|
Cloudera和英特尔公司的工程师们正在通力合作,旨在使Spark shuffle阶段具有更高的可扩展性和稳定性。本文对相关方法的设计进行了详细描述。
区别常见的Embarrassingly Parallel系统,类似MapReduce和Apache Spark(Apache Hadoop的下一代数据处理引擎)这样的计算引擎主要区别在于对“all-to-all” 操作的支持上。和许多分布式引擎一样,MapReduce和Spark的操作通常针对的是被分片数据集的子分片,很多操作每次只处理单个数据节点,同时这些操作所涉及到的数据往往都只存在于这个数据片内。all-to-all操作必须将数据集看作一个整体,而每个输出结果都可以总结自不同分片上的记录。Spark的groupByKey、sortByKey,还有reduceByKey这些shuffle功能都属于这方面常见的操作。
在这些分布式计算引擎中,shuffle指的是在一个all-to-all操作中将数据再分割和聚合的操作。显而易见,在实践生产中,我们在Spark部署时所发现的大多性能、可扩展性及稳定性问题都是在shuffle过程中产生的。
Cloudera和英特尔的工程师们正通力合作以扩展Spark的shuffle,使得shuffle可以更加快速与稳定地处理大量的数据集。Spark在很多方面相较MapReduce有更多优势,同时又在稳定性与可扩展性上相差无几。在此,我们从久经考验的MapReduce shuffle部署中吸取经验,以提高排序数据输出的shuffle性能。
在本文中,我们将会逐层解析——介绍目前Spark shuffle的运作实现模式,提出修改建议,并对性能的提高方式进行分析。更多的工作进展可以于正在进行中的SPARK-2926发现。
Spark目前的运作实现模式
一个shuffle包含两组任务:1. 产生shuffle数据的阶段;2.使用shuffle数据的阶段。鉴于历史原因,写入数据的任务被称做“map task”,而读取数据的任务被称做“reduce tasks”,但是以上角色分配只局限于单个job的某个具体shuffle过程中。在一个shuffle中扮演reduce的task,在另一个shuffle中可能就是map了,因为它在前者里面执行的是读取操作,而在后者中执行的是数据写入任务,并在随后的阶段中被消费。
MapReduce和Spark的shuffle都使用到了“pull”模式。在每个map任务中,数据被写入本地磁盘,然后在reduce任务中会远程请求读取这些数据。由于shuffle使用的是all-to-all模式,任何map任务输出的记录组都可能用于任意reduce。一个job在map时的shuffle操作基于以下原则:所有用于同一个reduce操作的结果都会被写入到相邻的组别中,以便获取数据时更为简单。
Spark默认的shuffle实现(即hash-based shuffle)是map阶段为每个reduce任务单独打开一个文件,这种操作胜在简单,但实际中却有一些问题,比如说实现时Spark必须维持大量的内存消耗,或者造成大量的随机磁盘I/O。此外,如果M和R分别代表着一个shuffle操作中的map和reduce数量,则hash-based shuffle需要产生总共M*R个数量的临时文件,Shuffle consolidation将这个数量减至C*R个(这里的C代表的是同时能够运行的map任务数量),但即便是经过这样的修改之后,在运行的reducer数量过多时还是经常会出现“文件打开过多”的限制。
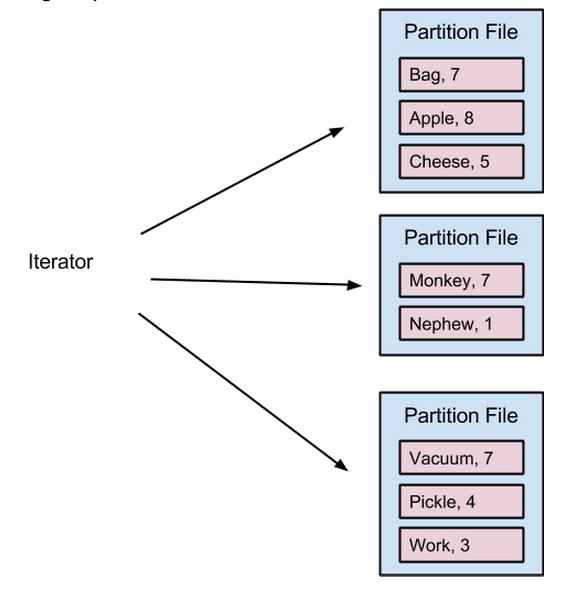
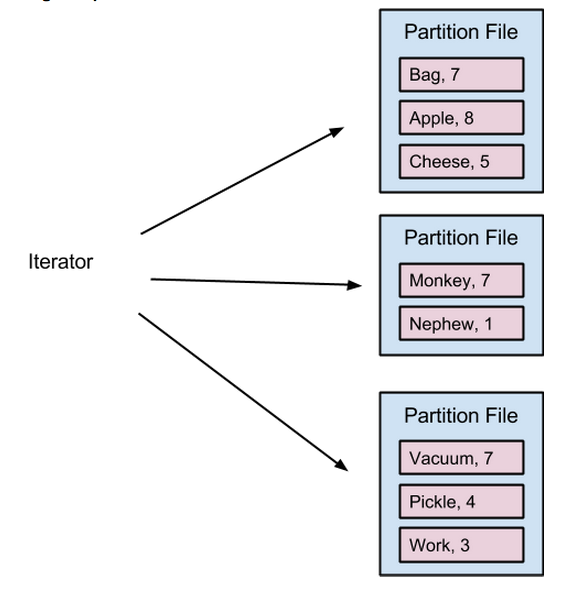
Hash-based shuffle中单个map任务
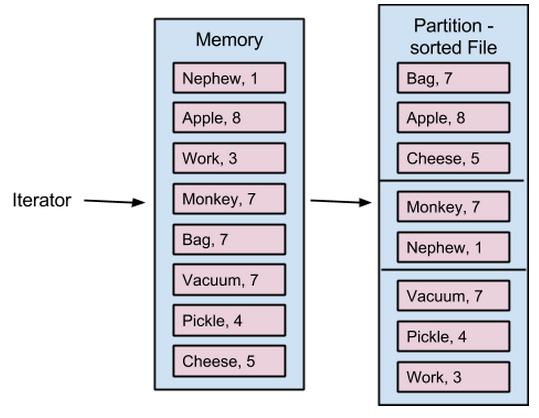
Sort-based shuffle中单个map任务
为了进一步提高shuffle的稳定性与性能,从1.1版本开始,Spark引入了“sort-based shuffle”实现,其功能与MapReduce使用的map方式十分类似。在部署时,每个任务的map输出结果都会被储存在内存里(直到可用内存耗尽),然后在reduce任务中进行排序,之后再spill到一个单独的文件。如果在单个任务中该操作发生了多次,那么这个任务的输出将被合并。
在reduced的过程中,一组线程负责抓取远程的map输出blocks。当数据进入后,它们会被反序列化,再转化成一个适用于执行all-to-all操作的数据结构。在类似groupByKey、reduceByKey,还有aggregateByKey之类的聚合操作中,其结果会变成一个ExternalAppendOnlyMap(本质上是一个内存溢出时会spill到硬盘的哈希map)。在类似sortByKey的排序操作中,输出结果会变成一个ExternalSorter(将结果分类后可能会spill到硬盘,并在对结果进行排序后返回一个迭代程序)。
完全Sort-based Shuffle
上文所描述的方式有两个弊端:
- 每个Spark reduce的任务都需要同时打开大量的反序列化记录,从而导致内存的大量消耗,而大量的Java对象对JVM的垃圾收集(garbage collection)产生压力,会造成系统变慢和卡顿,同时由于这个版本较之序列化的版本内存消耗更为巨大,因而Spark必须更早更频繁的spill,造成硬盘I/O也更为频繁。此外,由于判断反序列化对象的内存占用情况时难以达到100%的准确率,因此保持大量的反序列化对象会加剧内存不足的可能性。
- 在引导需要在分片内的排序操作时,我们需要进行两次排序:mapper时按分片排序,reducer时按Key排序。
我们修改了map时在分片内按Key对结果进行排序,这样在reduce时我们只要合并每个map任务排序后的吧blocks即可。我们可以按照序列化的模式将每个block存到内存中,然后在合并时逐一地将结果反序列化。这样任何时候,内存中反序列化记录的最大数量就是已经合并的blocks总量。
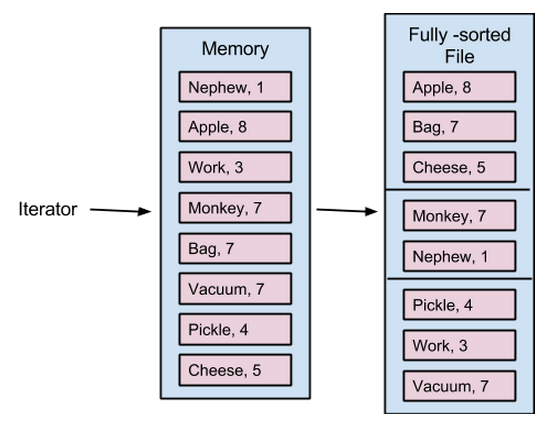
完全sort-based shuffle中的单个map任务
单个reduce任务可以接收来自数以千计map任务的blocks,为了使得这个多路归并更加高效,尤其是在数据超过可用内存的情况下,我们引入了分层合并( tiered merger)的概念。如果需要合并许多保存在磁盘上的blocks,这样做可以最小化磁盘寻道数量。分层合并同样适用于ExternalAppendOnlyMap以及ExternalSorter的内部合并步骤,但是暂时我们还没有进行修改。
高性能合并
每个任务中有一组线程是负责同步抓取shuffle数据的,每个任务对应的内存池有48MB,用来存放相应的数据。
我们引入了SortShuffleReader,先从内存池中获取到blocks,然后[key, value]的方式向用户代码中返回迭代器对象。
Spark有一个所有任务共享的shuffle内存区域,默认大小是完整executor heap的20%。当blocks进入时,SortShuffleReader会尝试从该主区域中调用shuffle所需的内存,直至内存塞满调用失败为止,然后我们需要将数据spill到硬盘上以释放内存。SortShuffleReader将所有(好吧,并非所有的,有时候只会spill一小部分)内存中的数据块写入一个单独的文件中并存入硬盘。随着blocks被存入硬盘,一个后台线程会对其进行监视,并在必要时将这些文件合并为更大一些的磁盘blogs。“final merge”会将所有最终硬盘与内存中的blocks全部合并起来。
如何确定是时候进行一个临时的“磁盘到磁盘”合并?
spark.shuffle.maxMergeFactor(默认为100)控制着一次可以合并的硬盘blocks数量的最大值,当硬盘blocks的数量超过限制时,后台线程会运行一次合并以降低这个数量(但是不会马上奏效,详情请查看代码)。在确定需要合并多少blocks时,线程首先会将需要执行合并的blocks数量设定为最小值,并将这个值作为合并数量的上限,以期尽可能减少blocks的合并次数。因此,如果spark.shuffle.maxMergeFactor是100,而磁盘blocks的最终数量为110,这样只需总共进行11个blocks的合并,就可将最终磁盘blocks的数量保持在恰好100。想要再合并哪怕一个blocks,都会需要再一次的额外合并,而可能导致不必要的磁盘I/O。
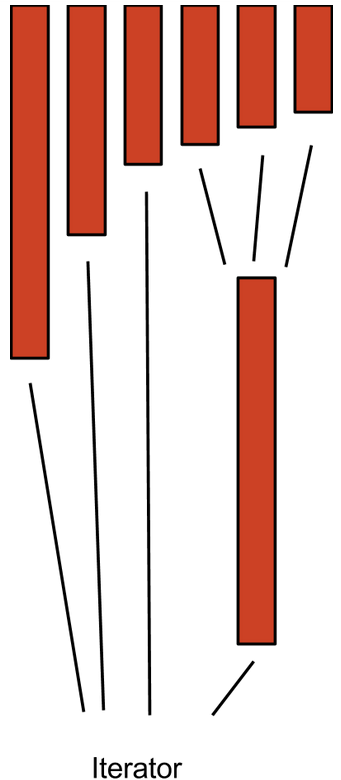
maxMergeWidth为4的分层合并。每个矩形代表一个segment,其中三个合并为一个,然后最终有四个segment被合并到一个迭代器中,以备下一次操作使用。
与sortByKey的性能对比
我们测试了使用SparkPerf进行sortbykey时,在相应的修改后,性能有何变化。在其中我们选择了两个不同大小的数据集,以比较我们的改动在内存足以支持所有shuffle数据时,和不足以支持的情况下对于性能的增益情况。
Spark的sortByKey变化导致两个job和三个stage。
- Sample stage:进行数据取样以创建一个分区范围,分区大小相等。
- Map阶段:写入为reduce阶段准备的shuffle bucket。
- Reduce阶段:得到相关的shuffle结果,按特定的数据集分区进行合并/分类。
引入一个6节点集群的基准,每个executor包含24个core和36GB的内存,大数据集有200亿条记录,压缩后在HDFS上占409.8GB。小数据集有20亿条记录,压缩后在HDFS上占15.9GB。每条记录都包含一对10个字符串的键值对,在两个case中,我们在超过1000个分片中测试了排序,每个stage的运行时间表以及总共的job如下图显示:
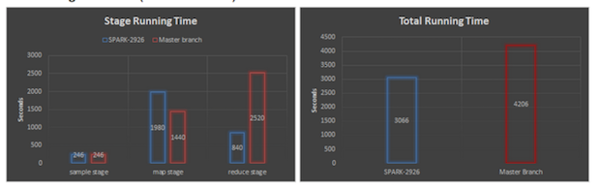
大数据集(越低则越好)
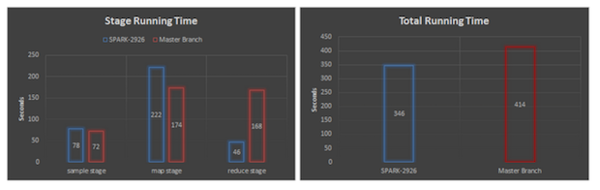
小数据集(越低则越好)
取样阶段耗时相同,因为此阶段并不涉及shuffle过程;在map阶段,在我们的改进下,每个分片中按Key对数据进行排序,导致这个阶段的运行时间增加了(大数据集增加了37%,小数据集则是27%)。但是增加的时间在reduce阶段得到了更大的补偿,由于现在只需合并排序后的数据,Reduce阶段的两个数据集的耗时共减少了66%,从而使得大数据集加速27%,小数据集加速17%。
下面还有什么?
SPARK-2926是Spark shuffle的几个改进计划的成果之一,在这个版本中很多方面上shuffle可以更好地管理内存:
- SPARK-4550 用内存缓冲中的map输出数据作为原始数据,取代Java对象。map输出数据的空间消耗更少,从而使得spill更少,在原始数据的对比上更快。
- SPARK-4452 更详细地追踪不同shuffle数据结构的内存分配,同时将无需消耗的内存尽早返还。
- SPARK-3461 追踪agroupBy后出现的特定Key值相应字符串或者节点,而不是一次将其全部loading入内存。
|






