|
2015��1��10�գ�һ������Spark�ĸ�����Ӧ��ʵ��ʢ����Databricks��������ʦ���ǡ��ٶȸ�����ʦ�������ٶȼܹ�ʦ��⡢�ٶ������з����ĸ��ܹ�ʦ����ɽ��λר�����ִ��졣
2014�꣬Spark��Դ��̬ϵͳ�õ��˴���������ѳ�Ϊ�����������������Ŀ�Դ��Ŀ֮һ����Ծ��Hortonworks��IBM��Cloudera��MapR��Pivotal���ڶ�֪�������ݹ�˾����ӵ��Spark SQL��Spark Streaming��MLlib��GraphX�ȶ�������Ŀ��ͬʱֵ��һ����ǣ�Spark����������һ�����ҵ��й��ˡ�
�̶�����ʱ�䣬Spark������չΪApache�����Ķ�����Դ��Ŀ����ͨ����������ڴ���㼰��ḻ����̬����Ӯ�ü������д����ݴ����û���2015��1��10�գ�һ������Spark�ĸ�����Ӧ��ʵ��ʢ����Databricks��������ʦ���ǡ��ٶȸ�����ʦ�������ٶȼܹ�ʦ��⡢�ٶ������з����ĸ��ܹ�ʦ����ɽ��λר�����ִ��졣
Databricks��������ʦ����——Spark SQL 1.2��������������

̸��Spark SQL 1.2�������������ԣ�������Ҫ�ܽ���4������——External data source API���ⲿ����ԴAPI������ʽ�ڴ�洢��ǿ��Enhanced in-memory columnar storage����Parquet֧�ּ�ǿ��Enhanced Parquet support����Hive֧�ּ�ǿ��Enhanced Hive support����
External data source API
���DZ�ʾ����Ϊ�ڴ����ܶ��ⲿ����Դ�г��ֵ���չ���⣬Spark��1.2�汾������External data source API��ͨ��External data source API��Spark����ͬ���ⲿ����Դ�����һ����ϵ���Ӷ�ʵ�ָ�������IJ�����

External data source API��֧���˶�����JSON��Avro��CSV�ȼ�ʽ��ͬʱ����ʵ����Parquet��ORC�ȵ�����֧�֣�ͬʱ��ͨ�����API������������ʹ��JDBC��HBase�������ⲿϵͳ�Խӵ�Spark�С�
���DZ�ʾ����1.2�汾֮ǰ����������ʵ�Ѿ�ʵ���˸��ָ����ⲿ����Դ��֧�֣���ˣ��Աȸ�ԭ����֧��һЩ�ⲿ����Դ��External data source API����������������Ӧ����Դ���е������Ż�����Ҫ����Column pruning���м�֦����Pushing predicates to datasources����predicates��������Դ���������棺
Column pruning����Ҫ�����ݺ�����ּ�֦�����м�֦�У�Column pruning������ȫ�������账�����ֶΣ��Ӷ������ؼ���IO��ͬʱ����ijЩ������ѯ�У�����Parquet��ORC�����ܸ�ʽд��ʱ��¼��ͳ����Ϣ���������ֵ����Сֵ�ȣ���ɨ�����������ε����ݣ��Ӷ�ʡ���˴����Ĵ���ɨ�踺�ء�
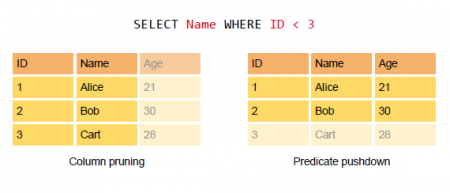
Pushing predicates to datasources���ڸ����ӵ�SQL��ѯ�У��ù�������ά�Ⱦ����ܵĽӽ�����Դ���Ӷ����ٴ��̺�����IO�������������˵��˵����ܡ�
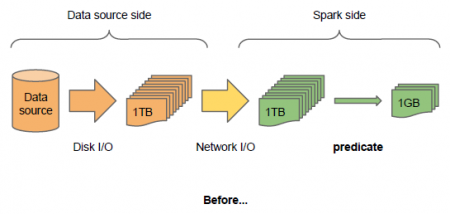
ʹ��External data source API֮ǰ
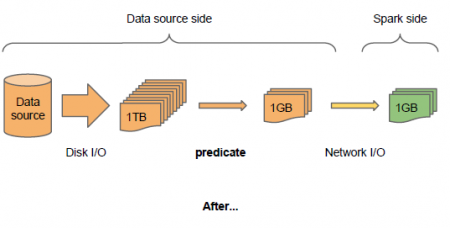
ʹ��External data source API֮��
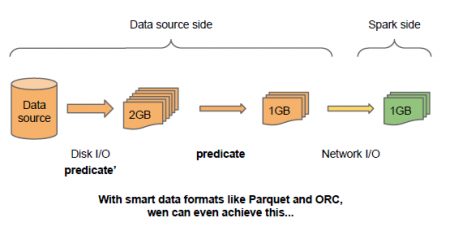
��������Parquet��ORC���������ܸ�ʽ
���DZ�ʾ����Spark 1.2�汾�У�External data source API��û��ʵ��Ԥ���еĹ��ܣ���Roadmap�У�First class��Ƭ֧�֣�First class partitioning support with partition pruning����Data sink��insertion��API����Hive��Ϊ�ⲿ����Դ�ȡ�
Enhanced in-memory columnar storage
���DZ�ʾ������Shark������Spark���ڴ滺�����֧�ֶ��Ƿdz���Ҫ��һ�����ԡ�����ʾ����Ȼ��1.1��֮ǰ�汾�е���ʽ�ڴ����������Ȼ���������ǻ������һЩ���⣺��һ�����������»��泬�������ʱ����Ȼ���Ƽ�������ȱ��ʵ�������������OOM�����⣻�ڶ�������ʽ�洢�У���Parquet��ORC�����ռ�ͳ����ϢȻ��ͨ����Щ��Ϣ��partition skipping�Ȳ�����֮ǰ�汾�в�û����ȫʵ�֡���Щ������1.2�汾�ж��õ��˽�������ڣ�������Ҫ����������ͳһ������ʵ�廯�����ڻ��湲���IJ�ѯ�ƻ���Cache���ʱ��OOM���⡢����ͳ�ƣ�Table statistics���ȷ��档
����ʵ�廯��SQLContext.cacheTable(“tbl”)Ĭ��ʹ��eagerģʽ������ʵ�廯���Զ����У������ٵȵ�����ʹ�û�ʱ�������ֶ���“SELECT COUNT(*) FROM src;”��ͬʱ��������“CACHE [LAZY] TABLE tbl [AS SELECT …]”������DML��
����ͳһ������ʱ��SchemaRDD.cache()��SQLContext.cacheTable(“tbl”)�����������Dz�ͬ�ġ����У�SQLContext.cacheTable��ȥ����һЩ��ʽ�洢��ʽ����Ż�����SchemaRDD.cache()ȴ��һ��һ�������ģʽ���С���1.2�汾�У������������ѱ�ͳһ��ͬʱ����cache���������õ�һ��ͳһ���ڴ����
���ڻ��湲���IJ�ѯ�ƻ��������õ���ͬ�����cache��佫����ͬһ�ݻ������ݡ�
����Cache���ʱ��OOM���⡣�Ż��ڴ���Ľ����ͷ��ʣ����ٿ�������һ���������ܣ��ڻ�����ʱ������batched column buffer builder����ÿһ���гɶ��batch���Ӷ�������OOM��
����ͳ�ơ�Table statistics������Parquet��ORCʹ�õļ�������1.2�汾����Ҫʵ����Predicate pushdown��ʵ�ָ���ı���ɨ�裩��Auto broadcast join��ʵ�ָ���ı���join����
������ǻ���ϸ������һЩ���ڼ�ǿParquet��Hive֧�ֵ�ʵ�֣��Լ�Sparkδ����һЩ������
�ٶȻ����ܹ���������ʦ����——Spark�ڰٶȿ�����BMR�е�ʵս����

�ٶȷֲ�ʽ�����ŶӴ�2011�꿪ʼ������עSpark������2014�꽫Spark��ʽ����ٶȷֲ�ʽ������̬ϵͳ�У��ڹ���������������ҵ�û��Ƴ���֧��Spark�����ݿ�Դ�ӿڵĴ����ݴ�����ƷBMR��Baidu MapReduce�����������ķ����У�������Ҫ�˽��˰ٶ�Spark Ӧ����״���ٶȿ�����BMR��Spark On BMR������������ݡ�
Spark�ڰٶ�
������ʾ����ǰ�ٶȵ�Spark��Ⱥ����ǧ̨��������������Cores���ϰ�TBMemory����ɣ����ύApp�����٣���Ӧ���ڷﳲ����������ֱ��š��ٶȴ����ݵ�ҵ��֮��ѡ��Spark�������ܽ�������ԭ���ٸ�Ч��API �Ѻ����ú�����ḻ��
���ٸ�Ч�����ȣ�Sparkʹ�����̳߳�ģʽ���������Ч�ʺܸߣ���Σ�Spark��������ȵ������ڴ棬���ֵ�������ִ��Ч�ʸߡ�
API�Ѻ����á�����Ҫ�����������棺��һ��Spark֧�ֶ��ű�����ԣ��������㲻ͬ���Ա�������ʹ�ã��ڶ���Spark�ı��������dz��ḻ�����ҷ�װ�˴������ò�����
����ḻ��Spark��̬Ȧ�����ѱȽ����ƣ��ڹٷ��������SQL��ͼ���㡢����ѧϰ��ʵʱ�����ͬʱ�������źܶ�������������������������Ӧ���ճ������ݴ�������
�ٶȿ�����BMR
��BMR�����У�������ʾ����ȻBMR����ΪBaidu MapReduce��������������Ѿ�������ȫ��ʾ�����ƽ̨��BMR�ǰٶȿ����Ƶ����ݷ��������Ʒ�����ڰٶȶ�������ݴ����������飬������ҵ�Ϳ������ṩ���貿���Hadoop&Spark��Ⱥ��������ÿͻ��߱��������ݷ������ھ��������Ӷ�����ҵ��������
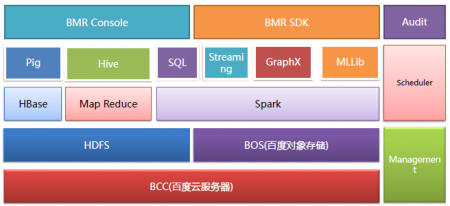
��ͼ��ʾ��BMR����BCC���ٶ��Ʒ���������������HDFS��BOS���ٶȶ���洢���ֲ�ʽ�洢֮�ϣ��䴦�����������MapReduce��Spark��ͬʱ��ʹ����HBase���ݿ⡣�ڴ�֮�ϣ�ϵͳ������Pig��Hive��SQL��Streaming��GraphX��MLLib��ר�з�����ϵͳ�����ϲ㣬BMR�ṩ��һ������Web�Ŀ���̨���Լ�һ��API��ʽ��SDK��
��ͼƬ�����ұߣ�Scheduler��BMR�����˹������ã�ʹ���������߿��Ա�д�Ƚϸ��ӵ���ҵ����
Spark On BMR
������ͨ�����Ʒ���BMR�е�Sparkͬ���������𣬼�Ⱥ���м����٣������û���ʡԤ�㡣���⣬��Ⱥ����������3��5��������ɣ�������������Spark+HDFS+YARN��ջ��ͬʱ��BMRҲ�ṩLong Runningģʽ�����ж����ײͿ�ѡ��
�ٶȻ����ܹ����ܹ�ʦ���——�ٶȸ�����ͨ��Shuffle����

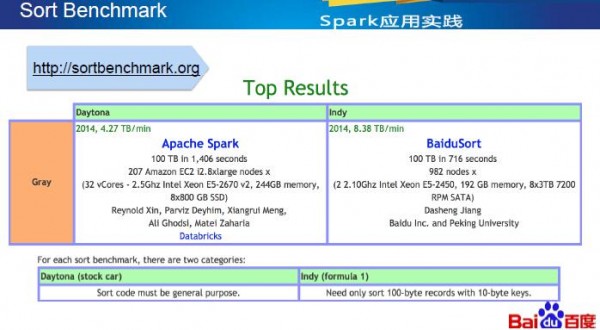
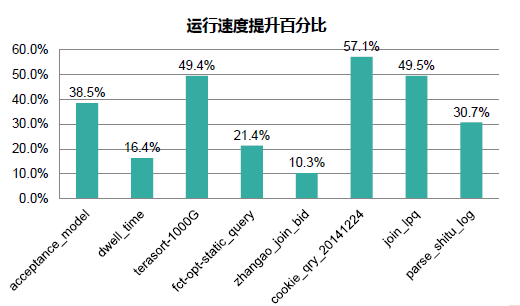
��2014 Sort Benchmark���ʴ����ϣ��ٶȳɹ���ڣ���Ļ��Ӣ������Խ��Shuffle���ƣ������ķ����У����Ƕ�Shuffle�ķ�չ��ϸ�ں�δ������һ����ȵĽӴ���
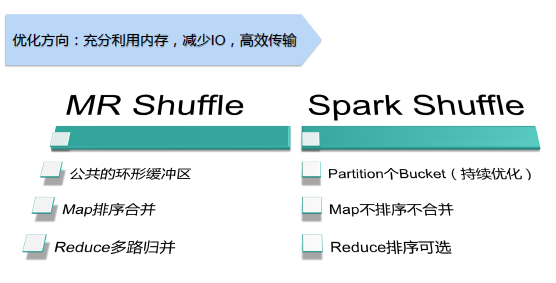
Shuffle���
����ʾ������˵��Shuffle���ǰ���һ���ķ������Mapһ�����ݣ�Ȼ����Reduce�ˡ����ܶ���MapReduce����Spark��Shuffle����һ���dz���Ҫ�ĽΡ�Ȼ������ȻShuffle�����������ͬ��������Spark��MapReduce�У�Shuffle���̣�����ʱ���ϸ�ڣ���Ȼ����һ���IJ��
Baidu Shuffle��չ����
ͨ������˽��Shuffle�ڰٶȵķ�չ��Ҫ���������Σ����������Ͷ�����չ����2008��ٶȵ�MapReduce/Hadoop��ʼ���ٶȾͿ�ʼ����������ʹ�������汾���ڼ����Ҫ��������Bug���������Ż��������棨�����ڴ�ء�����JVMGC������Server��Jetty��Netty�����������䡢�ۺ����ݵȷ��棩��
������shuffle��Map/Reduce
��2012�꿪ʼ��Baidu Shuffle����������չ�Σ���ҪԴ����һ��������ϵͳ�Ŀ�����Shuffle������Ϊ������ShuffleService���Ӷ�����˼�Ⱥ��Դ�������ʡ�
��ֹ��ʱ�������������汾��MapReduce/Spark�������ǰٶ��з���ShuffleService�����Ƕ��ǻ��ڴ��̵�PULLģʽ�����ڴ��̣�����Map�����ݶ���ŵ����̣���ȻSpark�ų��ڴ���㣬�����漰��Shuffleʱ���ǻ�д���̡�����PULL�����������ڷŵ�Map�˵Ĵ���֮��Reduce��ʹ��ʱ����Ҫ����������������˻��ܵ���������Ӱ�죺���ȣ�ҵ�����ݴ洢��Map�˵ķ������ϣ�����崻�ʱ��ɱ��ⶪʧ���ݣ���һ���ڴ��ģ�ֲ�ʽ��Ⱥ�зdz���������Σ�����Ҫ���ǣ�Shuffle�λ���������Ĵ���Ѱ��������������������㣨�м����ݴ��ڱ��ش��̣����ٸ����ӣ�ij������1�����Map��1���Reduce�����һ�δ���Ѱ����ʱ����10���룬��ô��Ⱥ�ܹ��Ĵ���Ѱ��ʱ��= 1000000 ×10000 ×0.01 = 1���롣
New Shuffle
������Щ���⣬�ٶ�����˻����ڴ��PUSHģʽ����ģʽ�£�Map��������ݽ�������̣������ڴ��м�ʱ��Push��Զ�˵�Shuffleģ�飬�Ӷ����������������
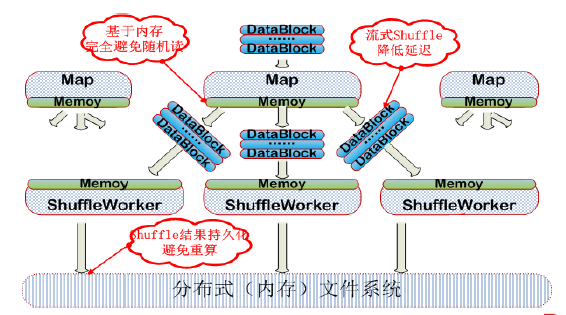
New Shuffle������
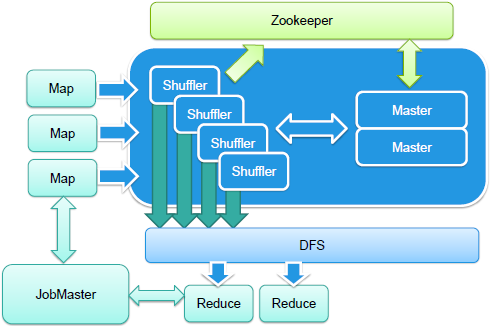
New Shuffle�ܹ�
��ͼ��ʾ����ɫ����ΪNew Shuffle���֣���Ҫ�����������֣�����д��Ͷ�ȡ��API��Map�˻�ʹ������ӿ�����ȡ���ݣ�Reduce��ʹ������ӿ�����ȡ���ݣ���Σ�������Ҫ���ǣ���������ʹ���˵��͵����Ӽܹ����ö��shuffle�����߽ڵ���shuffle���ݡ�ͬʱ����ϵͳ����У�Master�dz������ں�����չ����shuffle�����Ϊ�����ֲ�ʽϵͳ��ƿ����
��New Shuffleģ��רע��shuffle�����������ⲿ����ģ�飬�Ӷ�����ģ�����רע�ڼ��㣬ͬʱ�������˴���IO��Ȼ��New Shuffle����������Ҳ��֮��©������Ӱ��Ƚ���Ҫ���������ǣ����ڵ�������ظ���
���ڵ㡣��shuffleд������г������ڵ�Ϊ����ͨ������������������ȣ�Shuffle�������ڵ㣬�Ա������汾��ֻ��Ӱ�쵽һ��task��New Shuffle�г�����Ӱ�쵽һƬ��Ⱥ��������ٶ�Ϊÿ��Shuffle�ڵ㶼������һ���ӽڵ㣬��Map��һ�����ڵ�ʱ��ϵͳ���Զ��л����ӽڵ㡣��Σ�DFS�������ڵ㣬�������£�Shuffle�Ĵӽڵ�ֻ���������á���������£�����DFSϵͳ���Զ��������ڵ㣬�������滻�����磬��ͳ��HDFS����pipeline����ʽ����д�룬��DFS��ת��Ϊ�ַ�д��
�ڴ�֮�⣬New Shuffle����Ҫ����������⣬������Դ��������ȡ�ͬʱ������New Shuffle�Ļ��ƣ�New Shuffle������һЩ������ս������Reduceȫ���������ݹ��ڷ�ɢ����DFSѹ�������������ȵȡ�
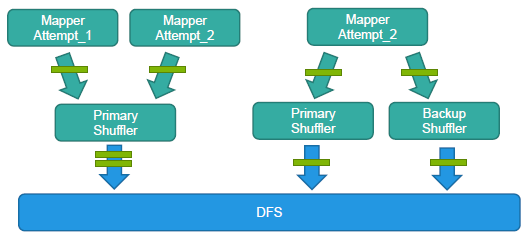
�����ظ�������ͼ��ʾ����Щ������Ҫ��ΪNew Shuffle���ϲ����ȱ�ٸ�֪���������Ľ����Ҫʹ��task id��block id����ȥ�ء�
New Shuffleչ��
����ʾ��New Shuffleʹ����ͨ�õ�Writer��Reader�ӿڣ������Ѿ�֧�ְٶ�MR��DCE��DAG��C++����ͬʱ�����Կ�ԴSpark�ṩ֧�֡���δ����New Shuffle���ɽ���Ϊ��ͨ�õ������֧�ָ���ļ���ģ�͡�
�ٶ���������з����ĸ��ܹ�ʦ����ɽ——Fast big data analytics with Spark on Tachyon

Tachyon��һ���ֲ�ʽ���ڴ��ļ�ϵͳ�������ڼ�Ⱥ���Է����ڴ���ٶ������ʴ���Tachyon����ļ���Tachyon�Ǽܹ��ڷֲ�ʽ�ļ��洢���ϲ���ּ�����֮����м������Ҫ������Щ����Ҫ�䵽DFS����ļ����䵽�ֲ�ʽ�ڴ��ļ�ϵͳ�У��Ӷ��ﵽ�����ڴ棬�����Ч�ʡ�1��10����������һ�������У�����ɽ������һ��Tachyon�����������
Tachyon��Spark
����ɽ��ʾ����Sparkʹ�ù����У��û�����������3�����⣺���ȣ�����Spark ʵ��ͨ���洢ϵͳ���������ݣ���������жԴ��̵IJ����������������ܣ���Σ���ΪSpark��������ɵ����ݶ�ʧ������������ջ��ƣ��������Sparkʵ������ͬ�������ݣ���ô������ݻᱻ�������Σ��Ӷ���ɺܴ���ڴ�ѹ�������������ܡ�

ʹ��Tachyon���洢���Դ�Spark�з��봦���������רע�ڼ��㣬�Ӷ�������������3�����⡣
Tachyon�ܹ�
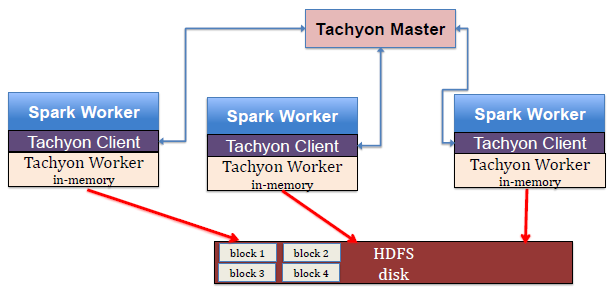
����ɽ��Spark�ĽǶȷ�����Tachyon�IJ�������Spark����ʹ��ʱ��ϵͳ�Ὠ��һ��Tachyon��job��ͨ��Tachyon Client������ͬһ�������ϵ�Tachyon Worker��Ҳ���ǻ����ϵ��ڴ档��Tachyon Client�����Tachyon Master�����������ÿ���ֽڵ������������ݡ��ɴ˿ɼ���������Tachyon ϵͳ�У�Master��Client��WorkerΪ����Ҫ���������֡�
Tachyon Master��Master��Ҫ������Inode��Master Worker Info��Inode�Ḻ��ϵͳ�ļ��ӣ�Master Worker Info��洢������Worker����Ϣ��
Tachyon Worker��Worker��Ҫ����洢������Worker Storage������Ҫ�����ݽṹ������Local data folder��Under File System�������֡�����Local data folder��ʾ���ڱ��ص�Tachyon�ļ���Under File System�����HDFS�ж�ȡWorker��δ���ֵ����ݡ�
Tachyon Client��ClientΪ�ϲ��û��ṩ��һ�����Ļ��ƣ���TachyonFS�ӿڸ�����������ÿ��Client���ж��Tachyon File������Block In Stream�����ļ���ȡ��Local Block In Stream���𱾵ػ�����ȡ��Remote Block In Stream�����ȡԶ�̻�������Block Out Stream��Ҫ�����ļ�д�����ػ����ϡ���Client�ϣ�Master Client����Master������Worker Client����Client������
Tachyon�ڰٶ�
ΪʲôҪʹ��Tachyon������ɽָ�����ڰٶȣ����㼯Ⱥ�ʹ洢��Ⱥ��������ͬһ������λ�õ��������ģ��ڴ����ݷ���ʱ��Զ�����ݶ�ȡ�������dz��ߵ���ʱ���ر���ad-hoc��ѯ����ˣ���Tachyon��Ϊһ�����仺��㣬�ٶ�ͨ���Ὣ֮�����ڼ��㼯Ⱥ�ϡ��״β�ѯʱ�����ݻ��Զ�̴洢ȡ���������Ժ�IJ�ѯ�У����ݾͻ�ӱ��ص�Tacnyon�϶�ȡ���Ӷ�����ĸ�������ʱ��
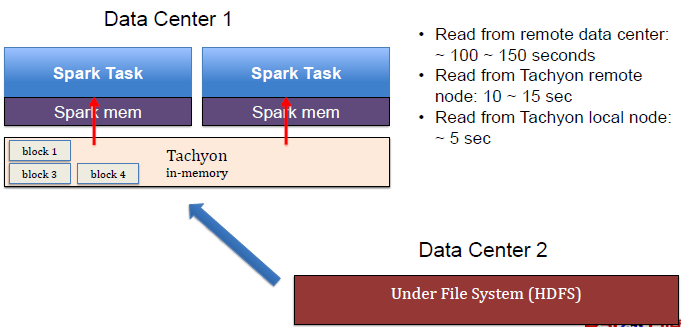
�ڰٶȣ�Tachyon�IJ����ڳ�ʼ�Σ���Լ������50̨��������Ҫ������ad-hoc��ѯ��
ʵ������������ս
ͨ������ɽ�˽��Tachyon��ʹ�ù��̲�����һ����˳�����磺��ΪTachyon�����Block��ȫ��ȡ���Ӷ��������Blocks��δ�����棻��ʱ����Ȼscheduler�Ѿ�ȷ�������ݴ��ڱ��أ�Spark workers��Ȼ��Զ��blocks��ȡ��������������Ҳֻ�п�����33%���������Ҫ����2��block��Tachyon��ֱ��1��2��3��block��ȡ���Ӷ���block��ȡ��3�ݣ�����ˣ�����ɽ��ʾ�����Ҫʹ�ú�Spark��Tachyon��һ��Ҫ��������Tachyon���г�ֵ��˽⡣
�����������ɽ��������Hierarchical Storage Feature�����Լ��ٶ�δ���Ĺ��������а��������滻���Եȡ�
| 





