|
并行执行计划中典型的串行点
现实世界中,由于使用不当,并行操作无法并行,或者并行执行计划效率低下,没有获得期望的性能提升。本节举几个典型例子。
- 在sql中使用rownum,导致出现PX SEND 1 SLAVE操作,所有数据都需要分发到一个PX进,以给每一行记录赋值一个唯一的rownum值,以及BUFFER SORT等阻塞操作。
- 使用用户自定义的pl/sql函数,函数没有声明为parallel_enable,导致使用这个函数的sql无法并行。
- 并行DML时,没有enable parallel dml,导致DML操作无法并行。
Rownum,导致并行执行计划效率低下
在’数据倾斜对不同分发方式的影响’小节中,我们新建一个表lineorder_skew把lineorder的lo_custkey列90%的值修改为-1。因为lo_custkey是均匀分布的,我们可以通过对lo_custkey列求模,也可以通过对rownum求模,把90%的数据修改为-1。使用如下的case when语句:

通过以下的建表sql来测试两种用法时的sql执行性能,并行度为16。
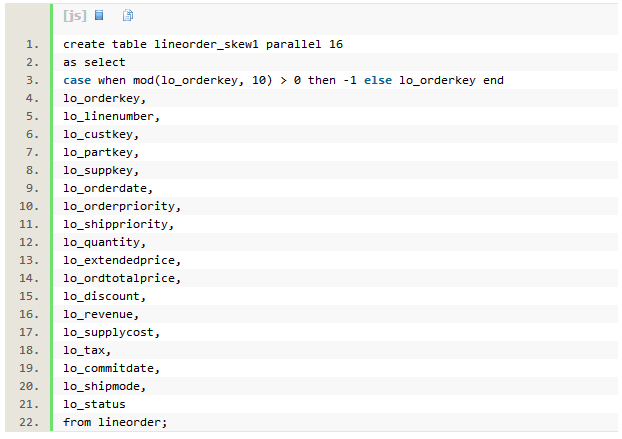
不使用rownum时,create table执行时间为1分钟,db time为15.1分钟。QC只分配了一组 PX进程,每个蓝色的PX进程以基于数据块地址区间为单位,并行扫描lineorder表,收集统计信息,并加载到lineorder_skew1表。没有数据需要分发,每个PX进程一直保持活跃,这是最有效率的执行路径。
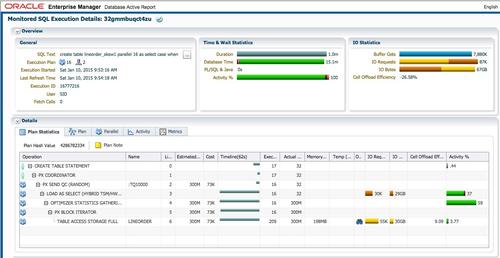
大部分时间,AAS=16。
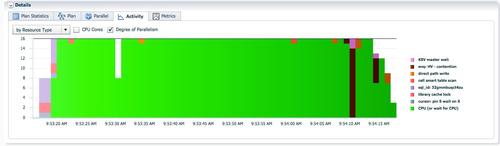
使用rownum时,create table执行时间为22.3分钟,db time为38.4分钟。SQL的执行时间为使用lo_orderkey时的22倍。

执行计划中出现两组PX进程,PX SEND 1 SLAVE和BUFFER SORT两个操作在之前的测试没有出现过。根据跟随table queue顺序的原则,我们来阅读这个执行计划:
- 蓝色的PX进程并行扫描lineorder,通过tablequeue0把所有数据分发给一个红色的PX进程 (第10~12行)。因为rownum是一个伪列,为了保证每一行记录拥有一个唯一行号,对所有数据的rownum赋值这个操作只能由一个进程完成,为rownum列赋值成为整个并行执行计划的串行点。这就是出现PX SEND 1 SLAVE操作,性能急剧下降的原因。这个例子中,唯一活跃的红色PX进程为实例1 p008进程。Lineorder的300M行记录都需要发送到实例1 p008进程进行rownum赋值操作,再由这个进程分发给16个蓝色的PX进程进行数据并行插入操作。
- 实例1 p008进程接收了16个蓝色PX进程分发的数据,给rownum列赋值(第8行count操作)之后,需要通过tablequeue1把数据分发给蓝色的PX进程。但是因为通过tablequeue0的数据分发的还在进行,所以执行计划插入一个阻塞点BUFFER SORT(第7行),把rownum赋值之后的数据缓存到临时空间,大小为31GB。
- Tablequeue0的数据分发结束之后,实例1 p008把31GB数据从临时空间读出,通过tablequeue1分发给16个蓝色的PX进程进行统计信息收集和插入操作
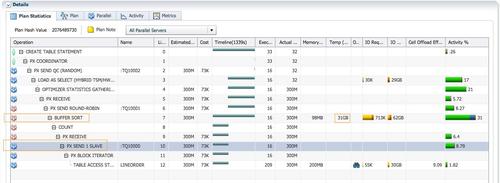
红色的PX进程只有实例1 p008是活跃的。消耗了16.7分钟的db time。对于整个执行计划而言,两次数据分发也消耗了大量的db cpu。通过Table queue 0把300M行记录从16个蓝色的PX进程分发给1个红色的 PX 进程。通过Table queue 1把300M行记录从1个红色的PX进程分发给16个蓝色的PX进程。
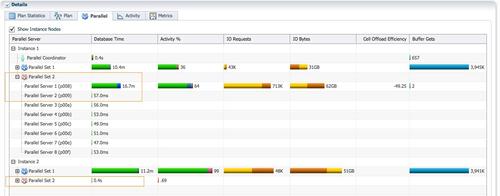
虽然DoP=16,实际AAS=1.5,意味着执行计划效率低下。
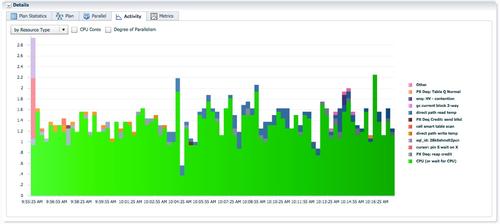
现实世界中,在应用中应该避免使用rownum。Rownum的生成操作会执行计划的串行点,增加无谓的数据分发。对于使用rownum的sql,提升并行度往往不会改善性能,除了修改sql代码,没有其他方法。
自定义PL/SQL函数没有设置parallel_enable,导致无法并行
Rownum会导致并行执行计划出现串行点,而用户自定义的pl/sql函数,如果没有声明为parallel_enable,会导致sql只能串行执行,即使用hint parallel指定sql并行执行。我们来测试一下,创建package pk_test,包含函数f,返回和输入参数一样的值。函数的声明中没有parallel_enable,不支持并行执行。
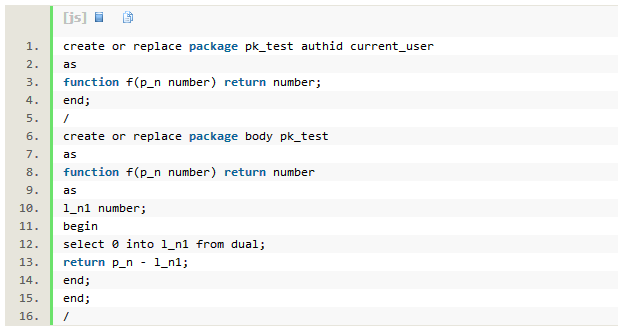
以下例子中在where语句中使用函数pk_test.f,如果在select列表中使用函数pk_test.f,也会导致执行计划变成串行执行。
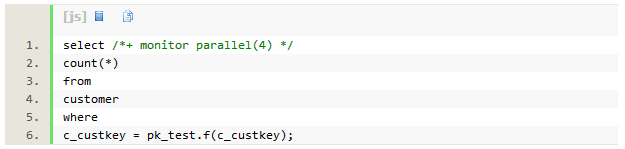
查询执行时间为54秒,db time也为54秒。虽然我们指定使用Dop=4并行执行,执行计划实际是串行的。
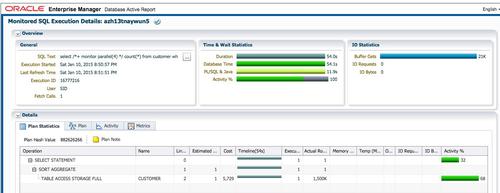
在函数的声明时设置parallel_enable,表明函数支持并行执行,再次执行sql。

此时查询的执行时间为12秒,db time为46.4秒。并行执行如期发生,并行度为4。
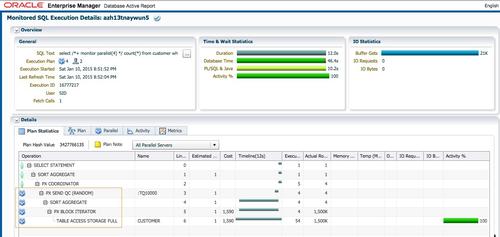
除非有特殊的约束,创建自定义pl/sql函数时,都应该声明为parallel_enable。pl/sql函数声明时没有设置parallel_enable导致无法并行是一个常见的问题,我曾在多个客户的系统中遇到。在11g中,这种情况发生时,执行计划中可能会出现PX COORDINATOR FORCED SERIAL操作,这是一个明显的提示; 或者你需要通过sql monitor报告定位这种问题。仅仅通过dbms_xplan。display_cursor检查执行计划是不够的,这种情况执行计划的note部分,还是会显示DoP=4。 /p>
并行DML,没有enable parallel dml,导致DML操作无法并行。
这是ETL应用中常见的问题,没有在session级别enable或者force parallel dml,导致dml操作无法并行。使用customer的1.5M行数据演示一下。
建一个空表customer_test:

我们使用并行直接路径插入的语句作为例子。分别执行两次insert,第一次没有enable parallel dml,insert语句如下:

Insert语句执行时间9秒。虽然整个语句的并行度为4,但是执行计划中,第2行直接路径插入操作LOAD AS SELECT是串行执行的。
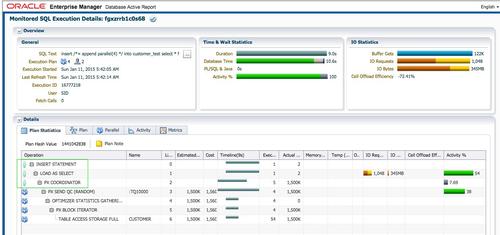
此时执行计划的Note部分会显示PDML没有启用:

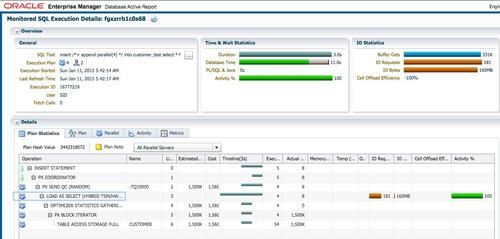
启用parallel dml之后,重新执行insert语句。

此时insert语句执行时间为3秒,执行计划中第三行,LOAD AS SELECT操作是可以并行的。
小节
我列举了使用并行执行时,常见的三种问题:
- 使用rownum。
- 自定义pl/sql函数没有声明parallel_enable。
- 并行DML时没有enable parallel dml。
希望通过以上三个例子,希望读者对调试并行执行计划有一个更直观的感受。处理并行执行的问题,sql monitor报告是最好的分析工具。对于并行DDL和DML,Oracle本身有一些限制,可以参见官方文档3,比如:
- 表上的触发器或者外键约束可能导致DML无法并行。
- 包含LOB字段的非分区表,不支持并行DML和DDL;包含LOB字段的分区表,只支持分区间的并行DML和DDL。
- 远程表(通过db link)不支持并行DML;临时表不支持并行update,merge,delete。
总结
这篇长长的文章更像是我在Real-World Performance Group的工作总结。在大量实际项目中,我们发现很多开发或者DBA并没有很好理解并行执行的工作原理,设计和使用并行执行时,往往也没取得最佳的性能。对于并行执行,已经有很多的Oracle书籍和网上文章讨论过,在我看来,这些内容更偏重于并行执行原理的解释,缺乏实际的使用案例。我希望在本文通过真实的例子和数据,以最简单直接的方式,向读者阐述Oracle并行执行的核心内容,以及在现实世界中,如果规避最常见的使用误区。也希望本文所使用sql monitor报告分析性能问题的方法,对读者有所启示! 如果现在你对以下并行执行的关键点,都胸有成竹的话,我相信现实世界中Oracle的并行执行问题都不能难倒你。
- Oracle并行执行为什么使用生产者-消费者模型。
- 如何阅读并行执行计划。
- 不同的数据分发方式分别适合什么样的场景。
- 使用partition wise join和并行执行的组合提高性能。
- 数据倾斜会对不同的分发方式带来什么影响。
- 由于生产者-消费者模型的限制,执行计划中可能出现阻塞点。
- 布隆过滤是如何提高并行执行性能的。
- 现实世界中,使用并行执行时最常见的问题。
致谢
本文目前的内容和质量,源于对初稿的多次审校和迭代。本文的两个难点,1)连续hash分发时出现阻塞点; 2)hash分发时使用布隆过滤的具体过程,得到了我英国同事Mike Hallas的解答和确认。我的同事董志平对初稿的做了详细的审校,指出多处纰漏。本文的一些内容是在他的建议下增加的,比如Partition Wise Join时,DoP大于分区数时partition wise join会失效,比如replicate方式为什么不能完全替代broadcast分发。我的同事徐江和李常勇,我的朋友蒋健阅读初稿之后,也提供了诸多反馈,在此一并感谢!
|






