| 绝大部分的大数据需求都来自于
Internet 技术的爆炸,这已经不是什么秘密。面向公众的应用程序可以拥有几百万用户,这个想法在 10-20
年前是闻所未闻的。如今,即使是一个普通网站,也可能拥有数百万用户,如果这些用户是活跃的,那么每天可能产生数百万个数据项。具有讽刺意味的是,创建大数据的基础架构和系统也可以反向工作,提供一些更好的方法来集成和使用该数据。有用的是,InfoSphere
BigInsights 通过一个简单的 REST API 支持数据作业的管理和执行。通过 Jaql 接口,我们可以运行查询,并直接从
Hadoop 集群中获取信息。本文将重点介绍这些系统如何协同工作,为捕捉数据提供丰富的基础,并提供了一??个用来再次备份信息的接口。
使用 REST 技术的应用程序
REST 是一个简单的易于使用的结构,用于和特定的服务及应用程序进行交互。它植根于许多技术,其中包括
XML-RPC 和 SOAP,当然还有 HTTP,它现在是无处不在的首选网络传输方法。
InfoSphere BigInsights 自带 Jaql 和相应的部署接口,使用户可通过
REST 接口访问它。为了运行 Jaql 接口,首先需要安装示例 Jaql 应用程序,您可以通过 InfoSphere
BigInsights 控制台完成此安装。
访问 http://servername:8080 或者,如果您位于同一台机器上,请访问
http://localhost:8080,并打开控制台。单击 Applications 选项卡,如图
1 所示。
图 1. Applications 选项卡
现在,单击页面左上角的 Manage 链接,如图 2 所示,然后选中 Ad
hoc Jaql query 应用程序,单击 Deploy。
图 2. Manage 链接
在完成应用程序部署后,要找到它的端点。在 REST 中,端点是应用程序的
URL。InfoSphere BigInsights 在应用程序部署时创建一个惟一的应用程序引用。
为了找到端点,可以使用一个 REST 调用来获得已配置的应用程序的列表。您可以使用任何
REST 客户端,包括浏览器。下面的示例使用了命令行工具 curl。首先,通过访问以下 URL 来获取应用程序列表:http://servername:8080/data/controller/catalog/applications:
$ curl -O http://192.168.0.20:8080/data/controller/catalog/applications。
这将创建一个名为 applications 的文件,它包含了所有已配置的应用程序和活动应用程序的详细信息。查看该文件将会显示包含应用程序定义的
XML。寻找包含 Jaql 的应用程序,如清单 1 所示。
清单 1. Applications 文件
<row>
<column>3d420497-e1a6-411f-9644-c40db1c290b6</column>
<column>Ad hoc Jaql query</column>
<column>The Ad hoc Jaql Query application runs a custom query
entered in the UI to analyze data.</column>
<column>samples</column>
<column>images/appicons/3d420497-e1a6-411f-9644-c40db1c290b6.png
</column>
<column>catalogStore/archive/3d420497-e1a6-411f-9644-c40db1c290b6.zip
</column>
<column>Query,SQL</column>
<column>DEPLOYED</column>
</row> |
第一个 <column> 块显示了惟一的应用程序 ID,未来的查询将会使用它。
为了确认已经获得正确的应用程序,可通过使用 REST URL 查看所访问的应用程序的详细信息,如清单
2 所示: http://servername:8080/data/controller/catalog/applications/applicationID。
清单 2. 获得关于某个应用程序的详细应用程序信息
$ curl -O http://servername:8080/data/controller/catalog/applications/applicationID
3d420497-e1a6-411f-9644-c40db1c290b6 |
清单 2 中的代码将会生成更详细的 XML 描述,如清单 3 所示。
清单 3. 详细的 XML 描述
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<application-template xmlns="http://biginsights.ibm.com/application">
<name>Ad hoc Jaql query</name>
<description>The Ad hoc Jaql Query application runs a custom
query entered in the UI to analyze data.</description>
<properties>
<property uitype="textfield" paramtype="TEXTAREA"
name="script" label="Jaql query"
isRequired="true" isOutputPath="false" isInputPath="false"
description=" Ad hoc Jaql query"/>
</properties>
<assets>
<asset type="WORKFLOW" id="Ad hoc Jaql query"/>
</assets>
<localContextPath>catalogStore/archive/3d420497-e1a6-411f-9644
-c40db1c290b6.zip</localContextPath>
<imagePath>images/appicons/3d420497-e1a6-411f-9644
-c40db1c290b6.png</imagePath>
<appId>3d420497-e1a6-411f-9644-c40db1c290b6</appId>
<creator>samples</creator>
<dfsPath>/user/applications/3d420497-e1a6-411f-9644
-c40db1c290b6/workflow</dfsPath>
<categories>Query,SQL</categories>
<runtimeDependencies>/biginsights/oozie/sharedLibraries/jaql</
runtimeDependencies>
</application-template> |
使用这些详细信息,将应用程序请求提交给运行 Jaql 查询的系统。相关的信息是属性列表。输出显示,只有一个属性:Jaql
查询文本。我们要劫持此属性,以便运行任意 Jaql 查询。
为了运行一个查询,我们将构造一个包含属性信息的 XML 文件。其基本结构如清单 4 所示。
清单 4. 包含属性信息的 XML 文件的基本结构
<runconfig>
<name>Hello Jaql</name>
<appid>3d420497-e1a6-411f-9644-c40db1c290b6</appid>
<properties>
<property>
<name>script</name>
<value paramtype='TEXTAREA'>'Hello World';</value>
</property>
</properties>
</runconfig> |
<appid> 是应用程序 ID,在前面步骤中获得已配置应用程序的列表时进行确定。script
<value> 是想执行的 Jaql 脚本。
为了提交一个作业,必须将此 XML(URL 编码的)作为参数值发送到不同的 REST 端点,将已编码的
XML 提供给 runconfig 参数,如清单 5 所示。
清单 5. 提交一个作业
$ curl -o t.out
"http://192.168.0.20:8080/data/controller/ApplicationManagement
?actiontype=run_application&runconfig=$jaqlxml" |
对 XML 进行编码,使用了多个 URL 编码的工具或函数之一,比如 PHP 中的 urlencode()
函数,或 JavaScript 中的 encodeURIComponent() 函数。
清单 6 将信息写出到一个 t.out 文件,它将包含执行 ID 和一个用 JSON 值表示的状态。
清单 6. 将信息写出到一个文件
{
"result":{
"oozie_id":"0000003-131017053452866-oozie-biad-W",
"status":"OK"
}
} |
如果状态是 “OK” 以外的任何状态,那么所提交的作业存在一个问题。两个常见的问题是,应用程序 ID
无效,或 XML 没有良好的结构或编码。
被返回的 oozie_id 是一个作业标识符,可用于在作业完成后从作业中获得输出。为了获得作业详细信息,请访问
REST 端点:http://<oozieHost>:<ooziePort>/oozie/v1/job/<oozieid>?show=info。例如,为了获得刚刚提交的作业的状态,可使用清单
7 中的代码。
清单 7. 获得刚刚提交的作业的状态
$ curl -o status.out "http://192.168.0.20:8280/oozie/v1/job/0000003
-131017053452866-oozie-biad-W?show=info" |
此代码生成文件 status.out,其中包含所执行的作业的 JSON 表示,如清单 8 所示。
清单 8. 生成文件 status.out
{
"actions" :[
{
"retries" :0,
"externalStatus" :"SUCCEEDED",
"externalId" :"job_201310170523_0004",
"status" :"OK",
"trackerUri" :"bivm:9001",
"toString" :"Action name[jaql1] status[OK]",
"errorCode" : null,
"endTime" :"Thu, 17 Oct 2013 12:22:58 GMT",
"id" :"0000003-131017053452866-oozie-biad-W@jaql1",
"startTime" :"Thu, 17 Oct 2013 12:22:38 GMT",
"consoleUrl" :"http://bivm:50030/jobdetails.jsp?jobid
=job_201310170523_0004",
"transition" :"end",
"stats" : null,
"name" :"jaql1",
"data" :"#\n#Thu Oct 17 08:22:58 EDT 2013\nhadoopJobs=\n",
"errorMessage" : null,
"conf" :"<jaql xmlns=\"uri:oozie:jaql-action:0.1\">\r\n
<job-tracker>bivm:9001</job-tracker>\r\n
<name-node>hdfs://bivm:9000</name-node>\r\n
<configuration>\r\n <property>\r\n
<name>mapred.compress.map.output</name>\r\n
<value>true</value>\r\n </property>\r\n
<property>\r\n <name>mapred.job.queue.name</name>\r\n
<value>default</value>\r\n </property>\r\n
</configuration>\r\n <script>adhoc.jaql</script>\r\n
<eval>setOptions( { conf:{ \"hadoop.job.ugi\":\"biadmin,\"
}} );\r\n\t\t\t\tsetOptions( { conf:{ \"user.name\":\"biadmin\" }} );\r\n \t
'Hello World';;</eval>\r\n</jaql>",
"externalChildIDs" : null,
"cred" :"null",
"type" :"jaql"
}
],
"appPath" :"hdfs://bivm:9000/user/applications/3d420497-e1a6-411f-9644
-c40db1c290b6/workflow",
"appName" :"jaql-adhoc",
"externalId" : null,
"status" :"SUCCEEDED",
"lastModTime" :"Thu, 17 Oct 2013 12:22:59 GMT",
"createdTime" :"Thu, 17 Oct 2013 12:22:38 GMT",
"toString" :"Workflow id[0000003-131017053452866-oozie-biad-W] status[SUCCEEDED]",
"group" : null,
"run" :0,
"endTime" :"Thu, 17 Oct 2013 12:22:59 GMT",
"user" :"biadmin",
"id" :"0000003-131017053452866-oozie-biad-W",
"startTime" :"Thu, 17 Oct 2013 12:22:38 GMT",
"consoleUrl" :"http://bivm:8280/oozie?job=0000003-131017053452866-oozie-biad-W",
"acl" : null,
"progress" :1,
"conf" :"<configuration>\r\n <property>\r\n
<name>oozie.libpath</name>\r\n
<value>/biginsights/oozie/sharedLibraries/jaql</value>\r\n
</property>\r\n <property>\r\n
<name>oozie.wf.application.path</name>\r\n
<value>hdfs://bivm:9000/user/applications/3d420497
-e1a6-411f-9644-c40db1c290b6/workflow</value>\r\n
</property>\r\n <property>\r\n
<name>jobTracker</name>\r\n
<value>bivm:9001</value>\r\n
</property>\r\n <property>\r\n
<name>script</name>\r\n
<value>'Hello World';</value>\r\n
</property>\r\n <property>\r\n
<name>queueName</name>\r\n
<value>default</value>\r\n
</property>\r\n <property>\r\n
<name>nameNode</name>\r\n
<value>hdfs://bivm:9000</value>\r\n
</property>\r\n <property>\r\n
<name>user.name</name>\r\n
<value>biadmin</value>\r\n
</property>\r\n</configuration>",
"parentId" : null
} |
status.out 文件的关键部分是 status 行,它说明该作业已成功完成。URL 也恨有用,它在
consoleUrl 中提供了有关作业的更多信息。
远程访问的最后一部分是利用 WebHDFS 接口,它通过 HTTP 提供对存储在 Hadoop 中的数据的访问。此功能默认情况下安装在
InfoSphere BigInsights 中并在其中使用。为了测试这个功能正在工作,请访问以下 URL:http://servername:14000/webhdfs/v1?op=GETHOMEDIRECTORY&user.name=biadmin。
需要使用 user.name 参数,而且该参数必须与 Hadoop 安装中的有效用户相匹配。op 参数(GETHOMEDIRECTORY)应返回用户的
home 目录。信息以一个 JSON 对象的形式返回:{"Path":"\/user\/biadmin"}。
要真正从 HDFS 下载一个文件,可使用 OPEN 操作。例如,从 biadmin 用户的 chicago
目录下载文件 chicago.csv,使用清单 9。
清单 9. 从 HDFS 下载一个文件
$ curl -o chicago.csv "http://192.168.0.20:14000/webhdfs/v1/user/biadmin/chicago/
chicago.csv?user.name=biadmin&op=OPEN" |
利用这一组基本的 REST 和 HTTP 接口,使用一个很好的顺序对数据执行任意 Jaql 查询:
通过 REST,使用 XML 将作业提交到 Jaql 应用程序服务。
通过 REST 检查作业状态。
通过 REST,使用 WebHDFS 下载生成的文件。
在尝试这个顺序之前,我们快速介绍一下通过 Jaql 处理数据。
通过 Jaql 加载和读取数据
Jaql 的工作原理是直接从一个源读取和写入数据,处理并解析内容,然后写回该信息。Jaql 是一个查询分析器,它访问数据(通过任何可访问的手段),对这些信息进行查询,并返回数据。Jaql
其实是针对数据处理而设计的一种小语言,但它也包括对读写 HDFS 的支持。
虽然在实践中 Jaql 可以读取和写入多种数据存储,但最佳的性能和处理是在 Jaql 可以从存储并行读取数据时实现的。Jaql
实际上从 I/O 层接收有关数据是以串行还是并行方式读入的信息。这种能力使得它非常适合于处理来自 HDFS
的信息,特别适合于信息广泛分布在某个大型集群中的情况。
在最基本的层面上,可以使用 read() 和 write() 函数在 Jaql 中读写数据。在这个层面试用
Jaql 的最简单方法是使用 jaqlshell (/opt/ibm/biginsights/jaql/bin/jaqlshell),它提供一个交互式界面,可以在
Jaql 提示符下执行语句,如清单 10 所示。
清单 10. Jaql 提示符
[biadmin@bivm ~]$ /opt/ibm/biginsights/jaql/bin/jaqlshell
jaql> |
例如,要读取一个本地文件,可使用 read('file:///chicago.csv');。要从 HDFS
读取文件,可使用 read(hdfs('chicago.csv'));。
在默认情况下,Jaql 会预读取 Hadoop sequence 文件,但 Jaql 还包括用于处理不同文件格式(包括
CSV、JSON 等)的特定解析器。这种灵活的模式提供了明显的优势,可以在不同目标中读写不同文件格式的数据。例如,要读取一个分隔符的文件,可以使用
del() 函数:read(del('chicago.csv'));。该函数读入数据,标识内容,并将它们放在一个内部
JSON 结构中,如清单 11 所示。
清单 11. 将它放入一个内部 JSON 结构
[
[
"03/12/2011 12:20:44 AM",
"28",
"2",
"11",
"29.32"
],
[
"03/12/2011 12:20:44 AM",
"29",
"8",
"56",
"19.940000000000001"
],
...
] |
这种格式很有用,但进一步讲,它可以在文件字段名称中分配单个字段。从长远来看,字段名称使得数据更具可塑性,因为它使得我们可以基于字段而不是隐含的列编号来查询和运行代码。清单
12 显示了如何分配字段名称。
清单 12. 在文件字段名称中分配单个字段
read(del('chicago/chicago.csv',{ schema: schema { logdate: string, region: long,
buscount: long, logreads: long, speed: double}})); |
使用文本或 JSON 文件的好处是,可以采用行方式对它们进行读写,这非常适合配合 HDFS 和 Hadoop
使用。请注意这里使用了不同的类型。输入中的原始日期字符串(取自 Chicago Traffic Tracker)不是
JSON 格式的日期信息,所以在对此日期类型进行进一步处理之前不能使用它们。如果需要达到这种详细程度,Jaql
提供了一个完整的解析器来处理这些数据。
然后,输出变成了一个记录数组,如清单 13 所示。
清单 13. 记录数组
...
{
"logdate":"02/11/2013 09:51:23 AM",
"region":26,
"buscount":54,
"logreads":910,
"speed":26.59
},
{
"logdate":"02/11/2013 09:51:23 AM",
"region":27,
"buscount":27,
"logreads":336,
"speed":30.0
},
... |
要在 Jaql 中处理信息,您可以将信息指定给某个变量,如清单 14 所示。
清单 14. 将信息指定给某个变量
x = read(del('chicago/chicago.csv',{ schema: schema { logdate: string,
region: long, buscount: long, logreads: long, speed: double}})); |
Jaql 在这方面的灵活性在 Hadoop 外部非常有用。例如,Jaql 可以用来读取本地文件系统中的数据,并将数据写入
HDFS。它也可以用于通过程序将文本或 CSV 文件转换为 JSON。在我们的 Web 应用程序中,我们可以利用这种灵活性,从
HDFS 加载数据,处理它,并写出一个 JSON 文件,可以从 Web 界面中更方便地使用该文件来提供和显示查询的结果。
然后,可以引用数据,并在内部转换它,使用 x -> write(seq('chicago.seq'));,可以将它写出为一个序列文件,或使用
jsonText() 函数显式地将它转换为文件中的相应 JSON:x -> write(jsonText('chicago.json'));。查看
Jaql 的文档,获得更多读写二进制、序列、JSON 和其他格式的复杂示例(参阅 参考资料)。
在从 Web 界面编写查询时,我们将使用 JSON 输出格式,以便写出一个以后可以使用
WebHDFS 访问的 JSON 文件。
执行 Jaql 查询
在 Jaql 中有数据之后(通过显式或隐式地读取数据),就可以对数据结构执行转换和查询。该转换可以很简单,也可以是基于分析的数据结构的类似于全
SQL 的查询。
我们将跳过基本转换,因为与对数据执行 SQL 语句相比,它们对我们不太有用。来自我们的数据处理的已定义字段将成为您可以选择和查询的字段,而且变量(上面示例中的
x)是表格。因此,我们可以执行选择特定字段的基本查询,如清单 15 所示。
清单 15. 执行选择特定字段的基本查询
jaql> SELECT region FROM x;
[
...
{
"region":3
},
{
"region":4
},
{
"region":5
}
] |
执行涉及函数和分组的复杂查询,请参见清单 16。
清单 16. 执行涉及函数和分组的复杂查询
jsql> SELECT region,avg(speed) FROM x GROUP BY region;
[
...
{
"region":26,
"#1":29.466060606060772
},
{
"region":27,
"#1":28.768625178975057
},
{
"region":28,
"#1":21.32377419211978
},
{
"region":29,
"#1":19.889688925634466
}
] |
如果您已经向内部结构加载多个文件,那么可以执行联接,将数据组合在一起。
输出可以分配给一个变??量,然后将查询的结果写出到某个文件,我们可以将这些操作都放在一个脚本中,如清单
17 所示。
清单 17. 将输出分配给某个变量并将查询的结果写出到某个文件
x = read(del('chicago/chicago.csv',{ schema: schema { logdate: string,
region: long, buscount: long, logreads: long, speed: double}}));
y = SELECT region,avg(speed) FROM x GROUP BY region;
y -> write(jsonText('output.json')); |
清单 17 中的脚本将执行三个步骤:读取源文件,执行查询,然后将信息写出到一个 JSON 格式的文件。
我们现在有了如何提交作业、访问其状态、编写查询,以及读取生成的输出文件的基本结构。
构建一个 Web 界面来访问大数据存储
各部分都准备好之后,我们就可以编写一个基本的 HTML 界面来访问 InfoSphere BigInsights
服务器,它将执行任意 Jaql 脚本并写出要在页面中查看的数据。此界面的 HTML 如清单 18 所示。
清单 18. 界面的 HTML
<html>
<head>
<title>JAQL Query for Chicago Traffic Tracker</title>
<script src="jquery.js"></script>
<script src="work.js"></script>
</script>
</head>
<body>
<h1>JAQL Query Executor</h1>
<div><textarea id="query" name="query" rows="10" columns="80"></textarea></div>
<div>Output Filename:<input id="filename" name="filename"/></div>
<a href="#" onclick="runquery();">Run Query</a>
<div id="status"/>
<div id="result"/>
|
我们将使用 jQuery 执行 AJAX 风格的数据加载。
基本结构提供了两个输入框:一个用于输入 Jaql 查询文本,另一个用于输入保存输出信息的文件的名称。我们不希望从脚本解析文件名称,所以我们将单独获取它,以确保我们加载了正确的数据。一个简单的链接可用于执行查询,状态和结果
DIV 用于保存当前活动和结果文件的信息。
如图 3 所示的页面本身填充了脚本的信息,显示在单击 Run Query 之前的应用程序。
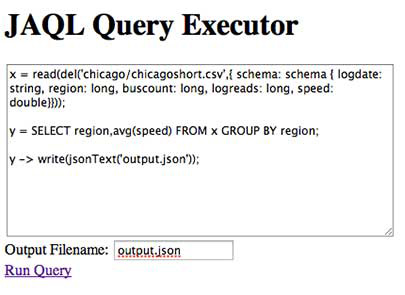
图 3. 单击 Run Query 之前的应用程序
该应用程序背后的 JavaScript 被分为四个主要程序块。
第一块定义应用程序所使用的一些全局变量:作业 ID(一旦已经提交了作业)、文件名称(用于加载结果),以及一个用于保存间隔定时器对象的变量,在等待作业完成的时候将会使用它。
本节的主函数是 runquery() 函数,在单击 Run Query 时被调用。runquery()
函数可以更新状态并调用 submitquery() 函数,它将会实际执行一些工作,如清单 19 所示。
清单 19. 更新状态并调用 submitquery() 函数
var jobid;
var checkinterval;
var filename;
function runquery() {
$('#status').html('Executing remote query');
$('#status').html($('#query').val());
submitquery();
} |
第二块包含 submitquery() 函数的定义。该函数将会读取 TEXTAREA 的内容,其中包含要执行的
Jaql 脚本,该脚本嵌入在 XML 中,以便运行配置,然后通过 jQuery ajax() 函数将作业提交给应用服务器。
若提交失败,我们将会报告错误,但是如果提交成功了,我们就会从返回的 JSON 结构中提取 Oozie
作业 ID,运行 checkjobstatus() 函数来获得当前运行状态,并创建一个间隔定时器,每 5
秒调用一次相同的 checkjobstatus() 函数,以检查状态。请记住,作业提交是通过一个包含 XML
作业规范的 REST 请求完成的,必须对该规范进行转义(使用 encodeURIComponent()),如清单
20 所示。
清单 20. submitquery() 函数
function submitquery() {
var startfrag = "<runconfig><name>Jaql Remote
Query</name><appid>3d420497-e1a6-411f-9644-c40db1c290b6
</appid>
<properties><property><name>script</name><value
paramtype='TEXTAREA'>";
var endfrag = "</value></property></properties></runconfig>";
var jobspec = startfrag + $('#query').val() + endfrag;
remoteurl = "http://192.168.0.20:8080/data/controller/ApplicationManagement
?actiontype=run_application&runconfig=" + encodeURIComponent(jobspec);
$.ajax(remoteurl,
{
error: function() {
$('#status').html("Error submitting job");
},
success: function(data) {
jobid = data.result.oozie_id;
$('#status').html("Job Submitted:" + data.result.status
+ " ID:" + jobid);
checkjobstatus();
checkinterval = setInterval(checkjobstatus,5000);
},
});
} |
checkjobstatus() 函数使用 REST 接口获取作业状态,它使用了上一步中提取的作业 ID。因为这个函数每隔
5 秒被调用一次,所以它必须是独立的,也就是说,它必须提交 REST 请求,更新状态,如果作业被认定为是成功的,则关闭时间间隔并执行函数(getoutputfile()),以便检索由
Jaql 脚本生成的查询输出,如清单 21 所示。
清单 21. checkjobstatus() 函数
function checkjobstatus() {
var checkurl = "http://192.168.0.20:8280/oozie/v1/job/" + jobid + "?show=info";
$.ajax(checkurl,
{
error: function() {
$('#status').html("Error getting status");
},
success: function(data) {
jobstatus = data.status;
if (jobstatus) {
$('#status').html("Current Job Status:" + jobstatus);
if (jobstatus == 'SUCCEEDED') {
clearTimeout(checkinterval);
getoutputfile();
}
}
else {
$('#status').html("Current Job Status:Unknown");
}
},
});
} |
在成功执行脚本之后,最后一个函数将会使用 WebHDFS 访问由脚本生成的文件,如清单 22 所示。
清单 22. getoutputfile() 函数
function getoutputfile() {
filename = $('#filename').val();
var fileurl = "http://192.168.0.20:14000/webhdfs/v1/user/biadmin/" + filename +
"?user.name=biadmin&op=OPEN";
$.ajax(fileurl,
{
error: function() {
$('#status').html("Error getting result file");
},
success: function(data) {
$('#result').html(data);
},
}); |
执行的顺序基本上很直观:
1.输入查询。
2.单击 Run Query。
3.将作业提交给应用服务器。
4.通过 REST 检查作业状态。
5.重复步骤 4,直到作业状态为 "succeeded"。
6.下载所生成的输出文件并显示它。
假设您的 Jaql 脚本没有问题,那么您应该获得类似于图 4 的输出。
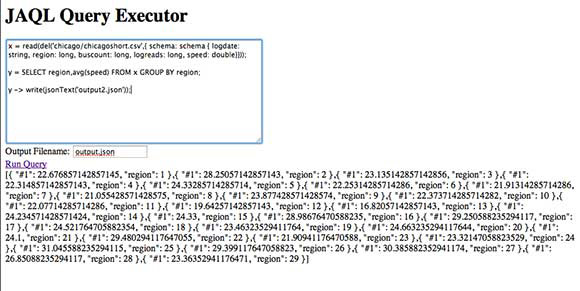
图 4. 输出
结束语
InfoSphere BigInsights 自带了一系列令人印象深刻的应用程序,可以配置和运行您需要的任何脚本。通过利用提供给这些系统的标准
REST 接口,我们可以为 Hadoop 和底层的数据处理函数构建一个完全基于 Web 的接口,无需编写复杂的代码或开发
MapReduce 函数。使用 Jaql 为我们提供了在数据上运行任意查询的灵活性,即使数据没有被直接格式化为可处理的格式,我们也可以通过类似于
SQL 的接口轻松地将其转换成可处理的结构。利用一点点 JavaScript 和 jQuery 的魔法,整个界面就会变得更小、更紧凑,足以在任何地方运行。
|






