|
HASH JOIN BUFFERED������hash�ַ�ʱִ�мƻ��е�������
��ĿǰΪֹ�����еIJ���ֻ�漰�����������ӡ��������������������Ҫ�������ε�hash join�����ݷַ�������࣬�����������ߵĽ�ɫ���ܻ�����ִ�мƻ������ɱ����ø��ӡ�ִ��·���䳤��Ϊ�˱�֤����ִ�е��������У�ִ�мƻ����ܻ������Ӧ�������㣬��hash joinʱ���ѷ���join���������ݻ��浽��ʱ������ͣ���ݼ����ַ���������ʹ��һ���������ӵ�sql��˵������hash joinʱ����ͬ�ַ���ʽ�IJ�ͬ��Ϊ��
ʹ��Broadcast�ַ���û�������㡣
�������������ӵ�sql���£�����part����ʹ��hint���Ż�������hash join��ʹ��broadcast�ַ���Replicate SQL��ѯ�������ơ�
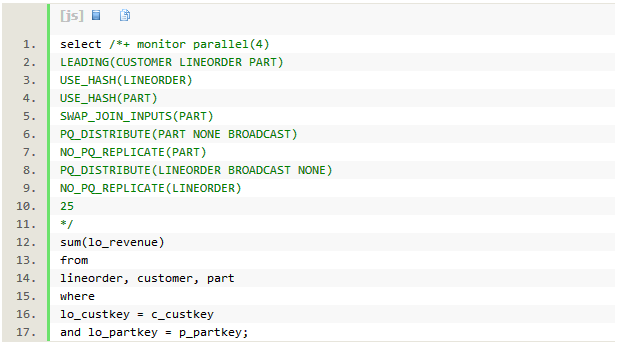
SQLִ��ʱ��Ϊ42�룬dbtimeΪ2.6���ӡ�
AAS=(sql db time)/(sql ִ��ʱ��)=(2.6*60)/42=3.7���ӽ�4��˵��4��PX���̻���һֱ���ֻ�Ծ��

ִ�мƻ���һ������������������������ģ�Ͳ�ѯʱִ�мƻ��ĵ�����ʽ�������߶�����ά�Ƚ���broadcast�ַ��������߽�������֮����������hash join��build table�� ���ɨ����ʵ����������hash join������ͨ������table queue˳���ԭ���Ķ����ִ�мƻ���
- ��ɫPX������Ϊ�����߲���ɨ��part��ͨ��tablequeue0�㲥��ÿ����ɫ��������PX���� (��7~9��)��ÿ����ɫ��PX���̽���part����������(��6��)��1.2M�м�¼�������õ�5��hash join��build table��
- ��ɫPX������Ϊ�����߲���ɨ��customer��ͨ��tablequeue1�㲥broadcast��ÿ����ɫ�� ������PX����(��12~14��)��ÿ����ɫ��PX���̽���customer����������(��11��)��1.5M�м�¼�������õ�10��hash join��build table��
- ��ɫ��PX���̲���ɨ����ʵ��lineorder����ÿ������ɨ������(���sql��������lineorder�Ĺ�������)��3���м�¼�����е�10�е�hash join������ÿһ��ͨ����10�е� hash join�ļ�¼�����Ͻ��е�5�е�hash join�������ٽ��оۺϡ���sql monitor����� Timeline����Ϣ����lineorder��ɨ�������hash join������ͬʱ���еġ�ִ�мƻ���û�������㣬������ִ��·���ϵ���������Ҫͣ�����ȴ����ֵ�db cpu����������hash join���������Ż���ִ�мƻ�����ζ�ž���ÿ��hash join������Խ��Խ�á���������ִ�мƻ�������Ҫȷ���Ż��������ܹ������ݵ�join��������ӽ���ʵ����λ��ִ�С�
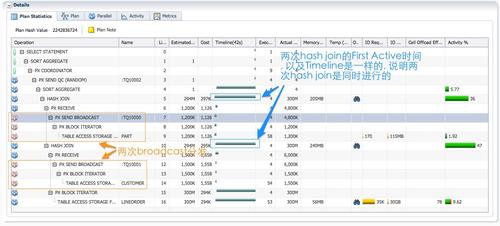
����hash�ַ���ִ�мƻ�����������
ʹ������hints��ǿ��SQLʹ��hash�ַ���
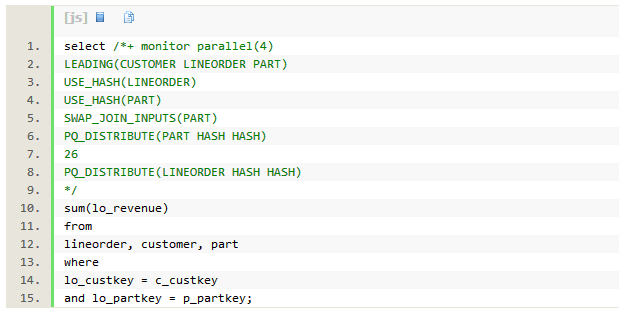
SQLִ��ʱ��Ϊ1.5���ӣ�dbtimeΪ8.1���ӡ������������14GB��IO������

��������hash join��ʹ��HASH�ַ���ÿ��hash join�������߶���Ҫ�ַ���PX����֮�䷢��4�����ݷַ���ִ�мƻ����������ĵط����Ե�12�е�HASH JOIN BUFFERED������һ�������ԵIJ��������棬������Ȼͨ������table queue˳���ԭ���Ķ�ִ�мƻ���������Ϊʲô����HASH JOIN BUFFERED�������������������һ���HASH JOIN��
1.����ɫ��PX������Ϊ�����ߣ�����ɨ��customer��ͨ��tablequeue0��hash�ַ�����Ϊ�����ߵĺ�ɫPX����(��14~16��)��ÿ����ɫ��PX���̽�����1/4��customer������(��13��)�� ��ԼΪ370k�м�¼�������õ�12��‘HASH JOIN BUFFERED’��build table����broadcast�ַ�������ǣ���ʱִ�мƻ��Ǵӵ�16�У�ɨ�迿��lineorder��customer��ʼ�ģ������Ǵӵ�һ��û��’����’�IJ���(��9��ɨ��part)��ʼ�ġ�����hash�ַ��ʹ���ִ�мƻ��Լ�broadcast�ַ���ͬ�ĵط���
2.����ɫ��PX������Ϊ�����ߣ�����ɨ��lineorder��ͨ��tablequeue1��hash�ַ���Ϊ�����ߵĺ�ɫPX����(��18~20��)��ÿ����ɫPX���̽�����1/4��lineorder����(��17��)����Լ75M�м�¼��ÿ����ɫPX�����ڽ���ͨ��tablequeue1�������ݵ�ͬʱ�����е�12�е�hash join������join�Ľ������PGA�������棬ʹ������ʱ��Ҫ������������������������ ��Ļ�����Ҫ�������ݴ浽��ʱ�ռ䣬��������������ӣ�����7GB����ʱ�ռ䡣���������Ϊ��join�Ľ�����ݴ浽һ����ʱ������ô��Ϊʲôִ�мƻ���Ҫ���������һ�������㣬��ֹ���ݼ�������������?
�����漰������������ģ�͵ĺ��ģ�ͬһ��DFO���У����ֻ��������PX���̣�һ�����ݷַ�Ҫ������PX����Эͬ����; ����ζ��ͬһʱ�̣�����PX����֮�䣬���ֻ�ܴ���һ����Ծ�����ݷַ���һ����Ϊ�����߷������ݣ�һ����Ϊ�����߽������ݣ�ÿ��PX����ֻ�ܰ�������һ�ֽ�ɫ������ͬʱ�������ֽ�ɫ������ɫ��PX����ͨ��tablequeue1����ɫ��PX���̷ַ�lineorder���ݣ�ͬʱ����ɫ��PX�������ڽ���lineorder���ݣ�������hash join���۲�timeline�е�ʱ������Ϣ����12��17~20����ͬʱ���еġ� ���Ǵ�ʱ��ɫ��PX���̲��ܷ�������Ϊ�����ߣ���hash join�Ľ���ַ�����ɫ���̣���Ϊ��ʱ���������ƣ�
• ��ɫ��PX������Ϊ�����ߣ���æ��ɨ��lineorder;��ʱ������������Ϊ�����ߣ��������Ժ�ɫPX���̵����ݡ�
• ��5��hash jon������build table��û���ã���ʱ��part������û��ɨ�衣
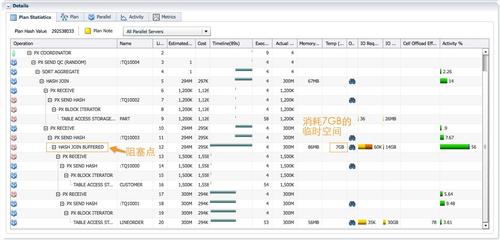
����Oracle��Ҫ�ڵ�12��hash join���λ�ò���һ�������㣬���HASH JOIN BUFFER��������join�Ľ������������������ɫ��PX������ɶ�lineorder��ɨ��ͷַ�����ɫ��PX������ɵ�12�е�hash join���ѽ����ȫ�ݴ浽��ʱ�ռ�֮��Tablequeue2�����ݷַ��Ϳ�ʼ�ˡ�
3.����ɫ��PX������Ϊ�����ߣ� ����ɨ��part��ͨ��tablequeue2���ַ�����Ϊ�����ߵ���ɫPX����(��7~9��)��ÿ����ɫPX���̽�����1/4��part����(��6��)�����300k�м�¼�������õ�5��hash join��build table��
4.����ɫ��PX������Ϊ�����ߣ����ڵ�12��”HASH JOIN BUFFERED”������������ʱ�ռ�Ķ���customer��lineorder���ӵĽ��������������ͨ��table queue 3���ַ�����ɫ��PX����(��11~12��)��“HASH JOIN BUFFERED”�������ʹ����7GB����ʱ�ռ䣬дIO7GB����IO 7GB��IO����Ϊ 14GB��
5.��ÿ����ɫ��PX������Ϊ�����ߣ������˴�Լ75M�м�¼������ͨ��tablequeue3���յ��� ���ݣ�ͬʱ���е�5�е�hash join������ͨ��join���������ݽ��е�4�еľۺϲ�������tablequeue3�ϵ����ݷַ�������ÿ����ɫ��PX�������hash join�;ۺϲ���֮���ٰѸ��ԵľۺϽ����һ�м�¼��ͨ��tablequeue4���ַ���QC(��3~5��)��QC������ľۺϣ����ظ��ͻ��ˡ�
��
��Ϊʹ������ģ�Ͳ��ԣ��������ʹ��Broadcast�ַ�����replicate���Ǻ����ġ�ʵ��Ӧ���У�������hash�ַ�����һ�������HASH JOIN BUFFERED��������㣬�����ѯ�漰�ı�����С��һ�㲻�����HASH JON BUFFERED����ʹִ�мƻ��г���BUFFER SORT��HASH JOIN BUFFERED������������Ҳ����ζ��ִ�мƻ��������ŵġ����sql���ܲ����룬HASH JOIN BUFFERED���������˴ֵ�CPU�ʹ�����ʱ�ռ䣬ͨ��sql monitor���棬������ж����Ƿ��Ǻ����ģ�
- ���estimated rows��actual rows�����У�ȷ���Ż�����hash Join��������cardinality�����Ƿ����ƫ�����ѡ��hash�ַ���
- ͬ�����hash join������estimated rows��actual rows�����У��Ż�����hash join�����cardinality�Ĺ����Ƿ�������Ż������hash join��������Ϊ�����¼�����join�����cardinality�Ĺ�����ܹ��ڱ��أ�estimate rowsƫС����������ģ�͵�һ�ֵ��������������ά�ȱ��������ӣ�ִ��·���ܳ���һ��ʼά�ȱ��ķַ���ʽΪbroadcast����ʵ�����÷ַ�����������join֮�����cardinality�½��ܿ죬����hash join���ߵ�estimated rows�ӽ��������Ż���ѡ��hash�ַ���
- ͨ�����ÿ��join�����˵����ݱ�����ȷ���Ż����Ƿ������Ч�������ݵ�join����ִ�У���֤��ִ��·�������������������١�
Hash join�Ͳ�¡����
��¡�����ڲ���ִ�мƻ��е�ʹ�÷dz��ձ飬�ҽ��ڱ��½ڽ�����һ���ݽṹ�������á� ��11.2�汾��ʼ������ִ�е�sqlҲ����ʹ�ò�¡���ˡ�
���ڲ�¡����
��¡������һ���ڴ����ݽṹ�������ж�ij��Ԫ���Ƿ�����һ�����ϡ���¡���˵Ĺ���ԭ��ͼ2���£�
������ά���ٿƣ�http��//en.wikipedia.org/wiki/Bloom_filter

��ͼ����¡������һ����bit���飬��Ҫ��������������
����1.��m������Ĵ�С����������У�m=18.
����2.��k��hash�����ĸ�������������У�k=3��
һ���յIJ�¡��������bit��Ϊ0������һ��Ԫ��ʱ����Ԫ����Ҫ��������hash�������㣬 �õ�3��hashֵ����������������λ�ö���Ϊ1������{x��y��z}��3��Ԫ�أ��ֲ�ͨ������hash���㣬������9��λ������Ϊ1���ж�ij��Ԫ���Ƿ�����һ�����ϣ�����ͼ�е�w�� ֻ���w��������hash�����������ֵ���ұߵ�λ���������в����У���λ��Ϊ0������ȷ����w����{x��y��z}������ϡ����ڴ���hash��ײ����¡���˵��жϻ�����ֹ�(false positive)�����ܴ���Ԫ�ز�����{x��y��z}������ͨ��hash����֮������λ�ö����У��������϶�Ϊ����{x��y��z}�����ݼ���Ԫ�صĸ��������������������Сm�����Ѵ����жϵļ��ʿ����ں�С�ķ�Χ֮�ڡ�
��¡���˶�hash join���ܵĸĽ�
��¡���˵���������ʹ�õĺ����ڴ棬�Ϳ��Թ��˴ֵ����ݡ����hash join����߰��������������Ż�������ѡ���hash join��ߵ����ݼ����ɲ�¡���ˣ���ɨ��hash join�ұ�ʱʹ�������¡��¡��Ϊ������������һʱ��Ѿ��ֲ�����join���������ų����������ݷַ���join��������������������������ܡ�
ʹ�ò�¡����ʱ������
ʹ�ò�¡����ʱ�����ܶ�customerʹ��c_nation=’CHINA’������ֻ���������й������Ŀͻ������������ܺ͡����ǹ۲�ʹ�ò�¡���˺Ͳ�ʹ�ò�¡����ʱ���ܵIJ��

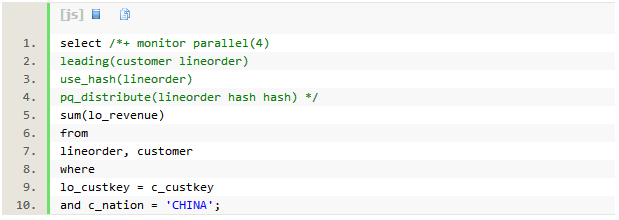
SQLִ��ʱ��Ϊ1�룬dbtimeΪ7.9 �롣�Ż���Ĭ��ѡ��replicate�ķ�ʽ��ִ�мƻ��ж���JOIN FILTER CREATE��JOIN FILTER USE������������SQL��ִ��˳��Ϊÿ��PX�����ظ�ɨ��customer��(��7��)���Է���c_nation=’CHINA’���ݼ���60K(240K/4)�м�¼����c_custkey�����ɲ�¡���ˣ�BF0000(��6��JOIN FILTER CREATE)����ɨ��lineorderʱʹ�������¡����(��8��JOIN FILTER USE)����Ȼlineorder������Ϊ300M��sqlû�й���������ֻʹ�ò�¡���ˣ�ɨ��֮��ֻ����28M�м�¼������272M�м�¼�����˵��ˡ�ÿ��PX������hash join����ʱ��ֻ�账��60K��customer��¼��7M(28M/4)��lineorder��¼�����ӣ����join�����ijɱ�������Exadata��Smart Scan֧�ֲ�¡����ж�ص��洢�ڵ㣬�洢�ڵ�ɨ��lineorderʱ��ʹ�ò�¡�����ų�272M�м�¼�����ڷ������������ݣ��Ѳ���Ҫ����Ҳȥ����Cell offload Efficiency=98%����ζ��ֻ��30GB��2%�Ӵ洢�ڵ㷵�ظ�PX���̡������ʹ�ò�¡���ˣ�Cell Offload Efficieny����ߴ�98%�����ǽ����¸����ӿ��������ڷ�Exadataƽ̨������û��Smart Scan���ԣ����ݵĹ��˲�����Ҫ��PX������ɣ���¡���˵�Ч��������ô���ԡ�12C��������Database In-�\memory��֧��ɨ����ʽ�洢���ڴ�����ʱ��ʹ�ò�¡���ˡ�
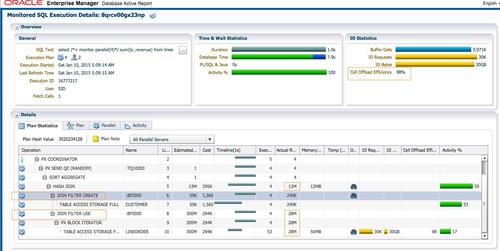
ִ�мƻ��г��ֵ�10�ж�LINEORDER��ɨ��ʱ��ʹ���˲�¡����������SYS_OP_BLOOM_FILTER(��BF0000��"LO_CUSTKEY")
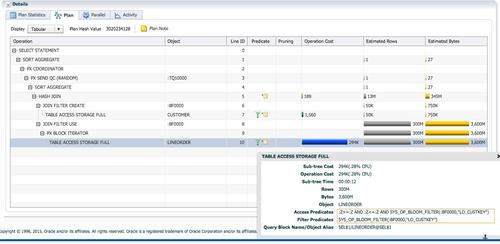
��ʹ�ò�¡����ʱ������
���ţ�����ͨ��hint NO_PX_JOIN_FILTER�����ò�¡���ˣ��۲��ʱ��sqlִ�����ܡ�
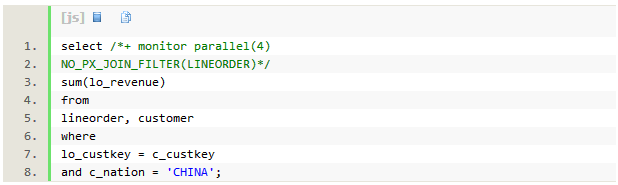
SQLִ��ʱ��Ϊ9�룬dbtimeΪ33.7�롣��ʹ�ò�¡����ʱ�������½����ԡ��Ż�����Ȼѡ��replicate�ķ�ʽ��ִ�мƻ���û��PX JOIN CREATE��PX JOIN USE������db time����Ϊԭ��4����ԭ��
- ��PXɨ��lineorderʱ������300M�м�¼��û�в�¡������Ϊ������ÿ��PX������Ҫ�Ӵ洢�ڵ����75M�м�¼��
- ���е�5�е�hash join����ʱ��ÿ��PX������Ҫ����60k��customer��¼��75M��lineorder��¼��Join�����ijɱ�������ӡ�
����û�в�¡���ˣ�Cell Offload Efficiency�½�Ϊ83%��
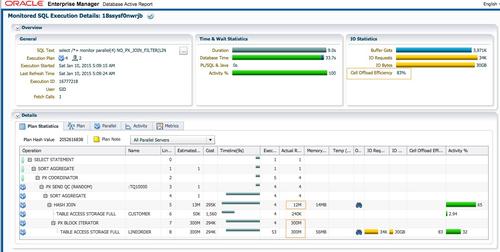
HASH�ַ�ʱ��¡���˵����ɣ����䣬�ϲ���ʹ��
����ͨ��hintǿ��ʹ��hash�ַ����۲��ʱsqlִ�мƻ��в�¡���˵����ɺ�ʹ�á�
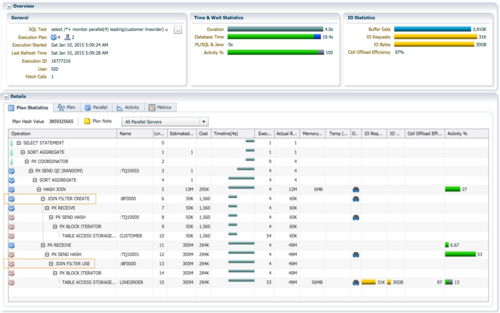
��ʱsqlִ��ʱ��Ϊ4�룬db timeΪ19.4�롣ִ�мƻ���6��ΪJOIN FILTER CREATE; ��13��ΪJOIN FILTER USE��������PX ���̷ֲ��ڶ��RAC����ʵ����Hash�ַ�ʱ�漰��¡���˵����ɣ����䣬�ϲ���ʹ�ã���Ϊ���ӣ�����������£�
- ��¡���˵IJ�����4����ɫ��PX������Ϊ�����ߣ�ͨ��tablequeue0�����պ�ɫ��PX����hash�ַ���customer���ݣ�ÿ����ɫ��PX���̽���15K�м�¼������customer��¼��ͬʱ��ʵ��1��������ɫPX������SGA��ͬ����һ����¡���ˣ�����ΪB1; ʵ��2��������ɫPX������SGA��ͬ����һ����¡���ˣ�����ΪB2����Ϊλ��SGA�У���¡����B1����ʵ��1�� ������ɫ��PX�����ǿɼ��ģ�ͬ����B2����ʵ��2��������ɫPX����Ҳ�ǿɼ��ġ�
- ��¡���˵Ĵ��䣺����ɫ��PX������ɶ�hash join���customer��ɨ�裬�ͻᴥ����¡����B1/B2�Ĵ��䡣ʵ��1�ĺ�ɫPX���̰�B1����ʵ��2����ɫPX����; ʵ��2�ĺ�ɫPX���̰�B2����ʵ��1����ɫPX���̡�
- ��¡���˵ĺϲ���ʵ��1����ɫPX���̺ϲ�B1�ͽ��յ���B2; ʵ��2����ɫPX���̺ϲ�B2�ͽ��յ���B1���ϲ�֮��ʵ��1��2������ͬ��¡���ˡ�
- ��¡���˵�ʹ�ã�ʵ��1��2��4����ɫ��PX������Ϊ�����ߣ�����ɨ��lineorderʱʹ�� �ϲ�֮��IJ�¡���˽��й��ˡ�Lineorder����֮��Ϊ49M�м�¼����ʱ�IJ�¡�����ƺ�û��replicateʱ����Ч��Cell Offloadload EfficiencyΪ97%��
�������ִ��ֻ��һ��ʵ�������ɫ��PX���̲���Ҫ�Բ�¡���˽��д��䣬��ɫ��PX����Ҳ����Բ�¡���˽��кϲ���
��Ϊhash join�ijɱ�����ˣ�����lineorder 49M�м�¼��hash�ַ�����Ϊ���Ե�ƽ����ռ53%��db time��
��
���ڲ����˲�¡���˵�ԭ�����Լ���Oracle�е�һ������Ӧ�ã���hash join���ܵ���������¡���˵ı������ڰ�hash join�����Ӳ�����ǰ�ˣ���hash join�ұ�ɨ��ʱ���͵�һʱ��Ѳ�����join�����Ĵ����ݹ��˵�����ͺ������ݷַ���hash join�����ijɱ�����ͬ�ķֲ���ʽ����¡���˵����ɺ�ʹ�����в�ͬ��
- ����broadcast�ַ���replicate��ÿ��PX���̳���hash join��ߵ��������ݣ������Ӽ�����һ�������IJ�¡���ˣ�ɨ��hash join�ұ�ʱʹ�á����sql�漰���ά�ȱ���ά�ȱ�ȫ��ʹ��broadcast�ַ����Ż������ܶԲ�ͬ��ά�ȱ��������ɶ���IJ�¡���ˣ���ɨ����ʵ��ʱͬʱʹ�á�
- ����hash�ַ�����Ϊ�����ߵ�PX���̽�����hash join��ߵ�����֮��ÿ��PX���̷ֱ�Ը��Ե����ݼ����ɲ�¡���ˣ��ٹ㲥����Ϊ�����ߵ�ÿ��PX���̣���ɨ��hash join�ұ�ʱʹ�á�
��ʵ�����У��Ż��������ͳ����Ϣ��sql�Ĺ��������Զ�ѡ��¡���ˡ�ͨ��ʹ�ò�¡����ʹ����������ܵ�������ijЩ���˵������ʹ�ò�¡���˷�����������½�������������
- ��hash join��ߵ����ݼ������缸�����У��������Ӽ��ϵ�Ψһֵ�ܶ࣬�Ż�����Ȼѡ��ʹ�ò�¡���ˡ����ɵIJ�¡���˹�������CPU cache���������档��ôʹ�ò�¡����ʱ������hash join�ұߵ�ÿһ�м�¼������Ҫ���ڴ��ȡ��¡�������жϣ������������⡣
- ���Join�����������������ݣ�ʹ�ò�¡����ʱhash join�ұߵ����ݶ������С��Ż�����������ʶ��join�������������ݣ���Ȼѡ��ʹ�ò�¡��¡�����hash join�ұ����ݼ��ܴ�¡���˿��ܻ��������ԵĶ���cpu��
|






