|
Partition Wise Join,消除分发的额外开销
无论对于broadcast或者hash分发,数据需要通过进程或者节点之间通信的完成传输,分发的数据越多,消耗的db cpu越多。并行执行时,数据需要分发,本质上是因为Oracle采用share---everything的集中存储架构,任何数据对每个实例的PX进程都是共享的。为了对hash join操作分而治之,切分为N个独立的工作单元(假设 DoP=N),必须提前对数据重新分发,数据的分发操作就是并行带来的额外开销。 使用full或者partial partition wise join技术,可以完全消除分发的额外开销,或者把这种开销降到最低。如果hash join有一边在连接键上做hash分区,那么优化器可以选择对分区表不分发,因为hash分区已经对数据完成切分,这只需要hash分发hash join的其中一边,这是partial partition wise join。如果hash join的两边都在连接键上做了hash join分区,那么每个PX进程可以独立的处理对等的hash分区, 没有数据需要分发,这是full partition wise join。hash分区时,hash join的工作单元就是对等hash分区包含的数据量,应该控制每个分区的大小,hash join时就可能消除临时表空间的使用,大幅减少所需的PGA。
Partition Wise Join,不需要数据分发。
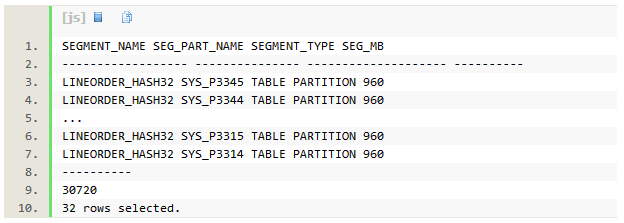
如果在lineorder的列lo_orderkey上做hash分区,分区数为32个。每个分区的大小接近1G。
使用lo_orderkey 连接时,lineorder不需要再分发。我们继续使用自连接的sql,演示full partition wise join。
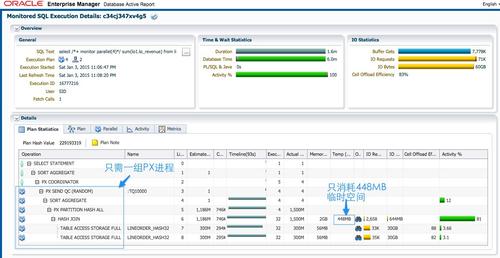
此时sql执行时间为1.6分钟,dbtime 6分钟;不分区使用hash分发时,执行时间为2.4分钟,db time 10.5 分钟。使用Partition Wise join快了三分之一。执行计划中只有一组蓝色的PX进程,不需要对数据进行分发。因为lineorder_hash32的3亿行数据被切分为32个分区。虽然并行度为4,每个PX进程hash join时,工作单元为一对匹配的hash分区,两边的数据量都为3亿的1/32。更小的工作单元,使整个hash join消耗的临时表空间下降为 448MB。每个PX进程消耗8对hash分区,可以预见,当我们把并行度提高到8/16/32,每个PX进程处理的hash分区对数,应该分别为4/2/1,sql执行时间会线性的下降。
蓝色的PX进程为、的p000/p001进程。每个PX进程消耗的db time是平均的,每个PX进程均处理了8对分区的扫描和hash join。
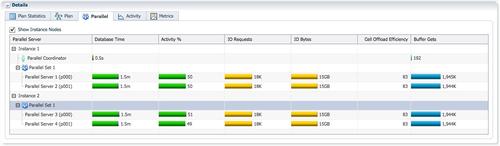
AAS绝大部分时间都为4。
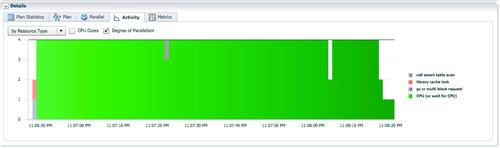
唯一的数据连接为tablequeue0,每个PX进程向QC发送一行记录。
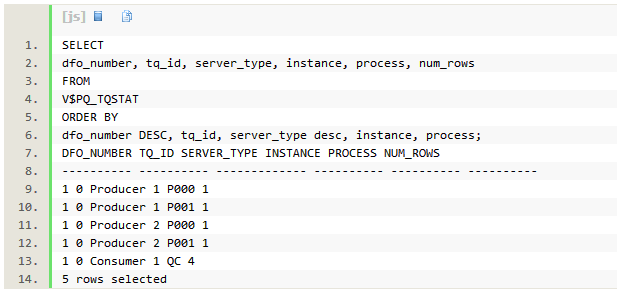
当DoP大于分区数时,Partition Wise Join不会发生
当并行执行的DoP大于hash分区数时,partition wise join不会发生,这时优化器会使用 broadcast local的分发。使用DoP=64执行同样的sql:

DoP=64,查询执行时间为15秒,db time为11.3分钟。

执行计划中出现了两组PX进程。优化器选择对hash join的右边进行broadcast local分发。如果hash join的左边比较小的话,broadcast local会发生在hash join的左边。因为DoP是分区数的两倍,hash join两边的lineorder_hash64的每个分区,由2个PX进程共同处理。处理一对匹配分区的两个蓝色的PX进程和两个红色的PX进程,会处在同一个实例上。数据只会在同一个实例的PX进程之间,不会跨实例传输,降低数据分发成本,这是broadcast local的含义。SQL的执行顺序如下:
- 以数据库地址区间为单位,蓝色的PX进程并行扫描hash join左边的lineorder_hash32(第7行),因为DoP是分区数的两倍,每个分区由两个蓝色PX进程共同扫描,这两个PX进程在同一个实例上。每个蓝色的PX进程大约扫描每个分区一半的数据,大约4.7M行记录,并准备好第5行hash join的build table。
- 红色的PX进程并行扫描hash join右边的lineorder_hash32,每个红色的PX进程大概扫描4.7M行记录,然后tablequeue0,以broadcast local的方式,分发给本实例两个红色的PX进程(数据分发时,映射到本实例某些PX进程,避免跨节点传输的特性,称为slaves mapping,除了broadcast local,还有hash local,random local等分发方式)。通过broadcast local分发,数据量从300M行变成600M行。
- 每个蓝色的PX进程通过tablequeue0接收了大概9.4M行数据,这是整个匹配分区的数据量。然后进行hash join,以及之后的聚合操作。每个蓝色的PX进程hash join操作时,左边的数据量为lineorder_hash32的1/64(=1/DoP),右边的数据为lineorder_hash32的1/32(=1/分区数)。如果继续提高DoP,只有hash join左边的数据量减少,右边的数据量并不会减少; 同时,更多的PX进程处理同一个分区,会提高broadcast分发成本。所以当DoP大于分区数时,并行执行的随着DoP的提高,扩展性并不好。
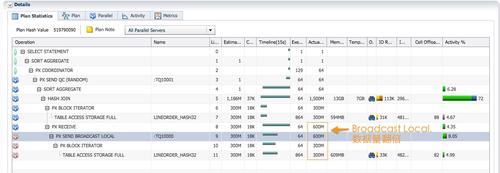
查看一个蓝色的PX进程,实例1p005进程的执行信息,可以确认hash join的左边为lineorder_hash32的1/64,hash join的右边为lineorder_hash32的1/32。
小结
数据仓库设计时,为了取得最佳的性能,应该使用partition wise join和并行执行的组合。在大表最常用的连接键上,进行hash分区,hash join时使优化器有机会选择partition wise join。Range-hash或者list-hash是常见的分区组合策略,一级分区根据业务特点,利用时间范围或者列表对数据做初步的切分,二级分区使用hash分区。查询时,对一级分区裁剪之后,优化器可以选择partition wise join。
设计partition wise join时,应该尽可能提高hash分区数,控制每个分区的大小。Partition wise join时,每对匹配的分区由一个PX进程处理,如果分区数据太多,可能导致join操作时使用临时空间,影响性能。另一方面,如果分区数太少,当DoP大于分区数时,partition wise join会失效,使用更大的DoP对性能改善非常有限。
数据倾斜对不同分发方式的影响
数据倾斜是指某一列上的大部分数据都是少数热门的值(Popular Value)。Hash join时,如果hash join的右边连接键上的数据是倾斜的,数据分发导致某个PX进程需要处理所有热门的数据,拖长sql执行时间,这种情况称为并行执行倾斜。如果优化器选择了hash分发,此时join两边的数据都进行hash分发,数据倾斜会导致执行倾斜。同值记录的hash值也是一样的,会被分发到同一PX进程进行hash join。工作分配不均匀,某个不幸的PX进程需要完成大部分的工作,消耗的db time会比其他PX进程多,SQL执行时间会因此被明显延长。对于replicate或者broadcast分发,则不存在这种执行倾斜的风险,因为hash join右边(一般为大表)的数据不用进行分发,PX进程使用基于数据块地址区间或者基于分区的granule,平均扫描hash join右边的数据,再进行join操作。
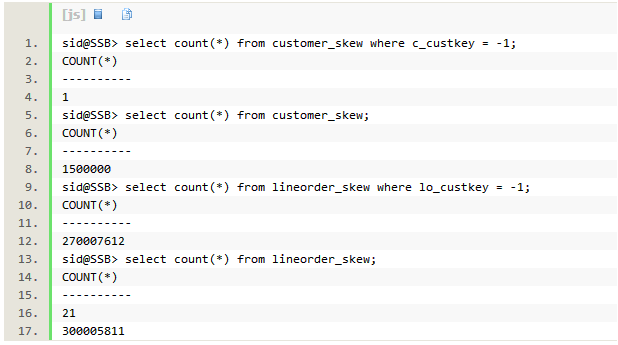
为了演示数据倾斜和不同分发的关系,新建两个表,customer_skew包含一条c_custkey=-1 的记录,lineorder_skew 90%的记录,两亿七千万行记录lo_custkey=-1。
Replicate方式,不受数据倾斜的影响
测试sql如下:
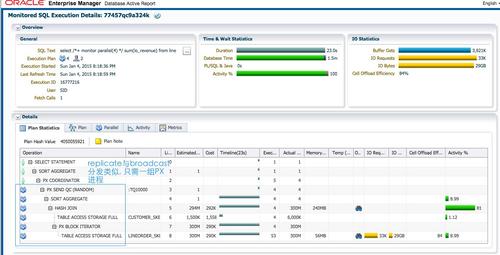
SQL执行时间为23秒,db time为1.5m。优化器默认的执行计划选择replicate的方式,只需分配一组PX进程,与broadcast分发的方式类似。每个蓝色的PX进程重复扫描customer,并行扫描lineorder_skew时,是采用基于地址区间的granule为扫描单位,见第7行的’PX BLOCK ITERATOR’。
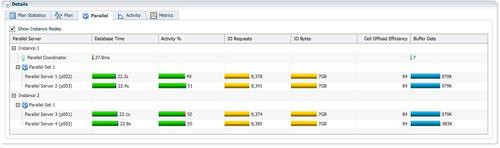
4个蓝色的PX进程消耗的db time是平均的,对于replicate方式,lineorder_skew的数据倾斜并没有造成4个PX进程的执行倾斜。
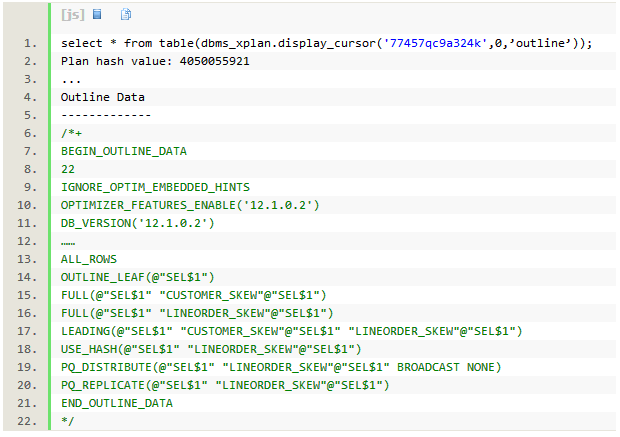
当优化器使用replicate方式时,可以通过执行计划中outline中的hint PQ_REPLICATE确认。以下部分dbms_xplan。display_cursor输出没有显示,只显示outline数据。
Hash分发,数据倾斜造成执行倾斜
通过hint使用hash分发,测试sql如下:
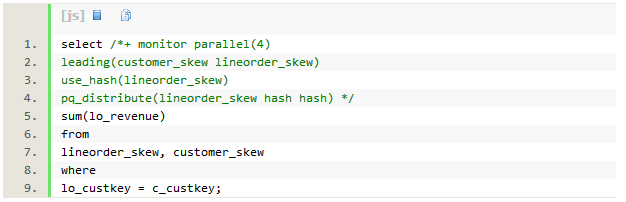
使用hash分发,SQL执行时间为58秒,dbtime 2.1分钟。对于replicate时sql执行时间23秒,dbtime 1.5分钟。有趣的是,整个sql消耗的db time只增加了37秒,而执行时间确增加了35秒,意味着所增加的dbtime并不是平均到每个PX进程的。如果增加的dbtime平均到每个PX进程,而且并行执行没有倾斜的话,那么sql执行时间应该增加37/4,约9秒,而不是现在的35秒。红色的PX 进程作为生产者,分别对customer_skew和lineorder_skew 完成并行扫描并通过tablequeue0/1,hash分发给蓝色的PX进程。对lineorder_skew的分发,占了45%的db cpu。
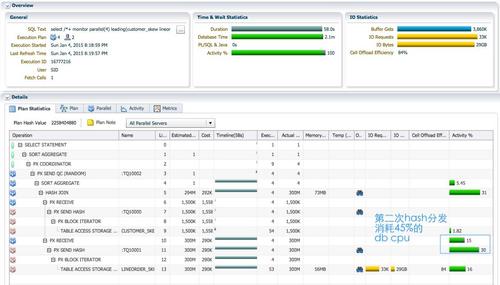
实例2的蓝色PX进程p001消耗了57.1秒的dbtime,sql执行时间58秒,这个PX进程在sql执 行过程中一直是活跃状态。可以预见,lineorder_skew所有lo_custkey=-1的数据都分发到这个进程处理。而作为生产者的红色PX进程,负责扫描lineorder_skew并进行分发,它们的工作量是平均的。
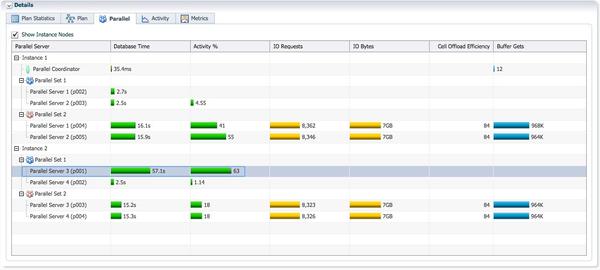
大部分时候AAS=2,只有实例2的p001进程不断的从4个生产者接收数据并进行hash join。
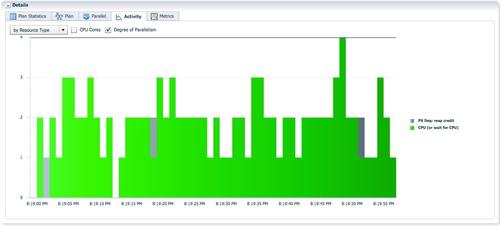
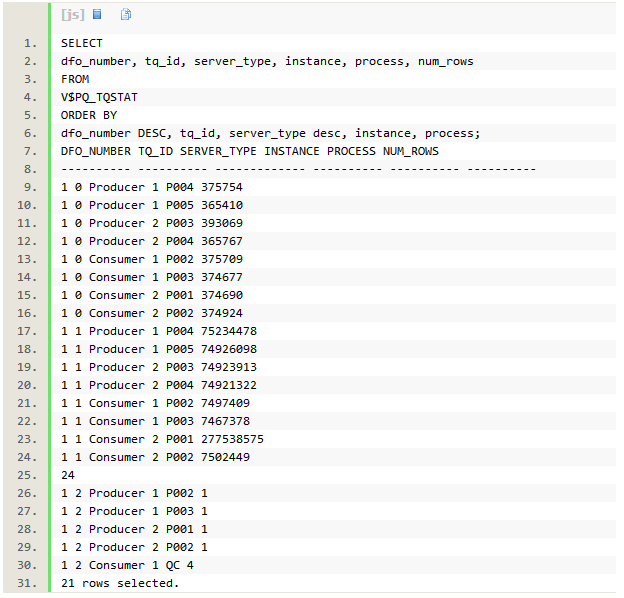
从V$PQ_TQSTAT视图我们可以确认,对hash join右边分发时,通过tablequeue1,作为消费者的实例2的P001,接收了两亿七千多万的数据。这就是该PX进程在整个sql执行过程中一直保持活跃的原因。
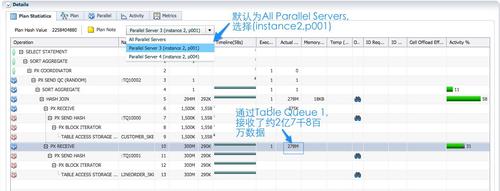
12c的sqlmonitor报告作了增强,并行执行倾斜时,包含了消耗最大的PX进程的采样信息。在plan statistics页面,下拉菜单选择’Parallel Server 3(instance 2,p001)’, 从执行计划的第10行,‘PX RECEIVE’,以及Actual Rows列的数据278M,也可以确认实例2的p001进程接收了两亿七千多万数据。
小节
对于实际的应用,处理数据倾斜是一个复杂的主题。比如在倾斜列上使用绑定变量进行过滤,绑定变量窥视(bind peeking)可能造成执行计划不稳定。本节讨论了数据倾斜对不同分发方式的带来影响:
- 通常,replicate或者broadcast分发不受数据倾斜的影响。
- 对于hash分发,hash join两边连接键的最热门数据,会被分发到同一PX进程进行join操作,容易造成明显的并行执行倾斜。
- 12c引入adaptive分发,可以解决hash分发时并行执行倾斜的问题。我将在下一篇文章” 深入理解Oracle的并行执行倾斜(下)”演示adaptive分发这个新特性。
|






