|
大家都知道HDFS的架构由NameNode,SecondaryNameNode和DataNodes组成,其源码类图如下图所示:
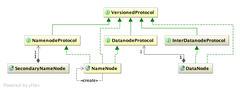
正如上图所示,NameNode和DataNode继承了很多的protocol用于彼此间的通信,其实nameNode还实现了RefreshUserMappingsProtocol和RefreshAuthorizationPolicyProtocol两个协议,用于权限控制和更新;实现了ClientProtocol协议用于和client端通信。
ClientProtocol协议:
通过此协议,client端可以操控目录空间,包括文件流读写等。比如:
getBlockLocations方法可以获取具体某个文件在datanode上的存储位置;
addBlock添加block数据,还有create,delete等操作。
NamenodeProtocol协议:
用于secondNameNode和NameNode节点通信,比如获取namenode上的一些状态信息,比如获取某个DataNode上的blocks的信息以及操控editLog文件,这个文件会记录每次namenode对文件的操作日志,相当于mysql的binlog。关于secondarynamenode节点的作用这里要做个说明,它真正的用途,是用来保存namenode中对HDFS
metadata的信息的备份,并减少namenode重启的时间。为了保证交互速度,HDFS文件系统的metadata是被load到namenode机器的内存中的,并且会将内存中的这些数据保存到磁盘进行持久化存储。为
了保证这个持久化过程不会成为HDFS操作的瓶颈,hadoop采取的方式是:没有对任何一次的当前文件系统的snapshot进行持久化,对HDFS最
近一段时间的操作list会被保存到namenode中的一个叫Editlog的文件中去。当重启namenode时,除了
load fsImage意外,还会对这个EditLog文件中 记录的HDFS操作进行replay,以恢复HDFS重启之前的最终状态。
而SecondaryNameNode,会周期性的将EditLog中记录的对HDFS的操作合并到一个checkpoint中,然后清空
EditLog。所以namenode的重启就会Load最新的一个checkpoint,并replay EditLog中
记录的hdfs操作,由于EditLog中记录的是从 上一次checkpoint以后到现在的操作列表,所以就会比较小。如果没有snn的这个周期性的合并过程,那么当每次重启namenode的时候,就会
花费很长的时间。而这样周期性的合并就能减少重启的时间。同时也能保证HDFS系统的完整性。
DatanodeProtocol协议:
用于DataNode和NameNode节点的通信,主要的通信接口如下:
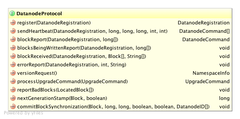
可以看出来每个DataNode起来之后要调用rigister方法通知NameNode更新它,然后通过sendHeartBeat信息告诉NameNode
它还健康的活着和一些其他信息,当然namenode也可以返回一些结果告诉Datanode删除或者移动数据。此外还有很多交互接口
InterDatanodeProtocol协议:
该协议用于Datanode节点之间的互相通信。比如获取具体一个block的metadata信息或者是执行数据恢复迁移etc
此外DataNode还实现了ClientDatanodeProtocol协议用于和client交互通信。比如block获取,block数据恢复和block路径信息。从这里可以看出client提交数据的时候是向namenode发出请求而非向datanode发送存储数据的请求。
了解了NameNode的一些协议之后再来看看NameNode的属性:
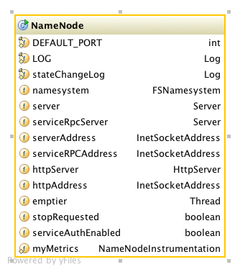
看看几个重要的属性:
serviceRpcServer用于和secondaryNameNode,DataNode之间进行RPC通信;
server用于和client端进行RPC通信;
httpServer就是我们的本地启动服务器。
NameNode在初始化的时候还会启动一个emptier线程用于定期的删除当前回收站的文件。定期时间可以在配置文件中配置fs.trash.interval参数,假如0的话就相当于回收站功能是无效的
NameNode节点初始化的工作就是先启动服务器httpServer,然后启动namenode对客户端的RPC
server ,接着启动serviceRpcServer,然后启动回收站后台线程emptier
接下来重点看一下namesystem参数,namesystem相当于所有DataNode的记事本,主要记录了以下信息:
// Mapping: 数据块 -> { inode节点, datanode列表, self ref }
//主要用于记录每个block存储的datanode节点和对应的inode节点信息
//也就是存储了block的meta信息 |
// Updated only in response to client-sent information.
02.//
03.final BlocksMap blocksMap = new BlocksMap(DEFAULT_INITIAL_MAP_CAPACITY,
04. DEFAULT_MAP_LOAD_FACTOR);
|
属性datanodeMap:
NavigableMap<String, DatanodeDescriptor> datanodeMap =
02. new TreeMap<String, DatanodeDescriptor>();
|
这个treemap存储了每个DataNode对应的元信息;
属性heartbeats用于heartbeat线程监控使用:
ArrayList<DatanodeDescriptor> heartbeats = new ArrayList<DatanodeDescriptor>();记录的是存活的datanode节点信息
02.
03.private Map<String, Collection<Block>> recentInvalidateSets =new TreeMap<String, Collection<Block>>();
//无用block列表
|
假如现在要获取某个datanode上的n个节点的话,先要去datanodeMap中获取DatanodeDescriptor信息,然后获取BlockInfo信息
接着blocksMap中获取block存储的datanode节点id,当然假如这个block在recentInvalidateSets列表中那就要过滤掉。
属性dir
//
02.// Stores the correct file name hierarchy
03.//这个文件中存储了每个文件名对应的位置也就是命名空间
04.//
05.public FSDirectory dir;
|
接下来我们要关注一下FSNamesystem的初始化过程:
1.读取和设置conf文件中的参数
2.将FSNamesystem注册到MBean以便JMS操作和监控
3.加载本地映象文件
4.启动HeartbeatMonitor,ReplicationMonitor等线程
HeartbeatMonitor线程一直运行,它会每间隔heartbeatRecheckInterval时间就去检查所有的datanode节点是否alive
while (!allAlive) {
03. boolean foundDead = false;
04. DatanodeID nodeID = null;
05.
06. // 在datanode节点列表中查找第一个dead了的
07.
08. synchronized(heartbeats) {
09. for (Iterator<DatanodeDescriptor> it = heartbeats.iterator();
10. it.hasNext();) {
11. DatanodeDescriptor nodeInfo = it.next();
12. if (isDatanodeDead(nodeInfo)) {//datanode的meta信息中上次更新时间超过一定阀值
13. foundDead = true;
14. nodeID = nodeInfo;
15. break;
16. }
17. }
18. }
19.
20. //移出已经死了的节点
21. if (foundDead) {
22. synchronized (this) {
23. synchronized(heartbeats) {
24. synchronized (datanodeMap) {
25. DatanodeDescriptor nodeInfo = null;
26. try {
27. nodeInfo = getDatanode(nodeID);
28. } catch (IOException e) {
29. nodeInfo = null;
30. }
31. if (nodeInfo != null && isDatanodeDead(nodeInfo)) {
32. NameNode.stateChangeLog.info("BLOCK* NameSystem.heartbeatCheck: "
33. + "lost heartbeat from " + nodeInfo.getName());
34. removeDatanode(nodeInfo);
35. }
36. }
37. }
38. }
39. }
40. allAlive = !foundDead;
41. }
42.移出操作过程是这样的:
43.//从heartbeats中移出
44. synchronized (heartbeats) {
45. if (nodeInfo.isAlive) {
46. updateStats(nodeInfo, false);
47. heartbeats.remove(nodeInfo);
48. nodeInfo.isAlive = false;
49. }
50. }
51.//删除该node对应的block信息
52. for (Iterator<Block> it = nodeInfo.getBlockIterator(); it.hasNext();) {
53. removeStoredBlock(it.next(), nodeInfo);
54. }
55. unprotectedRemoveDatanode(nodeInfo);
56.//将其从拓扑结构中移出
57. clusterMap.remove(nodeInfo);
|
ReplicationMonitor线程负责数据块的多个备份和监控工作
它负责将需要多个备份的block加入PendingReplicationBlocks中并用一个线程监控它在这个map里面的存活时间,过期了就将其删除。这样在DataNode节点启动服务的时候可以扫描这个列表完成复制备份工作.
|






