|
自2014年3月份跻身Apache顶级项目(TLP),Spark已然成为ASF最活跃的项目之一,得到了业内广泛的支持——2014年12月发布的Spark 1.2版本包含了来自172位Contributor贡献的1000多个commits。
2014年的大数据领域,Apache Spark(以下简称Spark)无疑最受瞩目。Spark,出自名门伯克利AMPLab之手,目前由商业公司Databricks保驾护航。自2014年3月份跻身Apache顶级项目(TLP),Spark已然成为ASF最活跃的项目之一,得到了业内广泛的支持——2014年12月发布的Spark 1.2版本包含了来自172位Contributor贡献的1000多个commits。而在2014一整年中,Spark共发布了大小9个版本(包含5月底发布具有里程碑意义的1.0版本),其社区活跃度可见一斑。值得一提的是,2014年11月,Databricks基于AWS完成了一个Daytona Gray类别的Sort Benchmark,并创造了该测试的新纪录。本文将概括性地总结Spark在2014年的发展。
Spark 2014,星星之火已成燎原之势
首先,Spark会议及相关交流。目前,世界范围内最权威的Spark领域会议无疑是Spark Summit,已于2013年与2014年连续成功举办两届,来自全球各地的工程师们与会分享了各自的Spark使用案例。鉴于目前Spark的火爆态势,Spark Summit将在2015年分Spark Summit East与Spark Summit West两次举行。着眼国内,首届中国Spark技术峰会(Spark Summit China)于2014年4月在北京举办,据统计,全国各大互联网公司几乎都出席了会议。因此,大家可以期待下今年的Spark Summit China又会带来怎样的惊喜。除去这样比较大型的会议,Spark Meetup也不定期地在全球各地举行,截止本文写作时,已有来自13个不同国家的33个城市举办过Spark Meetup,国内目前已经举办Spark Meetup的城市有四个,分别是北京、杭州、上海和深圳。除了线下交流,线上也会组织一些公开课,供那些不方便到线下交流的朋友参加。由此可以看出,2014年关于Spark的交流活动非常频繁,这对推动Spark发展是大有裨益的。
其次,在2014年,各大厂商相继宣布与Databricks进行合作。其中,Cloudera早在2013年底即宣布将在其发行版中添加Spark,而后又有更多的企业加入进来,如Datastax、MapR、Pivotal及Hortonworks等。由此可见,Spark已得到了众多大数据企业的认可,而这些企业也确实将自己的产品与Spark进行了紧密的集成。譬如Datastax将Cassandra与Spark进行了集成,使得Spark可以操作Cassandra内的数据,又譬如ElasticSearch也和Spark进行了集成,更多这方面的动作可参考Spark Summit 2014中提到的相关内容。
此外,Spark在2014年也吸引了更多企业的落地使用。国外比较知名的有Yahoo! 、eBay、Twitter、Amazon、SAP、Tableau及MicroStrategy等;同时,值得高兴的是,在Spark落地实践上,国内企业也不遑多让,淘宝、腾讯、百度、小米、京东、唯品会、爱奇艺、搜狐、七牛、华为及亚信等知名企业都进行了生产环境使用,从而也促成了越来越多的华人工程师为Spark提交代码,特别是Spark SQL这个组件,甚至有一半左右的Contributor都是华人工程师。各大知名企业的使用,大幅度提升了整个业界使用Spark的兴趣和信心,我们有理由相信,在2015年,使用Spark的企业数量必会是井喷式的爆发。与此同时,已经出现了一批基于Spark做应用的创业公司,而其中有不少发展得相当不错,如Adatao和TupleJump。
随着市场上对Spark工程师需求的日益加强,Databricks也适时地推出了Spark开发者认证计划,第一次线下测试已经于2014年11月在西班牙巴塞罗那举行。截止到本文写作时(2015年1月),Spark开发者认证还不支持线上测试,但线上测试平台不久后就会上线。
基于Spark持续健康发展的生态系统,越来越多的企业和机构在Spark上面开发应用和扩展库。随着这些库的增长,Databricks在2014年圣诞节前夕上线了一个类似pip的功能来跟踪这些库的网站:http://spark-packages.org,目前已经有一些库入驻Spark Packages,其中有几个相当不错,比如:dibbhatt/kafka-spark-consumer、spark-jobserver/spark-jobserver和mengxr/spark-als。
Spark 2014,解析众人拾柴下的技术演进
如图1所示,可以看出Spark包含了批处理、流处理、图处理、机器学习、即席查询与关系查询等功能,这就意味着我们只需要一个框架就可以满足各种使用场景的需求。如果放在以前,我们可能需要为每个功能都准备一套框架,譬如采用Hadoop MapReduce来做批处理和采用Storm来做流式处理,这样做带来的结果是我们必须分别针对两套计算框架编写不同的业务代码,而编写出的业务代码也几乎无法重用;另一方面,为了使系统稳定,我们还得额外投入人力去深入理解Hadoop MapReduce及Storm的原理,这将造成很大的人力开销。当采用Spark后,我们只需要去理解Spark即可,另一个吸引人的地方在于Spark批处理与流计算的业务代码几乎可以完全重用,这也就意味着我们只需要编写一份逻辑代码就可以分别运行批处理与流计算。最后,Spark可以无缝使用存储在HDFS上的数据,无需任何数据迁移动作。
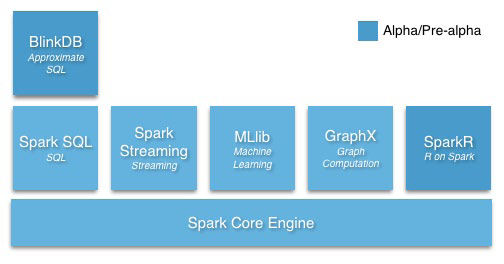
图1 Spark Stack
同时,由于现存系统必须要与以HDFS为代表的分布式文件系统进行数据共享和交换,由此造成的IO开销大幅度地降低了计算效率;除此之外,反复的序列化与反序列化也是不可忽略的开销。鉴于此,Spark中抽象出了RDD的概念,并基于RDD定义了一系列丰富的算子,MapReduce只是其中一个非常小的子集,与此同时,RDD也可以被缓存在内存中,从而迭代计算可以充分地享受内存计算所带来的加速效果。与MapReduce基于进程的计算模型不一样,Spark基于的是多线程模型,这也意味着Spark的任务调度延迟可以控制在亚秒级,当任务特别多的时候,这么做可以大幅度降低整体调度时间,并且为基于macro batch的流式计算打下基础。Spark的另一个特色是基于DAG的任务调度与优化,Spark不需要像MapReduce一样为每一步操作都去调度一个作业,相反,Spark丰富的算子可以更自然地以DAG形式表达运算。同时,在Spark中,每个stage内部是有pipeline优化的,所以即使我们不使用内存缓存数据,Spark的执行效率也要比Hadoop高。最后Spark基于RDD的lineage信息来容错,由于RDD是不可变的,Spark并不需要记录中间状态,当RDD的某些partition丢失时,Spark可以利用RDD的lineage信息来进行并行的恢复,不过当lineage较长时,还是推荐用户适时checkpoint,从而减少恢复时间。
以下我们沿着2014年各主要版本的发布轨迹简单总结下Spark及各个组件(Spark Streaming、MLlib、GraphX及Spark SQL)在新功能及稳定性上做出的努力。
Spark 0.9.x
2014年2月初,Databricks发布了Spark的第一个版本0.9.0,这一版本带来的最直接的变化是将Scala从2.9.x升级到了2.10。由于Scala在那时并没有做到二进制向下兼容,所以大家不得不使用Scala2.10重新编译业务代码,这也算是个插曲吧。
这个版本最大的贡献应该是加入了配置系统,即SparkConf。在这之前,各种属性参数都直接作为Master的参数传进去,而有了SparkConf后,Master就不需要管这些了,各种参数在SparkConf中配置完成后,将SparkConf传给Master即可,这在测试中是非常有用的。另外在提交任务时,允许把Driver程序放到集群中的某台服务器上运行,以前只能放在集群外的服务器上运行。
Spark Streaming终于在这个版本“自信”地结束了alpha版本,并且加入了HA模式,现在大家知道,其实那时的HA并不能保证数据不丢失,这一点到1.2的时候我们再谈。在Spark Streaming跳出alpha的同时,新增加了alpha组件GraphX,GraphX是一个分布式图计算框架,在这个版本中提供了一些标准算法,如PageRank、connected components、 strongly connected components与triangle counting等等,但稳定性还有待加强。MLlib在这个版本中增加了常用的朴素贝叶斯算法,不过更引人注意的是,MLlib终于也开始支持Python API了(需要NumPy的支持)。
社区分别于4月份与7月份发布了两个maintena-nce版本:0.9.1与0.9.2,修复了一些Bug,无新的feature加入,不过0.9.1倒是Spark成为Apache顶级项目后的第一个发布。
Spark 1.0.x
用“千呼万唤始出来”形容Spark1.0一点都不为过,作为一个里程碑式的发布,Spark社区也是非常谨慎,在发布了多个RC版本后,终于在5月底正式发布了1.0版本。这个版本有110多位Contributor,历经4个月的共同努力,而1.0版本也毫无悬念地成为了Spark诞生以来最大的一次发布。作为1.x的开端版本,Spark社区也对API在以后所有1.x版本上的兼容性做了保证。另一方面,Spark 1.0的Java API开始支持Java 8的lambda表达式,这多少让一些必须用Java来写Spark程序的用户得到了不小的便利。
万众瞩目的Spark SQL终于在这个版本中亮相,尽管只是alpha版本,但全球各地的Spark用户们已经迫不及待开始尝试,这一势头至今仍在延续,Spark SQL现在是Spark中最活跃的组件,没有之一。提到Spark SQL,不得不提Shark,Databricks在Spark Summit 2014上宣布Shark已经完成了其学术使命,且Shark的整体设计架构对Hive的依赖性太强,难以支持其长远发展,所以决定终止Shark开发,全面转向Spark SQL。Spark SQL支持以SQL的形式来操作结构化数据,并且也支持使用HiveContext来操作Hive中的数据。在这个方面,业内对SQL on Hadoop的超强需求决定了Spark SQL必将长期处于快速发展的态势。值得一提的是,Hive社区也推出了一个Hive on Spark的项目——将Hive的执行引擎换成Spark。不过从目标上看,Hive on Spark更注重于针对Hive彻底地向下兼容性,而Spark SQL更注重于Spark与其他组件的互操作和多元化数据处理。
MLlib方面也有一个较大的进步,1.0开始终于支持稀疏矩阵了,这对MLlib的使用者来说绝对是一个让人欢欣鼓舞的特性。在算法方面,MLlib也增加了决策树、SVD及PCA等。Spark Streaming与GraphX的性能在这个版本中都得到了增强。
此外,Spark提供了一个新的提交任务的工具,称为spark-submit,无论是运行在Standalone模式,还是运行在YARN上,都可以使用这个工具提交任务。从这一点上说,Spark统一了提交任务的入口。
最后,社区在7月和8月份分别发布了1.0.1与1.0.2两个maintenance版本。
Spark 1.1.x
Spark 1.1.0在9月如期而至。此版本加入了sort-based的shuffle实现,之前hash-based的shuffle需要为每个reducer都打开一个文件,导致的结果是大量的buffer开销与低效的I/O,而最新sort-based的shuffle实现能很好地解决上述问题,当shuffle数据量特别大的时候,sort-based的shuffle优势尤其明显。需要指出的是,和MapReduce针对KV排序不一样,sort-based是按照partition序号进行排序的,在partition内部并不排序。但是1.1中默认的shuffle方式还是基于hash的,到1.2中才会把sort-based作为默认的shuffle方式。
Spark SQL在这个版本里加入了不少新特性。最值得关注的是加入了JDBC Server的功能,这意味着用户可以只写JDBC代码就可以享受Spark SQL的各种功能。
MLlib引入了一个用于完成抽样、相关性、估计、测试等任务的统计库。之前呼声很高的特征抽取工具Word2Vec和TF-IDF也被加进了此版本。除了增加一些新的算法之外,MLlib性能在这一版本中得也到了较大的提升。比起MLlib,GraphX在这一版并无特别大的改变。
Spark Streaming在这一版本的数据源中加入了对Amazon Kinesis的支持,只不过国内用户对这个数据源支持的兴趣不是很大,对于国外用户的意义更多一些。不过在这个版本中,Spark Streaming改变了从Flume取得数据的方式,之前是Flume push数据到executor/worker中,但在这种模式下,当executor/worker挂掉后,Flume便无法再正常地push数据。所以现在把push改成了pull,这意味着即使某个receiver挂掉后,也能保证在其他worker上新启动的receiver也能继续正常地接收数据。另一个重要的改进是加入了限流的功能,譬如之前Spark Streaming在读取Kafka中topic数据时经常会发生OOM,而加入限流后,OOM基本不再发生。Spark Streaming与MLlib的结合是另一个不得不提的全新特性,利用Streaming的实时性在线训练模型,但当下只是一个比较初级的实现。
在11月底发布的maintenance版本1.1.1中修复了一个较大的问题,之前在使用外部数据结构时(ExternalAppendOnlyMap与ExternalSorter)会产生大量非常小的中间文件,这不但会造成“too many open files”的异常,也会极大地影响性能,1.1.1版本对其进行了修复。
Spark 1.2.0
12月中旬发布了1.2,不得不说Spark社区在控制发布进度工作上做得很赞。在此版本中,首当其冲的就是把sort-based shuffle设置成了默认的shuffle策略。另一方面,在数据传输量非常大的情况下,connection manager终于换成Netty-based的实现了,以前的实现非常慢的原因是每次都要从磁盘读到内核态,再到用户态,再回到内核态进入网卡,现在用zero-copy来实现,效率高了很多。
对于Spark Streaming说,终于也算是个小小的里程碑,开始支持fully H/A模式。以前当driver挂掉的时候,可能会丢失掉一小部分数据。现在加上了一层WAL(Write Ahead Log),每次receiver收到数据后都会存在HDFS上,这样即使driver挂掉,当它重启起来后,还是可以接着处理。同时大家也需要注意 unreliable receivers和reliable receivers的区别,只有用户使用reliable receivers才能保证数据零丢失。
MLlib最大变动是引入了新的pipeline API,可以更加便捷地搭建机器学习相关的全套流水线,其中还包括了以Spark SQL SchemaRDD为基础的dataset API。
GraphX结束alpha正式发布,同时提供了stable API,这意味着用户不需要担心现有代码以后会因API的变化而改动了。此外,新的核心API aggregateMessages也替代掉了mapReduceTriplet,大家要注意这个变动。
Spark SQL最重要的特性毫无疑问应该属于external data source,此API让开发者可以更容易地开发出对接外部数据源的spark connector,统一用SQL操作所有数据源,同时也可以push predicates to data source,譬如你要从HBase取数据后做一些筛选,一般我们需要把数据从HBase全取出来后在Spark引擎中筛选,现在可以把这个步骤推到data source端,让用户在取数据的时候就可以筛选。另一个值得一提的是现在cacheTable和原生的cache已经统一了语义,并且性能和稳定性也有显著提升,不但内存表支持predicates pushdown,可以基于统计信息跳过批量数据,而且建内存buffer时分段建立,因此在cache较大的表时也不再会OOM。
由于篇幅原因,以上我们简单总结了Spark在2014年的各个版本中比较重要的特性,但有一个功能的增强始终贯穿其中——YARN,由于目前很多公司都把不同的计算框架跑在YARN上,所以Spark对YARN的支持肯定会越来越好,事实上Spark确实在这方面做了很多工作。
结语
2014年对Spark是非常重要的一年,不仅因为发布了里程碑式的1.0版本,更重要的是通过整个社区的努力,Spark变得越来越稳定与高效,也正在被越来越多的企业采用。在2015年,随着社区不断的努力,相信Spark一定会达到一个新的高度,在更多的企业中扮演更重要的角色。
感谢来自Databricks公司的Reynold Xin和连城给本文review,并提供宝贵建议。
|






