| MySQL��Ŀǰʹ�����Ŀ�Դ���ݿ⣬����MySQL���ݿ��Ĭ���������ܷdz��IJ������в��ϵ��Ż������Ż���һ�����ӵ������������Ա����ݿ��Ŷ����MySQL���ݿ�Metadata
Lock��ϵͳ���Ż���hash_scan �㷨��ʵ�ֽ����������Ż���TokuDB���汾�Ż����Լ�MariaDB���������Ż������������Ա��Ŷ��ڲ����������
MySQL����5.7�Ż���Metadata Lock��ϵͳ���Ż�
����
����MDL����Ŀ�ģ������Ϊ�˽��������bug#989����MySQL 5.1��֮ǰ�İ汾������ִ�й����в���ά���漰�������б���Metatdata
�������׳��ָ����жϣ���������ִ�����У�
Session 1: BEGIN;
Session 1: INSERT INTO t1 VALUES (1);
Session 2: Drop table t1; �����CSQL�BINLOG
Session 1: COMMIT; ���C�����BINLOG |
�ڱ����ط� binlogʱ������ִ��DROP TABLE����INSERT���ݣ��Ӷ����¸����жϡ�
��MySQL 5.5�汾�������MDL, ������������漰�������б���MDL����ֱ������������ͷš�����ζ���������е�DROP
TABLE ��������Session 1����סֱ�����ύ��
�����ù�5.5���˶�֪����MDLʵ���Ǹ���������Ķ��������Ų����˿϶���������ʹ��mysqldump��������ʱ��������Ҫִ��FLUSH
TABLES WITH READ LOCK (������FTWRL��д����)����ȡȫ��GLOBAL��MDL������˾������Կ�����wait
for global read lock��֮�����Ϣ�����������ڴ��ѯ�����߸����߳�����ִ�бȽ�������DDL������FTWRL��blockס����ô����QUERY���ᱻblockס������ҵ�����������ϡ�
Ϊ�˽��������⣬FacebookΪMySQL�����µĽӿ��滻��FTWRL ֻ����һ��read view
����������read viewһ�µ�binlogλ�㣻����Percona ServerҲʵ����һ�����Ƶİ취���ƹ�FTWRL���������ĵ������Լ�percona�IJ��ͣ���չ��������
MDL�����bug#989��ȴ������һ���µ��ȵ㣬���е�MDL������ά����һ��hash�����У������ȵ㣬���������뷨��Ȼ�Ƕ�����з�������ɢ�ȵ㣬������Ҳ��Facebook�Ĵ���Mark
Callaghan��report��bug#66473��ż���ģ���ʱMark�۲쵽MDL_map::mutex���������dz��ߣ������ƶ��ٷ��ı䡣�����MySQL
5.6.8��֮��İ汾�У��������²���metadata_locks_hash_instances�����ƶ�mdl
hash�ķ�����(Rev:4350)��
�������»�û����������IJ����ַ��ֹ�ϣ���������⣬somedb. someprefix1 �� .somedb
.someprefix8 ��hash keyֵ��ͬ������hash��ͬһ��Ͱ�����ˣ��൱��hash����û��Ч��������hash�㷨�����⣬ϲ�����ŵ�ͬѧ�����Ķ���bug#66473����Dmitry
Lenev�ķ�����
Mark��һ���IJ��Է���Innodb��hash�����㷨��my_hash_sort_binҪ����Ч�� Oracle�Ŀ�����Ա�ؿ��˸�bug#68487�����ٸ����⣬����MySQL5.6.15��hash
key���㺯�������Ż�������fix ����˵��hash��������(Rev:5459)��ʹ��MurmurHash3�㷨������mdl
key��hashֵ��
MySQL 5.7 ��MDL�����Ż�
��MySQL 5.7���MDL��ϵͳ���˸�Ϊ�����Ż�����Ҫ�����¼��������
��һ�����ܶ�MDL HASH�����˷��������������Ա���+�����ķ�ʽ��Ϊkeyֵ���з����������ѯ����DML��������ͬһ�ű��ϣ��ͻ�hash����ͬ�ķ������������Ե�MDL
HASH�ϵ���������
�����һ�㣬������LOCK-FREE��HASH���洢MDL_lock��LF_HASH�����㷨�������ġ�Split-Ordered
Lists: Lock-Free Extensible Hash Tables����ʵ�ֻ��Ƚϸ��ӡ� ע��ʵ����LF_HASH����ͱ�Ӧ����Performance
Schema�����DZȽϳ���Ĵ���ģ�顣����������LF_HASH��MDL HASH����������Ȼֱ�ӱ��ϳ���
����ӦWL#7305�� PATCH(Rev:7249)
�ڶ����ӹ㷺ʹ�õ�ʵ�ʳ���������DML/SELECT���DDL�ȸ���MDL�����ͣ��Ǹ�Ϊ�ձ�ģ���˿�������ԵĽ���DML��SELECT������MDL������
Ϊ��ʵ�ֶ�DML/SELECT�Ŀ��ټ�����ʹ��������LOCK-WORD�ļ�����ʽ����֮ΪFAST-PATH�����FAST-PATH����ʧ�ܣ�����SLOW-PATH�����м�����
ÿ��MDL������MDL_lock����ά����һ��long long���͵�״ֵ̬����ʾ��ǰ�ļ���״̬��������ΪMDL_lock::m_fast_path_state
�ٸ������ӣ�����ʼ��sbtest1���϶�ӦMDL_lock::m_fast_path_stateֵΪ0��
Session 1: BEGIN;
Session 1: SELECT * FROM sbtest1 WHERE id =1;
//m_fast_path_state = 1048576, MDL ticket ����MDL_lock::m_granted����
Session 2: BEGIN;
Session 2: SELECT * FROM sbtest1 WHERE id =2;
//m_fast_path_state=1048576+1048576=2097152��ͬ�ϣ���FAST PATH
Session 3: ALTER TABLE sbtest1 ENGINE = INNODB;
//DDL����ӵ�MDL_SHARED_UPGRADABLE����������Ϊunobtrusive lock��
������Ϊ����DZ�����SQL��MDL��������ߵ��������Ҳ����ݣ���˱�ǿ����slow path��
��slow path����Ҫ��MDL_lock::m_rwlock��д����
m_fast_path_state = m_fast_path_state | MDL_lock::HAS_SLOW_PATH | MDL_lock::HAS_OBTRUSIVE
ע:DDL�����ÿ⼶�����������MDL�����߱�����Ĺ�������������
��Ϊ�˱������㣬����ֱ�Ӻ����ˣ�ֻ�����漰��ͬһ��MDL_lock������
Session 4: SELECT * FROM sbtest1 WHERE id =3;
// ���m_fast_path_state &HAS_OBTRUSIVE�����DDL��û���꣬�ͻ���slow path�� |
��������������Կ�����MDL��ϵͳ��ʽ�Ķ������ͽ��������֣�OBTRUSIVE or UNOBTRUSIVE�����洢���������m_unobtrusive_lock_increment��
��˶����������͵�MDL�����ͣ�����DML/SELECT��������������û���κζ�д����MUTEX��������ӦWL#7304,
WL#7306 �� PATCH��Rev:7067,Rev:7129��(Rev:7586)
����������������MDL����ʵ�������ڰ汾���ڿ���Server����������������THR_LOCK ����Innodb�����Ѿ���Щ�����ˣ����Innodb����ȫ���Ժ����ⲿ�ֵĿ�����
���������е����У�Innodb��Ȼ����THR_LOCK��ʵ��LOCK TABLE tbname READ������������µ�MDL����������������ʵ�֡�ʵ���ϴ���Ĵ��Ķ���Ϊ�˴����µ�MDL���ͣ�Innodb�ĸĶ�ֻ�м��д��롣��ӦWL#6671��PATCH(Rev:8232)
���ģ�Server����û�����ͨ��GET_LOCK������ȡ��ʹ��MDL������ʵ�֡�
�û�����ͨ��GET_LOCK()��ͬʱ��ȡ����û�����ͬʱ����ʹ��MDL��ʵ�֣����Խ���MDL��ϵͳʵ�������ļ�⡣ע�����ڸñ仯�������û�������������С��64�ֽڣ�������MDL��ϵͳ�����Ƶ��¡���ӦWL#1159,
PATCH(Rev:8356)
MySQL�������Ż���hash_scan �㷨��ʵ�ֽ���
��������
���ȣ�����ִ�������TestCase��
--source include/master-slave.inc
--source include/have_binlog_format_row.inc
connection slave;
set global slave_rows_search_algorithms='TABLE_SCAN';
connection master;
create table t1(id int, name varchar(20);
insert into t1 values(1,'a');
insert into t2 values(2, 'b');
......
insert into t3 values(1000, 'xxx');
delete from t1;
---source include/rpl_end.inc |
���� t1 ������������rpl_hash_scan.test ��ִ��ʱ������� t1 ����������������ٵ���������Ϊ��ִ��
��delete from t1;�� ����t1��ÿһ��ɾ�����������ⶼҪɨ��t1,��ȫ��ɨ�裬��� select
count(*) from t1 = N, ����Ҫɨ��δ� t1 ���� ���ȡ��¼��Ϊ�� O(N + (N-1)
+ (N-2) + ��. + 1) = O(N^2)���� replication û������ hash_scan��binlog_format=rowʱ������������������ͨ��
table_scan ʵ�ֵģ����һ��update_rows_log_event/delete_rows_log_event
����������ʱ��ÿ���Ķ�Ҫ����ȫ��ɨ����ʵ�֣��� stack ���£�
#0 Rows_log_event::do_table_scan_and_update
#1 0x0000000000a3d7f7 in Rows_log_event::do_apply_event
#2 0x0000000000a28e3a in Log_event::apply_event
#3 0x0000000000a8365f in apply_event_and_update_pos
#4 0x0000000000a84764 in exec_relay_log_event
#5 0x0000000000a89e97 in handle_slave_sql (arg=0x1b3e030)
#6 0x0000000000e341c3 in pfs_spawn_thread (arg=0x2b7f48004b20)
#7 0x0000003a00a07851 in start_thread () from /lib64/libpthread.so.0
#8 0x0000003a006e767d in clone () from /lib64/libc.so.6 |
��������£���������ɱ����ӳ٣���Ҳ�����������������ĸ����ӳ����⡣
��ν�����⣺
RDS Ϊ�˽�������⣬����ÿ����������ʱ����һ�±��Ƿ������������Ψһ�������û�а�������һ����ʽ���������������û������û��У���Ӧ��show
create, select * �Ȳ�����������ʽ�������Ӷ����Լ�����������������Ӱ��;
�ٷ�Ϊ�˽��������⣬��5.6.6 ���Ժ�汾������� slave_rows_search_algorithms
������ָʾ������ apply_binlog_eventʱʹ�õ��㷨���������㷨TABLE_SCAN,INDEX_SCAN,HASH_SCAN������table_scan��index_scan���Ѿ����ڵģ�������Ҫ�о�HASH_SCAN��ʵ�ַ�ʽ�����ڲ���slave_rows_search_algorithms�����á�
hash_scan ��ʵ�ַ�����
�Ľ����� apply rows_log_eventʱ���Ὣ log_event �ж��еĸ��»����������ṹ�У��ֱ��ǣ�m_hash,
m_distinct_key_list�� m_hash����Ҫ����������µ��м�¼����ʼλ�ã���һ��hash����
m_distinct_key_list���������������������ֵpush ��m_distinct_key_list�������û����������ʹ�����List�ṹ��
����Ԥɨ���������ù������£� Log_event::apply_event
Rows_log_event::do_apply_event
Rows_log_event::do_hash_scan_and_update
Rows_log_event::do_hash_row (add entry info of changed records)
if (m_key_index < MAX_KEY) (index used instead of table scan)
Rows_log_event::add_key_to_distinct_keyset () |
��һ��event �а�������еĸ���ʱ��������ɨ�����еĸ��ģ���������浽m_hash�У�����ñ�����������������ֵ������m_distinct_key_list
List �У����û�У���ʹ���������ṹ����ֱ�ӽ���ȫ��ɨ�裻
ִ�� stack ���£�
#0 handler::ha_delete_row
#1 0x0000000000a4192b in Delete_rows_log_event::do_exec_row
#2 0x0000000000a3a9c8 in Rows_log_event::do_apply_row
#3 0x0000000000a3c1f4 in Rows_log_event::do_scan_and_update
#4 0x0000000000a3c5ef in Rows_log_event::do_hash_scan_and_update
#5 0x0000000000a3d7f7 in Rows_log_event::do_apply_event
#6 0x0000000000a28e3a in Log_event::apply_event
#7 0x0000000000a8365f in apply_event_and_update_pos
#8 0x0000000000a84764 in exec_relay_log_event
#9 0x0000000000a89e97 in handle_slave_sql
#10 0x0000000000e341c3 in pfs_spawn_thread
#11 0x0000003a00a07851 in start_thread ()
#12 0x0000003a006e767d in clone () |
ִ�й���˵����
Rows_log_event::do_scan_and_update
open_record_scan()
do
next_record_scan()
if (m_key_index > MAX_KEY)
ha_rnd_next();
else
ha_index_read_map(m_key from m_distinct_key_list)
entry= m_hash->get()
m_hash->del(entry);
do_apply_row()
while (m_hash->size > 0); |
��ִ�й����Ͽ��Կ�������ʹ��hash_scanʱ��ֻ��ȫ��ɨ��һ�Σ���Ȼ���α���m_hash���hash�����������ɨ����O(1),���ԣ����ۺ�С����˿��Խ���ɨ����������ִ��Ч�ʡ�
hash_scan ��һ�� bug
bug���飺http://bugs.mysql.com/bug.php?id=72788
bugԭ��m_distinct_key_list �е�index key ����Ψһ�ģ����Դ����Ŷ��Ѿ�ɾ���˵ļ�¼�ظ�ɾ�������⡣
bug����http://bazaar.launchpad.net/~mysql/mysql-server/5.7/revision/8494 |
������չ��
1.��û������������£��Dz��ǰ� hash_scan �������Ч�ʣ������ӳ��أ���һ�������ÿ�θ��²���ֻһ����¼����ʱ��Ȼ��Ҫȫ��ɨ�裬��������entry
�Ŀ�����Ӧ�û��к��˵������
2.һ��event���ܰ�����������¼�ĸ����أ�����ͱ��ṹ�Լ���¼�����ݴ�С�йأ�һ��event
�Ĵ�С���ᳬ��9000 bytes, û�в������Կ������size��
3.hash_scan ��û�������أ�hash_scan ֻ��Ը��¡�ɾ��������Ч������binlog_format=statement
������ Query_log_event ����binlog_format=row ʱ������ Write_rows_log_event
�������ã�
TokuDB���汾�Ż���7.5.0
TokuDB��7.5.0��汾�ѷ�������һ����̱��İ汾������̸�����Ż������ϴ洢���氮�����ǡ�
a) shutdown����
���û�����TokuDB��shutdown��ʱ���Сʱ��û���£��dz����ɽ��ܡ���shutdown��ʱ��TokuDB�ڸ�ʲô�أ�����checkpoint�����ڴ��еĽڵ��������л���ѹ�������̡�
��Ϊʲô��˺�ʱ�أ����tokudb_cache_size���ıȽϴ��ڴ��еĽڵ��dz��࣬��shutdown��ʱ��Ҷ��Ŷӵ��ű�ѹ�������̣����еģ���
��7.5.0�汾��TokuDB�ٷ���Դ�����������Ż���ʹ����ڵ㲢��ѹ��������ʱ�䡣
BTW: TokuDB��������Ƶ�ʱ���ѱ������нӿڣ�ֻ��һֱδ������
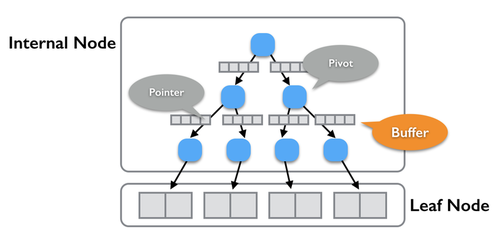
b) �ڽڵ��ȡ����
���ڴ��У�TokuDB�ڽڵ�(internal node)��ÿ��message buffer���У�����Ҫ���ݽṹ��
1) FIFO�ṹ������{key, value}
2) OMT�ṹ������{key, FIFO-offset} |
����FIFO���߱����ٲ������ԣ�������OMT�������ٲ���(����key�鵽value)�����������ڽڵ㷢��cache
miss��ʱ����������Ҫ����
1) �Ӵ��̶�ȡ�ڵ����ݵ��ڴ�
2) ����FIFO�ṹ
3) ����FIFO����OMT�ṹ(������) |
����TokuDB�ڲ��в�������̽(ji)��(shu)�����Ƿ��ֲ���3)�Ǹ���С���������ĵ㣬��Ϊÿ�ζ�Ҫ��message
buffer�����������OMT��������7.5.0�汾����OMT��FIFO-offset(������)Ҳ�־û������̣������������ľ�û�ˡ�
c) ˳��д����
��д������ʱ����ݵ�ǰ��key��pivots�����(����)��ǰдҪ�����ĸ�mesage
buffer�����д��˳��(��ֲ�˳����������Ϊ���ұ�·��)�ģ��Ϳ��Ա����ɣ����ң������Ķ������
����ж���˳��д�أ�TokuDBʹ����һ�ּ�����ʽ����(heurstic)��seqinsert_score����ʽ�������
1) ��ǰд���������ҽڵ㣬��seqinsert_score��һ��(ԭ��)
2) ��ǰд����������ҽڵ㣬��seqinsert_score����(ԭ��) |
��seqinsert_score����100��ʱ�Ϳ�����Ϊ��˳��д�����´�д��������ʱ�����������ҵĽڵ�pivot���жԱ��жϣ����ȷʵΪ˳��д����ᱻд���ýڵ㣬ʡȥ����compare��������������Ч��
MariaDB���������Ż���filesort with small LIMIT
optimization
��MySQL 5.6.2/MariaDB 10.0.0�汾��ʼ��MySQL/MariaDB��ԡ�ORDER
BY ��LIMIT n�����ʵ����һ���µ��Ż����ԡ���n�㹻С��ʱ���Ż��������һ���ݻ�Ϊn�����ȶ�����������������������������Ȼ��ȡ��ǰn����
������㷨������ô��������������ASC����
1.����һ��ֻ��n��Ԫ�ص����ȶ��У��ѣ������ڵ�Ϊ�������Ԫ��
2.�����������������δӱ���ȡ��һ������
3.�����ǰ�е�����ؼ���С�ڶ�ͷ����ѵ�ǰԪ���滻��ͷ������Shift���ֶѵ�����
4.��ȡһ�������ظ�2���裬���û����һ��������ִ��5
5.����ȡ�����е�Ԫ�أ��Ӵ�С���������������С�����������ɵ�ASC��������
�������㷨��ʱ�临�Ӷ�Ϊm*log(n)��mΪ�������˺��������nΪLIMIT����������ԭʼ��ȫ�����㷨��ʱ�临�Ӷ�Ϊm*log(m)��ֻҪnԶС��m������㷨�ͻ����Ч��
������MySQL 5.6�У�����optimizer_trace��û�кõķ�������������µ�ִ�мƻ��������˶������á�MariaDB
10.013��ʼ���ṩһ��ϵͳ״̬�����Բ鿴��ִ�мƻ����õĴ�����
Sort_priority_queue_sorts
����: ͨ�����ȶ���ʵ������Ĵ�����(���������=Sort_range+Sort_scan)
��Χ: Global, Session
��������: numeric
����汾: MariaDB 10.0.13 |
���⣬MariaDB��������Ϣ������Slow Log�С�ֻҪָ�� log_slow_verbosity=query_plan���Ϳ�����Slow
Log�п��������ļ�¼��
# Time: 140714 18:30:39
# User@Host: root[root] @ localhost []
# Thread_id: 3 Schema: test QC_hit: No
# Query_time: 0.053857 Lock_time: 0.000188 Rows_sent: 11 Rows_examined: 100011
# Full_scan: Yes Full_join: No Tmp_table: No Tmp_table_on_disk: No
# Filesort: Yes Filesort_on_disk: No Merge_passes: 0 Priority_queue: Yes
SET timestamp=1405348239;SET timestamp=1405348239;
select * from t1 where col1 between 10 and 20 order by col2 limit 100; |
Priority_queue: Yes�� �ͱ�ʾ���Query���������ȶ��е�ִ�мƻ�(pt-query-digest
Ŀǰ�Ѿ����Խ��� Priority_queue �����)�����ྫ�����ݣ������ڴ���
|






