|
Oracle����ִ����һ�ֶַ���֮�ķ�����ִ��һ��sql ʱ�����������н���ͬʱִ������ɨ�裬�����Լ��ۺϵȲ�����ʹ�ø������Դ���õ������sql ��Ӧʱ�䡣����ִ���dz������Ӳ����Դ��������������ʱ�ĺ��ļ�����
�ڱ����У���һ��������ģ���ϣ��һ�ʹ�ô������Ӻ�sql monitor ���棬��������ֱ�ۼķ�ʽ������߲�������ִ�еĺ������ݣ�
• Oracle ����ִ��Ϊʲôʹ��������——������ģ�͡�
• ����Ķ�����ִ�мƻ���
• ��ͬ�����ݷַ���ʽ�ֱ��ʺ�ʲô���ij�����
• ʹ��partition wise join �Ͳ���ִ�е����������ܡ�
• ������б��Բ�ͬ�ķַ���ʽ����ʲôӰ�졣
• ����������-�\������ģ�͵����ƣ�ִ�мƻ��п��ܳ��������㡣
• ��¡�����������߲���ִ�����ܵġ�
• ��ʵ�����У�ʹ�ò���ִ��ʱ��������⡣
����˵����
- S�� ʱ�䵥λ�롣
- K�� ������λһǧ��
- M�� ������λһ���� ����ʱ�䵥λ���ӡ�
- DoP�� Degree of Parallelism�� ����ִ�еIJ��жȡ�
- QC�� ���в�ѯ�� Query Coordinator��
- PX ���̣� Parallel Execution Slaves��
- AAS�� Average active session�� ����ִ��ʱƽ���Ļ�Ự����
- �ַ��� pq distribution method�� ����ִ�еķַ���ʽ�� ���� replicate�� broadcast�� hash �� adaptive�ַ��� 4 �ַ�ʽ�� ���� adaptive �ַ��� 12c ����ĵ������ԣ� �ҽ��ڱ�ƪ������һһ������
- Hash join ����ߣ� �������� the build side of hash join�� һ��ΪС����
- Hash join ���ұߣ� ���������� the probe side of hash join�� һ��Ϊ�����
- ��¡���ˣ� bloom filter�� һ���ڴ����ݽṹ�� �����ж�һ��Ԫ���Ƿ�����һ�����ϡ�
���Ի���������
Oracle�汾Ϊ12.1.0.2.2�������ڵ��RAC��Ӳ��ΪExadataX3-�\8��
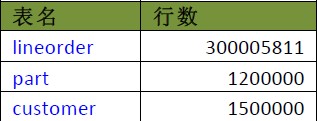
����һ�����͵�����ģ�ͣ���ʵ��lineorder��3���м�¼��ά�ȱ�part/customer�ֱ����1.2M
��1.5M�м�¼��3������û�н��з�����lineorder��С�ӽ�30GB��
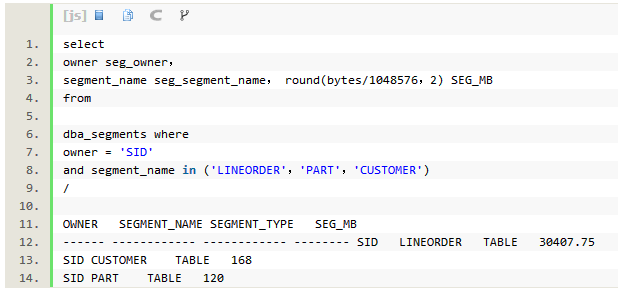
��ƪ�������еIJ��ԣ������ر��˵�����ҹر���12c��adaptive plan���ԣ�����optimizer_adaptive_features��Ĭ������Ϊfalse��Adaptive��ص�������cardinality feedback��adaptive distribution method��adaptive join���������á�������ִ�мƻ���outline���ݣ���ᷢ��7���Ż�����ص���������������Ϊ�ر�״̬����ʵ�ϣ�12c�Ż�����Ϊ����adaptive plan���ԣ��������汾���ӵö࣬����12c���Ż����ĸ��������ԣ��Ҿ��÷dz�������ս�ԣ������һ�����һƪ�����ﳢ��һ�¡�
�������
����ִ��
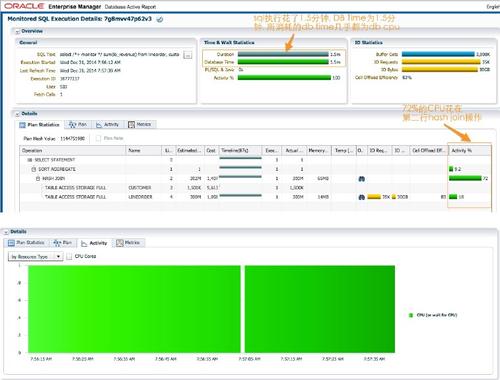
����sql��customers��lineorder����֮�������ж�����ȫ������ ����ִ��ʱ��ʹ��parallel hint��

����ִ��ʱ��sqlִ��ʱ��Ϊ1.5���ӣ�dbtimeΪ1.5���ӡ�ִ�мƻ���5�У�һ���û����̹�������˶�customer��lineorder��������ɨ�裬hashjoin���ۺ��Լ��������ݵ����в�������ʱAAS(average active sessions)Ϊ1��sqlִ��ʱ�����db time���������е�dbtime��Ϊdb cpu��72%��cpu�����˵ڶ��е�hash join��������Ϊ���Ի���Ϊһ̨Exadata X3——8��30GB��IO������һ��֮�ڴ�����ɡ�Celloffload Efficiency����87%��ζ�ž����洢�ڵ�ɨ�裬���˲���Ҫ���У����շ��ؼ���ڵ�����ݴ�Сֻ��30GB��13%��
����ִ��
ʹ��hint parallel(4)��ָ��DoP=4����ִ��ͬ����sql��
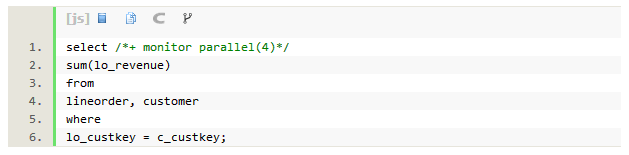
SQLִ��ʱ��Ϊ21s��db timeΪ1.4���ӡ�DoP=4��������ʵ����ִ�С�ִ�мƻ���5������Ϊ9�У��������Ϸֱ����’PXBLOCKITERATOR’�� ‘SORTAGGREGATE’�� ‘PXSENDQC(RANDOM)’ �� ’PXCOORDINATOR’ ���ĸ�������
����3��8�еIJ���Ϊ���д�����sql��ִ��˳��Ϊ��ÿ��PX����ɨ��ά�ȱ�customer(��6��)�������ݿ��ַ������Ϊ��λ(��7��)ɨ���ķ�֮һ����ʵ��lineorder(��8��)�����Ž���hash join(��5��)��Ȼ�������֮���������Ԥ�Ⱦۺ�(��4��)�����ѽ����QC(������)��QC��������(��2��)֮������һ���Ļ���(��1��)���������(��0��)��
SQLִ��ʱ���ԭ������4������Ϊ������ʱ��IJ����������lineorder��ȫ��ɨ�裬hashjoin�;ۺϣ�����ʹ��4�����̲��д������������sqlִ��ʱ��Ϊ����ִ�е�1/4����һ���棬dbtime��û�������½�������ʱ1.4m������ʱΪ1.5m����ϵͳ�ĽǶȿ�������ִ�����ĵ�ϵͳ��Դ��һ���ġ�
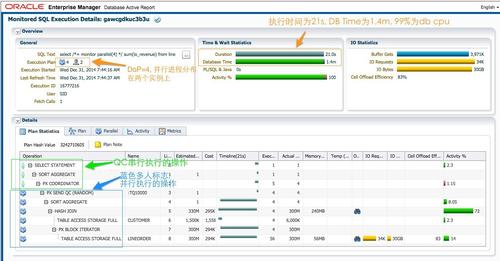
DoP=4ʱ����Ϊû���漰���ݵķַ�(distribution)��QCֻ�����һ��PX���̣��ĸ�PX���̷ֱ�Ϊʵ��1��2��p000/p0001�����ǿ��Դ�ϵͳ�ϲ鿴��4��PX���̡�ÿ��PX�������Ĵ���һ����db time��CPU��IO��Դ��AAS=4������������������ÿ��PX�������ͬ���Ĺ�������һֱ���ֻ�Ծ��û�д��е㣬û�в���ִ����б��
AAS=4���鿴���Ϣʱ��Ϊ�˸��õ�չʾ���Ϣ��ע����”CPU Cores”�����ѡ��
��Linuxϵͳ����ʾ���ĸ�PX���̡�
��
���ڵ������У�DoP=4������ִ��ʱ������4��PX���̣�����4��������������SQL monitor��������˲���ִ�е�������Ϣ����ϸ�ڣ�����QC��DoP������ִ�����ڵ�ʵ����ÿ��PX�������ĵ���Դ���Լ�ִ��SQLʱAAS��
������-������ģ��
�����沢��ִ�е������У�ÿ��px���̶���ɨ��һ��ά�ȱ�customer��Ȼ��ɨ����ʵ��lineorder����hash join����ʱû��������Ҫ���зַ���ֻ��Ҫ����һ��px���̡�����replicateά�ȱ�����Ϊ����12c�������ԣ��ɲ���_px_replication_enabled���ơ�
����������Dz���ִ��ʱ��QC��Ҫ��������PX���̣���Ϊ�����ߺ�������Эͬ��������ɲ���ִ�мƻ����ܹ�ͼ1���£�
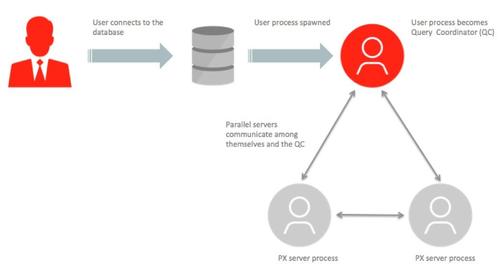
Broadcast�ַ���һ�����ݷַ�
Ϊ�˾���˵������px�������Э���ģ�����_px_replication_enabledΪfalse��QC���������PX���̣�һ��Ϊ�����ߣ�һ��Ϊ�����ߡ�
����ͼ����ʱsqlִ��ʱ��Ϊ23s��ִ��ʱ�������2s��dbtime��Ϊ1.5���ӡ�

���ı仯����ִ�мƻ�������ִ�мƻ���12�С������˶�customer�IJ���ɨ�� PXBLOCKITERATOR (��8��)���ַ�’PXSENDBROADCAST’�ͽ���’PXRECEIVE’��ִ�мƻ��г���������PX���̣�����֮ǰ��ɫ�Ķ��˱�־�����ڳ����˺�ɫ�Ķ��˱�־����ʱ��SQL��ִ��˳��Ϊ��
- 4����ɫ��PX���̰��������߽�ɫ��ɨ��ά�ȱ�customer��������ͨ��broadcast�ķ�ʽ�ַ���ÿһ�����������ߵ���ɫPX���̡���ΪDoP=4��ÿһ����ɨ������ļ�¼��������4�ݣ���sqlmonitor�ĵ�9�У�customerȫ��ɨ�践��1��5m�����ݣ���8�еķַ��͵�7�еĽ���֮ʱ�������6m�м�¼��ÿ����Ϊ�����ߵ���ɫpx���̶�������һ��������������custome��¼�����ݣ������õ�5��hashjoin��buildtable��
- 4����Ϊ�����ߵ���ɫPX���̣������ݿ��ַ����Ϊ��λɨ����ʵ��lineorder(��10/11��);ͬʱ���Ѿ����е�customer�������ݽ�hashjoin(��5��)��Ȼ�������join������������Ԥ�ۺ�(��4��)����Ϊ���Dz�ѯ��Ŀ���Ƕ�����lo_revenue��ͣ��ۺ�֮��ÿ��PX����ֻ�����һ��������
- 4����ɫ��PX���̷�������Ϊ�����ߣ��Ѿۺϵ����ݷ���������QC(��3�к͵�2��)����QC�Խ��յ�4�м�¼�����ľۺϣ�Ȼ�ظ��û���
- ʹ��broadcast�ķַ���ʽ��ֻ��Ҫ��customer�����ݹ㲥��ÿ�������ߡ�Lineorder��������Ҫ���·ַ�����Ϊlineorder����������customer��Ķ࣬Ӧ�ñ����lineorder�����ݽ��зַ�������ִ�мƻ��dz��ʺ�����ģ�͵����ݡ�
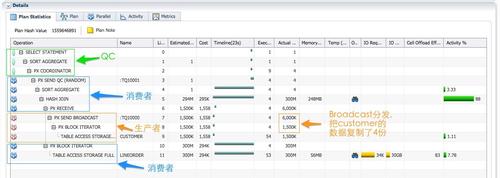
�۲�sql monitor������Parallel��ǩ�µ���Ϣ����ɫ��PX����Ϊʵ��1��2�ϵ�p002/p003���̣���ɫ��PX����Ϊp000/p001���̣���Ϊ��ɫ��PX���̸���ɨ����ʵ��lineorder��hash join�;ۺϣ��������ļ������е�db time��
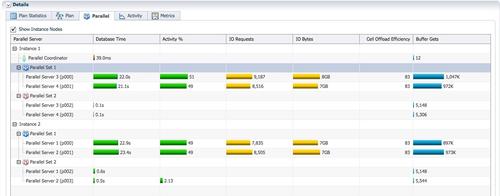
������-������ģ����ԭ��
���в�ѯ֮����ͨ����ͼV$PQ_TQSTAT����֤����������ִ�й��̡�
- ʵ��1��2�ϵ�p002/p003������Ϊ�����ߣ�����ƽ��ɨ��customer��1/4��¼����ÿһ����¼�㲥��4��������PX���̣����͵ļ�¼��֮��Ϊ6m�С�ͨ��table queue0(TQ_ID=0)��ÿ����Ϊ�����ߵ�p000/p001���̣�������������1��5m��customer��¼�����յļ�¼��֮��Ϊ 6m�С�
- ʵ��1��2�ϵ�p000/p0001������Ϊ�����ߣ�ͨ��table queue1(TQ_ID=1)���Ѿۺϵ�һ�������¼������Ϊ�����ߵ�QC��QC��Ϊ�����ߣ�������4�м�¼��
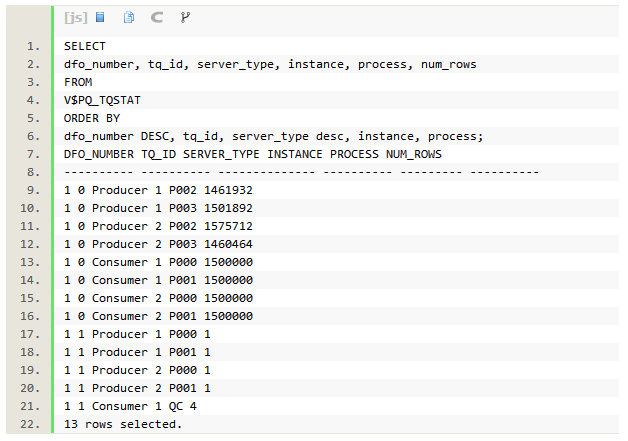
��ô�����ϵ�����У�DFO_NUMBER��TQ_ID�����б�ʾʲô��˼��?
- DFO����Data Flow Operator����ִ�мƻ��п��Բ���ִ�еIJ�����һ��QC����һ��DFO��(tree)���������DFO;ͬһ��QC�����в��в�����DFO_NUMBER����ͬ�ģ������У�����DFO_NUMBERΪ1��ִ�мƻ��������QC������Ҳ���ټ�������ʹ��unionall����䣬unionallÿ����֧���Ƕ�����DFO������ͬ��DFO��֮����Բ���ִ�С���ƪ���½�����ִ�мƻ�ֻ��һ��QC�������
- TQ����table queue������PX����֮����ߺ�QCͨ�����ӡ�����ִ�мƻ��У�table queue0ΪPX����֮������ӣ�table queue1ΪPX���̺�QC֮������ӡ�������ͨ��table queue�ַ����ݣ������ߴ�tablequeue�������ݡ���ͬ��table queue��ţ������˲�ͬ�����ݷַ���ͨ��table queue�����ǿ�������Oracle����ִ��ʹ��������-�\������ģ�͵ı��ʣ�
- ͬһ��DFO���У����ֻ������PX���̡�ÿ�������߽��̶�����һ����ÿ�������߽��̵����ӣ�ÿ��PX���̺�QC������һ�����ӡ�����DoP=n����������Ϊ(n*n+2*n)������n�����������������ᱬը��������Oracle����ִ�����ʱ�����������ߺ�������ģ�ͣ����ǵ��������ĸ��Ӷȣ�ÿ��DFO���ֻ��������PX���̡�����DoP=100ʱ������PX����֮�����������Ϊ10000��������Է�������PX����һ����ɲ���ִ�мƻ�����ô����PX֮���������������1����ά����ô�����ӣ���һ�������ܵ�����
- ͬһ��DFO���У�����PX����֮�䣬ͬһʱ��ֻ����һ����Ծ�����ݷַ������ִ��·���ܳ���������Ҫ��ηַ�������PX���̻�任�����������߽�ɫ���Э����������в��в�����ÿ�����ݷַ�����Ӧ��tablequeue�ı�Ų�ͬ��һ����Ծ�����ݷַ����̣���Ҫ����PX���̶����룬һ��Ϊ�����߷������ݣ�һ��Ϊ�����߽������ݡ���Ϊһ��DFO�����ֻ������PX���̣���ζ�ţ�PX����֮�䣬ͬһʱ��ֻ����һ����Ծ�����ݷַ������PX������ִ�мƻ�����Ҫ��ηַ����ݣ�������Ҫ��ִ�мƻ�����һЩ�����㣬����BUFFERSORT��HASHJOINBUFFERED��������������֤��һ�ε����ݷַ����֮�ſ�ʼ��һ�ηַ����ں�����½ڣ��ҽ���˵����Щ���������ʲôӰ�졣��������У�tablequeue0��1����ͬʱ��������Ϊ��tablequeue0������PX����֮������ӣ�tablequeue1ΪPX���̺�QC֮������ӣ�tablequeue0��tablequeue1��������ģ���� ����ͬʱ���С�
- PX����֮�������QC���������ٴ���һ��(���ڵ�������������RAC�����������ĸ�)��Ϣ���������ڽ��̼����ݽ���������Ϣ������Ĭ����Largepool�з���(���û������Largepool����Sharedpool�з���)�������������Ϊ��ʵ���첽ͨ�ţ�������ܡ�
- ÿ����Ϣ�������Ĵ�С�ɲ���parallel_execution_message_size���ƣ�Ĭ��Ϊ16k��
- ���������̶���ͬһ���ڵ��ʱ��ͨ����Largepool(���û������Largepool��Sharedpool)�д��ݺͽ�����Ϣ����������ݽ���������������λ�ڲ�ͬ�ڵ�ʱ��ͨ��RAC��������������ݽ���������һ�����յ�������Ҫ�����ڱ���Largepool(���û������Largepool��Sharedpool)���档
��
Ϊ��˵������ִ�е�������--������ģ������ι����ģ���ʹ����broad cast�ַ���QC��������PX���̣�һ��Ϊ�����ߣ�һ��Ϊ�����ߡ�QC��PX����֮�䣬����PX����֮��ͨ��table queue�������ݷַ���Эͬ�����������ִ�мƻ�����ͼV$PQ_TQSTAT��¼�˲���ִ�й����У���������ηַ��ġ�ͨ����DFO��table queue���������Ҳ���������-�\������ģ�͵Ĺ���ԭ����ͨ�Ź��̣�������Щ����������˵����ͻȻ�����õ��ģ�������½��һ�ͨ��������������������⡣
|






