ժҪ:
ͨ���������ܣ����Ƕ� Big SQL ����ϵ�ṹ������ԭ���������ص�����һ���������˽⣬�����ʹ�� Big
SQL ���������ز����� Hive��HBbase ��Ҳ����һ���Ƚ�ȫ����˽⣬���⣬���ǻ������� Big
SQL ��ѯ�Ż��ĸ��ַ� ...
����֪�����������ݹ�ģ��ըʽ����������������Ϸ����Լ����ݴ����ٶȲ��ϼӿ죬�����ݴ���������ƽ̨Ӧ�˶����������ݴ���ƽ̨Ϊ���Ǹ��õ��ۺ����ýṹ������ṹ�����ǽṹ�����ݡ��������Լ��������ݽ��з����ṩ�˼�ʵ�Ļ����������ݴ���ƽ̨��Ҫ�������ھ�̬�����ݷ�����
Hadoop ƽ̨�Լ����������ݴ�����������ƽ̨��Hadoop �����ݴ���ƽ̨�� Apache Hadoop
Ϊ�����������ڲ�ͬ�ķ��а汾��
IBM InfoSphere BigInsights �� IBM �� Hadoop
�����ݴ���ƽ̨������ Apache Hadoop Ϊ�������������˴����ݴ���ƽ̨����ҵ���ԣ��������ɵİ�װ���������������ߣ�NameNode��Job
Tracker ������ĸ߿��ã���ȫ����ǿ�����ܵ���ǿ��Map/Reduce ������ܵ���ǿ��ʹ�ñ���
SQL ���ʴ������Լ������л�����ʩ�ʹ����������㼼����ļ��ɵȣ����⣬IBM InfoSphere
BigInsights ���ṩ���ı�����������ѧϰ�������ھ��ӻ������ȴ����ݷ���������
Ŀǰ��Hadoop �����ݴ��������ڻ�������ҵ�Ѿ��õ��˹㷺��Ӧ�ã����С����ż���������ҵ�û�Ҳ��ʼ���ô����ݴ����������Ӵ�����Ӧ�ó����Ƕ����������ݲֿ���ǿ��
Hadoop ������Ӧ�ô�����һ���dz���Ҫ��ʹ�ó���������֪�������ݲֿ�ϵͳͨ������ø߶˷��������߶˴洢���ṩ�������ݴ洢����Ч���ݴ������������Ŵ�����ʱ�����������ݹ�ģ�ʱ�ըʽ���������ݲֿ�洢�������ɱ�Ҳ�Ἣ��������Ϊ�˽��ͳɱ������ǿ��Խ����ݲֿ��еĺ�����ʷ����ж�ص�
Hadoop ƽ̨������ Hadoop ƽ̨�����ijɱ��� Map/Reduce ���д��������ṩ��ʷ���ݵIJ�ѯ�����������������ô�ͳ�����ݲֿ�ϵͳ��Ч�����������ݡ�
�ڴ����ݼ����ƹ㡢ʹ�ù����У�һ���ܴ����ս�������ʹ��Ŀǰ��ҵ�û��㷺ʹ�õı�
SQL �����ʻ��� Hadoop ƽ̨�Ĵ����ݣ�ʹ����ҵԭ��Ӧ�������ʴ����ݣ��ر������ݲֿ���ǿʹ�ó��������Ǵ��������ݻ���Ҫ�Ǻ����Ľṹ�����ݣ�������Ȼ��Ҫʹ�ñ���
SQL ��ʹ����ҵԭ�еij��������ʴ����ݡ�Ŀǰ��ʹ�ô����ݼ�����ͨ��ʹ�� Hive��Pig �� Java
���������� Hadoop �����ݣ���Ҫ�û�ѧϰ�µı�����ԣ���д��ҵԭ�е�Ӧ�ã����� Hive QL �ṩ��
SQL �ӿڣ�����ֻ֧�ֱ� SQL ���Ӽ���������ȫ����Ӧ�õ�����Ϊ�˽���������⣬IBM �Ƴ���
Big SQL����ʹ�ñ��� SQL �����ʻ��� Hadoop ƽ̨�� InfoSphere BigInsights�����ṩ����
JDBC��ODBC �ӿڣ�����ʹ�����Ϥ SQL ���û�ֱ�ӷ��ʴ����ݣ����ң��������Ż��Ƕȣ�Big SQL
�ṩ���ز�ѯ�� Map Reduce ��������ģʽ����С��ģ���ݣ����ñ��ز�ѯ��ʽ���� Map Reduce
�����п��������ִ��Ч�ʣ��Դ��ģ���ݣ��Զ����� Map Reduce ��ʽ��Ч���С�
Big SQL ����
Big SQL �� IBM ���� Hadoop ƽ̨ InfoSphere
BigInsights �� SQL �ӿڣ����ṩ���� ANSI SQL 92 �������� SQL ������Ա�ܹ����ɵ����ն�
Hadoop ���������ݵIJ�ѯ����ʹ���ݹ���Ա�ܹ�Ϊ Hive��HBase �����ǵ� BigInsights
�ֲ�ʽ�ļ�ϵͳ�д洢�����ݴ����±������⣬LOAD ����ʹ����Ա�ܹ��� Big SQL �����������Ը�����Դ�����ݡ����⣬Big
SQL �ṩ���� JDBC �� ODBC ����������ʹ�������еĹ���ʹ�� Big SQL ��ѯ�ֲ�ʽ���ݡ���Щ�������
Hive ���ڵ�һЩ���ޣ�Ŀǰ��Hive ��֧�� ANSI SQL ���Ӽ�������֧���Ӳ�ѯ�����ں�������֧��
ANSI JOIN ������������͵�֧��Ҳ�о��ޣ�Ŀǰ��֧�� varchar��Decimal �������ͣ����⣬���Ա���
JDBC �� ODBC ���������֧��Ҳ�о����ԡ�ͨ��ʹ�� Big SQL������ʹ�����Ϥ SQL ���û�ֱ�ӷ��ʴ����ݡ�
�������Ż��Ƕȣ�Big SQL �ṩ Big SQL ���������ز�ѯ��
Map Reduce ��������ģʽ������С���ݼ����ȡ��һ���ض� HBase �м����������ݵIJ�ѯ��ͨ�����ڵ����ڵ���˳��ִ�У�����
Map Reduce �����п��������ִ��Ч�ʣ��Դ��ģ���ݣ��Զ����� Map Reduce ��ʽ��Ч���С�
����֮�⣬Big SQL ����� HBase �����ṩ����ǿ��ͨ��ʹ��
Big SQL���û�����Ҫʹ���� Hive �������ӵ���������� HBase ��������֧�ִ�������н�������ֶΣ�����Ϊ
HBase ��������������������ʹ�� LOAD��insert ���Ϊ HBase ��װ�����ݣ�����ָ��ѹ�������ȡ�
Big SQL ��ϵ�ṹ
����ͼ��ʾ��Big SQL ͬ Hive ����Ԫ���ݶ�����Ϣ����ͨ�� Hcatalog
���� Hive metastore���� InfoSphere BigInsights ��Hive metastore
Ĭ�ϲ��� Derby ���ݿ⡣��ˣ�Big SQL �еĶ���ı����Ժ� Hive �ж���ı�������ʣ�Ĭ������£�Big
SQL �д����ı���ʹ Hive ����
�ⲿӦ��ͨ������ JDBC/ODBC ����������� Big SQL��Big
SQL �� SQL ��ѯ���渺�������� SQL �����б��룬����ִ�мƻ���������ͨ����д��ص� SQL
�������߲�ѯ���ܣ��罫�Ӳ�ѯ��д�ɱ����Ӳ�����������ͨ�� SQL �Ż���ʾ������ѡ��ı����ݷ��ʲ��ԡ����ݲ�ѯ�����ʡ����������������أ�Big
SQL ����ʹ�� Hadoop �� MapReduce ��ܲ��д������ֲ�ѯ�������ڵ����ڵ��ϵ� Big
SQL �������ϱ���ִ�����IJ�ѯ�� Ҳ���Բ��ֲ�ѯ������ Hadoop �� MapReduce �������ɣ����ֲ�ѯ������
Big SQL ����������ɡ�
Big SQL ͨ�� Hive �洢��������д���ݡ�SQL ��ѯ������Ը��ݲ�ͬ���������ͣ�ѡ��ͬ�Ĵ洢��������װ�ز�ͬ�����ݴ���������ȡ���ݡ�Big
SQL ֧�� Delimited files��Sequence files��RC files��Custom��Partitioned
tables �ȶ������ݸ�ʽ��ͬʱ֧�� Hive SerDe �ṩ�ĸ��ֱ��뷽ʽ������ Text��Binary��Avro��Thrift��JSON��Custom��Big
SQL ���ṩ���Լ�ר�е� HBase �洢����������� HBase �����ṩ�˺ܶ���ǿ���ܣ�����֧���ַ�������Ʋ�ͬ�ı��뷽ʽ��֧������н�������ֶΡ�����Ϊ
HBase ���������������ȡ�

ͼ 1. Big SQL �ܹ�
ʹ�� Big SQL
���� Big SQL ����
������Ҫ���� Big SQL ���������� Big SQL��������ʾ�������Թ���Ա����
(biadmin) ��¼ϵͳ����ʹ����������������ֹͣ����ѯ Big SQL ����
�嵥 1. ���� Big SQL ����
biadmin@imtebi1:/opt/ibm/biginsights/bin> $BIGSQL_HOME/bin/bigsql stop
BigSQL pid 2850313 stopped.
biadmin@imtebi1:/opt/ibm/biginsights/bin> $BIGSQL_HOME/bin/bigsql start
BigSQL running, pid 2893219.
biadmin@imtebi1:/opt/ibm/biginsights/bin> $BIGSQL_HOME/bin/bigsql status
BigSQL server is running (pid 2893219)
biadmin@imtebi1:/opt/ibm/biginsights/bin> $BIGSQL_HOME/bin/bigsql level
IBM BigInsights Big SQL Server Version number is "V2.1.0.1
and level identifier is "20130821". |
����Ҳ����ʹ�� BigInsights �����ļ��ɹ���������������ֹͣ����ѯ
Big SQL ����������ʾ��
�嵥 2. ʹ�ü��ɹ����������� Big SQL ����
biadmin@imtebi1:/opt/ibm/biginsights/bin> $BIGINSIGHTS_HOME/bin/stop.sh bigsql
biadmin@imtebi1:/opt/ibm/biginsights/bin> $BIGINSIGHTS_HOME/bin/start.sh bigsql
biadmin@imtebi1:/opt/ibm/biginsights/bin> $BIGINSIGHTS_HOME/bin/status.sh bigsql |
���ǻ�����ʹ�� BigInsights �����ļ��ɹ������������� BigInsights
�����з����� Big SQL ����������ʾ��
�嵥 3. ���� BigInsights �����з���
biadmin@imtebi1:/opt/ibm/biginsights/bin> $BIGINSIGHTS_HOME/bin/stop-all.sh
biadmin@imtebi1:/opt/ibm/biginsights/bin> $BIGINSIGHTS_HOME/bin/start-all.sh |
���⣬���ǻ�����ͨ�� BigInsights �ṩ�� Web Console
����������������ֹͣ����ѯ Big SQL ����������ʾ������ͨ��ִ�� http://172.16.42.202:8080/
������ BigInsights Console����ѡ�� Cluster Status �˵���

ͼ 2. ʹ�� Web Console ����
Big SQL ����
���� Big SQL
BigInsights �ṩ���ֹ��߷��� Big SQL��������
1.JSqsh �����з�ʽ
2.BigInsights console ��������
3.Big SQL Eclipse plugin
4.ͨ�õ� JDBC/ODBC ��������
5.JDBC/ODBC Ӧ�ó���
ʹ�������з��� Big SQL
BigInsights �ṩһ����Դ JDBC �����й��� JSqsh
������ Big SQL�����ǿ���ִ���������������� jsqsh ��ִ�� SQL ��ѯ ��������ʾ��
�嵥 4. ���� jsqsh ��ִ�� SQL ��ѯ
biadmin@imtebi1:/opt/ibm/biginsights/bigsql>$BIGSQL_HOME/bin/jsqsh
--user=biadmin --password=password --server localhost --port 7052 --driver=bigsql
JSqsh Release 1.5-ibm, Copyright (C) 2007-2013, Scott C. Gray
Type \help for available help topics. Using JLine.
[localhost][biadmin] 1> select * from hbase_staff; |
����Ҳ����ʹ���������������� Big SQL �ű���������ʾ��
�嵥 5. ���� Big SQL �ű�
biadmin@imtebi1:/opt/ibm/biginsights/bigsql/samples/queries>
$BIGSQL_HOME/bin/jsqsh --user=biadmin --password=password --server localhost
--port 7052 --driver=bigsql -i GOSALESDW_starSchemaJoin.sql |
���⣬���ǻ�����ʹ�� jsqsh �C setup ������Լ������ӻ�����������ʾ��
�嵥 6. �����Լ������ӻ���
biadmin@imtebi1:/opt/ibm/biginsights/bigsql/bin> ./jsqsh --setup |
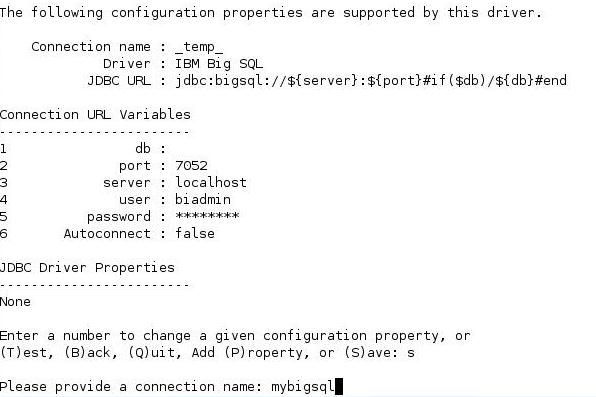
ͼ 3. ʹ�� jsqsh �C setup
��������ӻ���
���������ǿ���ʹ�ö�������Ӵ������Լ������ӻ�����������ʾ��
�嵥 7. �����Լ��Ļ���
biadmin@imtebi1:/opt/ibm/biginsights/bigsql/bin> ./jsqsh mybigsql |
ʹ�� Web Console ���� Big SQL
���ǿ���ͨ�� BigInsights �ṩ�� Web Console ��������������
Big SQL��������ʾ������ͨ��ִ�� http://172.16.42.202:8080/ ������ BigInsights
Console����ѡ�� Quick Links �е� Run Big SQL Queries �˵�������
Big SQL ��ѯ��䡣

ͼ 4. ʹ�� Web Console ����
Big SQL ��ѯ
ʹ�� Eclipse ���߷��� Big SQL
���ȣ�ͨ��ִ�� http://172.16.42.202:8080/ ������
BigInsights Console����ѡ�� Quick Links �е� Download the
Big SQL Client drivers ������ Big SQL client drivers��Ȼ��ͨ��ִ��
/usr/local/eclipse/eclipse/eclipse ����� BigInsights
Eclipse �������ߣ�ѡ�� Windows �˵��µ� Preferences �˵���ͨ��ѡ�� Data
Management ѡ���µ� Connectivity->Driver Definitions
������ Big SQL Driver��������ʾ��

ͼ 5. Ϊ Eclipse �������� Big
SQL Driver
֮���� BigInsights Eclipse ���������У��� Database
Development Perspective���� Data Source Explorer ��ͼ�У�ѡ��
Database Connections ѡ�����Ҽ����� Big SQL JDBC ���ݿ����Ӹ�Ҫ������ͼ��ʾ��
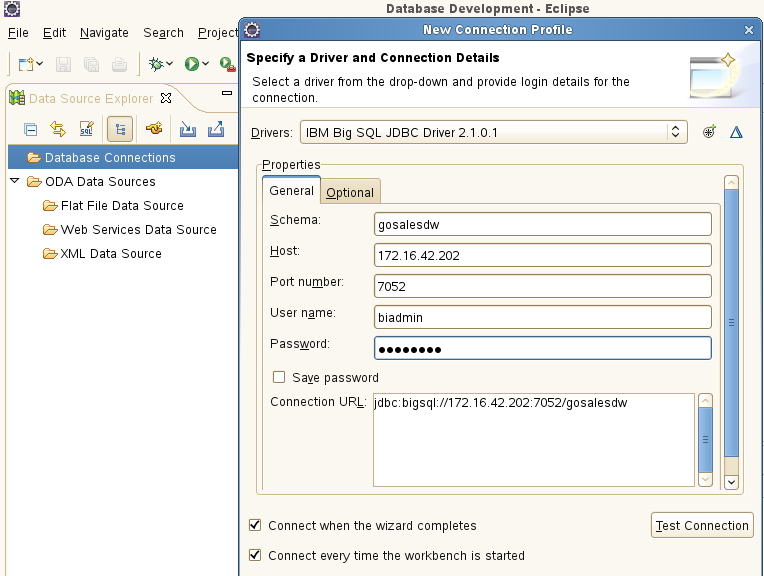
ͼ 6. Ϊ Eclipse ���ߴ��� Big
SQL JDBC ���ݿ����Ӹ�Ҫ
֮�����ǿ���ͨ������ BigInsights Project �Լ�����
SQL Script ������������ GOSALESDW_Counts.sql ��䣬������ʾ��
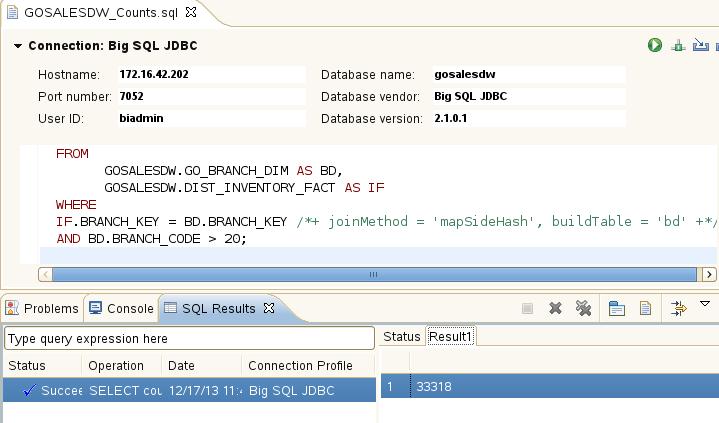
ͼ 7. ʹ�� Eclipse ��������
Big SQL ��ѯ
ʹ�� Db Visualizer �� JDBC/ODBC ���߷��� Big
SQL
Big SQL �ṩ���� JDBC/ODBC ����������������֧�ֱ�
JDBC/ODBC �Ĺ��߷��� BigInsights Hadoop �����ݣ���Ҳ�� Big SQL ���
Hive �ȴ����ݲ�ѯ���Ե�����֮һ�������Գ����� Db Visualizer ����Ϊ�������ȣ�����ͨ��ѡ��
Tools �˵��µ� Driver Manager �˵������� Big SQL Driver��������ʾ��

ͼ 8. Ϊ Db Visualizer
���� Big SQL Driver
֮���� Database ��ǩ�£�ѡ�� Connections ѡ�����Ҽ�����
BigSQL ���ݿ����ӣ�������ʾ���������ݿ⣬��ѡ�� File �˵��µ� New SQL Commander
�˵����������� Big SQL ��ѯ��
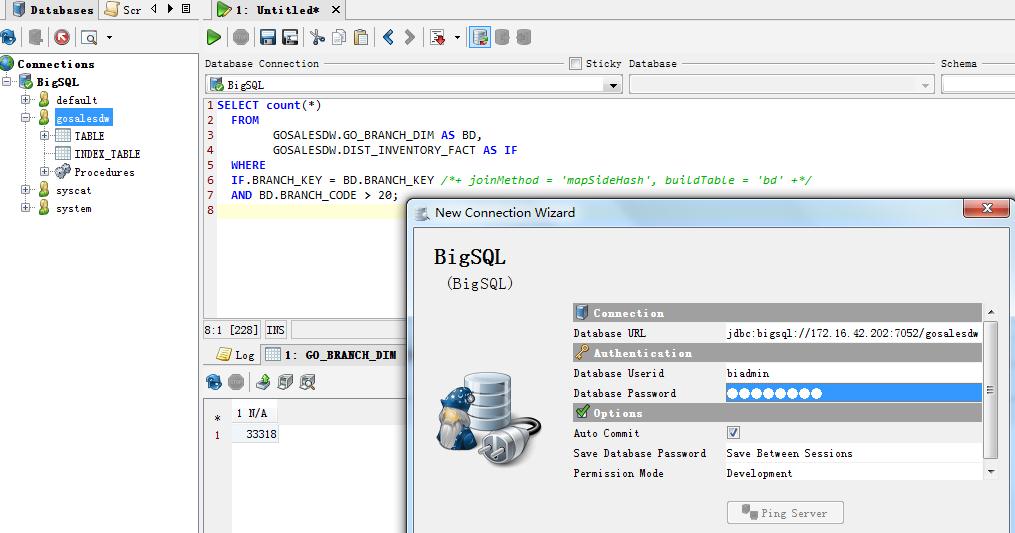
ͼ 9. ʹ�� Db Visualizer
���� Big SQL ��ѯ
ʹ�� JDBC/ODBC ������� Big SQL
���ǿ���ʹ�� JDBC/ODBC ���������� Big SQL�������� JDBC
����Ϊ������ϸ������ʹ�� JDBC ���� Big SQL �ľ��巽����
���ȣ�������Ҫ�� CLASSPATH �������������� bigsql-jdbc-driver.jar �ļ���������ʾ��
�嵥 8. ���� CLASSPATH ��������
biadmin@imtebi1:/opt/ibm/biginsights/bigsql/samples/queries>
export CLASSPATH=$CLASSPATH:/opt/ibm/biginsights/bigsql/samples/queries/bigsql-jdbc-driver.jar |
������ countbrand.java ����������ʾ��
�嵥 9. countbrand.java ����
countbrand.java
import java.io.*;
import java.sql.*;
import java.util.*;
class countbrand {
public static void main(String args[]) throws SQLException,Exception {
try {
//load the driver class
Class.forName("com.ibm.biginsights.bigsql.jdbc.BigSQLDriver");
} catch (ClassNotFoundException e) {
System.out.print(e); }
try {
//set connection properties
String user="biadmin";
String password="password";
Connection con = DriverManager.getConnection("jdbc:bigsql://172.16.42.202:7052/gosalesdw",
user,password);
Statement st = con.createStatement();
//query execution
ResultSet rs = st.executeQuery("SELECT count(*) FROM GOSALESDW.GO_BRANCH_DIM AS BD,
GOSALESDW.DIST_INVENTORY_FACT AS IF WHERE IF.BRANCH_KEY
= BD.BRANCH_KEY /*+ joinMethod = 'mapSideHash',
buildTable = 'bd' +*/ AND BD.BRANCH_CODE > 20");
while(rs.next()) {
System.out.println(rs.getString(1));
}
} catch(SQLException sqle)
{ System.out.print(sqle); }
}
} |
���ǿ���ʹ������������벢���� countbrand.java ����������ʾ��
�嵥 10. ���벢���� countbrand.java ����
biadmin@imtebi1:/opt/ibm/biginsights/bigsql/samples/queries> javac countbrand.java
biadmin@imtebi1:/opt/ibm/biginsights/bigsql/samples/queries> java countbrand
33318 |
���������ر�
ͬ��ϵ���ݿ�һ����Big SQL Ҳ����ģʽ��ģʽ��ָһ�����ļ��ϣ����ǿ���ͨ��������ͬ��ģʽ����֯
Big SQL �е����ݶ���������ʾ�����Ǵ��� gosalesdw ģʽ����֯������Ҫ������ Hive
�� HBase ����
�嵥 11. ���� gosalesdw ģʽ
biadmin@imtebi1:/opt/> $BIGSQL_HOME/bin/jsqsh -U biadmin -P password
JSqsh Release 1.5-ibm, Copyright (C) 2007-2013, Scott C. Gray
Type \help for available help topics. Using JLine.
[localhost][biadmin] 1> create schema if not exists gosalesdw;
0 rows affected (total: 1m4.56s)
[localhost][biadmin] 1> quit;
biadmin@imtebi1:/opt/$HADOOP_HOME/bin/hadoop fs -ls /biginsights/hive/warehouse
drwxr-xr-x - biadmin biadmgrp
0 2013-12-21 21:20 /biginsights/hive/warehouse/gosalesdw.db |
�� Big SQL �У����Ǵ�����ģʽ���� DFS �ֲ�ʽ�ļ�ϵͳ�д���һ����Ӧ��Ŀ¼����Ŀ¼�����ڴ���ģʽʱָ�������û��ָ��Ŀ¼������
Hive ��Ĭ��Ŀ¼ /biginsights/hive/warehouse/ �´��������ǿ���ͨ����
$HIVE_HOME/conf/hive-site.xml �ļ��е� hive.metastore.warehouse.dir
����ֵ���� Hive ��Ĭ�ϴ洢·����������ʾ��
�嵥 12. �� hive-site.xml
biadmin@imtebi1:/opt/> $BIGSQL_HOME/bin/jsqsh -U biadmin -P password
JSqsh Release 1.5-ibm, Copyright (C) 2007-2013, Scott C. Gray
Type \help for available help topics. Using JLine.
[localhost][biadmin] 1> create schema if not exists gosalesdw1 location
'/usr/biadmin/gosalesdw1.db';
0 rows affected (total: 0.87s)
[localhost][biadmin] 1> quit
biadmin@imtebi1:/opt/> $HADOOP_HOME/bin/hadoop fs -ls /usr/biadmin
Found 1 items
drwxr-xr-x - biadmin supergroup 0 2013-12-21 21:26 /usr/biadmin/gosalesdw1.db
more $HIVE_HOME/conf/hive-site.xml
hive.metastore.warehouse.dir
/biginsights/hive/warehouse |
ͬ�������Ǵ�����ÿһ�ű���Ҳ���� DFS �ֲ�ʽ�ļ�ϵͳ��Ӧ��ģʽĿ¼�´���һ����Ŀ¼�������װ�����ݣ�����ڸ���Ŀ¼�´���һ�����������ļ���������ʾ��
�嵥 13. DFS �ļ�ϵͳĿ¼
biadmin@imtebi1:/opt/ibm/biginsights> $HADOOP_HOME/bin/hadoop fs -ls /biginsights/hive/warehouse/gosalesdw.db
drwxr-xr-x - biadmin supergroup
0 2013-12-13 23:45 /biginsights/hive/warehouse/gosalesdw.db/sls_order_method_dim
drwxr-xr-x - biadmin supergroup
0 2013-12-13 23:46 /biginsights/hive/warehouse/gosalesdw.db/sls_product_dim
drwxr-xr-x - biadmin supergroup
0 2013-12-13 23:47 /biginsights/hive/warehouse/gosalesdw.db/sls_sales_fact
biadmin@imtebi1:/opt/ibm/biginsights>
$HADOOP_HOME/bin/hadoop fs -ls /biginsights/hive/warehouse/gosalesdw.db/sls_sales_fact
Found 1 items
-rw-r--r-- 1 biadmin supergroup 51258157 2013-12-13 23:47
/biginsights/hive/warehouse/gosalesdw.db/sls_sales_fact/GOSALESDW.SLS_SALES_FACT.txt |
Big SQL ֧�� tinyint��smallint��integer��bigint
�������ͣ�Ҳ֧�� float��double��real �������ͼ� decimal ���ͣ�string��varchar()��char()��binary��varbinary()
�ַ����͡�timestamp ʱ�������Լ� boolean �������ͣ����� tinyint �� smallint
�ǵȼ۵ģ�real �� float �ǵȼ۵ġ����⣬Big SQL Ҳ֧�� array ���鼰 struct
�ṹ�����������͡�Ŀǰ��Big SQL ��֧�ִ����� VARGRAPHIC ���͡�
Big SQL ��ֱ��ָ�������������͵ľ���洢��ʽ�������� SerDe
�����������û���ر�ָ����Big SQL ʹ�� Hive Ĭ�ϵ� LazySimpleSerDe �� LazyBinarySerDeSerDe
SerDe ���塣�ɴ˿ɼ���Big SQL ͬ Hive �������ݡ�
�� Big SQL �У���������Ҫ�漰���� Hive ���� HBase
��������ʽ���±����ǽ��������һ�����ִ�������װ�ر��ľ��巽����
���������� Hive ��
���� Hive ��
�� Big SQL �У�û���ر�ָ�����������ı�Ĭ�϶��� Hive ����������ʾ�����Ǵ�����
SLS_SALES_FACT��SLS_SALES_ORDER_DIM��SLS_ORDER_METHOD_DIM
���� Hive ����
�嵥 14. ���� Hive ��
USE GOSALESDW;
CREATE TABLE SLS_SALES_FACT ( ORDER_DAY_KEY int, ORGANIZATION_KEY int,
EMPLOYEE_KEY int, RETAILER_KEY int, RETAILER_SITE_KEY int, PRODUCT_KEY int,
PROMOTION_KEY int, ORDER_METHOD_KEY int, SALES_ORDER_KEY int, SHIP_DAY_KEY int,
CLOSE_DAY_KEY int, QUANTITY int, UNIT_COST decimal(19,2),
UNIT_PRICE decimal(19,2), UNIT_SALE_PRICE decimal(19,2), GROSS_MARGIN double,
SALE_TOTAL decimal(19,2), GROSS_PROFIT decimal(19,2) )
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
CREATE TABLE SLS_SALES_ORDER_DIM ( SALES_ORDER_KEY int,
ORDER_DETAIL_CODE int, ORDER_NUMBER int, WAREHOUSE_BRANCH_CODE int )
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
--GOSALESDW.SLS_ORDER_METHOD_DIM
CREATE TABLE SLS_ORDER_METHOD_DIM ( ORDER_METHOD_KEY int, ORDER_METHOD_CODE int,
ORDER_METHOD_EN varchar(180), ORDER_METHOD_DE varchar(180), ORDER_METHOD_FR varchar(180),
ORDER_METHOD_JA varchar(180), ORDER_METHOD_CS varchar(180), ORDER_METHOD_DA varchar(180),
ORDER_METHOD_EL varchar(180), ORDER_METHOD_ES varchar(180), ORDER_METHOD_FI varchar(180),
ORDER_METHOD_HU varchar(180), ORDER_METHOD_ID varchar(180), ORDER_METHOD_IT varchar(180),
ORDER_METHOD_KO varchar(180), ORDER_METHOD_MS varchar(180), ORDER_METHOD_NL varchar(180),
ORDER_METHOD_NO varchar(180), ORDER_METHOD_PL varchar(180), ORDER_METHOD_PT varchar(180),
ORDER_METHOD_RU varchar(180), ORDER_METHOD_SC varchar(180), ORDER_METHOD_SV varchar(180),
ORDER_METHOD_TC varchar(180), ORDER_METHOD_TH varchar(180) )
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; |
��������� /biginsights/hive/warehouse/gosalesdw.db
Ŀ¼�´��� sls_sales_fact��sls_sales_order_dim��sls_order_method_dim
����Ŀ¼��
���ǻ��������� DFS �ļ�ϵͳ���Ѿ����ڵ������ļ��������ⲿ Hive
�������������Ѿ����ڵ����ݣ��������� Hive MetaStore ��������Ӧ��Ԫ���ݶ�����Ϣ����ɾ���ñ���Ҳ���ǽ��ñ���Ԫ���ݶ�����Ϣɾ���������ļ����ֲ��䣬������ʾ��
�嵥 15. �����ⲿ Hive ��
use gosalesdw;
CREATE EXTERNAL TABLE SLS_PRODUCT_DIM_EXT ( PRODUCT_KEY int, PRODUCT_LINE_CODE int,
PRODUCT_TYPE_KEY int, PRODUCT_TYPE_CODE int, PRODUCT_NUMBER int, BASE_PRODUCT_KEY int,
BASE_PRODUCT_NUMBER int, PRODUCT_COLOR_CODE int, PRODUCT_SIZE_CODE int,
PRODUCT_BRAND_KEY int, PRODUCT_BRAND_CODE int, PRODUCT_IMAGE varchar(120),
INTRODUCTION_DATE timestamp, DISCONTINUED_DATE timestamp )
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' stored as textfile
location '/biginsights/hive/warehouse/gosalesdw.db/sls_product_dim'; |
�ڴ�����ʱ�����ǻ����Զ����Ż���ʾ��Ϣ��������ʾ�����Ǵ����� SLS_PRODUCT_DIM_1
������ָ���ñ����Ż���ʾΪ tablesize='small'����ʾ�ñ���һ��С�����������Ըñ��IJ������ܾͻ��ڱ������У�����
Map Reduce ���еĿ������������������Ӳ���ʱ�����ܻ���� mapSideHash ���ʷ�ʽ��
�嵥 16. �����Ż���ʾ��Ϣ
use gosalesdw;
CREATE TABLE SLS_PRODUCT_DIM_1( PRODUCT_KEY int, PRODUCT_LINE_CODE int,
PRODUCT_TYPE_KEY int, PRODUCT_TYPE_CODE int, PRODUCT_NUMBER int,
BASE_PRODUCT_KEY int, BASE_PRODUCT_NUMBER int, PRODUCT_COLOR_CODE int,
PRODUCT_SIZE_CODE int, PRODUCT_BRAND_KEY int, PRODUCT_BRAND_CODE int,
PRODUCT_IMAGE varchar(120), INTRODUCTION_DATE timestamp,
DISCONTINUED_DATE timestamp ) ROW FORMAT DELIMITED FIELDS TERMINATED
BY '\t' stored as textfile with hints (tablesize='small') ; |
Ϊ�˽�һ����߲�ѯ��Ч�ʣ����ǻ����Դ��������������÷�������һ���棬���ǿ���ͨ������
partition elimination �������Ե�����Ҫ�ķ������������ݵĴ���������߲�ѯЧ�ʣ���һ���棬���Զ�ÿһ���������й�������ɾ���ɵķ�������߹���������ԡ�ͬʱ�����ñ������ķ�ʽ��Ҳ�ᵼ�����ɹ�����ļ���HCatalog
Ҫ���������ķ�����Ϣ��������ʾ�����Ǵ����� SLS_PRODUCT_DIM_PART ��������
�嵥 17. ����������
use gosalesdw;
CREATE TABLE SLS_PRODUCT_DIM_PART( PRODUCT_KEY int, PRODUCT_TYPE_KEY int,
PRODUCT_TYPE_CODE int, PRODUCT_NUMBER int, BASE_PRODUCT_KEY int,
BASE_PRODUCT_NUMBER int, PRODUCT_COLOR_CODE int, PRODUCT_SIZE_CODE int,
PRODUCT_BRAND_KEY int, PRODUCT_BRAND_CODE int, PRODUCT_IMAGE varchar(120),
INTRODUCTION_DATE timestamp, DISCONTINUED_DATE timestamp )PARTITIONED
BY (PRODUCT_LINE_CODE int) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
biadmin@imtebi1:/opt/ibm/biginsights/bin>
hadoop fs -ls /biginsights/hive/warehouse/gosalesdw.db
Found 70 items
drwxr-xr-x - biadmin biadmgrp
0 2013-12-15 07:47 /biginsights/hive/warehouse/gosalesdw.db/sls_product_dim_part |
|






