| ���������Ƕ�֪��hadoop������������hadoop.���Ǹ���ι��������ݿ���Ŀ���������ߴ�����hadoop���DZȽ��ʺϵģ����Ƕ���ʵʱ�ԱȽ�ǿ�ģ��������Ƚϴ�ģ����ǿ��Բ���Storm����ôStorm��ʲô�������䣬���ܹ���һ���ʺ��Լ�����Ŀ���������ҿ��Բο���
���Դ��������������Ķ������£�
1.һ���õ���Ŀ�ܹ�Ӧ�þ߱�ʲô�ص㣿
2.����Ŀ�ܹ�����α�֤����ȷ�Եģ�
3.ʲô��Kafka��
4.flume+kafka������ϣ�
5.ʹ��ʲô�ű����Բ鿴flume��û����Kafka��������
�����������Ķ�֪��ģ�黯˼�룬������Ƶ�ԭ���������棺
һ�����ǿ���ģ�黯�����ܻ��ָ����������ӡ����ݲɼ�--���ݽ���--��ʧ����--�������/�洢��

1��.���ݲɼ�
����Ӹ��ڵ���ʵʱ�ɼ����ݣ�ѡ��cloudera��flume��ʵ��
2��.���ݽ���
���ڲɼ����ݵ��ٶȺ����ݴ������ٶȲ�һ��ͬ�����������һ����Ϣ�м������Ϊ���壬ѡ��apache��kafka
3��.��ʽ����
�Բɼ��������ݽ���ʵʱ������ѡ��apache��storm
4��.�������
�Է�����Ľ���־û����ݶ���mysql
��һ������ģ�黯֮���統Storm�ҵ���֮�����ݲɼ������ݽ��뻹�Ǽ��������ţ����ݲ��ᶪʧ��storm����֮����Լ���������ʽ���㣻
��ô��������������������ļܹ�ͼ
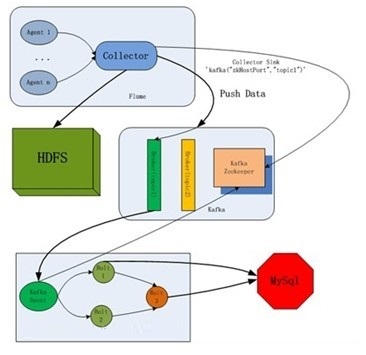
��ϸ���ܸ����������װ���ã�
����ϵͳ��ubuntu
Flume
Flume��Cloudera�ṩ��һ���ֲ�ʽ���ɿ����߿��õĺ�����־�ɼ����ۺϺʹ������־�ռ�ϵͳ��֧������־ϵͳ�ж��Ƹ������ݷ��ͷ��������ռ�����;ͬʱ��Flume�ṩ�����ݽ��м�������д���������ݽ��ܷ�(�ɶ���)��������
��ͼΪflume���͵���ϵ�ṹ��
Flume����Դ�Լ������ʽ:
Flume�ṩ�˴�console(����̨)��RPC(Thrift-RPC)��text(�ļ�)��tail(UNIX
tail)��syslog(syslog��־ϵͳ��֧��TCP��UDP��2��ģʽ)��exec(����ִ��)������Դ���ռ����ݵ�����,�����ǵ�ϵͳ��Ŀǰʹ��exec��ʽ������־�ɼ���
Flume�����ݽ��ܷ���������console(����̨)��text(�ļ�)��dfs(HDFS�ļ�)��RPC(Thrift-RPC)��syslogTCP(TCP
syslog��־ϵͳ)�ȡ�������ϵͳ����kafka�����ա�
Flume���ؼ��ĵ���http://flume.apache.org/
Flume��װ��
$tar zxvf apache-flume-1.4.0-bin.tar.gz/usr/local |
Flume�������
$bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties
--name producer -Dflume.root.logger=INFO,console |
Kafka
kafka��һ�ָ��������ķֲ�ʽ����������Ϣϵͳ�������������ԣ�
ͨ��O(1)�Ĵ������ݽṹ�ṩ��Ϣ�ij־û������ֽṹ���ڼ�ʹ����TB����Ϣ�洢Ҳ�ܹ����ֳ�ʱ����ȶ����ܡ�
������������ʹ�Ƿdz���ͨ��Ӳ��kafkaҲ����֧��ÿ����ʮ�����Ϣ��
֧��ͨ��kafka�����������ѻ���Ⱥ��������Ϣ��
֧��Hadoop�������ݼ��ء�
kafka��Ŀ�����ṩһ���������Ľ�������������Դ��������߹�ģ����վ�е����ж��������ݡ�
���ֶ�������ҳ����������������û����ж��������ִ������ϵ�������Ṧ�ܵ�һ���ؼ����ء� ��Щ����ͨ����������������Ҫ���ͨ��������־����־�ۺ��������
������Hadoop��һ������־���ݺ����߷���ϵͳ������Ҫ��ʵʱ���������ƣ�����һ�����еĽ��������kafka��Ŀ����ͨ��Hadoop�IJ��м��ػ�����ͳһ���Ϻ����ߵ���Ϣ������Ҳ��Ϊ��ͨ����Ⱥ�����ṩʵʱ�����ѡ�
kafka�ֲ�ʽ���ļܹ�����ͼ��--ȡ��Kafka����
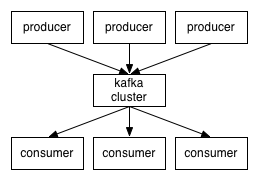
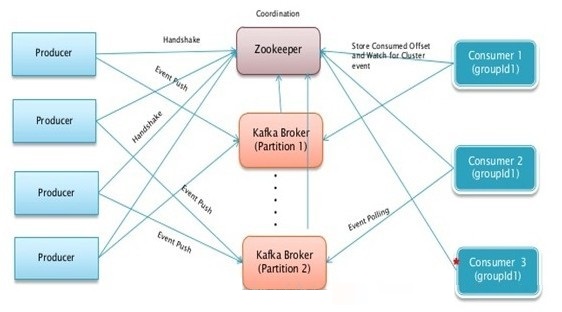
��ʵ����û��̫�����𣬹����ļܹ�ͼֻ�ǰ�Kafka���ı�ʾ��һ��Kafka
Cluster��������ܹ�ͼ�������ϸһЩ��
Kafka�汾��0.8.0
Kafka���ؼ��ĵ���http://kafka.apache.org/
Kafka��װ��
> tar xzf kafka-<VERSION>.tgz
> cd kafka-<VERSION>
> ./sbt update
> ./sbt package
> ./sbt assembly-package-dependency |
�������������
��1�� start server
> bin/zookeeper-server-start.shconfig/zookeeper.properties
> bin/kafka-server-start.shconfig/server.properties |
�����ǹ����ϵĽ̳̣�kafka����������zookeeper���������Լ���ʵ�ʲ�������ʹ�õ�����zookeeper��Ⱥ�����Ե�һ�������Ҿ�ûִ�У�����ֻ��Щ��������ҿ��¡�
���ö�����zookeeper��Ⱥ��Ҫ����server.properties�ļ�����zookeeper.connect��Ϊ������Ⱥ��IP�Ͷ˿�
zookeeper.connect=nutch1:2181 |
��2��Create a topic
> bin/kafka-create-topic.sh --zookeeper localhost:2181 --replica 1 --partition 1 --topic test
> bin/kafka-list-topic.sh --zookeeperlocalhost:2181 |
��3��Send some messages
> bin/kafka-console-producer.sh--broker-list localhost:9092 --topic test |
��4��Start a consumer
> bin/kafka-console-consumer.sh--zookeeper localhost:2181 --topic test --from-beginning |
kafka-console-producer.sh��kafka-console-cousumer.shֻ��ϵͳ�ṩ�������й��ߡ�����������Ϊ�˲����Ƿ��������������ѣ���֤������ȷ��
��ʵ�ʿ����л���Ҫ���п����Լ����������������ߣ�
kafka�İ�װҲ���Բο���֮ǰд�����£�http://blog.csdn.net/weijonathan/article/details/18075967
Storm
Twitter��Storm��ʽ��Դ�ˣ�����һ���ֲ�ʽ�ġ��ݴ���ʵʱ����ϵͳ�������й���GitHub�ϣ���ѭ
Eclipse Public License 1.0��Storm����BackType������ʵʱ����ϵͳ��BackType��������Twitter���¡�GitHub�ϵ����°汾��Storm
0.5.2����������Clojureд�ġ�
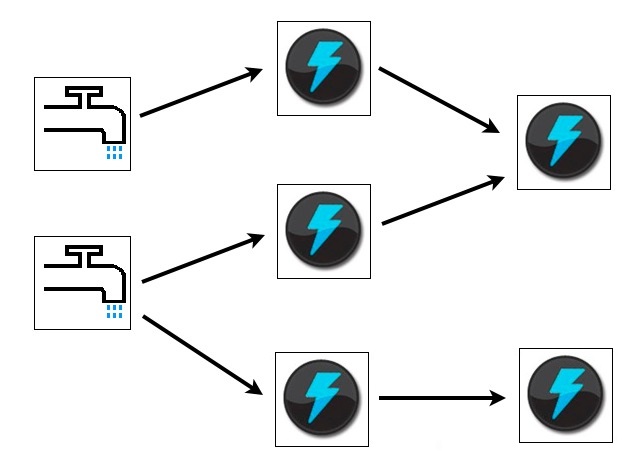
Storm����Ҫ�ص����£�
�ı��ģ�͡�������MapReduce�����˲��������������ԣ�Storm�����˽���ʵʱ�����ĸ����ԡ�
����ʹ�ø��ֱ�����ԡ��������Storm֮��ʹ�ø��ֱ�����ԡ�Ĭ��֧��Clojure��Java��Ruby��Python��Ҫ���Ӷ��������Ե�֧�֣�ֻ��ʵ��һ����Stormͨ��Э�鼴�ɡ�
�ݴ��ԡ�Storm������������̺ͽڵ�Ĺ��ϡ�
ˮƽ��չ���������ڶ���̡߳����̺ͷ�����֮�䲢�н��еġ�
�ɿ�����Ϣ������Storm��֤ÿ����Ϣ�����ܵõ�һ����������������ʧ��ʱ�����Ḻ�����ϢԴ������Ϣ��
���١�ϵͳ����Ʊ�֤����Ϣ�ܵõ����ٵĴ�����ʹ��?MQ��Ϊ��ײ���Ϣ���С���0.9.0.1�汾֧��?MQ��netty����ģʽ��
����ģʽ��Storm��һ��������ģʽ���������ڴ�����������ȫģ��Storm��Ⱥ����������Կ��ٽ��п����͵�Ԫ���ԡ�
����ƪ�����⣬����İ�װ������Բο���Storm-0.9.0.1��װ����
ָ��
��������ͷϷ��ʼ�����Ǿ��ǿ��֮���������
flume��kafka����
1.����flume-kafka-plus:https://github.com/beyondj2ee/flumeng-kafka-plugin
2.��ȡ����е�flume-conf.properties�ļ�
�ĸ��ļ���#source section
producer.sources.s.type = exec
producer.sources.s.command = tail -f -n+1 /mnt/hgfs/vmshare/test.log
producer.sources.s.channels = c |
������topic��ֵ��Ϊtest
���ĺ�������ļ��Ž�flume/confĿ¼��
�ڸ���Ŀ����ȡ����jar�����뻷����flume��lib�£�
ע�������flumeng-kafka-plugin.jar�������������github��Ŀ���Ѿ��ƶ���packageĿ¼�ˡ��Ҳ�����ͯЬ���Ե�packageĿ¼��ȡ��
�������IJ���֮��������������flume+kafka���������û����ͨ��
����������flume��Ȼ��������kafka���������谴֮ǰ�IJ���ִ�У�����������ʹ��kafka��kafka-console-consumer.sh�ű��鿴�Ƿ���flume��û����Kafka�������ݣ�
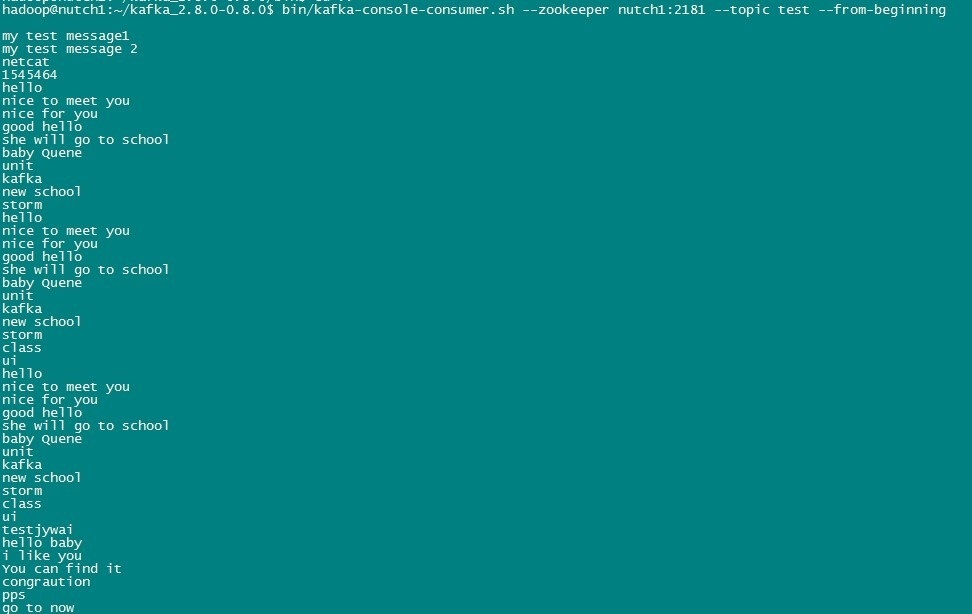
����������ҵ�test.log�ļ�ͨ��flumeץȡ����kafka�����ݣ�˵�����ǵ�flume��kafka������ͨ�ˣ�
��һ��ǵøտ�ʼ���ǵ�����ͼô��������һ����ͨ��flume��kafka������һ���ǵ�hdfs�ģ����������û���ᵽ��δ���kafka��ͬʱ����hdfs��
flume��֧������ͬ�����ƣ�ͬ����������ͼ���£�ȡ����flume�����������û�ָ�ϵ�ַ��http://flume.apache.org/FlumeUserGuide.html
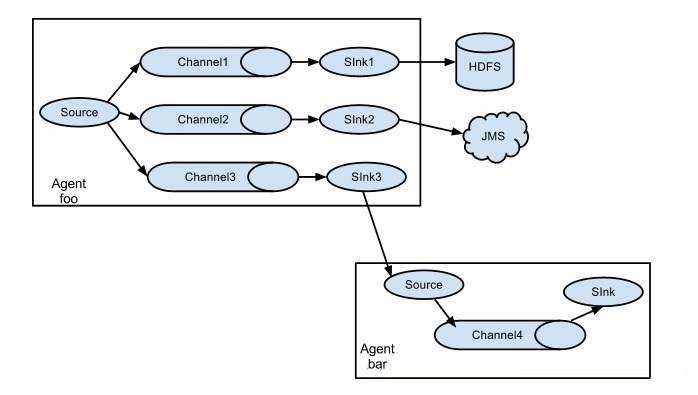
��ô����ͬ�������أ�����������ã�
#2��channel��2��sink�������ļ� �������ǿ�����������sink��һ����kafka�ģ�һ����hdfs�ģ�
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2 |
�������ô������Լ�������ȥ���ã�����Ͳ����������
kafka��storm������
1.����kafka-storm0.8�����https://github.com/wurstmeister/storm-kafka-0.8-plus
2.ʹ��maven package���б��룬�õ�storm-kafka-0.8-plus-0.3.0-SNAPSHOT.jar��
--��ת�ص�ͯЬע���£�����İ���֮ǰд���ˣ����ڸ���ȷ�ˣ�������˼��
3.����jar����kafka_2.9.2-0.8.0-beta1.jar��metrics-core-2.2.0.jar��scala-library-2.9.2.jar
(������jar����kafka��Ŀ�����ҵ�)
��ע�������������Ŀ��Ҫ����jar���ǵ�ҲҪ�Ž�storm��Lib�б����õ���mysql��Ҫ����mysql-connector-java-5.1.22-bin.jar��storm��lib��
��ô���������ǰ�stormҲ�����£�
������ϲ���֮�����ǻ���һ������Ҫ��������ʹ��kafka-storm0.8�����дһ���Լ���Storm����
�����Ҹ���︽��һ����Ū��storm���ٶ����̷�����ַ������: http://pan.baidu.com/s/1jGBp99W
����: 9arq
�������³���Ĵ���Topology����

���ݲ�����Ҫ��WordCounter���У�����ֻ��ʹ�ü�JDBC���в��봦��

����ֻ��Ҫ����һ��������ΪTopology���ƾͿ����ˣ���������ʹ�ñ���ģʽ�����Բ����������ֱ�ӿ������Ƿ���ͨ��
storm-0.9.0.1/bin/storm jar storm-start-demo-0.0.1-SNAPSHOT.jar com.storm.topology.MyTopology |
�ȿ�����־�������ӡ�����������ݿ��������������
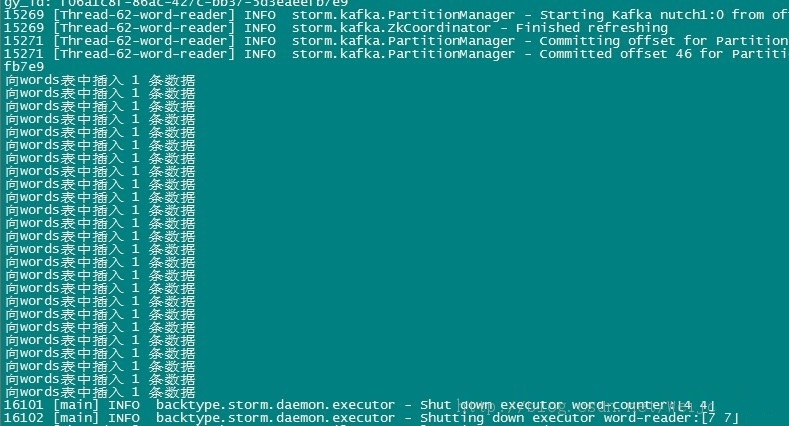
Ȼ�����Dz鿴�����ݿ⣻����ɹ��ˣ�
���������ǵ��������Ͼ�����ˣ�
�������ﻹ��һ�����⣬��֪�������û�з��֡�
��������ʹ��storm���зֲ�ʽ��ʽ���㣬��ô�ֲ�ʽ����Ҫע���������һ�����Լ����������ݵIJ������������ṩ�IJ�����Ŀֻ�����ڲ��ԣ���ʽ������������������
��ɫ�ǿ�J2EE��һ�����������Ľ����ǽ���һ��zookeeper�ķֲ�ʽȫ��������֤����һ���ԣ�����������¼�룡
zookeeper�ͻ��˿�ܴ�����ʹ��Netflix Curator����ɣ���������һ�ûȥ��������ֻ��д�������ˣ�
|






