|
将交通领域产生的海量车辆位置信息和道路进行关联的统计操作是颇为浩大的工作。本文将介绍一种通过使用地理网格进行数据关联,并利用Shuffle过程的二次排序实现高效的统计各条道路上位置点分布情况的方法。
交通领域正产生着海量的车辆位置点数据。将这些车辆位置信息和道路进行关联的统计操作则是一项颇为浩大的工作,而随着Hadoop技术的成熟和普及,使得在海量数据中进行该统计运算的工作变得相对容易了很多。本文将介绍一种通过使用地理网格进行数据关联,并利用Shuffle过程的二次排序实现高效的统计各条道路上位置点分布情况的方法。
中华人民共和国交通运输部、中华人民共和国公安部、国家安全生产监督管理总局于2014年1月28日公布了《道路运输车辆动态监督管理办法》,在该文件中规定,自2014年7月1日起,国内道路运输车辆须安装卫星定位装置,未按照要求安装卫星定位装置,或者已安装卫星定位装置但未能在联网联控系统正常显示的车辆,不予发放或者审验《道路运输证》。
随着该文件规定的落实,必将会产生海量的车辆位置点数据。将这些车辆位置信息与地理信息相结合进行统计,则是相关技术行业中常见的统计分析的应用场景。而在这些统计中,将位置点和道路进行关联的统计操作则属于一种较为复杂的情况。将TB级的车辆位置数据按照道路进行区分,并统计每条道路上的位置点分布情况,需要涉及较复杂的地理空间算法,而且在数据的组织方式上也需要进行更为精巧的设计。在几年前云计算与大数据的技术尚未兴起的条件下,进行这样的操作将会是一项颇为浩大的工作,既需要考虑分布式并行计算,又需要对地理算法进行尽量高效的设计,还需要兼顾分布式情况下系统的健壮性和可靠性。
Hadoop技术的成熟和普及,使得在海量数据中进行统计运算的工作变得相对容易了很多。作为Apache软件基金会的开源分布式计算平台,Hadoop提供了分布式文件系统(HDFS)和分布式计算(MapReduce/Yarn)的基础框架支持。在海量数据的分析与处理领域,Hadoop以其高可靠性、高效性、高扩展性和高容错性等优势,可以使用户很容易的架构和使用分布式计算平台,可以简便的进行海量数据的存储和检索,能够轻松的开发和运行处理海量数据的应用程序。在很多IT领域,尤其是互联网行业,Hadoop被广泛应用于用户行为分析、数据挖掘与机器学习、网页抓取与分析、构建搜索引擎以及推荐广告等与大数据相关的应用之中。
由于Hadoop的MapReduce模型是基于Key/Value对的操作,因此在Key/Value对中如何设计地理数据和位置数据的关联关系将会成为一个可以使统计性能产生质变的关键点。通过合理的Key/Value设计和对MapReduce的Shuffle过程的优化,将会使统计操作的性能产生质的飞跃。以下将介绍一种通过使用地理网格进行数据关联,并利用Shuffle过程的二次排序实现高效的统计各条道路上位置点分布情况的方法。
计算某位置点是否位于某条道路上的一种相对简单的方式是获取道路的轮廓数据(以道路边界的经纬度点组成的多边形顶点经纬度信息)和位置数据的经纬度信息,然后将道路的轮廓坐标构建一个多边形,并通过判断车辆位置的经纬度坐标是否位于多边形的内部来判断车辆是否位于道路之上。在获取车辆和道路关系信息后,可以生成一个类似如下结构的二维表数据模型,进而进行分布状态的统计。

实现这种统计的一个技术关键点是如何判断一个点是否包含于一个多边形内部,如下图中,如何判断各圆点和多边形的包含关系。
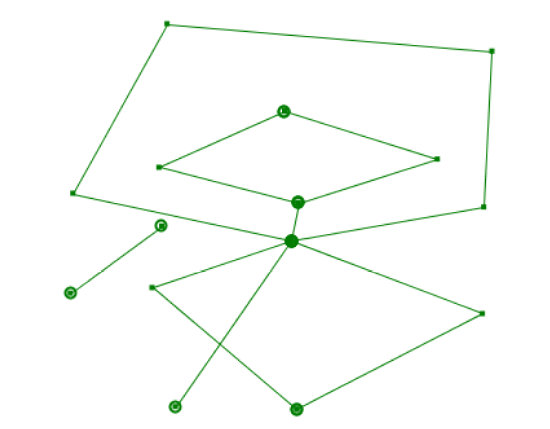
在已知多边形各顶点坐标的情况下,判断任意一个点是否位于该多边形的内部的方法在各种开发语言中均有较多实现,下面以Java为例,简述两种常见的方法:
方法一:使用顶点坐标构建一个java.awt.Polygon对象,该对象具有一个contains(int x,int y)方法,通过将x和y两个方向的坐标作为该方法的参数进行调用,即可判断该点是否位于多边形内部。
方法二:使用第三方空间拓扑关系工具包JTS Topology Suite进行判断。该工具包中存在一个抽象类com.vividsolutions.jts.geom.Geometry。该抽象类作为JTS的几何元素对象的基类,具有一个contains(Geometry g)方法,该方法可以用于判断一个几何元素是否位于另一个几何元素内部。com.vividsolutions.jts.geom.Geometry有一个表示多边形的子类com.vividsolutions.jts.geom.Polygon和一个表示位置点的子类com.vividsolutions.jts.geom.Point。使用多边形顶点坐标和位置点坐标分别构建com.vividsolutions.jts.geom.Polygon和com.vividsolutions.jts.geom.Point对象,然后根据Polygon.contains(Point p)方法即可判断位置点是否位于多边形内部。
在路网数据和位置点数据量非常巨大的情况下,直接使用这两种方法统计道路-位置点的方法将会遭遇非常严重的性能问题,尤其在统计一个较长时间段内全国道路上位置点的分布情况时候。对于TB级的位置数据和数十GB的路网数据,进行空间关系的判断,如果使用单台服务器会涉及大量的磁盘分片读写,性能会非常底下,而如果使用分布式架构进行统计,网络通信,容错控制,任务管理等工作又会大大增加操作的难度。面对这样的问题,使用Hadoop进行统计操作,则会非常合适。
Hadoop的MapReduce编程模型是Hadoop体系的分布式并行计算框架。MapReduce编程模型假设用户需要处理的输入是一系列的key/value。在此基础上定义了两个函数Map和Reduce。业务逻辑的实现者则需要提供这两个函数的具体实现。
Map函数:输入是一系列Key/Value对(k1,v1),经过相应处理之后,Map函数将会产生中间结果Key/Value对(k2,v2)。MapReduce框架将会对中间结果按照Reduce进行分区/汇总/排序,然后调用Reduce函数。
Reduce函数:输入是经过分区/汇总/排序以后的中间结果(k2,list(v2)),输出则是最后的输出,可记为list(v3)。
MaprReduce的大致过程可以描述为:Map(k1,v1)→list(k2,v2);Reduce(k2,list(v2)) →list(v3)。
MapReduce确保每个reducer的输入都按键排序。系统执行排序的过程——将map输出作为输入传给reducer——称之为shuffle。常见的Shuffle操作包括PartitionerClass中的getPartition方法,SortComparatorClass中的compare方法和GroupingComparatorClass的compare方法。Shuffle的过程如下图所示,该过程对于MapReduce相当重要,适当的优化就可以对整个操作的性能产生质的飞跃。
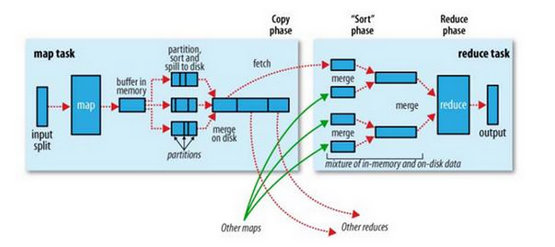
使用Hadoop统计道路-位置点分布状态,主要的思路是将路网数据和位置点数据存储在HDFS的两个目录下,通过运行MapReduce程序,对路网数据和位置点数据执行Reduce端的join的操作,并在每个Reduce函数内进行路网和位置点的关系判断,生成位置点所属车辆的ID和道路ID以及位置点和时间的关系记录。使用生成的关系记录,再执行一次MapReduce的统计,就可以计算出某个时段内每条道路上车辆的分布状态。
这个操作的关键点是在路网数据和位置点数据进行join操作并判断路网和位置点关系的这个流程,通过采用地理网格进行join并在Shuffle阶段以二次排序的方式进行路网和位置点的预排序,经过二次排序后的相同网格内的数据,可以在Reducer方法中进行高效的空间关系判断。执行这一流程的步骤如下:
1.确定地理网格的划分方式
划分地理网格的目的是使不同的网格内的路网和位置点数据可以在Reduce中并行的执行。适当的划分地理网格的范围,可以使资源更加合理的调配,提高运行的效率。每个地理网格会被设定一个ID,这个网格ID将会成为路网数据和位置点数据执行join操作的依据。例如ID为11025_3810的网格表示东经110.25度到110.30度,北纬38.10度到38.15度之间的地理区间。
2.Map阶段
由于HDFS中路网数据目录和位置数据的目录都被设定为MapReduce的InputPath,因此在map阶段,路网数据文件和位置数据文件的每行都会成为map函数的value参数,通过对该行数据格式的判断,可以确定该行数据是路网数据或是位置数据。
如果是位置数据,则以该网格的ID和”:point”组成的字符串(如11025_3810:point)作为key,以经度、纬度、时间、车辆ID组成的字符串作为value,生成一组map输出的key/value对并执行map的输出。
如果是路线数据,则需要找到与该路线相交的所有地理网格,实现该操作的方法是判断路线外接矩形的四个顶点所位于的地理网格,然后遍历经纬度位于所有顶点网格之间的所有网格。对于每一个网格,都会输出一个Key/Value对,Key是网格ID和” :line“组成的字符串(如11025_3810:line),value是路线点序列和路线ID组成的字符串。
该过程的主要步骤大致如下:

3.shuffle阶段
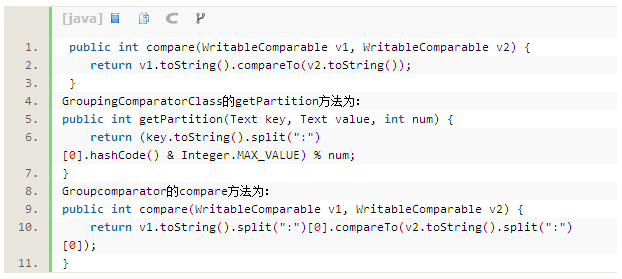
在Map执行阶段,输出记录的key的格式是网格ID+数据文件类型的组合,为了使具有相同网格ID的输出进入相同的Parition,需要对Partitioner的getPartition函数进行重写,将选择分区的方式修改成使用key字符串的网格ID的部分进行选择。Partition阶段之后,会在map端和reducer端分别根据SortComparatorClass中指定的compare规则进行排序。对于相同的网格ID,由于”line”字符串的字典排序在”point”字符串之前,而我们也希望排序的最终结果是数据量相对很小的路网数据排列在位置点的前面,因此compare函数制定的排序规则是v1.toString().compareTo(v2.toString())即可。排序阶段完成后,会根据GroupingComparatorClass中制定的排序规则,确定最后的Value序列在reduce函数中的排序。GroupingComparatorClass的compare函数会确定最终具有哪些key的value会出现在同一个reduce函数的参数列表中。根据业务规则,我们希望具有相同的网格ID的数据被排列到相同的reduce函数中,因此该compare函数需要从key中获取网格ID部分,然后根据字典顺序排序。
SortComparatorClass的compare方法为:
4.reduce阶段
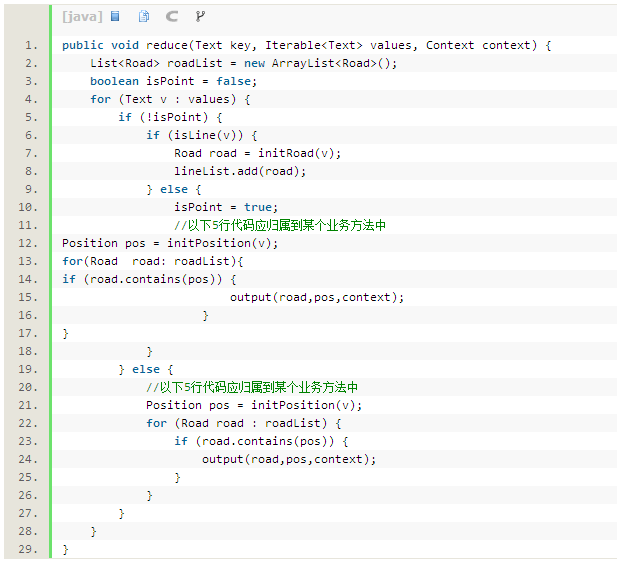
Reducer中的reduce函数每次被调用的时候,函数的第一个参数是一个包含网格ID的key,第二个参数是该网格内所有位置点以及与该网格相交的所有路线的数据组成的一个Iterable。通过Shuffle过程的优化,在使用Iterable遍历数据时,所有路网数据都排列在位置点数据的前端。这样的排序方式,可以使判断网格内所有路网和位置点的空间关系的操作只需要遍历一次Iterable。当遍历完位于最前端的路网数据的时候,就可以将所有的路网数据保存在一个list中。遍历的下一步就是开始遍历所有位置点,每遍历一个位置点,都要与保存路网数据的list中的每条数据进行空间关系判断,计算位置点是否位于该路网上。
该过程的主要步骤大致如下:
在数据规模较大的场景下统计位置点和路网的空间关系,由于涉及到两类数据进行join操作并执行空间计算的工作,因此传统的基于单服务器地理信息系统运算的模式会遇到很严重的性能问题,当数据量超过一定规模后,传统的方式甚至无法执行空间数据统计的工作。基于Hadoop的MapReduce框架,采用以地理网格进行join的方式,通过二次排序排列地理类型,可以使统计操作的空间、时间复杂度或是编程的工作量都会大为降低,使原本非常复杂的工作变成可以在生产环境中被常规操作的工作。
采用上述方法进行地理空间分析,对于类似在一个较大地理范围内统计某个时段内车辆在各条道路上的分布情况这样的应用场景可以发挥有效的作用。这种应用场景对于分析全国交通流量状态,规划路网设计的工作都有非常重要的参考价值。而在Hadoop上,使用基于网格的join操作,几乎可以应用于各种数据规模庞大的地理统计分析之中。目前,在实验环境下进行统计测试,对于600G的车辆轨迹点数据和300M的路网数据,在由10台PC服务器组成的Hadoop集群中,完成车辆轨迹点在路网上的分布情况的统计,大约耗时5小时可以完成,而采用传统技术对于这种数据规模的轨迹点和路网数据进行空间分析,需要耗费数天的时间。在下一步的工作中,可以将这样的地理空间统计方法推广到性能更加优秀的Spark平台,在数据规模不是很大的情况下,这种方法对于实时计算各条道路上的车辆分布情况,预测交通流量,解决道路拥堵问题,将会发挥很有实际意义的效用。
作者:杨晓明,阿里巴巴技术专家,曾担任中交兴路系统架构师。2003年开始全职从事软件研发工作,2007年后一直担任架构师的工作。曾参与民航航空安全管理信息系统、民航总局运行管理中心、中国空中交通流量预测系统、交通部全国货运监管服务平台、雅迅车联网系统、浪淘金全媒体推荐引擎、位客网、分分网、简单网等包括政府平台、SNS系统及电子商务平台的开发和架构工作。长期关注新兴技术,目前主要研究可应用于交通领域的高并发、大数据及数据挖掘相关技术。
|






