| ժҪ��Spark�Ƿ�Դ���������ݴ�ѧ��������УAMPLab�ļ�Ⱥ����ƽ̨�����������ڴ���㣬�Ӷ���������������������ղ������ݲֿ⡢��������ͼ����ȶ��ּ��㷶ʽ���Ǻ�����ȫ��ѡ�֡�
Spark����ʽ�������Apache�������������һ����ʵ���ҡ�����ɳ�Ϊ�����ݼ���ƽ̨�����ͻ�����������Ҫ����Spark�����˼�롣Spark��������չ���˴����ݲ������ġ����ʯ�𡱡������ص����Ϊ���ᡢ�졢����ɡ���
�Spark
0.6���Ĵ�����2���У�Hadoop 1.0Ϊ9���У�2.0Ϊ22���С�һ���棬��лScala���Եļ��ͷḻ����������һ���棬Spark�ܺõ�������Hadoop��Mesos��������
��һ���������������Ŀ��������Ⱥ�Ķ�̬��Դ�������Ļ�����ʩ����Ȼ���ᣬ�����ݴ�����ϲ����ۿۡ�������Matei���ƣ������Ѵ�������������������
֮�⣬�ݴ��ǻ�����ʩ��һ���֡�
�죺Spark��С���ݼ��ܴﵽ���뼶���ӳ٣������Hadoop
MapReduce�����¼��MapReduce����������ģ����ڡ�������������ƣ���������������������ӳ٣����ʹ����ݼ����ԣ��Ե��͵ĵ�������
ѧϰ����ϯ��ѯ��ad-hoc query����ͼ�����Ӧ�ã�Spark�汾�Ȼ���MapReduce��Hive��Pregel��ʵ�ֿ���ʮ�����ٱ��������ڴ���㡢���ݱ�����
��locality���ʹ����Ż��������Ż��ȸþ�����Ҳ�������ʼ�����ֵ����������ϵ��
�飺Spark�ṩ�˲�ͬ���������ԡ���ʵ�ֲ㣬������������Scala
trait��̬���루mixin�����ԣ���ɸ����ļ�Ⱥ�����������л��⣩����ԭ�Primitive���㣬��������չ�µ���������
��operator�����µ�����Դ����HDFS֮��֧��DynamoDB�����µ�language bindings��Java��Python�����ڷ�ʽ��Paradigm���㣬Spark֧���ڴ���㡢�����������������ϯ��ѯ����������ͼ����ȶ���
��ʽ��
�ɣ����ڽ��ƺͽ�����Spark��Hadoop֮�ƣ���Hadoop���ϣ�����Shark��Spark�ϵ����ݲֿ�ʵ�֣�����Hive���ƣ�ͼ�����
��Pregel��PowerGraph��API�Լ�PowerGraph�ĵ�ָ�˼�롣һ�е�һ�У���������Scala�����㷺��ΪJava��δ��ȡ��
�ߣ�֮�ƣ�Spark��̵�Look'n'Feel����ԭ֭ԭζ��Scala�������������API����ʵ���ϣ��������ɽ�����Ϊ֧�ֽ���ʽ��
�̣�Sparkֻ���Scala��ShellС���ģ����֮�£���Ϊ֧��JavaScript Console��MapReduce����ʽ��̣�����Ҫ��ԽJava��JavaScript��˼ά���ϣ���ʵ���ϻ�Ҫ�ɸ꣩��
˵��һ��Ѻô�������Ҫָ��Sparkδ��������������������ƣ����ܺܺõ�֧��ϸ���ȡ��첽�����ݴ�����Ҳ�к����ԭ��ʹ�кܰ��Ļ��Ͼ����ո��������ܡ��ȶ��Ժͷ�ʽ�Ŀ���չ���ϻ��кܴ�Ŀռ䡣
���㷶ʽ�ͳ���
Spark������һ�ִ��������ݲ��У�data parallel���ļ��㷶ʽ��
���ݲ��и������У�task parallel�����������������������档
��������������ݼ��ϣ����Ǹ������ݡ����ϵij�����ʵ�ֶ�������SIMD����ָ������ݣ�����ָ��һ����4��64��GPU��SIMT����ָ����̣߳�һ��
��32��SPMD������������ݣ����Ը�����Spark�������Ǵ����ݣ���˲��������Ⱥֵܴļ��ϣ�����Resilient
Distributed Datasets��RDD����
�����ڵ��������ݶ�����ͬ�����������С����ݲ��пɱ���Ժã����ڻ�ø߲����ԣ������ݹ�ģ��أ�������������IJ�������أ���Ҳ���ڸ�Ч��ӳ�䵽�ײ�
�IJ��л�ֲ�ʽӲ���ϡ���ͳ��array/vector������ԡ�SSE/AVX intrinsics��CUDA/OpenCL��Ct��C++
for throughput���������ڴ��ࡣ��ͬ�����ڣ�Spark����Ұ��������Ⱥ�����ǵ����ڵ���д�������
���ݲ��еķ�ʽ������ Spark������֧��ϸ���ȡ��첽���µIJ�����ͼ������д�����������Դ�ʱSpark����GraphLab��һ�����ģͼ�����ܣ�������һЩӦ�ã�
��Ҫϸ���ȵ���־���º����ݼ��㣬��Ҳ����RAMCloud��˹̹�����ڴ�洢�ͼ����о���Ŀ����Percolator��Google�������㼼������
����������ҲʹSpark�ܹ����ĸ������ó���Ӧ��������ͼ��ϸͨ�Ե�Dryad�������ڵĴ�����ƽ̨�����������ɹ���
Spark��RDD��������Scala�������͵ı�̷����ͬ�������˺���ʽ���壨functional
semantics����һ�DZհ�������RDD�IJ������ԡ����ϣ�ÿһ��RDD���Ӷ������µ�RDD��û�и����ã����������ֱ���Ϊ��ȷ���Եģ�������
�����Ӷ����ݵȵģ����ִ���ʱֻ���������������ִ�м��ɡ�
Spark�ļ���������������������Ǵ��й�������working set��������������������һ��������ģ�ͣ�MapReduceҲ�ǣ���������MapReduce��Ҫ�ڶ�ε�����ά�����������������ij�����ձ飬���
��������ѧϰ������ʽ�����ھ��ͼ���㡣Ϊ��֤�ݴ���MapReduce�������ȶ��洢����HDFS�������ع��������������ٶ�����HaLoop����ѭ��
���еĵ���������֤ǰ�ε�����Reduce����ͱ��ε�����Map�������ݼ���ͬһ̨�������ϣ��������Լ������翪���������������I/O��ƿ����
Spark��ͻ�����ڣ��ڱ�֤�ݴ���ǰ���£����ڴ������ع��������ڴ�Ĵ�ȡ�ٶȿ��ڴ��̶�����������Ӷ����Լ����������ܡ��ؼ���ʵ���ݴ�����ͳ�������ַ�������
־�ͼ��㡣���ǵ��������������������ͨ�ŵĿ�����Spark������־���ݸ��¡�ϸ���ȵ���־���²������ˣ�����ǰ�潲����SparkҲ���ó���
Spark��¼���Ǵ����ȵ�RDD���£������������Ժ��Բ��ơ�����Spark�ĺ���ʽ������ݵ����ԣ�ͨ���ط���־�������ݴ���Ҳ�����и����á�
���ģ��
����һ�δ��룺textFile���Ӵ�HDFS��ȡ��־�ļ������ء�file����RDD����filter����ɸ������ERROR�����У�����
��errors������RDD����cache���Ӱ������������Ա�δ��ʹ�ã�count���ӷ��ء�errors����������RDD��������Scala��������
û��̫���𣬵����ǵ����ݺ�����ģ�ʹ������졣

ͼ1������RDD����ģ�ͣ������������õ����ĸ�����ӳ�䵽�����������͡�Spark�������������ռ��У�Spark
RDD�ռ��Scalaԭ�����ݿռ䡣��ԭ�����ݿռ�����ݱ���Ϊ������scalar����Scala�������ͣ�����ɫС�����ʾ�����������ͣ���ɫ����
�ͳ־ô洢����ɫԲ������
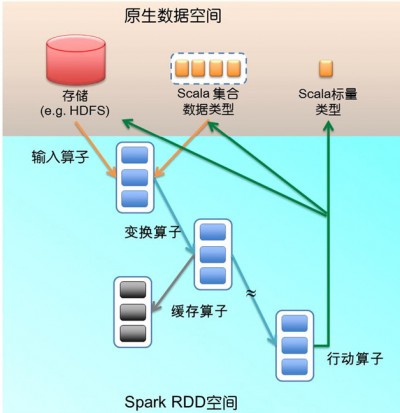
ͼ1 �����ռ���л������ͬ��RDD����
�������ӣ���ɫ��ͷ����Scala�������ͻ�洢�е���������RDD�ռ䣬תΪRDD����ɫʵ�߿��������ӵ�������������ࣺһ�����Scala�������ͣ���parallelize����һ����Դ洢���ݣ��������е�textFile���������ӵ��������Spark�ռ��RDD��
��Ϊ�������壬RDD�����任��transformation�����ӣ���ɫ��ͷ�������µ�RDD���任���ӵ�������������RDD��RDD�ᱻ���ֳɺܶ�ķ���
��partition���ֲ�����Ⱥ�Ķ���ڵ��У�ͼ1����ɫС�������������ע�⣬�����Ǹ�������任ǰ����¾ɷ����������Ͽ�����ͬһ���ڴ���
�������Ǻ���Ҫ���Ż����Է�ֹ����ʽ�����Ե��µ��ڴ������������š���ЩRDD�Ǽ�����м��������������һ������Ӧ���ڴ��洢��֮��Ӧ�������Ҫ
�����Ա�δ��ʹ�ã������Ե��û������ӣ������е�cache���ӣ���ɫ��ͷ��ʾ���������ﻯ��materialize������������ɫ���飩��
һ���ֱ任������RDD��Ԫ��Ϊ��Ԫ�أ���Ϊ���¼��ࣺ
1.�������һ��һ��element-wise�������ӣ��ҽ��RDD�ķ����ṹ���䣬��Ҫ��map��flatMap��map��չƽΪһάRDD����
2.�������һ��һ�������RDD�ķ����ṹ�����˱仯����union������RDD��Ϊһ������coalesce���������٣���
3.��������ѡ��Ԫ�ص����ӣ���filter��distinct��ȥ������Ԫ�أ���subtract����RDD�С���RDD��Ԫ������������sample����������
��һ���ֱ任�������Key-Value���ϣ��ַ�Ϊ��
1.�Ե���RDD��element-wise���㣬��mapValues������ԴRDD�ķ�����ʽ������map��ͬ����
2.�Ե���RDD���ţ���sort��partitionBy��ʵ��һ���Եķ������֣���������ݱ������Ż�����Ҫ������ὲ����
3.�Ե���RDD����key���������reduce����groupByKey��reduceByKey��
4.������RDD����key����join�����飬��join��cogroup��
������������漰���ţ���Ϊshuffle�������
��RDD��RDD�ı任�������У�һֱ��RDD�ռ䷢�����������Ҫ�������lazy evaluation�����㲢��ʵ�ʷ�����ֻ�Dz��ϵؼ�¼��Ԫ���ݡ�Ԫ���ݵĽṹ��DAG��������ͼ��������ÿһ�������㡱��RDD������������RDD
�����ӣ����Ӹ�RDD����RDD�С��ߡ�����ʾRDD��������ԡ�Spark��Ԫ����DAGȡ�˸��ܿ�����֣�Lineage����ϵ�������
LineageҲ��ǰ���ݴ��������˵����־���¡�
Lineageһֱ������ֱ�������ж���action�����ӣ�ͼ1�е���ɫ��ͷ������ʱ ��Ҫevaluate�ˣ��Ѹղ��ۻ�����������һ����ִ�С��ж����ӵ�������RDD���Լ���RDD��Lineage������������RDD���������ִ�к���
�ɵ�ԭ�����ݣ�������Scala�������������͵����ݻ�洢����һ�����ӵ��������������ʱ�������ӱ�Ȼ���ж����ӣ���Ч�����Ǵ�RDD�ռ䷵��ԭ������
�ռ䡣
�ж����������¼��ࣺ���ɱ�������count������RDD��Ԫ�صĸ�������reduce��fold/aggregate����
Scalaͬ�������ĵ��������ؼ�����������take������ǰ����Ԫ�أ�������Scala�������ͣ���collect����RDD�е�����Ԫ�ص���
Scala�������ͣ���lookup�����Ҷ�Ӧkey������ֵ����д��洢������ǰ��textFile��Ӧ��saveAsText-File������һ����
�������checkpoint����Lineage�ر�ʱ������ͼ������ʱ��������������ʱ����ִ����������Ҫ�ܳ�ʱ�䣬������������
checkpoint�ѵ�ǰ����д���ȶ��洢����Ϊ���㡣
�������������Ҫ�㡣������lazy evaluation����Ϥ����Ķ�֪�����������ܿ�����scopeԽ���Ż��Ļ����Խ�ࡣSpark��Ȼû�б��룬��������ʵ���϶�DAG�������Ը�
�Ӷȵ��Ż��������ǵ�Spark�����ж��ּ��㷶ʽ���ʱ�����������Դ��Ʋ�ͬ��ʽ����ı߽����ȫ�ֵ��Ⱥ��Ż�������������а�Shark��SQL����
��Spark�Ļ���ѧϰ���������һ�𡣸����ִ��뷭�뵽�ײ�RDD���ںϳ�һ�����DAG���������Ի�ø����ȫ���Ż����ᡣ

��һ��Ҫ����һ���ж����Ӳ���ԭ�����ݣ��ͱ����˳�RDD�ռ䡣��ΪĿǰSparkֻ�ܹ�����RDD�ļ��㣬ԭ�����ݵļ��������˵�Dz��ɼ��ģ������Ժ�
Spark���ṩԭ���������Ͳ��������ء�wrapper��implicit conversion�����ⲿ�ֲ��ɼ��Ĵ����������ǰ��RDD֮���������������Ĵ��룺

������filter��errors.count()����������(cnt-1)���ԭ��������������ģ���������������������㣬�Ǿͻ�������ˡ�
����Spark�����ṩ���������ڼ�������Ҫ������֧ʱ��Ҳ������˵�Scala�Ŀռ䡣����Scala���Զ��Զ����������֧�ֺ�ǿ�����ų�δ��SparkҲ��֧�֡�
Spark ����������ʵ�õĹ��ܡ�һ���ǹ㲥��broadcast����������Щ���ݣ���lookup�������ܻ��ڶ����ҵ�䷴���õ�����Щ���ݱ�RDDҪС�ö࣬��
����RDD�����ڽڵ�֮�仮�֡����֮�����ṩһ���µ����Խṹ�����㲥�����������δ������ݡ�Spark����ʱ�ѹ㲥�������ε����ݷ��������ڵ㣬����
��������δ������ʱ�������͡����Hadoop��distributed cache���㲥���ݿ��Կ���ҵ������Spark�ύ��Mosharafʦ��P2P���Ϸ�ʦIon
Stoica��������BitTorrent��û�����������ص�Ӱ���Ǹ�BT���ļ�ʵ�֡�����Ȥ�Ķ��߿��Բο�SIGCOMM'11������
Orchestra����һ��������Accumulator��Դ��MapReduce��counter��������Spark�����м���һЩȫ�ֱ�����
bookkeeping�����¼��ǰ������ָ�ꡣ
���к͵���
ͼ2��ʾ��Spark��������г��������ɿͻ����������������Σ���һ�μ�¼�任�������С���������DAGͼ���ڶ������ж����Ӵ�
����DAGScheduler��DAGͼת��Ϊ��ҵ��������Spark֧�ֱ��ص��ڵ����У������������ã���Ⱥ���С����ں��ߣ��ͻ���������
master�ڵ��ϣ�ͨ��Cluster manager�ѻ��ֺ÷����������͵���Ⱥ��worker/slave�ڵ���ִ�С�
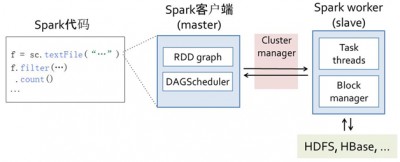
ͼ2 Spark�������й���
Spark ��ͳ����Mesos���������ϡ���Ҳ��֧��Amazon EC2��YARN���ײ�����������Ļ����Ǹ�trait�����IJ�ͬʵ�ֿ��Ի���ʵ�ʵ�ִ�С����磬��Mesos�������ֵ�����ʵ�֣�һ�ְ�ÿ���ڵ������
��Դ�ָ�Spark����һ������Spark��ҵ��������ҵһ����ȡ�������Ⱥ��Դ��worker�ڵ����������̣߳�task
thread����������DAGScheduler���ɵ������п��������block manager��������master�ϵ�block
manager masterͨ�ţ�����ʹ����Scala��Actorģʽ����Ϊ�����߳��ṩ���ݿ顣
����Ȥ�IJ�����DAGScheduler������������Ĺ������̡�RDD�����ݽṹ�����Ҫ��һ�����ǶԸ�RDD����������ͼ3��ʾ��������������խ��Narrow�������Ϳ���Wide��������
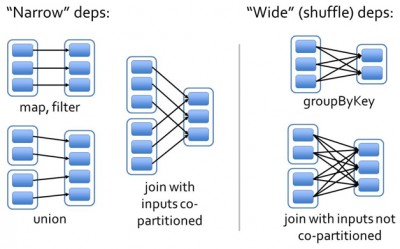
ͼ3 խ�����Ϳ�����
խ����ָ��RDD��ÿһ��������౻һ����RDD�ķ������ã�����Ϊһ����RDD�ķ�����Ӧ��һ����RDD�ķ�������������RDD�ķ�����Ӧ��һ����RDD
�ķ�����ͼ3�У�map/filter��union���ڵ�һ�࣬���������Эͬ���֣�co-partitioned����join���ڵڶ��ࡣ
������ָ��RDD�ķ��������ڸ�RDD�����з�����������Ϊshuffle���������ͼ3�е�groupByKey��δ��Эͬ���ֵ�join��
խ�������Ż������������ϣ�ÿ��RDD�����Ӷ���һ��fork/join����join�����ĵ�join���ӣ�����ָͬ��������������barrier����
�Ѽ���fork��ÿ�������������join��Ȼ��fork/join��һ��RDD�����ӡ����ֱ�ӷ��뵽����ʵ�֣��Ǻܲ����õģ�һ��ÿһ��RDD����ʹ
���м���������Ҫ�ﻯ���ڴ��洢�У���ʱ�ѿռ䣻����join��Ϊȫ�ֵ�barrier���Ǻܰ���ģ��ᱻ�������Ǹ��ڵ������������RDD�ķ�����
��RDD�ķ�����խ�������Ϳ���ʵʩ�����fusion�Ż���������fork/join��Ϊһ������������ı任�������ж���խ�������Ϳ��Ѻܶ��
fork/join��Ϊһ�������������˴�����ȫ��barrier�����������ﻯ�ܶ��м���RDD���⽫������������ܡ�Spark�����������ˮ��
��pipeline���Ż���
�任��������һ����shuffle��������������ͷ����ˣ���ˮ���Ż���ֹ���ھ���ʵ�� �У�DAGScheduler�ӵ�ǰ������ǰ��������ͼ��һ������������������һ��stage�������ѱ������������С������stage�����ȫ��ʵ
ʩ��ˮ���Ż���Ȼ���ִ��Ǹ���������ʼ�������ݣ�������һ��stage��
Ҫ��������⣺һ��������λ��֣����������÷ŵ���Ⱥ���ĸ��ڵ㡣�����ö�Ӧ��RDD�ṹ����������������������partitioner������ѡλ�ã�preferred
locations����
�������ֶ���shuffle������ܹؼ����������˸ò����ĸ�RDD����RDD֮����������͡������ᵽ��ͬһ��join���ӣ����Эͬ���ֵĻ���������
RDD֮�䡢��RDD����RDD֮�����γ�һ�µķ������ţ���ͬһ��key��֤��ӳ�䵽ͬһ�����������������γ�խ��������֮�����û��Эͬ���֣����¿�
������
��νЭͬ���֣�����ָ�������������Բ���ǰ��һ�µķ������š�Pregel��HaLoop�������Ϊϵͳ���õ�һ���֣���Spark
Ĭ���ṩ���ֻ�������HashPartitioner��RangePartitioner����������ͨ��partitionBy����ָ����ע�⣬HashPartitioner�ܹ��������ã�Ҫ��key��hashCode����Ч�ģ���ͬ�����ݵ�key����ͬ����hashCode�����
String�dz����ģ���������Ͳ���������Ϊ�����hashCode�������ı�ʶ���������ݣ����ɣ�����������£�Spark�����û��Զ���
ArrayHashPartitioner��
�ڶ��������Ƿ������õĽڵ㣬��غ����ݱ����ԣ������Ժã�����ͨ�ž��١���ЩRDD����ʱ�� ����ѡλ�ã���HadoopRDD��������ѡλ�þ���HDFS�����ڵĽڵ㡣��ЩRDD������������ˣ��Ǽ����Ӧ���͵�����������ڵĽڵ���С��ٲ�
Ȼ���ͻ���RDD��lineageһֱ�ҵ�������ѡλ�����Եĸ�RDD�����ݴ˾�����RDD�ķ��á�
��/խ�����ĸ��ֹ���ڵ����У����ݴ�Ҳ�����á����һ���ڵ�崻��ˣ�����������խ��������ֻҪ�Ѷ�ʧ�ĸ�RDD�������㼴�ɣ��������ڵ�û������������������Ҫ��RDD�����з��������ڣ�
����ͺܰ����ˡ��������ʹ��checkpoint�����������㣬����Ҫ����lineage�Ƿ��㹻����ҲҪ�����Ƿ��п��������Կ������Ӽ���������
����ֵ�ġ�
����
��Ϊƪ�����ޣ�����ֻ�ܽ���Spark�Ļ�����������˼�룬��������Spark�Ķ�ƪ���ģ���NSDI'12
��Resilient Distributed Datasets: A Fault-Tolerant Abstraction
for In-Memory Cluster Computing��Ϊ������Ҳ���Һ�ͬ���о�Spark���ĵã��Լ����������²���/�ֲ�ʽϵͳ�о��ĸ���Spark���ij�Ա/Shark����������
�Ա����������ĺ��ģ��ش���л�� |






