在关系型数据库中
join 是非常常见的操作,各种优化手段已经到了极致。在海量数据的环境下,不可避免的也会碰到这种类型的需求,例如在数据分析时需要连接从不同的数据源中获取到的数据。不同于传统的单机模式,在分布式存储的下采用
MapReduce 编程模型,也有相应的处理措施和优化方法。
本文对 Hadoop 中最基本的 join 方法进行简单介绍,这也是其它许多方法和优化措施的基础。文中所采用的例子来自于《
Hadoop in Action 》一书中的 5.2 节 。假设两个表所在的文件分别为Customers和Orders,以CSV格式存储在HDFS中。
1,Stephanie Leung,555-555-5555
2,Edward Kim,123-456-7890
3,Jose Madriz,281-330-8004
4,David Stork,408-555-0000
3,A,12.95,02-Jun-2008
1,B,88.25,20-May-2008
2,C,32.00,30-Nov-2007
3,D,25.02,22-Jan-2009 |
这里的Customer ID是连接的键,那么连接的结果:
1,Stephanie Leung,555-555-5555,B,88.25,20-May-2008
2,Edward Kim,123-456-7890,C,32.00,30-Nov-2007
3,Jose Madriz,281-330-8004,A,12.95,02-Jun-2008
3,Jose Madriz,281-330-8004,D,25.02,22-Jan-2009 |
回忆一下Hadoop中MapReduce中的主要几个过程:依次是读取数据分块,map操作,shuffle操作,reduce操作,然后输出结果。简单来说,其本质在于大而化小,分拆处理。显然我们想到的是将两个数据表中键值相同的元组放到同一个reduce结点进行,关键问题在于如何做到?具体处理方法是将map操作输出的key值设为两表的
连接键(如例子中的Customer ID) ,那么在shuffle阶段,Hadoop中默认的partitioner会将相同key值得map输出发送到同一个reduce结点。所以整个过程如下图所示:
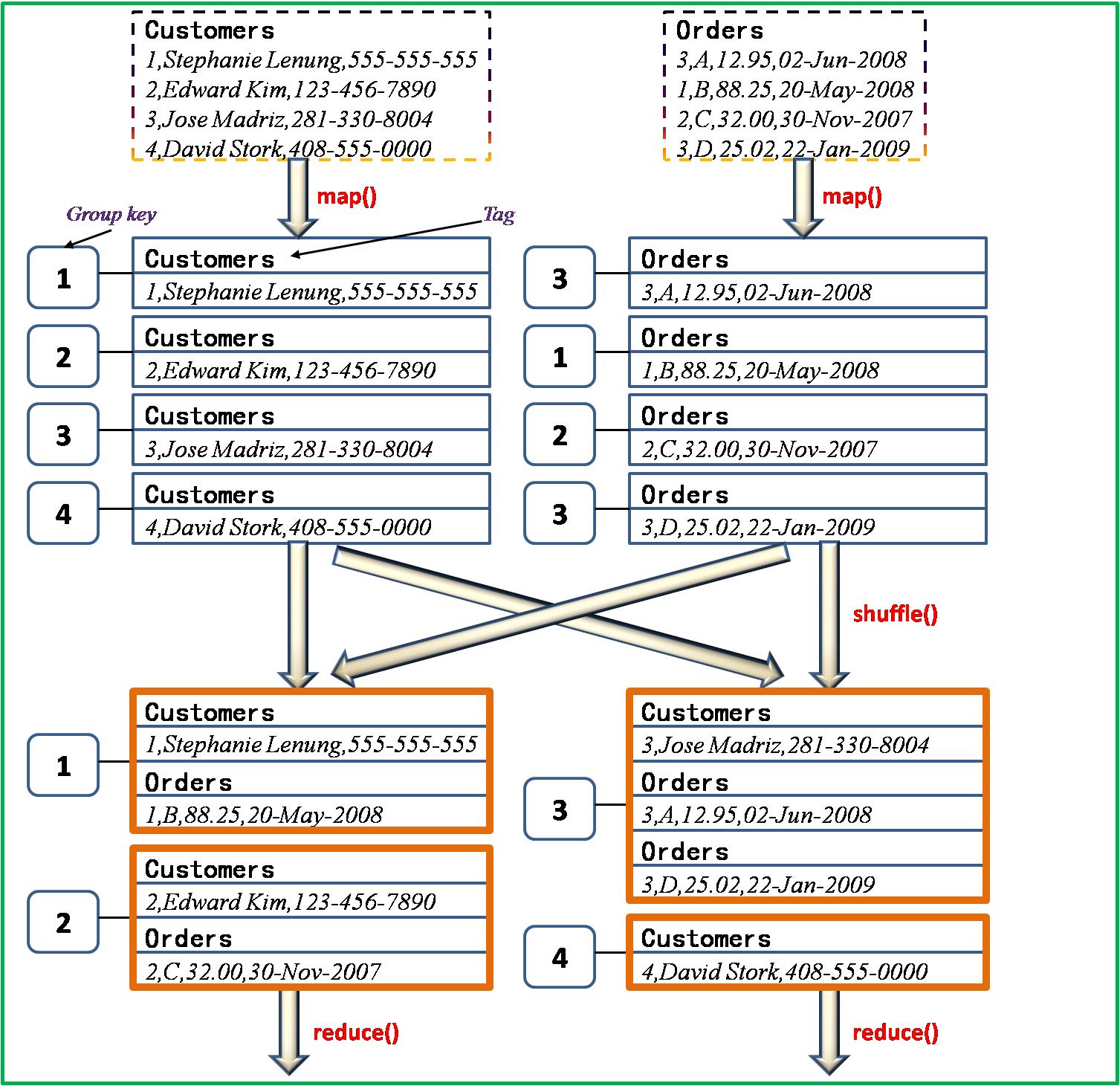
这种方法称为Repartition Join,同时它进行join操作是在reduce阶段进行,也属于Reduce-side
Join;在Hadoop中contrib目录下的datajoin就是采用的这种方法。
上一篇介绍了 Repartition Join 的基本思想,实践出真知,具体的实现中总是存在各种细节问题。下面我们通过具体的源码分析来加深理解。本文分析的是
Hadoop-0.20.2 版本的 datajoin 代码,其它版本也许会有变化,这里暂且不论。
参看源码目录下,共实现有 7 个类,分别是:
ArrayListBackIterator.java
DataJoinJob.java
DataJoinMapperBase.java
DataJoinReducerBase.java
JobBase.java
ResetableIterator.java
TaggedMapOutput.java |
源码比较简单,代码量小,下面对一些关键的地方进行分析:前面我们提到了 map 阶段的输出的 key 值的设定;然而在实现中,其value值也是另外一个需要考虑的地方,在不同的
reduce 结点进行 join 操作时,需要知道参与 join 的元组所属的表;解决方法是在 map
输出的 value 值中加入一个标记 (tag) ,例如上一篇例子中两表的tag 可以分别 customer
和 order (注:实际上,在reduce阶段可以直接分析两元组的结构就可以确定数据来源)。这也是 TaggedMapOutput.java
的来历。作为 Hadoop 的中间数据,必须实现 Writable 的方法,如下所示:
public abstract class TaggedMapOutput implements Writable {
protected Text tag;
public TaggedMapOutput() {
this.tag = new Text("");
}
public Text getTag() {
return tag;
}
public void setTag(Text tag) {
this.tag = tag;
}
public abstract Writable getData();
public TaggedMapOutput clone(JobConf job) {
return (TaggedMapOutput) WritableUtils.clone(this, job);
}
} |
接下来,我们看看 DataJoinMapperBase 中的相关方法
protected abstract TaggedMapOutput generateTaggedMapOutput(Object value);
protected abstract Text generateGroupKey(TaggedMapOutput aRecord); |
以上两个方法需要由子类实现。上一篇文章提到,将两个表的连接键作为 map 输出的 key 值,其中第二个方法所做的就是这件事,生成一个类型为
Text 的 key ,不过这里是将它称作是 GroupKey 而已。因此 map 方法也就比较简单易懂了
public void map(Object key, Object value, OutputCollector output,
Reporter reporter) throws IOException {
if (this.reporter == null) {
this.reporter = reporter;
}
addLongValue("totalCount", 1);
TaggedMapOutput aRecord = generateTaggedMapOutput(value);
if (aRecord == null) {
addLongValue("discardedCount", 1);
return;
}
Text groupKey = generateGroupKey(aRecord);
if (groupKey == null) {
addLongValue("nullGroupKeyCount", 1);
return;
}
output.collect(groupKey, aRecord);
addLongValue("collectedCount", 1);
} |
说完了 map 操作,接下来就是 reduce 阶段的事情了。参看 DataJoinReducerBase
这个类,其中的 reduce 方法主要部分是:
public void reduce(Object key, Iterator values,
OutputCollector output, Reporter reporter) throws IOException {
if (this.reporter == null) {
this.reporter = reporter;
}
SortedMap<Object, ResetableIterator> groups = regroup(key, values, reporter);
Object[] tags = groups.keySet().toArray();
ResetableIterator[] groupValues = new ResetableIterator[tags.length];
for (int i = 0; i < tags.length; i++) {
groupValues[i] = groups.get(tags[i]);
}
joinAndCollect(tags, groupValues, key, output, reporter);
addLongValue("groupCount", 1);
for (int i = 0; i < tags.length; i++) {
groupValues[i].close();
}
} |
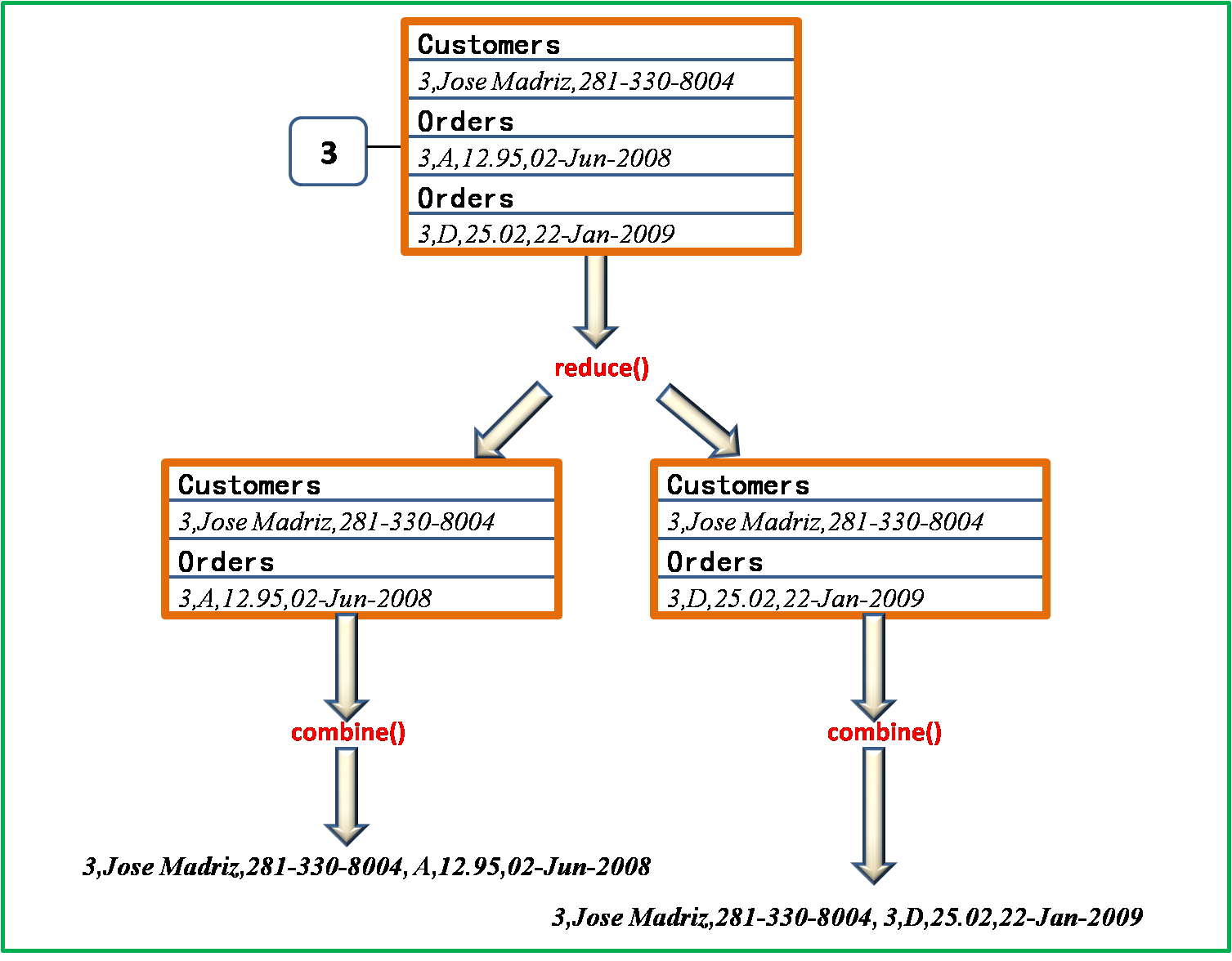
其中 groups 数组保存的是 tag 以及它们对应元组的 iterator 。例如 Customer
ID 为 3 的数据块所在的 reduce 节点上, tags = {"Custmoers"
, "Orders"}, groupValues 则对应 {"3,Jose
Madriz,281-330-8004"} 和 {"3,A,12.95,02-Jun-2008","3,D,25.02,22-Jan-2009"}
的 iterator 。归根结底,关于两个元组的 join 操作放在
protected abstract TaggedMapOutput combine(Object[] tags, Object[] values); |
该方法由子类实现。
下面附上 《 Hadoop in Action 》中提供的一种实现
public class DataJoin extends Confi gured implements Tool {
public static class MapClass extends DataJoinMapperBase {
protected Text generateInputTag(String inputFile) {
String datasource = inputFile.split(“-”)[0];
return new Text(datasource);
}
protected Text generateGroupKey(TaggedMapOutput aRecord) {
String line = ((Text) aRecord.getData()).toString();
String[] tokens = line.split(“,”);
String groupKey = tokens[0];
return new Text(groupKey);
}
protected TaggedMapOutput generateTaggedMapOutput(Object value) {
TaggedWritable retv = new TaggedWritable((Text) value);
retv.setTag(this.inputTag);
return retv;
}
}
public static class Reduce extends DataJoinReducerBase {
protected TaggedMapOutput combine(Object[] tags, Object[] values) {
if (tags.length < 2) return null;
String joinedStr = “”;
for (int i=0; i<values.length; i++) {
if (i > 0) joinedStr += “,”;
TaggedWritable tw = (TaggedWritable) values[i];
String line = ((Text) tw.getData()).toString();
String[] tokens = line.split(“,”, 2);
joinedStr += tokens[1];
}
TaggedWritable retv = new TaggedWritable(new Text(joinedStr));
retv.setTag((Text) tags[0]);
return retv;
}
}
public static class TaggedWritable extends TaggedMapOutput {
private Writable data;
public TaggedWritable(Writable data) {
this.tag = new Text(“”);
this.data = data;
}
public Writable getData() {
return data;
}
public void write(DataOutput out) throws IOException {
this.tag.write(out);
this.data.write(out);
}
public void readFields(DataInput in) throws IOException {
this.tag.readFields(in);
this.data.readFields(in);
}
}
public int run(String[] args) throws Exception {
Confi guration conf = getConf();
JobConf job = new JobConf(conf, DataJoin.class);
Path in = new Path(args[0]);
Path out = new Path(args[1]);
FileInputFormat.setInputPaths(job, in);
FileOutputFormat.setOutputPath(job, out);
job.setJobName(“DataJoin”);
job.setMapperClass(MapClass.class);
job.setReducerClass(Reduce.class);
job.setInputFormat(TextInputFormat.class);
job.setOutputFormat(TextOutputFormat.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(TaggedWritable.class);
job.set(“mapred.textoutputformat.separator”, “,”);
JobClient.runJob(job);
return 0;
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Confi guration(),
new DataJoin(),
args);
System.exit(res);
}
} |
本文讲述如何在map端完成join操作。之前我们提到了reduce-join,这种方法的灵活性不错,也是理所当然地能够想到的方法;但这种方法存在的一个最大的问题是性能。大量的中间数据需要从map节点通过网络发送到reduce节点,因而效率比较低。实际上,两表的join操作中很多都是无用的数据。现在考虑可能的一种场景,其中一个表非常小,以致于可以直接存放在内存中,那么我们可以利用Hadoop提供的DistributedCache机制,将较小的表加入到其中,在每个map节点都能够访问到该表,最终实现在map阶段完成join操作。这里提一下DistributedCache,可以直观上将它看作是一个全局的只读空间,存储一些需要共享的数据;具体可以参看Hadoop相关资料,这里不进行深入讨论。
实现的源码如下,原理非常简单明了:
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.Hashtable;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.KeyValueTextInputFormat;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
@SuppressWarnings("deprecation")
public class DataJoinDC extends Configured implements Tool{
private final static String inputa = "hdfs://m100:9000/joinTest/Customers";
private final static String inputb = "hdfs://m100:9000/joinTest/Orders";
private final static String output = "hdfs://m100:9000/joinTest/output";
public static class MapClass extends MapReduceBase
implements Mapper<Text, Text, Text, Text> {
private Hashtable<String, String> joinData = new Hashtable<String, String>();
@Override
public void configure(JobConf conf) {
try {
Path [] cacheFiles = DistributedCache.getLocalCacheFiles(conf);
if (cacheFiles != null && cacheFiles.length > 0) {
String line;
String[] tokens;
BufferedReader joinReader = new BufferedReader(
new FileReader(cacheFiles[0].toString()));
try {
while ((line = joinReader.readLine()) != null) {
tokens = line.split(",", 2);
joinData.put(tokens[0], tokens[1]);
}
}finally {
joinReader.close();
}}} catch (IOException e) {
System.err.println("Exception reading DistributedCache: " + e);
}
}
public void map(Text key, Text value,OutputCollector<Text, Text> output,
Reporter reporter) throws IOException {
// for(String t: joinData.keySet()){
// output.collect(new Text(t), new Text(joinData.get(t)));
// }
String joinValue = joinData.get(key.toString());
if (joinValue != null) {
output.collect(key,new Text(value.toString() + "," + joinValue));
}
}
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
DistributedCache.addCacheFile(new Path(inputa).toUri(), conf);
JobConf job = new JobConf(conf, DataJoinDC.class);
Path in = new Path(inputb);
Path out = new Path(output);
FileInputFormat.setInputPaths(job, in);
FileOutputFormat.setOutputPath(job, out);
job.setJobName("DataJoin with DistributedCache");
job.setMapperClass(MapClass.class);
job.setNumReduceTasks(0);
job.setInputFormat(KeyValueTextInputFormat.class);
job.setOutputFormat(TextOutputFormat.class);
job.set("key.value.separator.in.input.line", ",");
JobClient.runJob(job);
return 0;
}
public static void main(String[] args) throws Exception{
int res = ToolRunner.run(new Configuration(), new DataJoinDC(), args);
System.exit(res);
}
} |
以上参照《Hadoop in Action》 所附代码,我这里是将Customers表作为较小的表,传入DistributedCache。
这里需要注意的地方
DistributedCache.addCacheFile(new Path(inputa).toUri(), conf); |
这句一定要放在job初始化之前,否则在map中读取不到文件。因为job初始化时将传入Configuration对象拷贝了一份给了JobContext!
|






