|
Map的结果,会通过partition分发到Reducer上,Reducer做完Reduce操作后,通过OutputFormat,进行输出,下面我们就来分析参与这个过程的类。
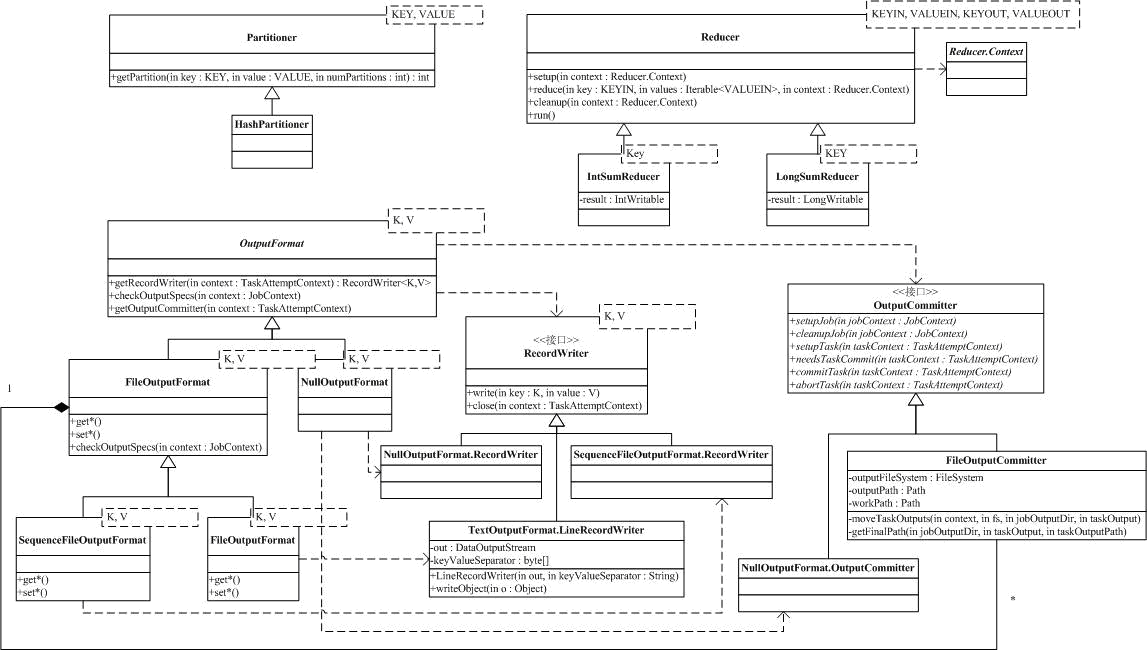
Mapper的结果,可能送到可能的Combiner做合并,Combiner在系统中并没有自己的基类,而是用Reducer作为Combiner的基类,他们对外的功能是一样的,只是使用的位置和使用时的上下文不太一样而已。
Mapper最终处理的结果对<key, value>,是需要送到Reducer去合并的,合并的时候,有相同key的键/值对会送到同一个Reducer那,哪个key到哪个Reducer的分配过程,是由Partitioner规定的,它只有一个方法,输入是Map的结果对<key,
value>和Reducer的数目,输出则是分配的Reducer(整数编号)。系统缺省的Partitioner是HashPartitioner,它以key的Hash值对Reducer的数目取模,得到对应的Reducer。
Reducer是所有用户定制Reducer类的基类,和Mapper类似,它也有setup,reduce,cleanup和run方法,其中setup和cleanup含义和Mapper相同,reduce是真正合并Mapper结果的地方,它的输入是key和这个key对应的所有value的一个迭代器,同时还包括Reducer的上下文。系统中定义了两个非常简单的Reducer,IntSumReducer和LongSumReducer,分别用于对整形/长整型的value求和。
Reduce的结果,通过Reducer.Context的方法collect输出到文件中,和输入类似,Hadoop引入了OutputFormat。OutputFormat依赖两个辅助接口:RecordWriter和OutputCommitter,来处理输出。RecordWriter提供了write方法,用于输出<key,
value>和close方法,用于关闭对应的输出。OutputCommitter提供了一系列方法,用户通过实现这些方法,可以定制OutputFormat生存期某些阶段需要的特殊操作。我们在TaskInputOutputContext中讨论过这些方法(明显,TaskInputOutputContext是OutputFormat和Reducer间的桥梁)。
OutputFormat和RecordWriter分别对应着InputFormat和RecordReader,系统提供了空输出NullOutputFormat(什么结果都不输出,NullOutputFormat.RecordWriter只是示例,系统中没有定义),LazyOutputFormat(没在类图中出现,不分析),FilterOutputFormat(不分析)和基于文件FileOutputFormat的SequenceFileOutputFormat和TextOutputFormat输出。
基于文件的输出FileOutputFormat利用了一些配置项配合工作,包括mapred.output.compress:是否压缩
mapred.output.compression.codec:压缩方法;mapred.output.dir:输出路径;mapred.work.output.dir:输出工作路径。FileOutputFormat还依赖于FileOutputCommitter,通过FileOutputCommitter提供一些和Job,Task相关的临时文件管理功能。如FileOutputCommitter的setupJob,会在输出路径下创建一个名为_temporary的临时目录,cleanupJob则会删除这个目录。
SequenceFileOutputFormat输出和TextOutputFormat输出分别对应输入的SequenceFileInputFormat和TextInputFormat,我们就不再详细分析啦。
Mapper的输出,在发送到Reducer前是存放在本地文件系统的,IFile提供了对Mapper输出的管理。我们已经知道,Mapper的输出是<Key,Value>对,IFile以记录<key-len,
value-len, key,value>的形式存放了这些数据。为了保存键值对的边界,很自然IFile需要保存key-len和value-len。
和IFile相关的类图如下:
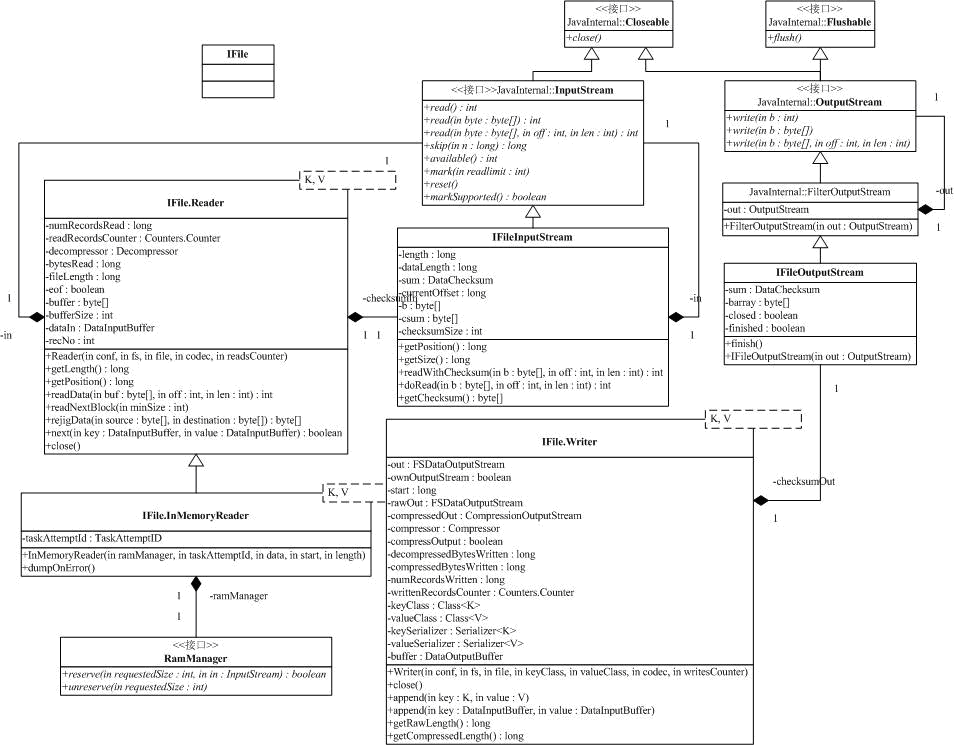
其中,文件流形式的输入和输出是由IFIleInputStream和IFIleOutputStream抽象。以记录形式的读/写操作由IFile.Reader/IFile.Writer提供,IFile.InMemoryReader用于读取存在于内存中的IFile文件格式数据。
我们以输出为例,来分析这部分的实现。首先是下图的和序列化反序列化相关的Serialization/Deserializer,这部分的code是在包org.apache.hadoop.io.serializer。序列化由Serializer抽象,通过Serializer的实现,用户可以利用serialize方法把对象序列化到通过open方法打开的输出流里。Deserializer提供的是相反的过程,对应的方法是deserialize。hadoop.io.serializer中还实现了配合工作的Serialization和对应的工厂SerializationFactory。两个具体的实现是WritableSerialization和JavaSerialization,分别对应了Writeble的序列化反序列化和Java本身带的序列化反序列化。
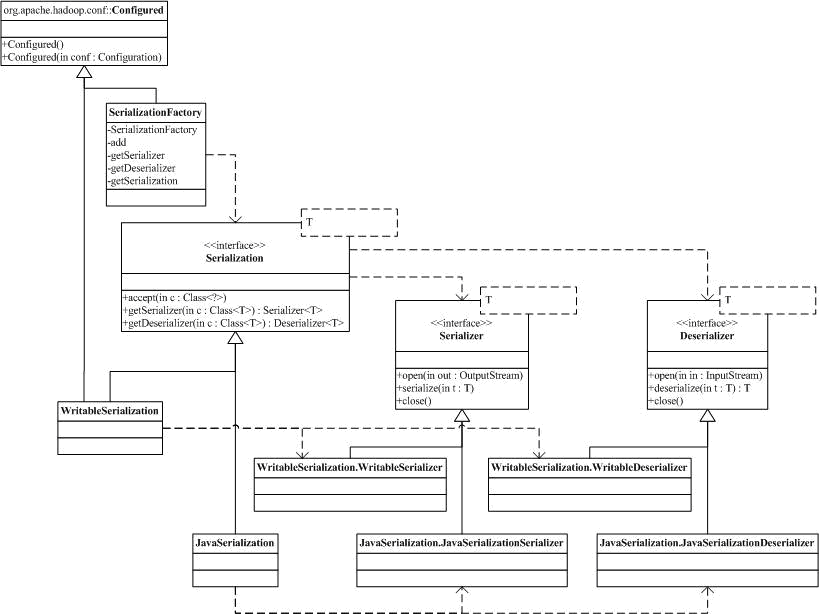
有了Serializer/Deserializer,我们来分析IFile.Writer。Writer的构造函数是:
public Writer(Configuration conf, FSDataOutputStream out,
Class<K> keyClass, Class<V> valueClass,
CompressionCodec codec, Counters.Counter writesCounter) |
conf,配置参数,out是Writer的输出,keyClass 和valueClass
是输出的Kay,Value的class属性,codec是对输出进行压缩的方法,参数writesCounter用于对输出字节数进行统计的Counters.Counter。通过这些参数,我们可以构造我们使用的支持压缩功能的输出流(类成员out,类成员rawOut保存了构造函数传入的out),相关的计数器,还有就是Kay,Value的Serializer方法。
Writer最主要的方法是append方法(居然不是write方法,呵呵),有两种形式:
public void append(K key, V value) throws IOException {
public void append(DataInputBuffer key, DataInputBuffer value) |
append(K key, V value)的主要过程是检查参数,然后将key和value序列化到DataOutputBuffer中,并获取序列化后的长度,最后把长度(2个)和DataOutputBuffer中的结果写到输出,并复位DataOutputBuffer和计数。append(DataInputBuffer
key, DataInputBuffer value)处理过程也比较类似,就不再分析了。
close方法中需要注意的是,我们需要标记文件尾,或者是流结束。目前是通过写2个值为EOF_MARKER的长度来做标记。
IFileOutputStream是用于配合Writer的输出流,它会在IFiles的最后添加校验数据。当Writer调用IFileOutputStream的write操作时,IFileOutputStream计算并保持校验和,流被close的时候,校验结果会写到对应文件的文件尾。实际上存放在磁盘上的文件是一系列的<key-len,
value-len, key, value>记录和校验结果。
Reader的相关过程,我们就不再分析了。
IDs类和*Context类
我们开始来分析Hadoop MapReduce的内部的运行机制。用户向Hadoop提交Job(作业),作业在JobTracker对象的控制下执行。Job被分解成为Task(任务),分发到集群中,在TaskTracker的控制下运行。Task包括MapTask和ReduceTask,是MapReduce的Map操作和Reduce操作执行的地方。这中任务分布的方法比较类似于HDFS中NameNode和DataNode的分工,NameNode对应的是JobTracker,DataNode对应的是TaskTracker。JobTracker,TaskTracker和MapReduce的客户端通过RPC通信,具体可以参考HDFS部分的分析。
我们先来分析一些辅助类,首先是和ID有关的类,ID的继承树如下:
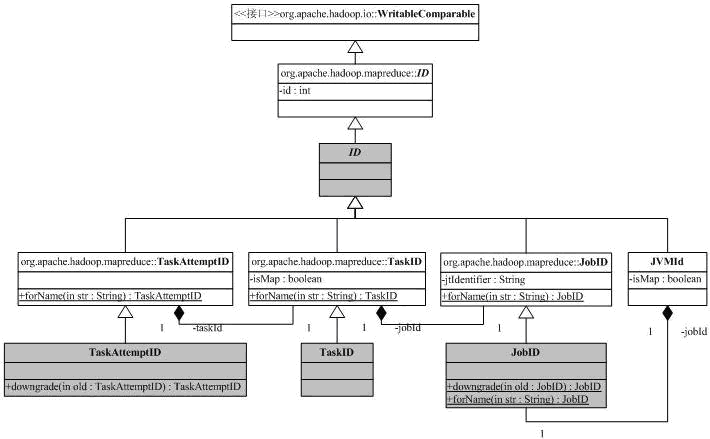
这张图可以看出现在Hadoop的org.apache.hadoop.mapred向org.apache.hadoop.mapreduce迁移带来的一些问题,其中灰色是标注为@Deprecated的。ID携带一个整型,实现了WritableComparable接口,这表明它可以比较,而且可以被Hadoop的io机制串行化/解串行化(必须实现compareTo/readFields/write方法)。JobID是系统分配给作业的唯一标识符,它的toString结果是job_<jobtrackerID>_<jobNumber>。例子:job_200707121733_0003表明这是jobtracker
200707121733(利用jobtracker的开始时间作为ID)的第3号作业。
作业分成任务执行,任务号TaskID包含了它所属的作业ID,同时也有任务ID,同时还保持了这是否是一个Map任务(成员变量isMap)。任务号的字符串表示为task_<jobtrackerID>_<jobNumber>_[m|r]_<taskNumber>,如task_200707121733_0003_m_000005表示作业200707121733_0003的000005号任务,改任务是一个Map任务。
一个任务有可能有多个执行(错误恢复/消除Stragglers等),所以必须区分任务的多个执行,这是通过类TaskAttemptID来完成,它在任务号的基础上添加了尝试号。一个任务尝试号的例子是attempt_200707121733_0003_m_000005_0,它是任务task_200707121733_0003_m_000005的第0号尝试。
JVMId用于管理任务执行过程中的Java虚拟机,我们后面再讨论。
为了使Job和Task工作,Hadoop提供了一系列的上下文,这些上下文保存了Job和Task工作的信息。
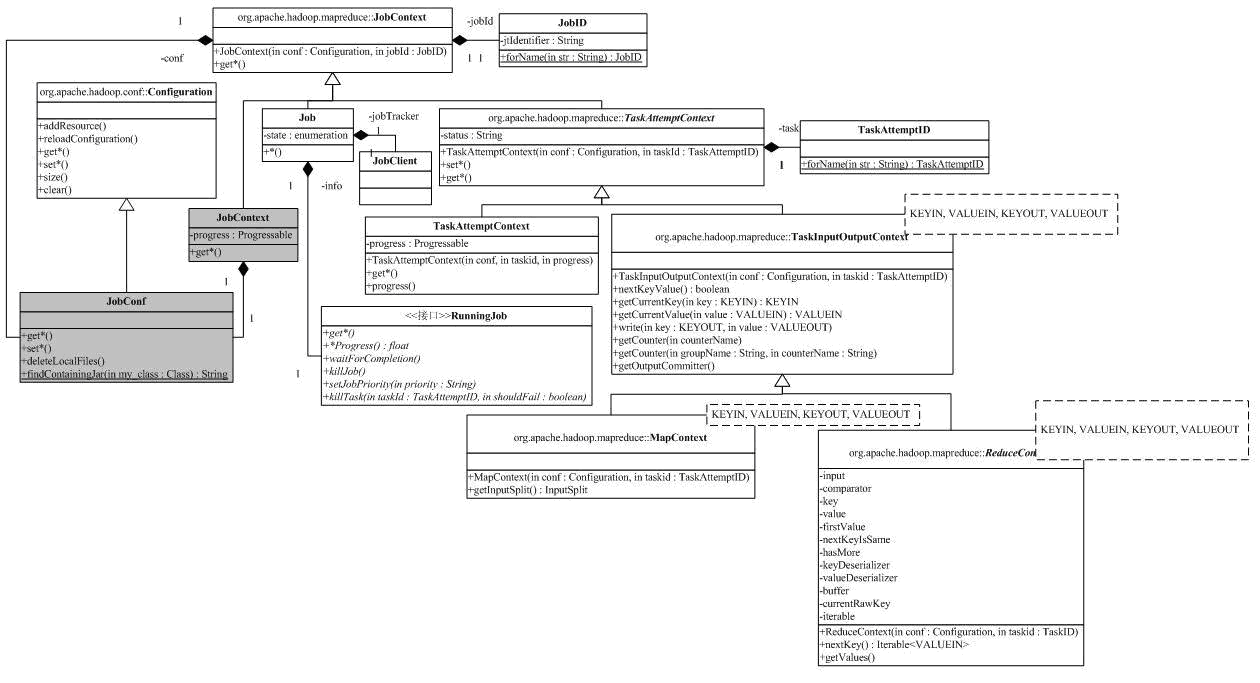
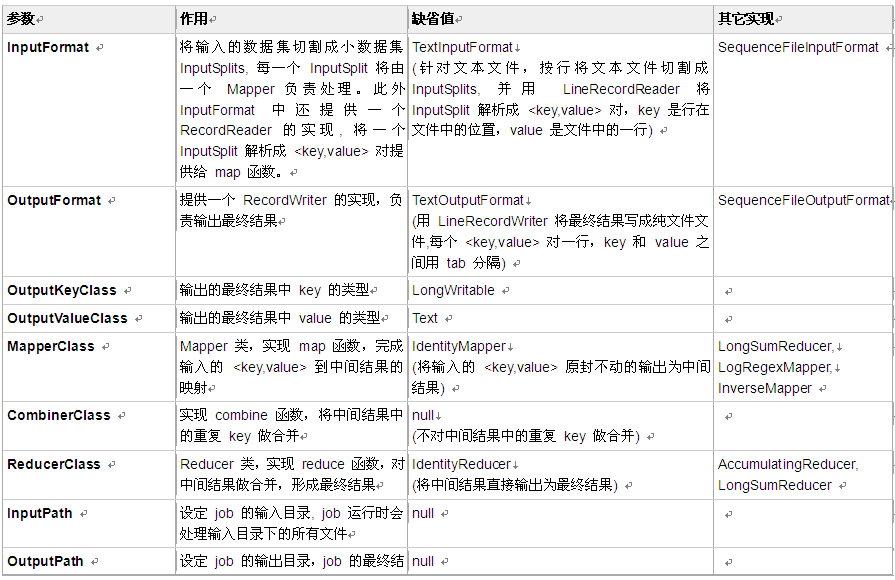
处于继承树的最上方是org.apache.hadoop.mapreduce.JobContext,前面我们已经介绍过了,它提供了Job的一些只读属性,两个成员变量,一个保存了JobID,另一个类型为JobConf,JobContext中除了JobID外,其它的信息都保持在JobConf中。它定义了如下配置项:
1.mapreduce.inputformat.class:InputFormat的实现
2.mapreduce.map.class:Mapper的实现
3.mapreduce.combine.class: Reducer的实现
4.mapreduce.reduce.class:Reducer的实现
5.mapreduce.outputformat.class: OutputFormat的实现
6.mapreduce.partitioner.class: Partitioner的实现
同时,它提供方法,使得通过类名,利用Java反射提供的Class.forName方法,获得类对应的Class。org.apache.hadoop.mapred的JobContext对象比org.apache.hadoop.mapreduce.JobContext多了成员变量progress,用于获取进度信息,它类型为JobConf成员job指向mapreduce.JobContext对应的成员,没有添加任何新功能。
JobConf继承自Configuration,保持了MapReduce执行需要的一些配置信息,它管理着46个配置参数,包括上面mapreduce配置项对应的老版本形式,如mapreduce.map.class
对应mapred.mapper.class。这些配置项我们在使用到它们的时候再介绍。
org.apache.hadoop.mapreduce.JobContext的子类Job前面也已经介绍了,后面在讨论系统的动态行为时,再回来看它。
TaskAttemptContext用于任务的执行,它引入了标识任务执行的TaskAttemptID和任务状态status,并提供新的访问接口。org.apache.hadoop.mapred的TaskAttemptContext继承自mapreduce的对应版本,只是增加了记录进度的progress。
TaskInputOutputContext和它的子类都在包org.apache.hadoop.mapreduce中,前面已经分析过。
包hadoop.mapred中的MapReduce接口
前面已经完成了对org.apache.hadoop.mapreduce的分析,这个包提供了Hadoop
MapReduce部分的应用API,用于用户实现自己的MapReduce应用。但这些接口是给未来的MapReduce应用的,目前MapReduce框架还是使用老系统。下面我们来分析org.apache.hadoop.mapred,首先还是从mapred的MapReduce框架开始分析,下面的类图(灰色部分为标记为@Deprecated的类/接口):
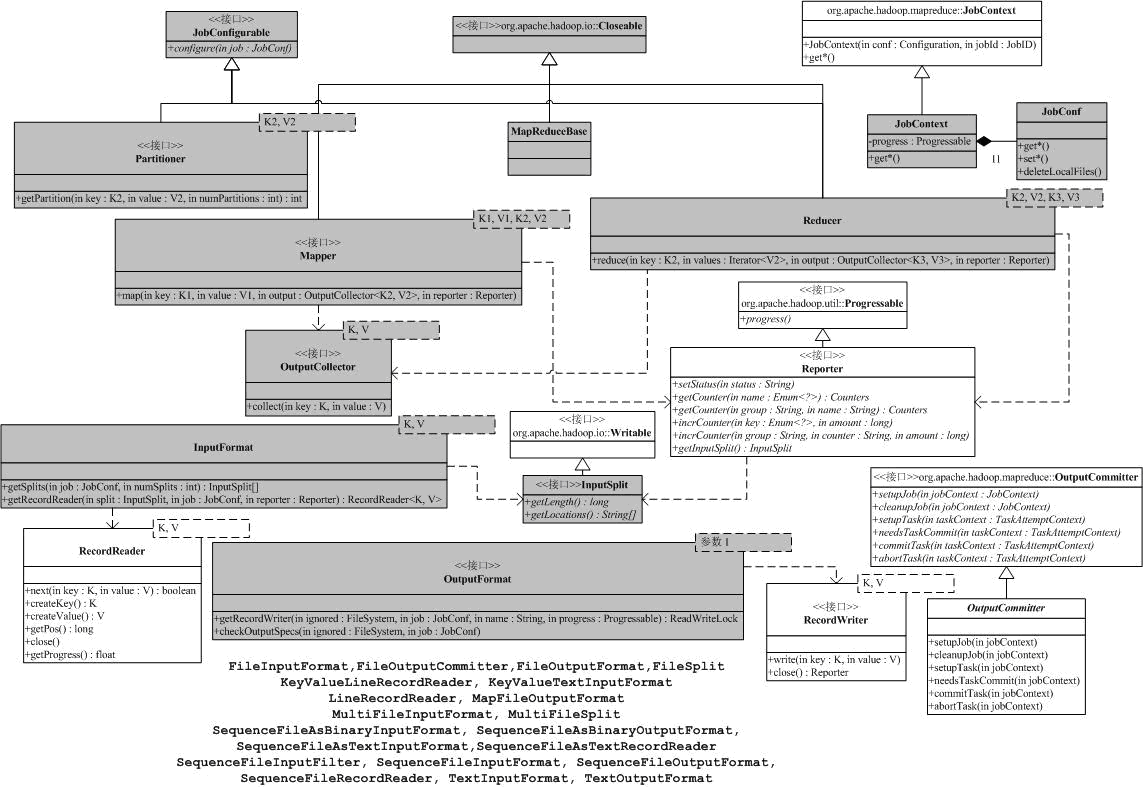
我们把包mapreduce的类图附在下面,对比一下,我们就会发现,org.apache.hadoop.mapred中的MapReduce
API相对来说很简单,主要是少了和Context相关的类,那么,好多在mapreduce中通过context来完成的工作,就需要通过参数来传递,如Map中的输出,老版本是:
output.collect(key, result); // output’s type is: OutputCollector |
新版本是:
context.write(key, result); // output’s type is: Context |
它们分别使用OutputCollector和Mapper.Context来输出map的结果,显然,原有OutputCollector的新API中就不再需要。总体来说,老版本的API比较简单,MapReduce过程中关键的对象都有,但可扩展性不是很强。同时,老版中提供的辅助类也很多,我们前面分析的FileOutputFormat,也有对应的实现,我们就不再讨论了。
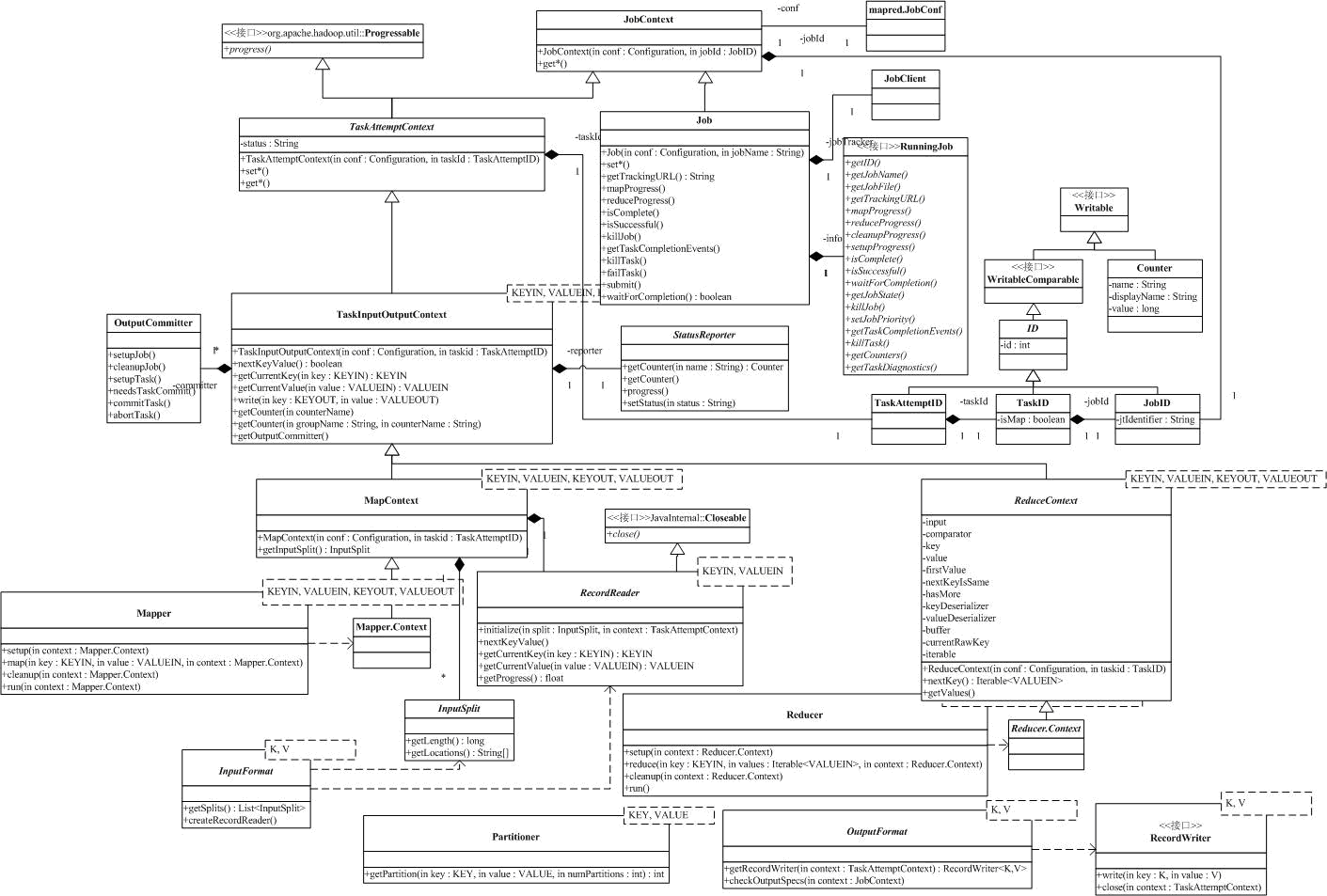
一、包mapreduce.lib.input
接下来我们按照MapReduce过程中数据流动的顺序,来分解org.apache.hadoop.mapreduce.lib.*的相关内容,并介绍对应的基类的功能。首先是input部分,它实现了MapReduce的数据输入部分。类图如下:
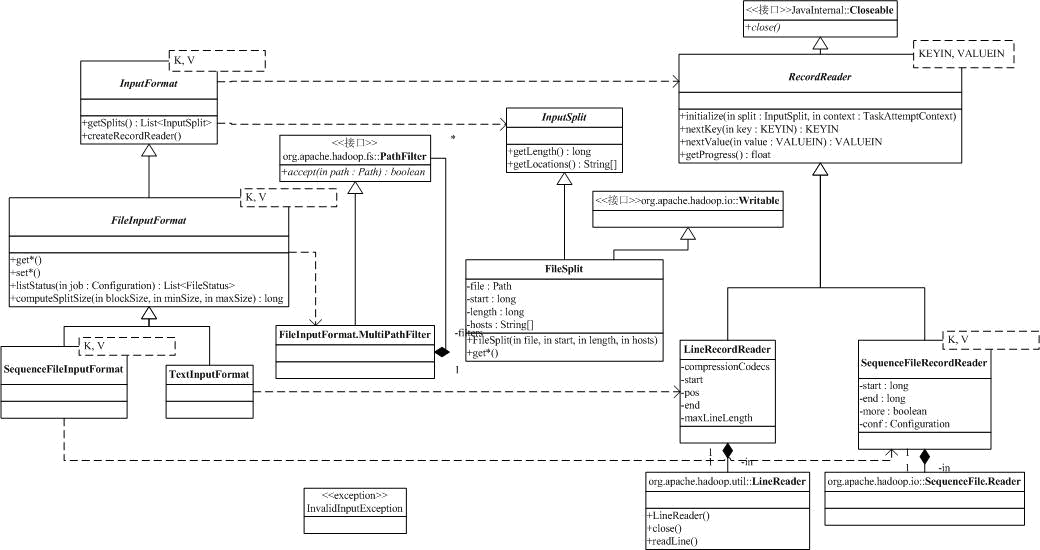
类图的右上角是InputFormat,它描述了一个MapReduceJob的输入,通过InputFormat,Hadoop可以:
1.检查MapReduce输入数据的正确性;
2.将输入数据切分为逻辑块InputSplit,这些块会分配给Mapper;
3.提供一个RecordReader实现,Mapper用该实现从InputSplit中读取输入的<K,V>对。
在org.apache.hadoop.mapreduce.lib.input中,Hadoop为所有基于文件的InputFormat提供了一个虚基类FileInputFormat。下面几个参数可以用于配置FileInputFormat:
1.mapred.input.pathFilter.class:输入文件过滤器,通过过滤器的文件才会加入InputFormat;
2.mapred.min.split.size:最小的划分大小;
3.mapred.max.split.size:最大的划分大小;
4.mapred.input.dir:输入路径,用逗号做分割。
类中比较重要的方法有:
protected List<FileStatus> listStatus(Configuration job) |
递归获取输入数据目录中的所有文件(包括文件信息),输入的job是系统运行的配置Configuration,包含了上面我们提到的参数。
public List<InputSplit> getSplits(JobContext context) |
将输入划分为InputSplit,包含两个循环,第一个循环处理所有的文件,对于每一个文件,根据输入的划分最大/最小值,循环得到文件上的划分。注意,划分不会跨越文件。
FileInputFormat没有实现InputFormat的createRecordReader方法。
FileInputFormat有两个子类,SequenceFileInputFormat是Hadoop定义的一种二进制形式存放的键/值文件(参考http://hadoop.apache.org/core/do
... o/SequenceFile.html),它有自己定义的文件布局。由于它有特殊的扩展名,所以SequenceFileInputFormat重载了listStatus,同时,它实现了createRecordReader,返回一个SequenceFileRecordReader对象
TextInputFormat处理的是文本文件,createRecordReader返回的是LineRecordReader的实例。这两个类都没有重载FileInputFormat的getSplits方法,那么,在他们对于的RecordReader中,必须考虑FileInputFormat对输入的划分方式。
FileInputFormat的getSplits,返回的是FileSplit。这是一个很简单的类,包含的属性(文件名,起始偏移量,划分的长度和可能的目标机器)已经足以说明这个类的功能。
RecordReader用于在划分中读取<Key,Value>对。RecordReader有五个虚方法,分别是:
1.initialize:初始化,输入参数包括该Reader工作的数据划分InputSplit和Job的上下文context;
2.nextKey:得到输入的下一个Key,如果数据划分已经没有新的记录,返回空;
3.nextValue:得到Key对应的Value,必须在调用nextKey后调用;
4.getProgress:得到现在的进度;
5.close,来自java.io的Closeable接口,用于清理RecordReader。
我们以LineRecordReader为例,来分析RecordReader的构成。前面我们已经分析过FileInputFormat对文件的划分了,划分完的Split包括了文件名,起始偏移量,划分的长度。由于文件是文本文件,LineRecordReader的初始化方法initialize会创建一个基于行的读取对象LineReader(定义在org.apache.hadoop.util中,我们就不分析啦),然后跳过输入的最开始的部分(只在Split的起始偏移量不为0的情况下进行,这时最开始的部分可能是上一个Split的最后一行的一部分)。nextKey的处理很简单,它使用当前的偏移量作为Key,nextValue当然就是偏移量开始的那一行了(如果行很长,可能出现截断)。进度getProgress和close都很简单。
二、包mapreduce.lib.map
Hadoop的MapReduce框架中,Map动作通过Mapper类来抽象。一般来说,我们会实现自己特殊的Mapper,并注册到系统中,执行时,我们的Mapper会被MapReduce框架调用。Mapper类很简单,包括一个内部类和四个方法,静态结构图如下:
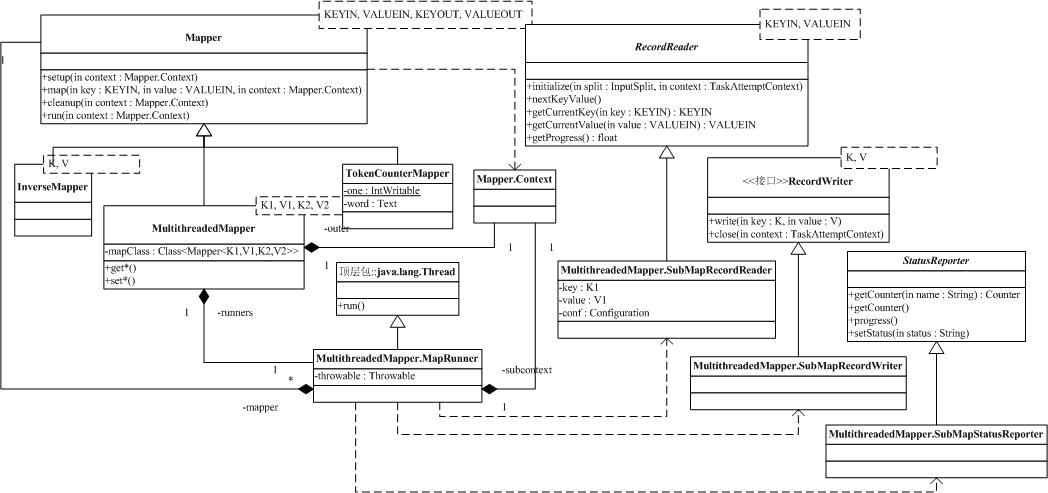
内部类Context继承自MapContext,并没有引入任何新的方法。
Mapper的四个方法是setup,map,cleanup和run。其中,setup和cleanup用于管理Mapper生命周期中的资源,setup在完成Mapper构造,即将开始执行map动作前调用,cleanup则在所有的map动作完成后被调用。方法map用于对一次输入的key/value对进行map动作。run方法执行了上面描述的过程,它调用setup,让后迭代所有的key/value对,进行map,最后调用cleanup。
org.apache.hadoop.mapreduce.lib.map中实现了Mapper的三个子类,分别是InverseMapper(将输入<key,
value> map为输出<value, key>),MultithreadedMapper(多线程执行map方法)和TokenCounterMapper(对输入的value分解为token并计数)。其中最复杂的是MultithreadedMapper,我们就以它为例,来分析Mapper的实现。
MultithreadedMapper会启动多个线程执行另一个Mapper的map方法,它会启动mapred.map.multithreadedrunner.threads(配置项)个线程执行Mapper:mapred.map.multithreadedrunner.class(配置项)。MultithreadedMapper重写了基类Mapper的run方法,启动N个线程(对应的类为MapRunner)执行mapred.map.multithreadedrunner.class(我们称为目标Mapper)的run方法(就是说,目标Mapper的setup和cleanup会被执行多次)。目标Mapper共享同一份InputSplit,这就意味着,对InputSplit的数据读必须线程安全。为此,MultithreadedMapper引入了内部类SubMapRecordReader,SubMapRecordWriter,SubMapStatusReporter,分别继承自RecordReader,RecordWriter和StatusReporter,它们通过互斥访问MultithreadedMapper的Mapper.Context,实现了对同一份InputSplit的线程安全访问,为Mapper提供所需的Context。这些类的实现方法都很简单。
我们来看一下具体的接口,它们都处于包org.apache.hadoop.mapreduce中。
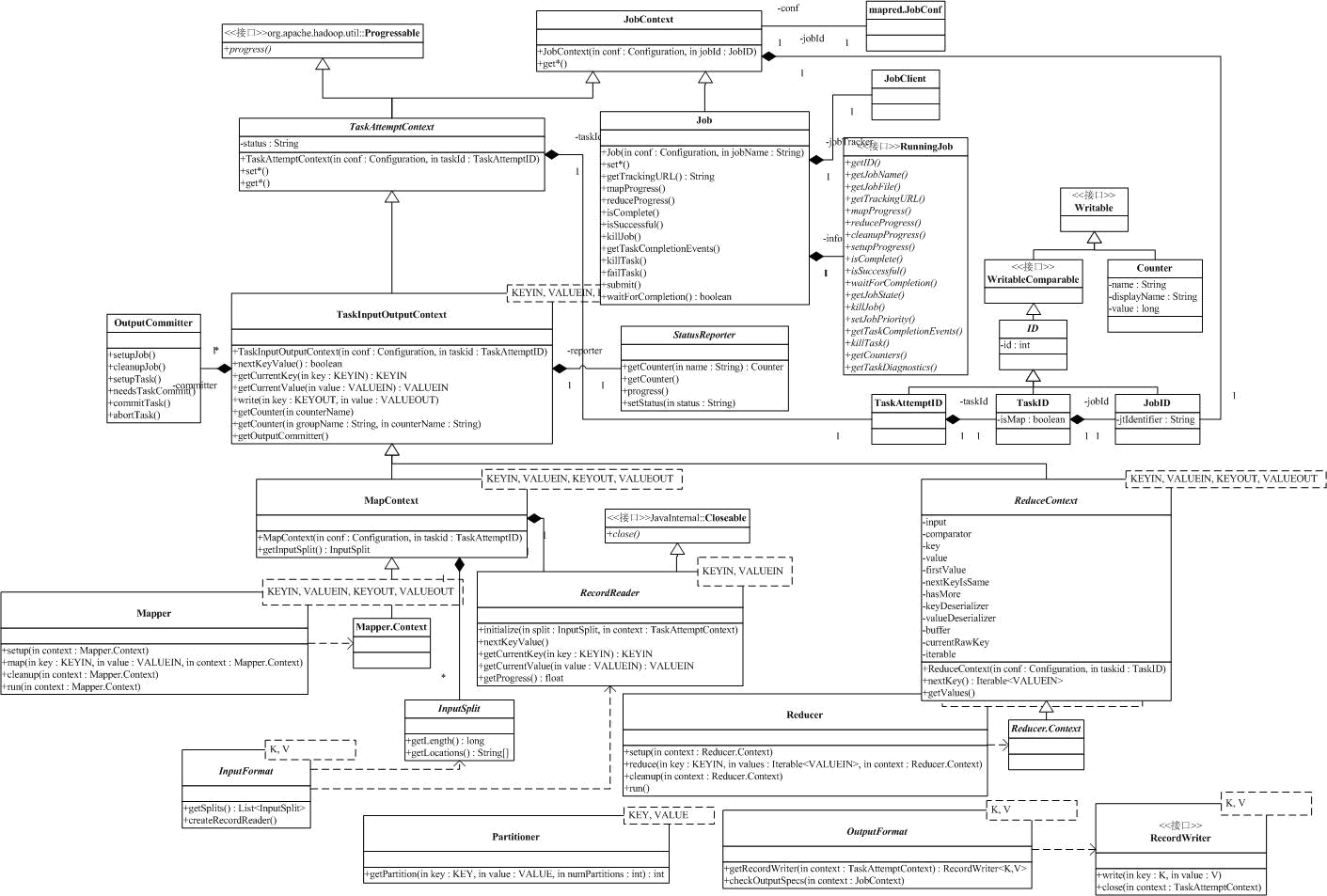
上面的图中,类可以分为4种。右上角的是从Writeable继承的,和Counter(还有CounterGroup和Counters,也在这个包中,并没有出现在上面的图里)和ID相关的类,它们保持MapReduce过程中需要的一些计数器和标识;中间大部分是和Context相关的*Context类,它为Mapper和Reducer提供了相关的上下文;关于Map和Reduce,对应的类是Mapper,Reducer和描述他们的Job(在Hadoop
中一次计算任务称之为一个job,下面的分析中,中文为“作业”,相应的task我们称为“任务”);图中其他类是配合Mapper和Reduce工作的一些辅助类。
如果你熟悉HTTPServlet, 那就能很轻松地理解Hadoop采用的结构,把整个Hadoop看作是容器,那么Mapper和Reduce就是容器里的组件,*Context保存了组件的一些配置信息,同时也是和容器通信的机制。
和ID相关的类我们就不再讨论了。我们先看JobContext,它位于*Context继承树的最上方,为Job提供一些只读的信息,如Job的ID,名称等。下面的信息是MapReduce过程中一些较关键的定制信息:
Job继承自JobContext,提供了一系列的set方法,用于设置Job的一些属性(Job更新属性,JobContext读属性),同时,Job还提供了一些对Job进行控制的方法,如下:
mapProgress:map的进度(0―1.0);
reduceProgress:reduce的进度(0―1.0);
isComplete:作业是否已经完成;
isSuccessful:作业是否成功;
killJob:结束一个在运行中的作业;
getTaskCompletionEvents:得到任务完成的应答(成功/失败);
killTask:结束某一个任务;
|






