կ����Ͳ�����˵�Ƚ����á� ������storm-starter�����topology��ʱ�����Ǿ����Ա���ģʽ���еģ�����Կ���topology�����ÿһ������ڷ���ʲô��Ϣ��
�ڷֲ�ʽģʽ�£� storm��һ�ѻ�����ɡ������ύtopology��master��ʱ�� ��ͬʱҲ��topology�Ĵ����ύ�ˡ�master����ַ���Ĵ��벢�Ҹ�������topolgoy���乤�����̡����һ���������̹ҵ��ˣ�
master�ڵ�����Ϊ���·��䵽�����ڵ㡣���������һ����Ⱥ��������topology�� ����Կ���Running
topologies on a production cluster���¡�
�������Ա���ģʽ����ExclamationTopology�Ĵ���:
Config conf = new Config();
conf.setDebug(true);
conf.setNumWorkers(2);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("test", conf, builder.createTopology());
Utils.sleep(10000);
cluster.killTopology("test");
cluster.shutdown(); |
���ȣ� ������붨��ͨ������һ��LocalCluster����������һ�������ڵļ�Ⱥ���ύtopology���������ļ�Ⱥ���ύtopology���ֲ�ʽ��
Ⱥ��һ���ġ�ͨ������submitTopology�������ύtopology�� ����������������Ҫ���е�topology�����֣�һ�����ö����Լ�Ҫ���е�topology������
topology������������Ψһ����һ��topology�ģ�������Ȼ����������������ɱ�����topology�ġ�ǰ���Ѿ�˵���ˣ�
�������ʽ��ɱ��һ��topology����������һֱ���С�
Conf����������úܶණ���� ��������������ģ�
TOPOLOGY_WORKERS(setNumWorkers) ������ϣ����Ⱥ������ٸ��������̸�����ִ�����topology.
topology�����ÿ������ᱻ��Ҫ�߳���ִ�С�ÿ����������ö��ٸ��߳���ͨ��setBolt��setSpout��ָ���ġ���Щ�̶߳������ڹ�����
������. ÿһ���������̰���һЩ�ڵ��һЩ�����̡߳����磬 �����ָ��300���̣߳�60�����̣� ��ôÿ��������������Ҫִ��6���̣߳�
����6���߳̿������ڲ�ͬ�����(Spout, Bolt)�������ͨ������ÿ������IJ��ж��Լ���Щ�߳����ڵĽ�������������topology�����ܡ�
TOPOLOGY_DEBUG(setDebug), ���������ó�true�Ļ��� storm���¼��ÿ������������ÿ����Ϣ�����ڱ��ػ�������topology�����ã�
������������ô���Ļ���Ӱ�����ܵġ�
����Ȥ�Ļ�����ȥ����Conf�����Javadocȥ����topology���������á�
���Կ�������һ����storm��Ŀȥ������ô���ÿ���������ʹ���ܹ��Ա���ģʽ����topology.
���������(Stream grouping)
��������Ը���topology������������֮�䷢��tuple�� Ҫ��ס�� spouts��bolts�Ժܶ�task����ʽ��topology����ͬ��ִ�С������task����������һ�����е�topology��
��Ӧ����������:
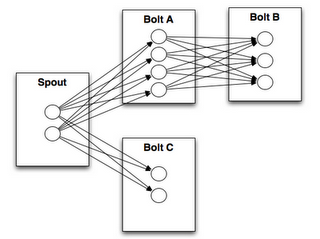
��task�Ƕ�����topology
��Bolt A��һ��taskҪ����һ��tuple��Bolt B�� ��Ӧ�÷���Bolt B���ĸ�task�أ�
stream groupingר�Żش���������ġ������������о���ͬ��stream grouping֮ǰ�������ǿ�һ��storm-starter���������һ��topology��WordCountTopology��ȡһЩ���ӣ�
�����������ÿ�����ʳ��ֵĴ���.
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("sentences", new RandomSentenceSpout(), 5);
builder.setBolt("split", new SplitSentence(), 8)
.shuffleGrouping("sentences");
builder.setBolt("count", new WordCount(), 12)
.fieldsGrouping("split", new Fields("word")); |
SplitSentence���ھ��������ÿ�����ʷ���һ���µ�tuple, WordCount���ڴ�����ά��һ������->������mapping��
WordCountÿ�յ�һ�����ʣ� �������ڴ������ͳ��״̬��
�кü��ֲ�ͬ��stream grouping:
���grouping��shuffle grouping, ����������κ�һ��task��������������RandomSentenceSpout��SplitSentence֮���õľ���shuffle
grouping, shuffle grouping�Ը���task��tuple����ıȽϾ��ȡ�
һ�ָ���Ȥ��grouping��fields grouping, SplitSentence��WordCount֮��ʹ�õľ���fields
grouping, ����grouping���Ʊ�֤��ͬfieldֵ��tuple��ȥͬһ��task�� �����WordCount��˵�dz��ؼ������ͬһ�����ʲ�ȥͬһ��task��
��ôͳ�Ƴ����ĵ��ʴ����Ͳ����ˡ�
fields grouping��stream�ϲ���stream�ۺ��Լ��ܶ����������Ļ������ڱ����أ�
fields groupingʹ�õ�һ���Թ�ϣ������tuple�ġ�
����һЩ�������͵�stream grouping.�������Conceptsһ�������ϸ���˽⡣
ʹ�ñ������������Bolt
Bolt����ʹ���κ����������塣���������Զ����bolt�ᱻ�����ӽ���(subprocess)��ִ�У�
stormʹ��JSON��Ϣͨ��stdin/stdout������Щsubprocessͨ�š����ͨ��Э����һ��ֻ��100�еĿ⣬
storm�ŶӸ���Щ����˶�Ӧ��Ruby, Python��Fancy�汾��
������WordCountTopology�����SplitSentence�Ķ���:
public static class SplitSentence extends ShellBolt implements IRichBolt {
public SplitSentence() {
super("python", "splitsentence.py");
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
} |
SplitSentence�̳���ShellBolt�����������Bolt��python�����У����Ҳ�����:
splitsentence.py��������splitsentence.py�Ķ���:
import storm
class SplitSentenceBolt(storm.BasicBolt):
def process(self, tup):
words = tup.values[0].split(" ")
for word in words:
storm.emit([word])
SplitSentenceBolt().run() |
�����й����������Զ���Spout��Bolt����Ϣ�� �Լ�����������������topology�� ��Ϣ���Բμ�:Using
non-JVM languages with Storm.
�ɿ�����Ϣ����
������̵̳�ǰ�棬�����������й�tuple��һЩ��������Щ��������storm�Ŀɿ���API�� storm��α�֤spout������ÿһ��tuple��������������������storm��α�֤��Ϣ����ʧ���Ը������˽�storm�Ŀɿ���API.
����
������Ž̳̱ȽϹ㷺�Ľ����˴ӿ��������ԺͲ���һ��topology.�ĵ����������ֻ��������ʹ��storm�ĸ������档
|






