一、概述
本文将粗略讲述一下Hash算法的概念特性,里边会结合分布式系统负载均衡实例对Hash的一致性做深入探讨。另外,探讨一下Hash算法在海量数据处理方案中的通用性。最后,从源代码出发,具体分析一下Hash算法在MapReduce框架的中的应用。
二、Hash算法
Hash可以通过散列函数将任意长度的输入变成固定长度的输出,也可以将不同的输入映射成为相同的相同的输出,而且这些输出范围也是可控制的,所以起到了很好的压缩映射和等价映射功能。这些特性被应用到了信息安全领域中加密算法,其中等价映射这一特性在海量数据解决方案中起到相当大的作用,特别是在整个MapReduce框架中,下面章节会对这二方面详细说。话说,Hash为什么会有这种压缩映射和等价映射功能,主要是因为Hash函数在实现上都使用到了取模。下面看看几种常用的Hash函数:
・直接取余法:f(x):= x mod maxM ; maxM一般是不太接近
2^t 的一个质数。
・乘法取整法:f(x):=trunc((x/maxX)*maxlongit)
mod maxM,主要用于实数。
・平方取中法:f(x):=(x*x div 1000 ) mod 1000000);
平方后取中间的,每位包含信息比较多。
三、Hash算法在海量数据处理方案中的应用
单机处理海量数据的大体主流思想是和MapReduce框架一样,都是采取分而治之的方法,将海量数据切分为若干小份来进行处理,并且在处理的过程中要兼顾内存的使用情况和处理并发量情况。而更加仔细的处理流程大体上分为几步(对大多数情况都使用,其中少部分情况要根据你自己的实际情况和其他解决方法做比较采用最符合实际的方法):
第一步:分而治之。
采用Hash取模进行等价映射。采用这种方法可以将巨大的文件进行等价分割(注意:符合一定规律的数据要被分割到同一个小文件)变成若干个小文件再进行处理。这个方法针对数据量巨大,内存受到限制时十分有效。
第二步:利用hashMap在内存中进行统计。
我们通过Hash映射将大文件分割为小文件后,就可以采用HashMap这样的存储结构来对小文件中的关注项进行频率统计。具体的做法是将要进行统计的Item作为HashMap的key,此Item出现的次数作为value。
第三步:在上一步进行统计完毕之后根据场景需求往往需要对存储在HashMap中的数据根据出现的次数来进行排序。其中排序我们可以采用堆排序、快速排序、归并排序等方法。
现在我们来看看具体的例子:
【例子1】海量日志数据,提取出某日访问百度次数最多的那个IP
思路:当看到这样的业务场景,我们脑子里应该立马会想到这些海量网关日志数据量有多大?这些IP有多少中组合情况,最大情况下占多少存储空间?解决这样的问题前我们最重要的先要知道数据的规模,这样才能从大体上制定解决方案。所以现在假设这些这些网关日志量有3T。下面大体按照我们上面的步骤来对解决此场景进行分析:
(1)首先,从这些海量数据中过滤出指定一天访问百度的用户IP,并逐个写到一个大文件中。
(2)采用“分而治之”的思想用Hash映射将大文件进行分割降低数据规模。按照IP地址的Hash(IP)%1024值,把海量IP日志分别存储到1024个小文件中,其中Hash函数得出值为分割后小文件的编号。
(3)逐个读小文件,对于每一个小文件构建一个IP为key,出现次数为value的HashMap。对于怎么利用HashMap记录IP出现的次数这个比较简单,因为我们可以通过程序读小文件将IP放到HashMap中key的之后可以先判断此IP是否已经存在如果不存在直接放进去,其出现次数记录为1,如果此IP已经存储则过得其对应的value值也就是出现的次数然后加1就ok。最后,按照IP出现的次数采用排序算法对HashMap中的数据进行排序,同时记录当前出现次数最多的那个IP地址;
(4)走到这步,我们可以得到1024个小文件中出现次数最多的IP了,再采用常规的排序算法找出总体上出现次数最多的IP就ok了。
这个我们需要特别地明确知道一下几点内容:
第一:我们通过Hash函数:Hash(IP)%1024将大文件映射分割为了1024个小文件,那么这1024个小文件的大小是否均匀?另外,我们采用HashMap来进行IP频率的统计,内存消耗是否合适?
首先是第一个问题,被分割的小文件的大小的均匀程度是取决于我们使用怎么样的Hash函数,对本场景而言就是:Hash(IP)%1024。设计良好的Hash函数可以减少冲突,使数据均匀的分割到1024个小文件中。但是尽管数据映射到了另外一些不同的位置,但数据还是原来的数据,只是代替和表示这些原始数据的形式发生了变化而已。
另外,看看第二个问题:用HashMap统计IP出现频率的内存使用情况。
要想知道HashMap在统计IP出现的频率,那么我们必须对IP组合的情况有所了解。32Bit的IP最多可以有2^32种的组合方式,也就是说去所有IP最多占4G存储空间。在此场景中,我们已经根据IP的hash值将大文件分割出了1024个小文件,也就是说这4G的IP已经被分散到了1024个文件中。那么在Hash函数设计合理最perfect的情况下针对每个小文件的HashMap占的内存大小最多为4G/1024+存储IP对应的次数所占的空间,所以内存绝对够用。
第二:Hash取模是一种等价映射,换句话说通过映射分割之后相同的元素只会分到同一个小文件中去的。就本场景而言,相同的IP通过Hash函数后只会被分割到这1024个小文件中的其中一个文件。
【例子2】给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
思路:还是老一套,先Hash映射降低数据规模,然后统计排序。
具体做法:
(1)分析现有数据的规模。
按照每个url64字节来算,每个文件有50亿个url,那么每个文件大小为5G*64=320G。320G远远超出内存限定的4G,所以不能将其全部加载到内存中来进行处理,需要采用分而治之的方法进行处理。
(2)Hash映射分割文件。逐行读取文件a,采用hash函数:Hash(url)%1000将url分割到1000个小文件中,文件即为f1_1,f1_2,f1_3,...,f1_1000。那么理想情况下每个小文件的大小大约为300m左右。再以相同的方法对大文件b进行相同的操作再得到1000个小文件,记为:f2_1,f2_2,f2_3,...,f2_1000。
经过一番折腾后我们将大文件进行了分割并且将相同url都分割到了这2组小文件中下标相同的两个文件中,其实我们可以将这2组文件看成一个整体:f1_1&f2_1,f1_2&,f2_2,f1_3&f2_3,...,f1_1000&f2_1000。那么我们就可以将问题转化成为求这1000对小文件中相同的url就可以了。接下来,求每对小文件中的相同url,首先将每对对小文件中较小的那个的url放到HashSet结构中,然后遍历对应这对小文件中的另一个文件,看其是否存才刚刚构建的HashSet中,如果存在说明是一样的url,将这url直接存到结果文件就ok了。
【例子3】有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。要求你按照query的频度排序。
【例子4】有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
像例子3和例子4这些场景都可以用我们的一贯老招数解决:先Hash映射降低数据规模,然后统计加载到内存,最后排序。具体做法可以参考上面2个例子。
四、Hash算法在MapReduce框架中的应用
Hash算法在分布式计算框架MapReduce中起着核心作用。先来看看下面整个mapreduce的运行流程,首先是原始数据经过切片进入到map函数中,经过map函数的数据会在整个环形缓冲区里边进行第一次排序,接着map的输出结果会根据key值(默认情况是这样,另外可以自定义)进行Hash映射将数据量庞大的map输出分割为N份(N为reduce数目)来实现数据的并行处理,这就是Partition阶段,另外MapReduce框架中Partition的实现方式往往能够决定数据的倾斜度,所以在处理数据前最好要对数据的分布情况有所了解。
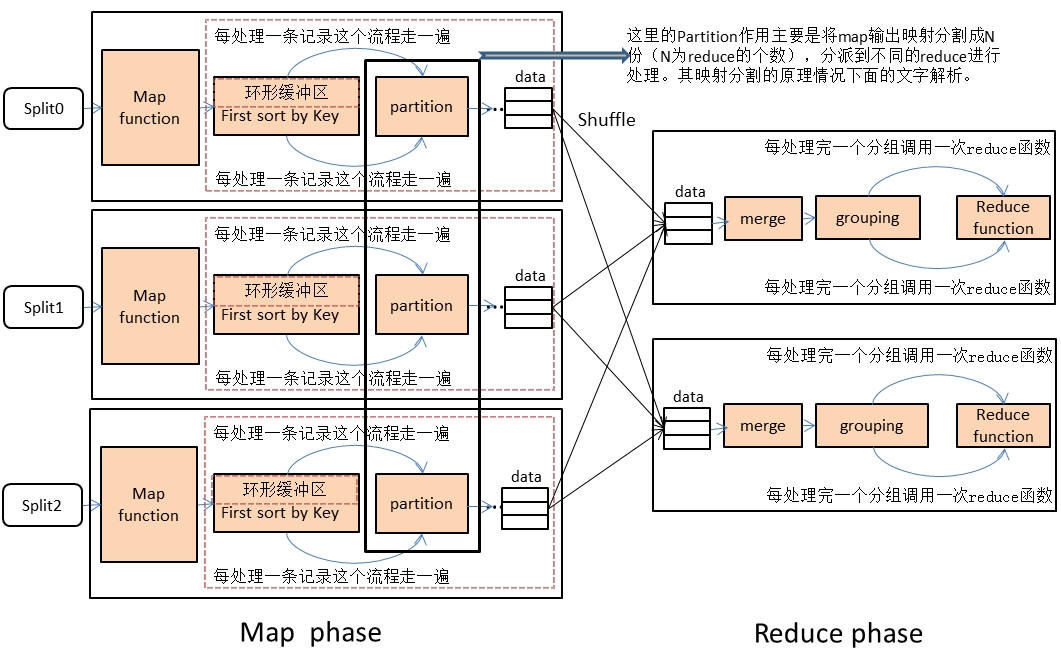
接下来从MapReudce的源码角度来研究一下Partition的实现原理:
其Partition的实现主要有:HashPartitioner、BinaryPartitioner、KeyFieldBasedPartitioner、TotalOrderPartitioner这几种,其中HashPartitioner是默认的。首先来看看HashPartitioner的核心实现:
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.mapreduce.lib.partition;
import org.apache.hadoop.mapreduce.Partitioner;
/** Partition keys by their {@link Object#hashCode()}. */
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
} |
我们看到第25行,在这里我们有看到了可爱的Hash取模映射方法,这样做的原因大家看到这里都应该已经了然于心了。另外,TotalOrderPartitioner、BinaryPartitioner等几种Partitioner的实现都是基于Hash取模映射方法,只是他们为了实现自己自定义的功能而添加了一些逻辑,例如其中的TotalOrderPartitioner可以实现全排序功能。其他几个Partition的源代码这里就不贴了,有兴趣的可以自己看看。
五、Hash算法的一致性
本部分为本文最后一部分,之所以要介绍这一部分的内容主要是从Hash算法的完整性出发的,这部分的内容和海量数据的解决方案关系不大,主要是用于分布式缓存设计方面。由于关于这部分的内容已经有一些大拿们做了很深入的研究并且讲解地相当完美,小弟这里就直接引用了。所以本部分引用sparkliang的blog。
consistent hashing算法早在1997年就在论文Consistent hashing and
random trees中被提出,目前在cache系统中应用越来越广泛;
1 基本场景
比如你有N个cache服务器(后面简称cache),那么如何将一个对象object映射到N个cache上呢,你很可能会采用类似下面的通用方法计算object的hash值,然后均匀的映射到到N个cache;hash(object)%N
一切都运行正常,再考虑如下的两种情况;
1 一个cache服务器m down掉了(在实际应用中必须要考虑这种情况),这样所有映射到cache
m的对象都会失效,怎么办,需要把cache m从cache中移除,这时候cache是N-1台,映射公式变成了hash(object)%(N-1);
2 由于访问加重,需要添加cache,这时候cache是N+1台,映射公式变成了hash(object)%(N+1);
1和2意味着什么?这意味着突然之间几乎所有的cache都失效了。对于服务器而言,这是一场灾难,洪水般的访问都会直接冲向后台服务器;
再来考虑第三个问题,由于硬件能力越来越强,你可能想让后面添加的节点多做点活,显然上面的hash算法也做不到。
有什么方法可以改变这个状况呢,这就是consistent hashing...
2 hash 算法和单调性
Hash算法的一个衡量指标是单调性(Monotonicity),定义如下:
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
容易看到,上面的简单hash算法hash(object)%N难以满足单调性要求。
3 consistent hashing 算法的原理
consistent hashing是一种hash算法,简单的说,在移除/添加一个cache时,它能够尽可能小的改变已存在key映射关系,尽可能的满足单调性的要求。
下面就来按照5个步骤简单讲讲consistent hashing算法的基本原理。
3.1 环形hash 空间
考虑通常的hash算法都是将value映射到一个32为的key值,也即是0~2^32-1次方的数值空间;我们可以将这个空间想象成一个首(0)尾(2^32-1)相接的圆环,如下面图1所示的那样。
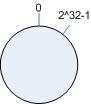
图1环形hash空间
3.2 把对象映射到hash 空间
接下来考虑4个对象object1~object4,通过hash函数计算出的hash值key在环上的分布如图2所示。
hash(object1) = key1;
… …
hash(object4) = key4; |
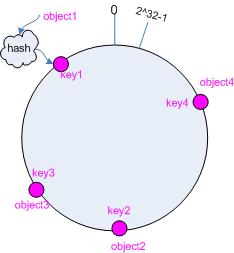
图2 4个对象的key值分布
3.3 把cache 映射到hash 空间
Consistent hashing的基本思想就是将对象和cache都映射到同一个hash数值空间中,并且使用相同的hash算法。
假设当前有A,B和C共3台cache,那么其映射结果将如图3所示,他们在hash空间中,以对应的hash值排列。
hash(cache A) = key A;
… …
hash(cache C) = key C; |
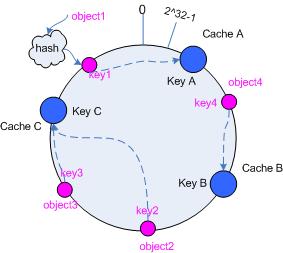
图3 cache和对象的key值分布
说到这里,顺便提一下cache的hash计算,一般的方法可以使用cache机器的IP地址或者机器名作为hash输入。
3.4 把对象映射到cache
现在cache和对象都已经通过同一个hash算法映射到hash数值空间中了,接下来要考虑的就是如何将对象映射到cache上面了。
在这个环形空间中,如果沿着顺时针方向从对象的key值出发,直到遇见一个cache,那么就将该对象存储在这个cache上,因为对象和cache的hash值是固定的,因此这个cache必然是唯一和确定的。这样不就找到了对象和cache的映射方法了吗?!
依然继续上面的例子(参见图3),那么根据上面的方法,对象object1将被存储到cache A上;object2和object3对应到cache
C;object4对应到cache B;
3.5 考察cache 的变动
前面讲过,通过hash然后求余的方法带来的最大问题就在于不能满足单调性,当cache有所变动时,cache会失效,进而对后台服务器造成巨大的冲击,现在就来分析分析consistent
hashing算法。
3.5.1 移除cache
考虑假设cache B挂掉了,根据上面讲到的映射方法,这时受影响的将仅是那些沿cache B逆时针遍历直到下一个cache(cache
C)之间的对象,也即是本来映射到cache B上的那些对象。
因此这里仅需要变动对象object4,将其重新映射到cache C上即可;参见图4。
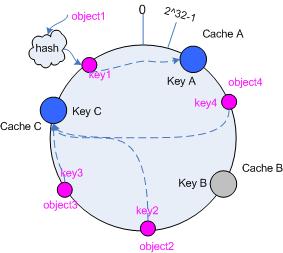
图4 Cache B被移除后的cache映射
3.5.2 添加cache
再考虑添加一台新的cache D的情况,假设在这个环形hash空间中,cache D被映射在对象object2和object3之间。这时受影响的将仅是那些沿cache
D逆时针遍历直到下一个cache(cache B)之间的对象(它们是也本来映射到cache C上对象的一部分),将这些对象重新映射到cache
D上即可。
因此这里仅需要变动对象object2,将其重新映射到cache D上;参见图5。
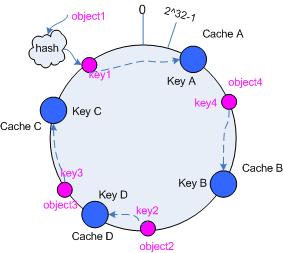
图5 添加cache D后的映射关系
4 虚拟节点
考量Hash算法的另一个指标是平衡性(Balance),定义如下:
平衡性
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。
hash算法并不是保证绝对的平衡,如果cache较少的话,对象并不能被均匀的映射到cache上,比如在上面的例子中,仅部署cache
A和cache C的情况下,在4个对象中,cache A仅存储了object1,而cache C则存储了object2、object3和object4;分布是很不均衡的。
为了解决这种情况,consistent hashing引入了“虚拟节点”的概念,它可以如下定义:
“虚拟节点”(virtual node)是实际节点在hash空间的复制品(replica),一实际个节点对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在hash空间中以hash值排列。
仍以仅部署cache A和cache C的情况为例,在图4中我们已经看到,cache分布并不均匀。现在我们引入虚拟节点,并设置“复制个数”为2,这就意味着一共会存在4个“虚拟节点”,cache
A1, cache A2代表了cache A;cache C1, cache C2代表了cache C;假设一种比较理想的情况,参见图6。
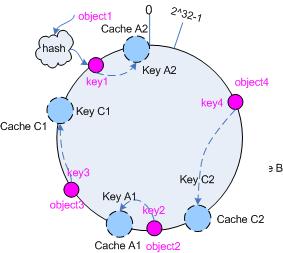
图6 引入“虚拟节点”后的映射关系
此时,对象到“虚拟节点”的映射关系为:
objec1->cache A2;objec2->cache A1;objec3->cache C1;objec4->cache C2; |
因此对象object1和object2都被映射到了cache A上,而object3和object4映射到了cache
C上;平衡性有了很大提高。
引入“虚拟节点”后,映射关系就从{对象->节点}转换到了{对象->虚拟节点}。查询物体所在cache时的映射关系如图7所示。
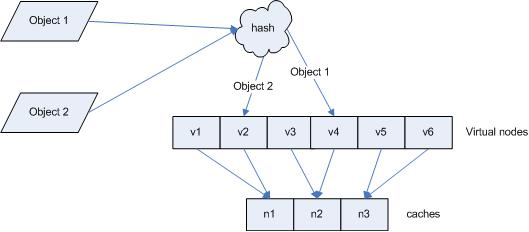
图7 查询对象所在cache
“虚拟节点”的hash计算可以采用对应节点的IP地址加数字后缀的方式。例如假设cache A的IP地址为202.168.14.241。
引入“虚拟节点”前,计算cache A的hash值:
引入“虚拟节点”后,计算“虚拟节”点cache A1和cache A2的hash值:
Hash(“202.168.14.241#1”); // cache A1
Hash(“202.168.14.241#2”); // cache A2 |
|






