| ʲô��Spark
Apache Spark��һ��Χ���ٶȡ������Ժ��ӷ��������Ĵ����ݴ�����ܡ������2009���ɼ��ݴ�ѧ��������У��AMPLab����������2010���ΪApache�Ŀ�Դ��Ŀ֮һ��
��Hadoop��Storm�����������ݺ�MapReduce������ȣ�Spark���������ơ�
���ȣ�SparkΪ�����ṩ��һ��ȫ�桢ͳһ�Ŀ�����ڹ����������Ų�ͬ���ʣ��ı����ݡ�ͼ�����ݵȣ������ݼ�������Դ���������ݻ�ʵʱ�������ݣ��Ĵ����ݴ���������
Spark���Խ�Hadoop��Ⱥ�е�Ӧ�����ڴ��е������ٶ�����100���������ܹ���Ӧ���ڴ����ϵ������ٶ�����10����
Spark�ÿ����߿��Կ��ٵ���Java��Scala��Python��д�����������Դ���һ������80���߽ײ��������ϡ����һ�����������shell���Խ���ʽ�ز�ѯ���ݡ�
����Map��Reduce����֮�⣬����֧��SQL��ѯ�������ݣ�����ѧϰ��ͼ�����ݴ����������߿�����һ�����ݹܵ������е���ʹ��ijһ�������߽���Щ���������һ��ʹ�á�
�����Apache Spark����ϵ�еĵ�һ�����У����ǽ��˽ʲô��Spark��������͵�MapReduce��������ıȽ��Լ������Ϊ�����ݴ����ṩ��һ�������Ĺ��ߡ�
Hadoop��Spark
Hadoop��������ݴ��������������ʮ����ʷ�����ұ���������ѡ�Ĵ����ݼ��ϴ����Ľ��������MapReduce��һ·�������������������
��������Ҫ��·������㷨��������˵������ʮ�ָ�Ч�����ݴ��������е�ÿһ������Ҫһ��Map�κ�һ��Reduce�Σ��������Ҫ������һ���������
��Ҫ������������ת����MapReduceģʽ��
����һ����ʼ֮ǰ����һ������ҵ������ݱ���Ҫ�洢���ֲ�ʽ�ļ�ϵͳ�С���ˣ����ƺʹ��̴洢�ᵼ�����ַ�ʽ�ٶȱ���������Hadoop���������
ͨ�����������װ�����ļ�Ⱥ������Ϊ�˴�����ͬ�Ĵ���������������Ҫ���ɶ��ֲ�ͬ�Ĺ��ߣ������ڻ���ѧϰ��Mahout�������ݴ�����Storm����
�����Ҫ��ɱȽϸ��ӵĹ������ͱ��뽫һϵ�е�MapReduce��ҵ��������Ȼ��˳��ִ����Щ��ҵ��ÿһ����ҵ���Ǹ�ʱ�ӵģ�����ֻ����ǰһ����ҵ���֮����һ����ҵ���ܿ�ʼ������
��Spark������������ʹ��������ͼ��DAG���������ӵĶಽ���ݹܵ������һ�֧�ֿ�������ͼ���ڴ����ݹ������Ա㲻ͬ����ҵ���Թ�ͬ����ͬһ�����ݡ�
Spark���������е�Hadoop�ֲ�ʽ�ļ�ϵͳ����֮�ϣ�HDFS���ṩ�������ǿ���ܡ���֧�ֽ�SparkӦ�ò����ִ��Hadoop
v1��Ⱥ��with SIMR �C Spark-Inside-MapReduce����Hadoop v2 YARN��Ⱥ������Apache
Mesos֮�С�
����Ӧ�ý�Spark������Hadoop MapReduce��һ�����Ʒ������Hadoop�����Ʒ������ͼ���������Hadoop������Ϊ���ṩһ��������ͬ�Ĵ����������������ȫ����ͳһ�Ľ��������
Spark����
Sparkͨ�������ݴ��������гɱ����͵�ϴ�ƣ�Shuffle����ʽ����MapReduce������һ�����ߵIJ�Ρ������ڴ����ݴ洢�ͽӽ�ʵʱ�Ĵ���������Spark�������Ĵ����ݴ�������������Ҫ��ܶ��
Spark��֧�ִ����ݲ�ѯ���ӳټ��㣬��������Ż������ݴ��������еĴ������衣Spark���ṩ����API�����������ߵ�������������֮�Ϊ�����ݽ�������ṩһ�µ���ϵ�ܹ�ģ�͡�
Spark���м����������ڴ��ж����ǽ���д����̣�����Ҫ��δ���ͬһ���ݼ�ʱ����һ���ر�ʵ�á�Spark����Ƴ��Ծ��Ǽȿ������ڴ����ֿ�
���ڴ����Ϲ�����ִ�����档���ڴ��е����ݲ�����ʱ��Spark�������ͻ�ִ���ⲿ������Spark�������ڴ������ڼ�Ⱥ�ڴ������ܺ͵����ݼ���
Spark�᳢�����ڴ��д洢�����ܶ������Ȼ����д����̡������Խ�ij�����ݼ���һ���ִ����ڴ��ʣ�ಿ�ִ�����̡���������Ҫ�������ݺ������������ڴ������Spark���������Ƶ����������ڴ��е����ݴ洢��
Spark��������������
1.֧�ֱ�Map��Reduce����ĺ�����
2.�Ż������������ͼ��operator graphs����
3.�������Ż��������ݴ������̵Ĵ����ݲ�ѯ���ӳټ��㡣
4.�ṩ������һ�µ�Scala��Java��Python API��
5.�ṩ����ʽScala��Python Shell��Ŀǰ�ݲ�֧��Java��
Spark����Scala����������Ա�д���ɣ�������Java�������JVM������֮�ϡ�Ŀǰ֧�����³���������Ա�дSparkӦ�ã�
1.Scala
2.Java
3.Python
4.Clojure
5.R
Spark��̬ϵͳ
����Spark����API֮�⣬Spark��̬ϵͳ�л������������ӿ⣬�����ڴ����ݷ����ͻ���ѧϰ�����ṩ�����������
���������
1.Spark Streaming:
Spark Streaming����������ʽ�ļ���ʹ������������ڴ���ʵʱ�������ݡ���ʹ��DStream������˵����һ�����Էֲ�ʽ���ݼ���RDD��ϵ�У�����ʵʱ���ݡ�
2.Spark SQL:
Spark SQL����ͨ��JDBC API��Spark���ݼ���¶��ȥ�����һ������ô�ͳ��BI�Ϳ��ӻ�������Spark������ִ������SQL�IJ�ѯ���û���������Spark
SQL�Բ�ͬ��ʽ�����ݣ���JSON��Parquet�Լ����ݿ�ȣ�ִ��ETL������ת����Ȼ��¶���ض��IJ�ѯ��
3.Spark MLlib:
MLlib��һ������չ��Spark����ѧϰ�⣬��ͨ�õ�ѧϰ�㷨������ɣ�������Ԫ���ࡢ���Իع顢���ࡢЭͬ���ˡ��ݶ��½��Լ��ײ��Ż�ԭ�
4.Spark GraphX:
GraphX������ͼ����Ͳ���ͼ����� �µģ�alpha��Spark API��ͨ�����뵯�Էֲ�ʽ����ͼ��Resilient
Distributed Property Graph����һ�ֶ���ͱ߶��������Ե��������ͼ����չ��Spark
RDD��Ϊ��֧��ͼ���㣬GraphX��¶��һ���������������ϣ���subgraph��joinVertices��aggregateMessages��
��һ�������Ż���Pregel API���塣���⣬GraphX������һ���������������ڼ�ͼ���������ͼ�㷨���������ϡ�
������Щ�����⣬����һЩ�����Ŀ⣬��BlinkDB��Tachyon��
BlinkDB��һ�����Ʋ�ѯ���棬�����ں���������ִ�н���ʽSQL��ѯ��BlinkDB����ͨ���������ݾ�����������ѯ��Ӧʱ�䡣ͨ��������������ִ�в�ѯ��չʾ����������Ĵ�����ע��Ľ�������������ݼ��ϡ�
Tachyon��һ�����ڴ�Ϊ���ĵ� �ֲ�ʽ�ļ�ϵͳ���ܹ��ṩ�ڴ漶���ٶȵĿ缯Ⱥ��ܣ���Spark��MapReduce���Ŀ����ļ������������������ļ��������ڴ��У��Ӷ����������
������Ҫ������ȡ�����ݼ���ͨ����һ���ƣ���ͬ����ҵ/��ѯ�Ϳ�ܿ������ڴ漶���ٶȷ��ʻ�����ļ���
���⣬����һЩ������������Ʒ���ɵ�����������Cassandra��Spark Cassandra ����������R��SparkR����Cassandra
Connector�����ڷ��ʴ洢��Cassandra���ݿ��е����ݲ�����Щ������ִ�����ݷ�����
��ͼչʾ����Spark��̬ϵͳ�У���Щ��ͬ�Ŀ�֮����������
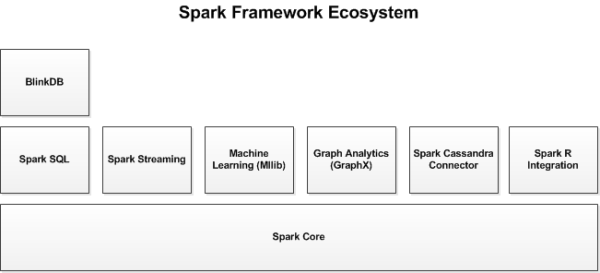
ͼ1. Spark����еĿ�
���ǽ�����һϵ����������̽����ЩSpark��
Spark��ϵ�ܹ�
Spark��ϵ�ܹ���������������Ҫ�����
1.���ݴ洢
2.API
3.�������
��������������ϸ�˽�һ����Щ�����
���ݴ洢��
Spark��HDFS�ļ�ϵͳ�洢���ݡ��������ڴ洢�κμ�����Hadoop������Դ������HDFS��HBase��Cassandra�ȡ�
API��
����API��Ӧ�ÿ����߿����ñ���API�ӿڴ�������Spark��Ӧ�á�Spark�ṩScala��Java��Python���ֳ���������Ե�API��
��Դ������
Spark�ȿ��Բ�����һ�������ķ�����Ҳ���Բ�������Mesos��YARN�����ķֲ�ʽ������֮�ϡ�
��ͼ2չʾ��Spark��ϵ�ܹ�ģ���еĸ��������
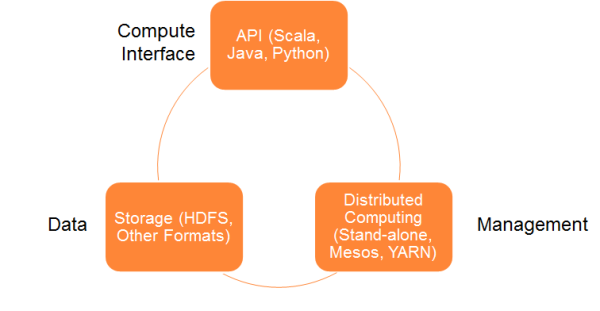
ͼ2 Spark��ϵ�ܹ�
���Էֲ�ʽ���ݼ�
���Էֲ�ʽ���ݼ�������Matei���о����ģ���RDD��Spark����еĺ��ĸ�����Խ�RDD�������ݿ��е�һ�ű������п��Ա����κ����͵����ݡ�Spark�����ݴ洢�ڲ�ͬ�����ϵ�RDD֮�С�
RDD���������°��ż��㲢�Ż����ݴ������̡�
���⣬���������ݴ��ԣ���ΪRDD֪��������´��������¼������ݼ���
RDD�Dz��ɱ�ġ�������ñ任��Transformation����RDD����������任�����ص���һ��ȫ�µ�RDD����ԭ�е�RDD��Ȼ���ֲ��䡣
RDD֧���������͵IJ�����
1.�任��Transformation��
2.���Action��
�任���任�ķ���ֵ��һ���µ�RDD���ϣ������ǵ���ֵ������һ���任�������������κ���ֵ���㣬��ֻ��ȡһ��RDD��Ϊ������Ȼ��һ���µ�RDD��
�任����������map��filter��flatMap��groupByKey��reduceByKey��aggregateByKey��pipe��coalesce��
�ж����ж��������㲢����һ���µ�ֵ������һ��RDD�����ϵ����ж�����ʱ��������һʱ�̼���ȫ�������ݴ�����ѯ�����ؽ��ֵ��
�ж�����������reduce��collect��count��first��take��countByKey�Լ�foreach��
��ΰ�װSpark
��װ��ʹ��Spark�м��ֲ�ͬ��ʽ����������Լ��ĵ����Ͻ�Spark��Ϊһ�������Ŀ�ܰ�װ���ߴ�����Cloudera��HortonWorks��MapR֮��Ĺ�Ӧ�̴���ȡһ��Spark���������ֱ��ʹ�á�������Ҳ����ʹ�����ƶ˻�������Databricks
Cloud����װ�����úõ�Spark��
�ڱ����У����ǽ���Spark��Ϊһ�������Ŀ�ܰ�װ���ڱ��������������Spark�ոշ�����1.2.0�汾�����ǽ�����һ�汾���ʾ��Ӧ�õĴ���չʾ��
�������Spark
�����ڱ��ػ�����װ��Spark��ʹ���˻����ƶ˵�Spark���м��ֲ�ͬ�ķ�ʽ�������ӵ�Spark���档
�±�չʾ�˲�ͬ��Spark����ģʽ�����Master URL������
�����Spark����
Spark���������к�����Spark shell���ӵ�Spark������н���ʽ���ݷ�����Spark
shell֧��Scala��Python�������ԡ�Java��֧�ֽ���ʽ��Shell�������һ������δ��Java������ʵ�֡�
������spark-shell.cmd��pyspark.cmd����ֱ�����Scala�汾��Python�汾��Spark
Shell��
Spark��ҳ����̨
����Spark��������һ��ģʽ�£�������ͨ������Spark��ҳ����̨�鿴Spark����ҵ�����������ͳ�����ݣ�����̨��URL��ַ���£�
http://localhost:4040
Spark����̨����ͼ3��ʾ������Stages��Storage��Environment��Executors�ĸ���ǩҳ
ͼ3. Spark��ҳ����̨
��������
Spark�ṩ�������͵Ĺ�����������������Ⱥ�����е�Spark��������Ч�ʡ��ֱ��ǹ㲥�������ۼ�����
�㲥�������㲥����������ÿ̨�����ϻ���ֻ������������ҪΪ���������ñ����Ŀ��������ǿ����ô���������ݼ��ļ�Ⱥ�����еĽڵ���Ӹ�Ч��
����Ĵ���Ƭ��չʾ�����ʹ�ù㲥������
//
// Broadcast Variables
//
val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar.value |
�ۼ�����ֻ����ʹ����ز���ʱ�Ż������ۼ�������������Ժܺõ�֧�ֲ��С��ۼ���������ʵ�ּ�����������MapReduce������������͡�������add�����������ڼ�Ⱥ�ϵ��������ӵ�һ���ۼ��������С�������Щ��������ȡ������ֵ��ֻ������������ܹ���ȡ�ۼ�����ֵ��
����Ĵ���Ƭ��չʾ�����ʹ���ۼ�������������
//
// Accumulators
//
val accum = sc.accumulator(0, "My Accumulator")
sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x)
accum.value |
SparkӦ��ʾ��
��ƪ���������漰��ʾ��Ӧ����һ��������ͳ��Ӧ�á�����ѧϰ��Hadoop���д����ݴ���ʱ��ʾ��Ӧ����ͬ�����ǽ���һ���ı��ļ���ִ��һЩ��
�ݷ�����ѯ����ʾ���е��ı��ļ������ݼ�����С�������������κδ��룬ʾ�������õ���Spark��ѯͬ�������õ����������ݼ�֮�ϡ�
Ϊ�������۾��������ǽ�ʹ��Spark Scala Shell��
���������ǿ�һ����������Լ��ĵ����ϰ�װSpark��
ǰ��������
Ϊ����Spark�ܹ��ڱ�����������������Ҫ��װJava�������߰���JDK�����⽫����������ĵ�һ���С�
ͬ������Ҫ�ڵ����ϰ�װSpark����������ĵڶ����������������������
ע��������Щָ�����Windows����Ϊ���������ʹ�ò�ͬ�IJ���ϵͳ��������Ҫ��Ӧ����ϵͳ������Ŀ¼·����ƥ����Ļ�����
I. ��װJDK
1����Oracle��վ������JDK���Ƽ�ʹ��JDK 1.7�汾��
��JDK��װ��һ��û�пո��Ŀ¼�¡�����Windows�û�����Ҫ��JDK��װ����c:\dev�������ļ����£������ܰ�װ����c:
\Program Files���ļ����¡���c:\Program Files���ļ��е������а����ո����������װ������ļ����»ᵼ��һЩ���⡣
ע����Ҫ�ڡ�c:\Program Files���ļ����а�װJDK�ڶ������������ģ�Spark������
2�����JDK��װ���л���JDK 1.7Ŀ¼�µġ�bin���ļ��У�Ȼ��������������֤JDK�Ƿ���ȷ��װ��
java -version
���JDK��װ��ȷ�����������ʾJava�汾��
II. ��װSpark������
��Spark��վ���������°汾 ��Spark���ڱ��ķ���ʱ�����µ�Spark�汾��1.2������Ը���Hadoop�İ汾ѡ��һ���ض���Spark�汾��װ������������Hadoop
2.4����߰汾ƥ���Spark���ļ�����spark-1.2.0-bin-hadoop2.4.tgz��
����װ�ļ���ѹ�������ļ����У��磺c:\dev����
Ϊ����֤Spark��װ����ȷ�ԣ��л���Spark�ļ���Ȼ����������������Spark Shell������Windows�����µ�������ʹ��Linux��Mac
OS������Ӧ�ر༭�����Ա��ܹ�����Ӧ��ƽ̨����ȷ���С�
c:
cd c:\dev\spark-1.2.0-bin-hadoop2.4
bin\spark-shell |
���Spark��װ��ȷ�����ܹ��ڿ���̨������п���������Ϣ��
��.
15/01/17 23:17:46 INFO HttpServer: Starting HTTP Server
15/01/17 23:17:46 INFO Utils: Successfully started service 'HTTP class server' on port 58132.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.2.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Type :help for more information.
��.
15/01/17 23:17:53 INFO BlockManagerMaster: Registered BlockManager
15/01/17 23:17:53 INFO SparkILoop: Created spark context..
Spark context available as sc. |
���Լ�������������Spark Shell�Ƿ���������
����
�����������֮���Լ������������˳�Spark Shell���ڣ�
���������Spark Python Shell����Ҫ���ڵ����ϰ�װPython����������ز���װAnaconda������һ����ѵ�Python���а汾�����а�����һЩ�Ƚ����еĿ�ѧ����ѧ�����̺����ݷ��������Python����
Ȼ���������������������Spark Python Shell��
c:
cd c:\dev\spark-1.2.0-bin-hadoop2.4
bin\pyspark |
Sparkʾ��Ӧ��
���Spark��װ�������Ϳ�����Spark APIִ�����ݷ�����ѯ�ˡ�
��Щ���ı��ļ��ж�ȡ���������ݵ�����ܼ����ǽ�����һϵ�����µĺ������������ҽ��ܸ�����Spark���ʹ�õ�������
������������Spark API�������е�Word Countʾ���������û������Spark Scala
Shell�����ȴ�һ��Scala Shell���ڡ����ʾ�����������������ʾ��
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
val txtFile = "README.md"
val txtData = sc.textFile(txtFile)
txtData.cache() |
���ǿ��Ե���cache��������һ�����ɵ�RDD���浽�����У��ڴ�֮��Spark�Ͳ���Ҫ��ÿ�����ݲ�ѯʱ�����¼��㡣��Ҫע���
�ǣ�cache()��һ���ӳٲ����������ǵ���cacheʱ��Spark���������Ͻ����ݴ洢���ڴ��С�ֻ�е���ij��RDD�ϵ���һ���ж�ʱ���Ż�����ִ
�����������
���ڣ����ǿ��Ե���count��������һ�����ı��ļ����ж��������ݡ�
Ȼ�����ǿ���ִ�����������������ͳ�ơ����ı��ļ���ͳ�����ݻ���ʾ��ÿ�����ʵĺ��档
val wcData = txtData.flatMap(l => l.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
wcData.collect().foreach(println) |
�����鿴����������ʹ��Spark����API�Ĵ���ʾ������ο���վ�ϵ�Spark�ĵ���
�����ƻ�
�ں�����ϵ�������У����ǽ���Spark SQL��ʼ��ѧϰ�������Spark��̬ϵͳ���������֡�֮�����ǽ������˽�Spark
Streaming��Spark MLlib��Spark GraphX������Ҳ���л���ѧϰ��Tachyon��BlinkDB�ȿ�ܡ�
��
�ڱ����У������˽���Apache Spark������ͨ�����API������ɴ����ݴ����ͷ������������ǻ���Spark�ʹ�ͳ��MapReduceʵ�֣���Apache
Hadoop�������˱Ƚϡ�Spark��Hadoop������ͬ��HDFS�ļ��洢ϵͳ�����������Ѿ���Hadoop�Ͻ����˴���Ͷ�ʺͻ�����ʩ���裬��
��һ��ʹ��Spark��MapReduce��
���⣬Ҳ���Խ�Spark������Spark SQL������ѧϰ�Լ�Spark Streaming�����һ�𡣹����ⷽ����������ǽ��ں����������н��ܡ�
����Spark��һЩ���ɹ��ܺ������������ǿ��Խ�����������Spark�����һ������һ���������ǽ�Spark��Kafka��Apache
Cassandra�����һ������Kafka�����������ʽ���ݣ�Spark��ɼ��㣬���Cassandra
NoSQL���ݿ����ڱ�����������ݡ�
������Ҫ�μǵ��ǣ�Spark��̬ϵͳ�Բ����죬�ڰ�ȫ����BI�����ɵ�������Ȼ��Ҫ��һ���ĸĽ���
|






