|
����Ķ�����ִ�мƻ�
Table queue �ı�Ŵ����˲���ִ�мƻ��У����ݷַ���˳������ִ�мƻ��еIJ��в�������α�ִ�еģ�ԭ��ܼ�����Tablequeue��˳��
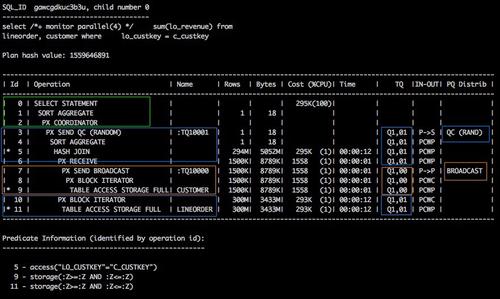
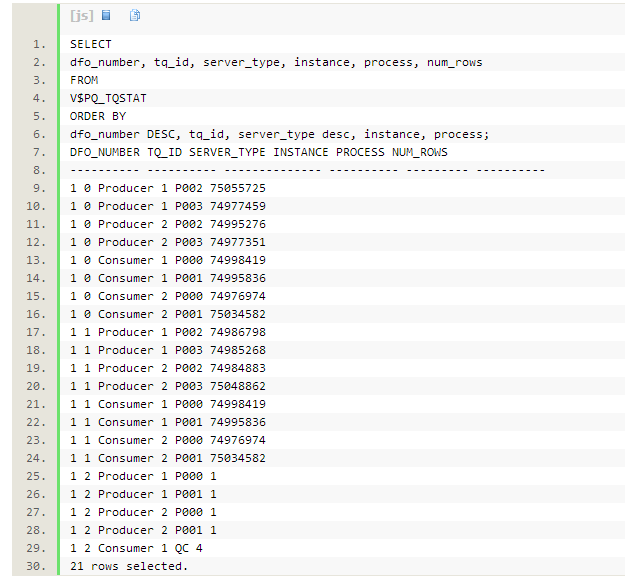
ͨ��sqlmonitor�����ж�sql��ִ��˳����Ҫ���name�е�tablequeue���ֱ��磺TQ10000(����DFO=1��tablequeue0)����TQ10001(����DFO=1��tablequeue1)������PX���̵���ɫ������ȷ����
���������Ϊdbms_xplan��display_cursor ����������ڲ���ִ�мƻ������������У�
1. TQ�У�ΪQ1��00����Q1��01������Q1������һ��DFO��00����01����tablequeue�ı�š�
a. ID7~9�IJ�����TQ��ΪQ1��00������PX���̣���Ϊ����������ִ�У�Ȼ��ͨ��broadcast �ķַ���ʽ�������ݷ��������ߡ�
b. ID10~11��3~6�IJ�����TQ��ΪQ1��01������PX������Ϊ�����߽���customer������֮��ɨ��lineorder��hashjoin���ۺ�֮������Ϊ������ͨ��tablequeue2������ ����QC��
2. In-�\out �У��������ݵ������ͷַ���
• PCWC��parallelcombinewithchild��
• PCWP��parallelcombinewithparent��
• P-�\>P�� paralleltoparallel��
• P-�\>S�� paralleltoSerial��
3. PQDistribute �У����ݵķַ���ʽ����ִ�мƻ��У�����ʹ����broadcast �ķ�ʽ��������½�
�һὲ�������ķַ���ʽ��
HASH�ַ���ʽ�� �������ݷַ�
����broadcast�ַ���ʽ����һ�ֳ����IJ��зַ���ʽΪhash��Ϊ�˹۲�ʹ��hash�ַ�ʱsql�� ִ��������Ҷ�sqlʹ��pq_distributehint ��
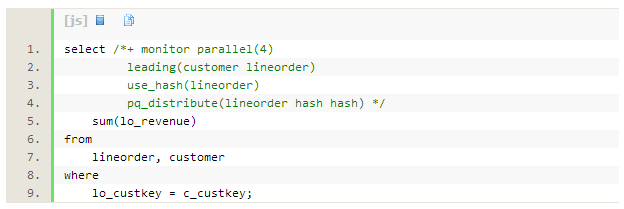
ʹ��hash�ַ���ʽʱ��sql��ִ��ʱ��Ϊ29s��dbtimeΪ2.6m�������broadcast��ʽ��sql��ִ��ʱ���dbtime�������˴�Լ40%��

ִ�мƻ����£�ִ�мƻ�Ϊ14�У������˶�lineorder��hash�ַ�����11�е�’PXSENDHASH’��3��������ͨ��hash�����ַ�����10�е�’PXRECEIVE’ͨ��tablequeue1����3�������ݣ�����������������38%��dbcpu�������ΪʲôSQLִ��ʱ���dbtime�䳤��ԭ��ʱ��SQL��ִ��˳��Ϊ��
- ��ɫ��PX������Ϊ�����ߣ�����ɨ��customer(��8~9��)���������Ӽ�c_custkey���ú���������ÿ�м�¼��hashֵ��ͨ��table queue0������4����ɫ�����ߵ�����һ��(��7��)��Hash�ַ���ʽ�����Ḵ�����ݣ�sql monitor����ĵ�6~9�У�actual rows�ж�Ϊ1.5m��
- ��ɫ��PX������Ϊ�����ߣ�����ɨ��li neorder(��12~13��)���������Ӽ�l o_custkey����ͬ����dhash������ͨ��tablequeue1 ������4����ɫ�����ߵ�����һ��(��11��)��ͬ����hash������֤��customer��li neorder��ͬ�����Ӽ��ᷢ��ͬһ�������ߣ���֤hashj oin�������ȷ����Ϊ3�������ݶ���Ҫ����hash�������㣬Ȼ��ַ�(���ǽ��̼��ͨ�ţ�������Ҫͨ��RAC��������ͨ��)����Щ��Ķ��������������38% cpu��ԭ��
-
4����ɫ��PX������Ϊ�����߽�����customer��1.5M�м�¼(�� 6 ��)����lineorder��3���м�¼(��10��)������hash join(��5��)��Ԥ�ۺ�(��4��)��
-
4����ɫ��PX���̷�������Ϊ�����ߣ�ͨ��table queue2���Ѿۺϵ����ݷ���������QC(��3 �к͵�2��)����QC�Խ��յ�4�м�¼�����ľۺϣ� Ȼ�ظ��û�(��1��0��)��
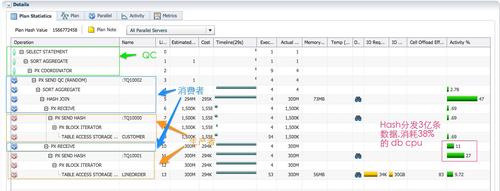
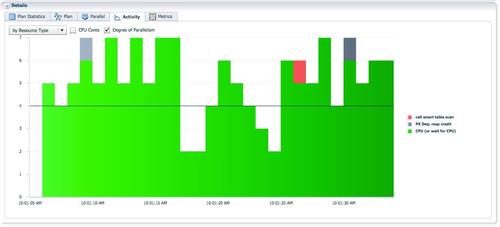
�۲�sql monitor������Parallel��ǩ�µ���Ϣ����ɫ��px����Ϊʵ��1��2�ϵ�p002/p003���̣���ɫ��PX����Ϊp000/p001���̡���Ϊ�����ߵĺ�ɫPX���̸���ɨ����ʵ��lineorder����3�������ݽ���hash�ַ���ռ�˳���1/3��db time��
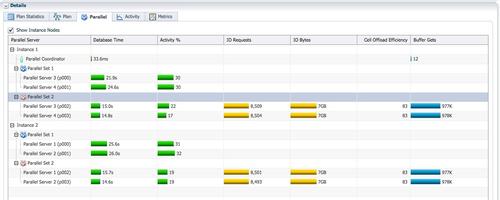
��Ϊ�漰3�������ݵķַ��ͽ��գ���Ϊ�����ߵĺ�ɫPX���̺���Ϊ�����ߵ���ɫPX������Ҫͬʱ��Ծ��SQL monitor�����е�activity��Ϣ��ʾ��ʱ�䣬AAS�������ж�4����ζ������PX����ͬʱ����������replicate����broadcast�ַ�ʱ��AASΪ4��ֻ��һ��PX���̱��ֻ�Ծ��
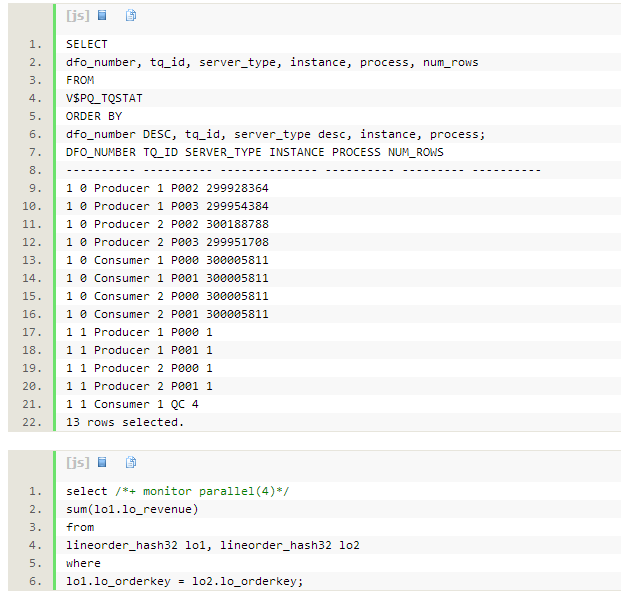
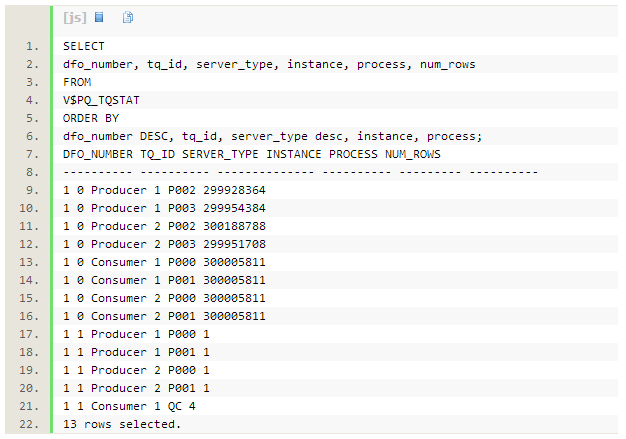
���в�ѯ֮��ͨ����ͼV$PQ_TQSTAT����һ����֤����������ִ�й��̡�����ִ�й����漰3
��tablequeue0/1/2��V$PQ_TQSTAT����21�м�¼��
1.��ʵ��1��2�ϵ�p002/p003������Ϊ�����ߣ�ƽ��ɨ��customer��1/4��¼��Ȼ��ͨ��tablequeue0(TQ_ID=0)��������Ϊ�����ߵ�p000/p001���̡����ͺͽ��յ�customer��¼֮�Ͷ�Ϊ 1.5m��
• ���͵ļ�¼����1500000= 365658+364899+375679+393764
• ���յļ�¼����1500000= 374690+374924+375709+374677
2. ��ʵ��1��2�ϵ�p002/p0003������Ϊ�����ߣ�ƽ��ɨ��lineorder��1/4��¼��ͨ��table queue1(TQ_ID=1) ��������Ϊ�����ߵ�p000/p001���̡����ͺͽ��յ�lineorder ��¼֮�Ͷ�Ϊ300005811��
• ���͵ļ�¼����300005811= 74987629+75053393+74979748+74985041
• ���յļ�¼����300005811= 74873553+74968719+75102151+75061388
3.��ʵ��1��2�ϵ�p000/p0001������Ϊ�����ߣ�ͨ��tablequeue2(TQ_ID=2)���Ѿۺϵ�һ������� ¼������Ϊ�����ߵ�QC��QC��Ϊ�����ߣ�������4�м�¼��
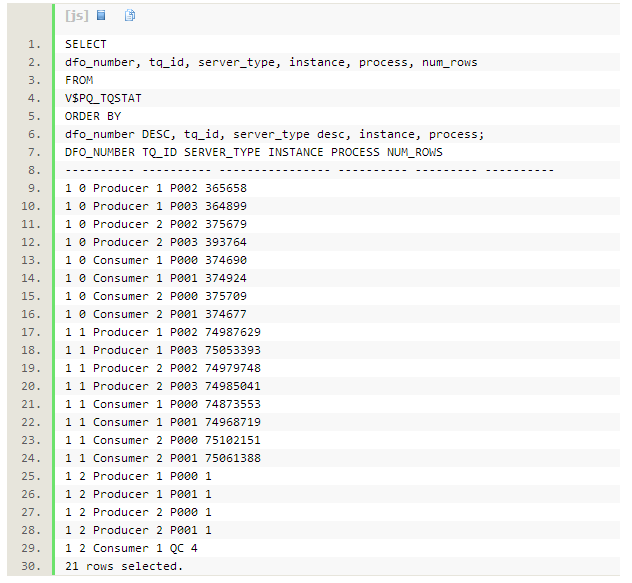
��
�����Сm�����Ѵ����жϵļ��ʿ����ں�С�ķ�Χ֮�ڡ�
���ǹ۲�hash�ַ�ʱsql�IJ���ִ�й��̡�Hash�ַ���broadcast�����������ڶ�hashjoin�� ���߶����зַ�����������У���lineorder ��hash�ַ����������Ե�dbcpu ����һ�ڣ��ҽ�ʹ����һ�����ӣ�˵��hash�ַ����õij�����
Replicate��Broadcast��Hash��ѡ��
�����Ѿ����Թ�replicate��broadcast����hash�����ַַ���ʽ��
- Replicate ��ÿ��PX�����ظ�ɨ��hashjoin ����ߣ�buffercache ����������hashjoin ��ߵ�С���������ظ�ɨ��������������������broadcast �ַ���replicate ��ʽֻ��һ��PX���̡�����repli cate�����滻br oadcast�ַ�����Ϊrepli cate������hashj oin����DZ�����������hashjoin����ߵĽ����������������������j oin������ͼ����ô��ʱ��ʹ��repli cate��
-
Broadcast�ַ�����Ϊ�����ߵ�PX����ͨ���㲥�ķ�ʽ����hashjoin��ߵĽ�����ַ���ÿ ����Ϊ�����ߵ�PX���̡�һ��������hashjoin ��߽�������ұ�С�ö�ij�������������ģ�͡�
-
Hash�ַ��ı��ʣ���hashjoin����ߺ��ұ�(��������Դ)��ͨ��ͬ��hash�������·ַ����� ��ΪN��������Ԫ(����DoP=N)���ٽ���join ��Ŀ���Ǽ���PX���̽���join ����ʱ����Ҫ���ӵ���������Hash�ַ��Ĵ�����Ҫ��hashjoin �����߶����зַ�������customer����li neorder�����ӣ���Ϊά�ȱ�customer������������ʵ��li neorderС�ö࣬��customer����repli cate����broadcast �ַ���Ȼ�Ǹ��õ�ѡ����Ϊ�����ַ�ʽ���ö�lineorder �������·ַ���������������join �Ļ���join������������ִ�мƻ���ƿ�����ڣ�hash�ַ���Ψһ���ʵķ�ʽ��Ϊ�˼���j oin�Ĵ��ۣ���hashj oin��ߺ��ұ߶�����hash�ַ��Ĵ����ǿ��Խ� �ܵġ�
Hash�ַ�����ʱ��Ψһ������ѡ��
����ʹ��lineorder�ϵ�����������ʾ��Ϊʲô��ʱhash�ַ���Ψһ������ѡ���Ե�SQL�� �£�
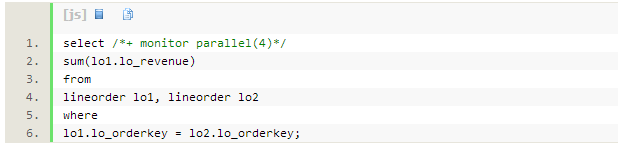
SQLִ��ʱ��Ϊ2.4���ӣ�dbtimeΪ10.5���ӡ�

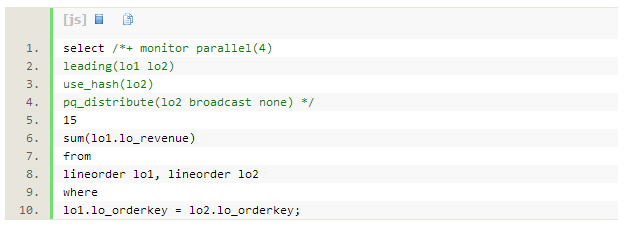
�Ż���Ĭ��ѡ��hash�ַ���ʽ��ִ�мƻ�Ϊ14�У��ṹ��֮ǰ��Hash�ַ���������һ�µġ��� ͬ���ǣ���5�е�hash join������73%��db time��ʹ����9GB����ʱ���ռ䣬���ռ��IOռ12%��db time����Լ15%��db time����Lineorder������hash�ַ��ͽ��գ������һ�����ӵ�ռ38%������������HASH�ַ�������Ӱ�콵����һ���ࡣ
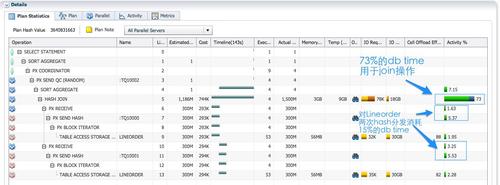
��ɫ��PX����Ϊʵ��1��2�ϵ�p002/p003���̣���ɫ��PX����Ϊp000/p001���̡���Ϊ�����ߵĺ�ɫPX����ռ��db time��15%���ҡ�
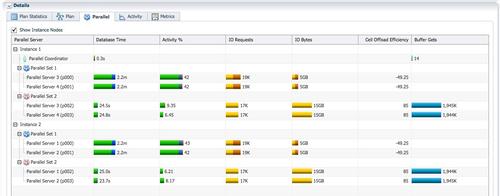
SQLִ�п�ʼ����lineorder����hash�ַ�ʱ��AAS����4���ַ����֮��ֻ����ɫ��PX���̽��� hash join������AAS=4��
��V$PQ_TQSTAT��ͼ����ȷ�ϣ�����lineorder�Ĵ������ηַ���ͨ��table queue0��1����Ϊ�����ߵ�4��PX���̽��յ�������������һ���ģ���֤���·ַ�����Ӱ��join�������ȷ�ԡ�ÿ����ɫPX ������Ҫhash join����ߺ��ұ߾�Ϊ3�������ݵ�1/4��ͨ��hash�ַ���3���м�¼����3���м�¼�Ĺ���ƽ���ķ����ĸ�����PX���̸��Դ�����ÿ��PX���̴���75M�м�¼����75M�м�¼��
ʹ�� broadcast �ַ�����������
����lineorder,lineorder�������ӣ� �������ʹ��broadcast�ַ��������ʲô�����? ���Dz���һ�£�
ʹ��broadcase�ַ���SQL��ִ��ʱ��Ϊ5.9���ӣ�db timeΪ23.8���ӡ����hash�ַ���ִ��ʱ��� db time�������˽ӽ�1.5����

��ɫ��PX������Ϊ�����ߣ���lineorder���в���ɨ��֮��3���м�¼ͨ��tablequeue0�㲥��4����Ϊ�����ߵ���ɫPX����(��6~9��)���൱�ڸ�����4�ݣ�ÿ����ɫ��PX���̶�������3���м�¼.���broadcast�ַ�������11%��db time����Ϊ��Ҫÿ�м�¼�����ÿ����ɫPX���̣����ĵ�db cpu��ʹ��hash�ַ�ʱ����hash�ַ������ĵĻ��ࡣ
��5�е�hash join�������ĵ���ʱ���ռ�������27GB����ʱ���ռ�IOռ��db time��38%����Ϊÿ����ɫPX���̽���hash join�����ݱ���ˣ�hash join�����Ϊ3�������ݣ�hash join���ұ�Ϊ3���м�¼��1/4.
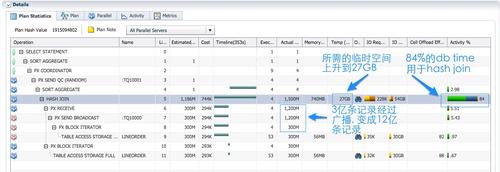
��ɫPX����Ϊ�����߸���hash join�������ĵ�db time����������ˡ�
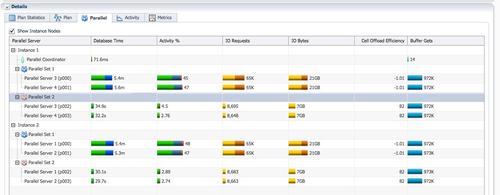
hash joinʱ����ʱ���ռ���ȴ��¼�’direct path read temp’���������ˡ�
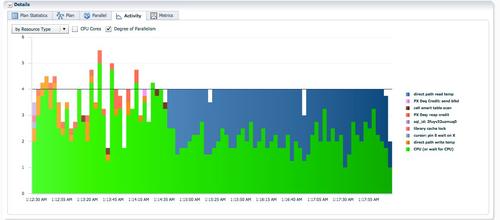
V$PQ_TQSTAT������У�ʵ��1��2�ϵ�p000/p001������Ϊ�����ߣ���������3�������ݣ���ɺ���hash join�ļ��������Broadcast�ַ���hash join��߽��й㲥�Ļ��ƣ������������ʺ�hash join���߶�Ϊ����������
С�ᣬBroadcast��Hash�ַ�������
ͨ��ǰһ�ںͱ��ڵ����ӣ�����֪�������ѡ���˲������ķַ���ʽ��SQLִ��ʱ���ܻ������½�
- ����broadcast�ַ���ֻ��hash join����߽��зַ������Dz��ù㲥�ַ���hash joinʱ��ߵ���������û�м��٣����hash join��ߵİ����������ݣ����ж�hash join���ܸ������ޡ��Դ������ݵ�broadcast�ַ�Ҳ�����Ķ����db cpu�����籾����lineorder�����ӵ����ӡ� Replicate ͬ����
-
����hash�ַ�����hash join�����߶����зַ���ʹÿ��PX���̽���hash joinʱ����ߺ��ұߵ���������Ϊԭʼ��1/N��NΪ���жȡ�Hash�ַ���DZ���������ڣ�
•���ηַ�������Դ���ķַ������ܴ������ԵĶ����������ǰһ��customer����lineorder �����ӡ�ʹ��Partition wise join���������ַ�����Ҫ����������˵����
•������ݴ�����б�����Ӽ��ϵ�����ֵռ�˴ֵ����ݣ�ͨ��hash�ַ���ͬһ����ֵ�ļ�¼��ַ���ͬһ��PX���̣�ijһ��PX���̻ᴦ�������ݵ�hash join��������ִ����б���һ��ں�����½�˵����������ͽ��������
SQL����ʱ���Ż��������hash join��ߺ��ұ߹����cardinality�����жȵ���Ϣ��ѡ�������ַַ���ʽ��ά����ȷ��ͳ����Ϣ�������Ż������������IJ���ִ�мƻ���������Ҫ�ġ�
|






