Spark是一个由加州大学伯克利分校(UC
Berkeley AMP)开发的一个分布式数据快速分析项目。它的核心技术是弹性分布式数据集(Resilient
distributed datasets),提供了比Hadoop更加丰富的MapReduce模型,可以快速在内存中对数据集进行多次迭代,来支持复杂的数据挖掘算法和图计算算法。
Spark使用Scala开发,使用Mesos作为底层的调度框架,可以和hadoop和Ec2紧密集成,直接读取hdfs或S3的文件进行计算并把结果写回hdfs或S3,是Hadoop和Amazon云计算生态圈的一部分。Spark是一个小巧玲珑的项目,项目的core部分的代码只有63个Scala文件,充分体现了精简之美。
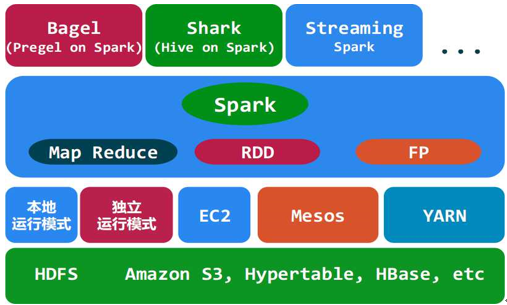
park之依赖
1.map Reduce模型:作为一个分布式计算框架,Spark采用了MapReduce模型。在它身上,Google的Map
Reduce和Hadoop的痕迹很重,很明显,它并非一个大的创新,而是微创新。在基础理念不变的前提下,它借鉴,模仿并依赖了先辈,加入了一点改进,极大的提升了MapReduce的效率。
函数式编程:Spark由Scala写就,而支持的语言亦是Scala。其原因之一就是Scala支持函数式编程。这一来造就了Spark的代码简洁,二来使得基于Spark开发的程序,也特别的简洁。一次完整的MapReduce,Hadoop中需要创建一个Mapper类和Reduce类,而Spark只需要创建相应的一个map
2.数和reduce函数即可,代码量大大降低。
3.Mesos:Spark将分布式运行的需要考虑的事情,都交给了Mesos,自己不Care,这也是它代码能够精简的原因之一。
4.HDFS和S3:Spark支持2种分布式存储系统:HDFS和S3。应该算是目前最主流的两种了。对文件系统的读取和写入功能是Spark自己提供的,借助Mesos分布式实现。
Spark与Hadoop的对比
1.Spark的中间数据放到内存中,对于迭代运算效率更高。Spark更适合于迭代运算比较多的ML和DM运算。因为在Spark里面,有RDD的抽象概念。
2.Spark比Hadoop更通用。
Spark提供的数据集操作类型有很多种,不像Hadoop只提供了Map和Reduce两种操作。比如map,filter,flatMap,sample,groupByKey,reduceByKey,union,join,cogroup,mapValues,sort,partionBy等多种操作类型,Spark把这些操作称为Transformations。同时还提供Count,collect,reduce,lookup,save等多种actions操作。
这些多种多样的数据集操作类型,给给开发上层应用的用户提供了方便。各个处理节点之间的通信模型不再像Hadoop那样就是唯一的Data
Shuffle一种模式。用户可以命名,物化,控制中间结果的存储、分区等。可以说编程模型比Hadoop更灵活。
不过由于RDD的特性,Spark不适用那种异步细粒度更新状态的应用,例如web服务的存储或者是增量的web爬虫和索引。就是对于那种增量修改的应用模型不适合。
3.容错性。在分布式数据集计算时通过checkpoint来实现容错,而checkpoint有两种方式,一个是checkpoint
data,一个是logging the updates。用户可以控制采用哪种方式来实现容错。
4.可用性。Spark通过提供丰富的Scala, Java,Python
API及交互式Shell来提高可用性。
park与Hadoop的结合
Spark可以直接对HDFS进行数据的读写,同样支持Spark on YARN。Spark可以与MapReduce运行于同集群中,共享存储资源与计算,数据仓库Shark实现上借用Hive,几乎与Hive完全兼容。
Spark的核心概念
1、Resilient Distributed Dataset (RDD)弹性分布数据集
RDD是Spark的最基本抽象,是对分布式内存的抽象使用,实现了以操作本地集合的方式来操作分布式数据集的抽象实现。RDD是Spark最核心的东西,它表示已被分区,不可变的并能够被并行操作的数据集合,不同的数据集格式对应不同的RDD实现。RDD必须是可序列化的。RDD可以cache到内存中,每次对RDD数据集的操作之后的结果,都可以存放到内存中,下一个操作可以直接从内存中输入,省去了MapReduce大量的磁盘IO操作。这对于迭代运算比较常见的机器学习算法,
交互式数据挖掘来说,效率提升比较大。
RDD的特点:
1.它是在集群节点上的不可变的、已分区的集合对象。
2.通过并行转换的方式来创建如(map, filter, join, etc)。
3.失败自动重建。
4.可以控制存储级别(内存、磁盘等)来进行重用。
5.必须是可序列化的。
6.是静态类型的。
RDD的好处:
1.RDD只能从持久存储或通过Transformations操作产生,相比于分布式共享内存(DSM)可以更高效实现容错,对于丢失部分数据分区只需根据它的lineage就可重新计算出来,而不需要做特定的Checkpoint。
2.RDD的不变性,可以实现类Hadoop MapReduce的推测式执行。
3.RDD的数据分区特性,可以通过数据的本地性来提高性能,这与Hadoop
MapReduce是一样的。
4.RDD都是可序列化的,在内存不足时可自动降级为磁盘存储,把RDD存储于磁盘上,这时性能会有大的下降但不会差于现在的MapReduce。
RDD的存储与分区:
用户可以选择不同的存储级别存储RDD以便重用。
当前RDD默认是存储于内存,但当内存不足时,RDD会spill到disk。
RDD在需要进行分区把数据分布于集群中时会根据每条记录Key进行分区(如Hash
分区),以此保证两个数据集在Join时能高效。
RDD的内部表示:
分区列表(数据块列表)
计算每个分片的函数(根据父RDD计算出此RDD)
对父RDD的依赖列表
对key-value RDD的Partitioner【可选】
每个数据分片的预定义地址列表(如HDFS上的数据块的地址)【可选】
RDD的存储级别:RDD根据useDisk、useMemory、deserialized、replication四个参数的组合提供了11种存储级别。RDD定义了各种操作,不同类型的数据由不同的RDD类抽象表示,不同的操作也由RDD进行抽实现。
RDD有两种创建方式:
从Hadoop文件系统(或与Hadoop兼容的其它存储系统)输入(例如HDFS)创建。
从父RDD转换得到新RDD。
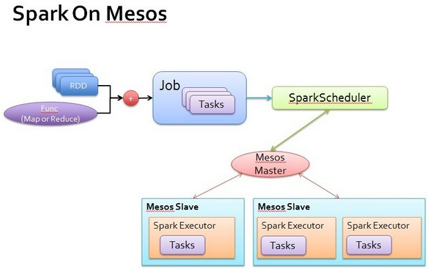
2、Spark On Mesos
Spark支持Local调用和Mesos集群两种模式,在Spark上开发算法程序,可以在本地模式调试成功后,直接改用Mesos集群运行,除了文件的保存位置需要考虑以外,算法理论上不需要做任何修改。Spark的本地模式支持多线程,有一定的单机并发处理能力。但是不算很强劲。本地模式可以保存结果在本地或者分布式文件系统,而Mesos模式一定需要保存在分布式或者共享文件系统。
为了在Mesos框架上运行,安装Mesos的规范和设计,Spark实现两个类,一个是SparkScheduler,在Spark中类名是MesosScheduler;一个是SparkExecutor,在Spark中类名是Executor。有了这两个类,Spark就可以通过Mesos进行分布式的计算。Spark会将RDD和MapReduce函数,进行一次转换,变成标准的Job和一系列的Task。提交给SparkScheduler,SparkScheduler会把Task提交给Mesos
Master,由Master分配给不同的Slave,最终由Slave中的Spark Executor,将分配到的Task一一执行,并且返回,组成新的RDD,或者直接写入到分布式文件系统。
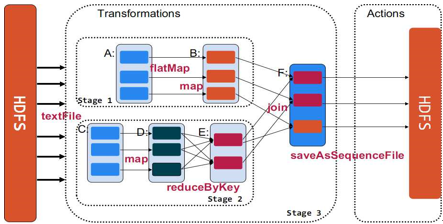
3、Transformations & Actions
对于RDD可以有两种计算方式:转换(返回值还是一个RDD)与操作(返回值不是一个RDD)。
转换(Transformations) (如:map, filter,
groupBy, join等),Transformations操作是Lazy的,也就是说从一个RDD转换生成另一个RDD的操作不是马上执行,Spark在遇到Transformations操作时只会记录需要这样的操作,并不会去执行,需要等到有Actions操作的时候才会真正启动计算过程进行计算。
操作(Actions) (如:count, collect, save等),Actions操作会返回结果或把RDD数据写到存储系统中。Actions是触发Spark启动计算的动因。
它们本质区别是:Transformation返回值还是一个RDD。它使用了链式调用的设计模式,对一个RDD进行计算后,变换成另外一个RDD,然后这个RDD又可以进行另外一次转换。这个过程是分布式的。Action返回值不是一个RDD。它要么是一个Scala的普通集合,要么是一个值,要么是空,最终或返回到Driver程序,或把RDD写入到文件系统中。关于这两个动作,在Spark开发指南中会有就进一步的详细介绍,它们是基于Spark开发的核心。这里将Spark的官方ppt中的一张图略作改造,阐明一下两种动作的区别。
4、Lineage(血统)
利用内存加快数据加载,在众多的其它的In-Memory类数据库或Cache类系统中也有实现,Spark的主要区别在于它处理分布式运算环境下的数据容错性(节点实效/数据丢失)问题时采用的方案。为了保证RDD中数据的鲁棒性,RDD数据集通过所谓的血统关系(Lineage)记住了它是如何从其它RDD中演变过来的。相比其它系统的细颗粒度的内存数据更新级别的备份或者LOG机制,RDD的Lineage记录的是粗颗粒度的特定数据转换(Transformation)操作(filter,
map, join etc.)行为。当这个RDD的部分分区数据丢失时,它可以通过Lineage获取足够的信息来重新运算和恢复丢失的数据分区。这种粗颗粒的数据模型,限制了Spark的运用场合,但同时相比细颗粒度的数据模型,也带来了性能的提升。
RDD在Lineage依赖方面分为两种Narrow Dependencies与Wide
Dependencies用来解决数据容错的高效性。
Narrow Dependencies是指父RDD的每一个分区最多被一个子RDD的分区所用,表现为一个父RDD的分区对应于一个子RDD的分区或多个父RDD的分区对应于一个子RDD的分区,也就是说一个父RDD的一个分区不可能对应一个子RDD的多个分区。
Wide Dependencies是指子RDD的分区依赖于父RDD的多个分区或所有分区,也就是说存在一个父RDD的一个分区对应一个子RDD的多个分区。对与Wide
Dependencies,这种计算的输入和输出在不同的节点上,lineage方法对与输入节点完好,而输出节点宕机时,通过重新计算,这种情况下,这种方法容错是有效的,否则无效,因为无法重试,需要向上其祖先追溯看是否可以重试(这就是lineage,血统的意思),Narrow
Dependencies对于数据的重算开销要远小于Wide Dependencies的数据重算开销。
在RDD计算,通过checkpint进行容错,做checkpoint有两种方式,一个是checkpoint
data,一个是logging the updates。用户可以控制采用哪种方式来实现容错,默认是logging
the updates方式,通过记录跟踪所有生成RDD的转换(transformations)也就是记录每个RDD的lineage(血统)来重新计算生成丢失的分区数据。
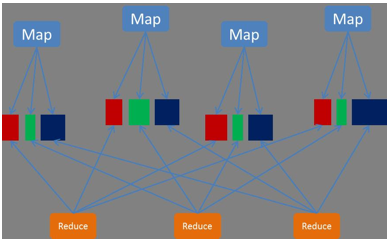
Spark的Shuffle过程介绍
1.Shuffle Writer
Spark丰富了任务类型,有些任务之间数据流转不需要通过Shuffle,但是有些任务之间还是需要通过Shuffle来传递数据,比如wide
dependency的group by key。
Spark中需要Shuffle输出的Map任务会为每个Reduce创建对应的bucket,Map产生的结果会根据设置的partitioner得到对应的bucketId,然后填充到相应的bucket中去。每个Map的输出结果可能包含所有的Reduce所需要的数据,所以每个Map会创建R个bucket(R是reduce的个数),M个Map总共会创建M*R个bucket。
Map创建的bucket其实对应磁盘上的一个文件,Map的结果写到每个bucket中其实就是写到那个磁盘文件中,这个文件也被称为blockFile,是Disk
Block Manager管理器通过文件名的Hash值对应到本地目录的子目录中创建的。每个Map要在节点上创建R个磁盘文件用于结果输出,Map的结果是直接输出到磁盘文件上的,100KB的内存缓冲是用来创建Fast
Buffered OutputStream输出流。这种方式一个问题就是Shuffle文件过多。
针对上述Shuffle过程产生的文件过多问题,Spark有另外一种改进的Shuffle过程:consolidation
Shuffle,以期显著减少Shuffle文件的数量。在consolidation Shuffle中每个bucket并非对应一个文件,而是对应文件中的一个segment部分。Job的map在某个节点上第一次执行,为每个reduce创建bucket对应的输出文件,把这些文件组织成ShuffleFileGroup,当这次map执行完之后,这个ShuffleFileGroup可以释放为下次循环利用;当又有map在这个节点上执行时,不需要创建新的bucket文件,而是在上次的ShuffleFileGroup中取得已经创建的文件继续追加写一个segment;当前次map还没执行完,ShuffleFileGroup还没有释放,这时如果有新的map在这个节点上执行,无法循环利用这个ShuffleFileGroup,而是只能创建新的bucket文件组成新的ShuffleFileGroup来写输出。
比如一个Job有3个Map和2个reduce:(1) 如果此时集群有3个节点有空槽,每个节点空闲了一个core,则3个Map会调度到这3个节点上执行,每个Map都会创建2个Shuffle文件,总共创建6个Shuffle文件;(2)
如果此时集群有2个节点有空槽,每个节点空闲了一个core,则2个Map先调度到这2个节点上执行,每个Map都会创建2个Shuffle文件,然后其中一个节点执行完Map之后又调度执行另一个Map,则这个Map不会创建新的Shuffle文件,而是把结果输出追加到之前Map创建的Shuffle文件中;总共创建4个Shuffle文件;(3)
如果此时集群有2个节点有空槽,一个节点有2个空core一个节点有1个空core,则一个节点调度2个Map一个节点调度1个Map,调度2个Map的节点上,一个Map创建了Shuffle文件,后面的Map还是会创建新的Shuffle文件,因为上一个Map还正在写,它创建的ShuffleFileGroup还没有释放;总共创建6个Shuffle文件。
2.Shuffle Fetcher
Reduce去拖Map的输出数据,Spark提供了两套不同的拉取数据框架:通过socket连接去取数据;使用netty框架去取数据。
每个节点的Executor会创建一个BlockManager,其中会创建一个BlockManagerWorker用于响应请求。当Reduce的GET_BLOCK的请求过来时,读取本地文件将这个blockId的数据返回给Reduce。如果使用的是Netty框架,BlockManager会创建ShuffleSender用于发送Shuffle数据。并不是所有的数据都是通过网络读取,对于在本节点的Map数据,Reduce直接去磁盘上读取而不再通过网络框架。
Reduce拖过来数据之后以什么方式存储呢?Spark Map输出的数据没有经过排序,Spark
Shuffle过来的数据也不会进行排序,Spark认为Shuffle过程中的排序不是必须的,并不是所有类型的Reduce需要的数据都需要排序,强制地进行排序只会增加Shuffle的负担。Reduce拖过来的数据会放在一个HashMap中,HashMap中存储的也是<key,
value>对,key是Map输出的key,Map输出对应这个key的所有value组成HashMapvalue
Spark将Shuffle取过来的每一个<key, value>对插入或者更新到HashMap中,来一个处理一个。HashMap全部放在内存中。
Shuffle取过来的数据全部存放在内存中,对于数据量比较小或者已经在Map端做过合并处理的Shuffle数据,占用内存空间不会太大,但是对于比如group
by key这样的操作,Reduce需要得到key对应的所有value,并将这些value组一个数组放在内存中,这样当数据量较大时,就需要较多内存。
当内存不够时,要不就失败,要不就用老办法把内存中的数据移到磁盘上放着。Spark意识到在处理数据规模远远大于内存空间时所带来的不足,引入了一个具有外部排序的方案。Shuffle过来的数据先放在内存中,当内存中存储的<key,
value>对超过1000并且内存使用超过70%时,判断节点上可用内存如果还足够,则把内存缓冲区大小翻倍,如果可用内存不再够了,则把内存中的<key,
value>对排序然后写到磁盘文件中。最后把内存缓冲区中的数据排序之后和那些磁盘文件组成一个最小堆,每次从最小堆中读取最小的数据,这个和MapReduce中的merge过程类似。
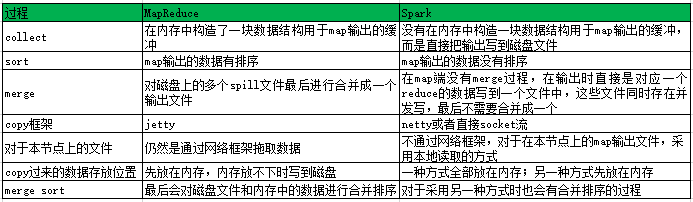
3.MapReduce和Spark的Shuffle过程对比
Spark的资源管理与作业调度
Spark对于资源管理与作业调度可以使用本地模式,Standalone(独立模式),Apache
Mesos及Hadoop YARN来实现。Spark on Yarn在Spark0.6时引用,但真正可用是在现在的branch-0.8版本。Spark
on Yarn遵循YARN的官方规范实现,得益于Spark天生支持多种Scheduler和Executor的良好设计,对YARN的支持也就非常容易,Spark
on Yarn的大致框架图。
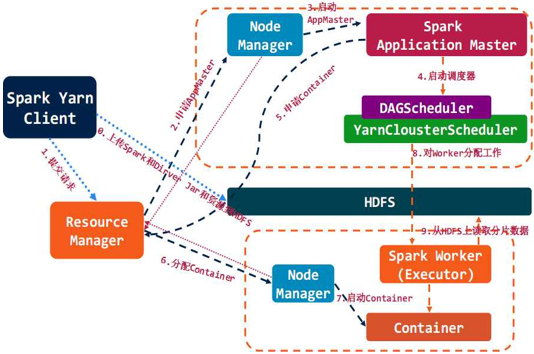
让Spark运行于YARN上与Hadoop共用集群资源可以提高资源利用率。
编程接口
Spark通过与编程语言集成的方式暴露RDD的操作,类似于DryadLINQ和FlumeJava,每个数据集都表示为RDD对象,对数据集的操作就表示成对RDD对象的操作。Spark主要的编程语言是Scala,选择Scala是因为它的简洁性(Scala可以很方便在交互式下使用)和性能(JVM上的静态强类型语言)。
Spark和Hadoop MapReduce类似,由Master(类似于MapReduce的Jobtracker)和Workers(Spark的Slave工作节点)组成。用户编写的Spark程序被称为Driver程序,Dirver程序会连接master并定义了对各RDD的转换与操作,而对RDD的转换与操作通过Scala闭包(字面量函数)来表示,Scala使用Java对象来表示闭包且都是可序列化的,以此把对RDD的闭包操作发送到各Workers节点。
Workers存储着数据分块和享有集群内存,是运行在工作节点上的守护进程,当它收到对RDD的操作时,根据数据分片信息进行本地化数据操作,生成新的数据分片、返回结果或把RDD写入存储系统。

Scala:Spark使用Scala开发,默认使用Scala作为编程语言。编写Spark程序比编写Hadoop
MapReduce程序要简单的多,SparK提供了Spark-Shell,可以在Spark-Shell测试程序。写SparK程序的一般步骤就是创建或使用(SparkContext)实例,使用SparkContext创建RDD,然后就是对RDD进行操作。
Java:Spark支持Java编程,但对于使用Java就没有了Spark-Shell这样方便的工具,其它与Scala编程是一样的,因为都是JVM上的语言,Scala与Java可以互操作,Java编程接口其实就是对Scala的封装。如:
Python:现在Spark也提供了Python编程接口,Spark使用py4j来实现python与java的互操作,从而实现使用python编写Spark程序。Spark也同样提供了pyspark,一个Spark的python
shell,可以以交互式的方式使用Python编写Spark程序。
Spark生态系统
Shark ( Hive on Spark): Shark基本上就是在Spark的框架基础上提供和Hive一样的H
iveQL命令接口,为了最大程度的保持和Hive的兼容性,Shark使用了Hive的API来实现query
Parsing和 Logic Plan generation,最后的PhysicalPlan execution阶段用Spark代替Hadoop
MapReduce。通过配置Shark参数,Shark可以自动在内存中缓存特定的RDD,实现数据重用,进而加快特定数据集的检索。同时,Shark通过UDF用户自定义函数实现特定的数据分析学习算法,使得SQL数据查询和运算分析能结合在一起,最大化RDD的重复使用。
Spark streaming: 构建在Spark上处理Stream数据的框架,基本的原理是将Stream数据分成小的时间片断(几秒),以类似batch批量处理的方式来处理这小部分数据。Spark
Streaming构建在Spark上,一方面是因为Spark的低延迟执行引擎(100ms+)可以用于实时计算,另一方面相比基于Record的其它处理框架(如Storm),RDD数据集更容易做高效的容错处理。此外小批量处理的方式使得它可以同时兼容批量和实时数据处理的逻辑和算法。方便了一些需要历史数据和实时数据联合分析的特定应用场合。
Bagel: Pregel on Spark,可以用Spark进行图计算,这是个非常有用的小项目。Bagel自带了一个例子,实现了Google的PageRank算法。
Spark的适用场景
1.Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小
2.由于RDD的特性,Spark不适用那种异步细粒度更新状态的应用,例如web服务的存储或者是增量的web爬虫和索引。就是对于那种增量修改的应用模型不适合。
总的来说Spark的适用面比较广泛且比较通用。
在业界的使用
Spark项目在2009年启动,2010年开源, 现在使用的有:Berkeley,
Princeton, Klout, Foursquare, Conviva, Quantifind, Yahoo!
Research & others, 淘宝等,豆瓣也在使用Spark的python克隆版Dpark。
|






