|
ժҪ��Spark��ǿ��ĵ��������ܣ����ڴ����ݼ�������ƥ�С�Cassandra���������ʽ�洢NoSQL����д��������ѷ���֡��Ա��ڡ��ʵס������������ʵ��ʵ��������Ҵ���һ����Spark��Cassandra��ɵĴ����ݷ���ƽ̨��
������Դ���Ķ��Ĺ����б�����һ�ַdz���˼άģʽ������Ŭ��ȥѰ��һ���ᴩȫ�ֵ����������ڱ��߿�����Spark�е�����������������ݵĴ����ڷֲ�ʽ���㻷�����Ǹ�Ч�����ҿɿ��ġ�
�ڶ�Spark�ڲ�ʵ������һ���˽�֮��Ȼϣ������Ӧ�õ�ʵ�ʵĹ���ʵ���У���ʱ������������µ���ս������ѡȡ�ĸ���Ϊ���ݲֿ⣬��HBase��MongoDB����Cassandra������һ��ѡ��֮����ʵ�����̻��������������벻�������⡣
Ҫ����ٵĽ�����������߹�����������ϵ�����⣬����Ҫ�߱��൱��ȵ�Linux֪ʶ��ǡ��֮ǰ������ʹ��Linux�ľ����ڴ����������л����Գ��ʹ�á�
���߲��ţ���������һЩ���⣬���������������ͬ������
1. Cassandra
NoSQL���ݿ��ѡ��֮ʹ��Ŀǰ�������н�150����NoSQL���ݿ⣬�������ô���ӵĶ�����ѡ���ʺ�ҵ����ٮٮ�ߣ�ʵ�����¡�
�õ��Ǿ���������ɸѡ����ұȽϿ϶��ļ���NoSQL���ݿ�ֱ���HBase��MongoDB��Cassandra��
Cassandra����Щ��������ס�˴����Ŀ�����Ա�أ��������һ�����Եķ�����
1.1 �߿ɿ���
Cassandra����gossip��Ϊ��Ⱥ�н���ͨ��Э�飬��Э��������Ⱥ�еĽڵ㶼����ͬ�ȵ�λ��û������֮�֣����ʹ����һ�ڵ���˳������ᵼ��������ȺʧЧ��
Cassandra��HBase���ǽ����Google BigTable��˼���������Լ���ϵͳ����Cassandra��һ��Ҫ�Ĵ��¾��ǽ�ԭ���������ļ������ܹ���p2p(peer
to peer)������NoSQL��
P2P��һ���ص����ȥ���Ļ�����Ⱥ�е����нڵ�����ͬ�ȵ�λ���⼫������˵����ڵ��˳���ʹ������Ⱥ���ܹ����Ŀ��ܡ�
��֮�γɶԱȵ���HBase������Master/Slave�ķ�ʽ����ʹ��ڵ���ʧЧ�Ŀ��ܡ�
1.2 �߿�����
����ʱ������ƣ���Ⱥ��ԭ�еĹ�ģ�����Դ洢�����ӵ����ݣ���ʱ����ϵͳ���ݡ�Cassandra�����������dz�����ʵ�������µĽڵ㵽���м�Ⱥ��������
1.3 ����һ����
�ֲ�ʽ�洢ϵͳ��Ҫ����CAP�������⣬�κ�һ���ֲ�ʽ�洢ϵͳ������ͬʱ����һ����(consistency)��������(availability)�ͷ����ݴ���(partition
tolerance)��
Cassandra�����ȱ�֤AP���������Ժͷ����ݴ��ԡ�
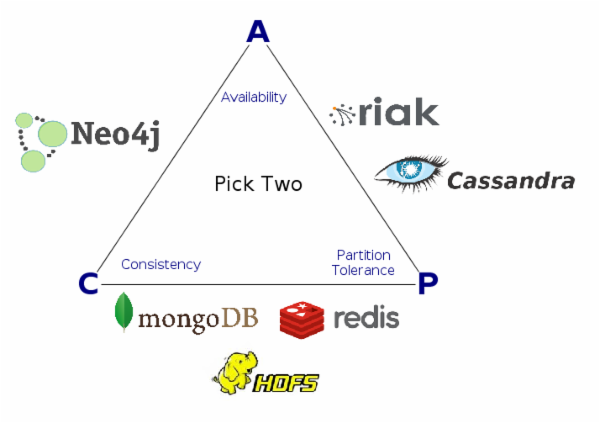
CassandraΪд�����Ͷ������ṩ�˲�ͬ�����һ����ѡ���û����Ը��ݾ����Ӧ�ó�����ѡ��ͬ��һ���Լ���
1.4 ��Чд����
д������dz���Ч�������ʵʱ���ݷdz����Ӧ�ó�����Cassandra����һ�������ɼ������ơ�
���ݶ�ȡ������Ҫ�����������
1.����ǵ�����ȡ��ָ���˼�ֵ����ܿ�ķ��ز�ѯ�����
2.����Ƿ�Χ��ѯ�����ڲ�ѯ��Ŀ����ܴ洢�ڶ���ڵ��ϣ������Ҫ�Զ���ڵ���в�ѯ�����Է����ٶȻ����
3.��ȡȫ�����ݣ��dz���Ч��
1.5 �ṹ���洢
Cassandra��һ�������е����ݿ⣬����Щ��RDBMS����ת�����Ŀ�����Ա��˵����ѧϰ�������ƽ����
Cassandraͬʱ�ṩ�˽�Ϊ�Ѻ�CQL���ԣ���SQL������ƶȺܸߡ�
1.6 ����
��ϵͳά���ĽǶ���˵������Cassandra�ĶԵ�ϵͳ�ܹ���ʹ��ά�����������С������ӽڵ㣬ɾ���ڵ㣬�����������µ��������ģ��������趼�dz��ļ����ˡ�
2. Cassandra����ģ��
2.1 ������ѯ
2.1.1 ����������ѯ
�ڽ���������Ϣ���ݿ��ʱ���Ը�������֤idΪ��������ѯ��ʱ��Ҳֻ������֤Ϊ�ؼ��ֽ��в�ѯ�����������Ƴ�Ϊ��
create table person (
userid text primary key,
fname text,
lname text,
age int,
gender int); |
Primary key�еĵ�һ����������ΪPartition key��Ҳ����˵�������partition
key��hash�����������¼�洢����һ��partition�У���������ɵ�����µ�һ�����������е�hash���ȫ������ͬһ��������ᵼ�¸÷������ݱ�������
�����һ����İ취��ͨ����Ϸ�����(compsoite key)��ʹ�����ݾ����ܵľ��ȷֲ��������ڵ��ϡ�
������˵�����ܽ�(userid,fname)����Ϊ������������ô��Ӧ�ı�����������д��
create table person (
userid text,
fname text,
lname text,
gender int,
age int,
primary key((userid,fname),lname);
) with clustering order by (lname desc); |
������һ��primary key((userid, fname),lname)�ĺ��壺
1.����(userid,fname)��Ϊ��Ϸ�����(composite
partition key)
2.lname�Ǿۼ���(clustering column)
3.((userid,fname),lname)һ���Ϊ��������(composite
primary key)
2.1.2 ������������ѯ
���Ҫ��ѯ��person�о�����ͬ��first name����Ա����ô�ͱ������fname������Ӧ�������������ѯ�ٶȻ�dz�������
Create index on person(fname);
CassandraĿǰֻ�ܶԱ��е�ijһ�н����������������Զ��н�������������
2.2 ���������ѯ
Cassandra����֧�ֹ�����ѯ��Ҳ��֧�ַ���;ۺϲ�����
���Dz��Ǿ�˵��Cassandraֻ�ǿ���ȥ������ʵ���������ʵ�������أ�����Ȼ��No,ֻҪ�㲻�����RDBMS��˼·�������������ˡ�
�������������ű���һ�ű�(Departmentt)��¼�˹�˾������Ϣ����һ�ű�(employee)��¼�˹�˾Ա����Ϣ����Ȼÿһ��Ա���ض��й����IJ��ţ������֪��ÿһ������ӵ�е�����Ա�����������RDBMS�Ļ���SQL������д�ɣ�
select * from employee e , department d where e.depId = d.depId; |
Ҫ��Cassandra���ﵽͬ����Ч�����ͱ�����employee����department��֮�⣬�ٴ���һ�Ŷ���ı�(dept_empl)����¼ÿһ������ӵ�е�Ա����Ϣ��
Create table dept_empl (
deptId text, |
��������������Ѿ������ˣ���Cassandra��ͨ������������ʵ�ָ�Ч�IJ�ѯЧ������������ѯת��Ϊ��һ�ı�������
2.3 ����;ۺ�
��RDBMS�г�����group by��max��min��Cassandra���Dz����ڵġ�
����뽫������Ա��Ϣ�����ս��з�������Ļ����Ǹ���δ�������ģ���أ�
Create table fname_person (
fname text,
userId text,
primary key(fname)
); |
2.4 �Ӳ�ѯ
Cassandra��֧���Ӳ�ѯ����ͼչʾ��һ����MySQL�е��Ӳ�ѯ���ӣ�
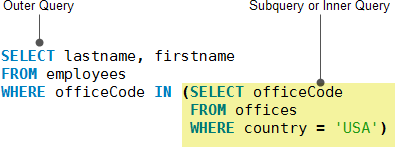
Ҫ��Cassandra��ʵ�֣�����ͨ�����Ӷ���ı����洢������Ϣ��
Create table office_empl (
officeCode text,
country text,
lastname text,
firstname,
primary key(officeCode,country));
create index on office_empl(country); |
2.5 ��
�ܵ���˵���ڽ���Cassandra����ģ�͵�ʱ��Ҫ������ݵĶ�ȡ��������ܵ�������Ȼ�����÷���ʽ����Ʒ�ʽ��ʵ�ֿ��ٵĶ�ȡ��ԭ������Կռ�����ȡʱ�䡣
3. ����Sparkǿ��Cassandra��ʵʱ��������
��Cassandra����ģ��һ���У�������ͨ����������ͷ���ʽ������ﵽ���ٸ�Ч�IJ�ѯЧ����
������Դ洢��cassandra����Ҫ����Ϊ���ӵ�ʵʱ�Է��������Ļ���ʹ��ԭ�еļ�����ʵ��Ŀ�꣬��ô����ͨ����Spark���ϣ�����Spark����һ�����ٸ�Ч�ķ���ƽ̨��ʵ�ָ��ӵ����ݷ������ܡ�
3.1 ����ܹ�

����spark-cassandra-connector����Cassandra����ȡ�洢��Cassandra�е����ݣ�Ȼ��Ϳ���ʹ��Spark
RDD�е�֧��API�������ݽ��и��ֲ�����
3.2 Spark-cassandra-connector
��Spark������datastax�ṩ��spark-cassandra-connector������Cassandra���ݿ�����Ϊ��һ�ַ�ʽ��
Ŀǰspark-cassandra-connector 1.1.0-alpha3֧�ֵ�Spark��Cassandra�汾���£�
1.Spark 1.1
2.Cassandra 2.x
�������sbt������scala����Ļ���ֻ��Ҫ��build.sbt�м����������ݼ�����sbt�Զ���������Ҫ��spark-cassandra-connector����
�����е�ʱ����github.com/datastax/spark-cassandra-connector�ٷ�վ���ϵ��ĵ���һ��ȷ��Ҫ��ȷ��֪������Щ�汾������sbt�Զ����صĻ�������ͨ��maven�IJֿ����鿴������鿴��ַ��
http://mvnrepository.com/artifact/com.datastax.spark
3.2.1 driver������
ʹ��spark-cassandra-connector��ʱ����Ҫ�༭һЩ����������ָ��Cassandra���ݿ�ĵ�ַ��ÿ������ȡ�����У�һ���߳��ܹ���ȡ�����еȡ�
��Щ����������Ӳ�Ե�д���ڳ����У���
val conf = new SparkConf()
2.conf.set(��spark.cassandra.connection.host��, cassandra_server_addr)
3.conf.set(��spark.cassandra.auth.username��, ��cassandra��)
4.conf.set(��spark.cassandra.auth.password��,��cassandra��)
|
Ӳ����ķ�ʽ�Ƿ���������ʵ��Щ���ò�����ȫ����д��spark-defaults.conf�У���ô���������ÿ���д��
spark.cassandra.connection.host 192.168.6.201
spark.cassandra.auth.username cassandra
spark.cassandra.auth.password cassandra |
3.2.2 �������İ汾����
sbt���Զ�����spark-cassandra-connector�������Ŀ��ļ������ڳ������β�����ֳ��κ����⡣
����ִ�н�����ͻ����ֳ��������������spark-cassandra-connector֮�Ҫ������Щ�ļ��أ��������Ҫ���»ص�maven�汾����ȥ��spark-cassandra-connector�������ˡ�
��������˵spark-cassandra-connector�����������⼸����
?cassandra-clientutil
?cassandra-driver-core
?cassandra-all
|
����һ�ֽ���İ취���Dz鿴$HOME/.ivy2Ŀ¼����Щ������°汾�Ƕ���
find ~/.ivy2 -name ��cassandra*.jar�� |
ȡ���İ汾�ż��ɣ���alpha3���ԣ����������Ŀ⼰��汾����
com.datastax.spark/spark-cassandra-connector_2.10/jars/spark-cassandra-connector_2.10-1.1.0-alpha3.jar
org.apache.cassandra/cassandra-thrift/jars/cassandra-thrift-2.1.0.jar
org.apache.thrift/libthrift/jars/libthrift-0.9.1.jar
org.apache.cassandra/cassandra-clientutil/jars/cassandra-clientutil-2.1.0.jar
com.datastax.cassandra/cassandra-driver-core/jars/cassandra-driver-core-2.1.0.jar
io.netty/netty/bundles/netty-3.9.0.Final.jar
com.codahale.metrics/metrics-core/bundles/metrics-core-3.0.2.jar
org.slf4j/slf4j-api/jars/slf4j-api-1.7.7.jar
org.apache.commons/commons-lang3/jars/commons-lang3-3.3.2.jar
org.joda/joda-convert/jars/joda-convert-1.2.jar
joda-time/joda-time/jars/joda-time-2.3.jar
org.apache.cassandra/cassandra-all/jars/cassandra-all-2.1.0.jar
org.slf4j/slf4j-log4j12/jars/slf4j-log4j12-1.7.2.jar |
3.3 Spark������
����˳��ͨ������֮������Spark�Ͻ��в��ԣ���ô��Ҫ����������
3.3.1 spark-default.env
Spark-defaults.conf�����÷�ΧҪ��������༭driver���ڻ����ϵ�spark-defaults.conf�����ļ���Ӱ�쵽driver���ύ���е�application����ר��Ϊ��application�ṩ������Դ��executor����������
ֻ��Ҫ��driver���ڵĻ����ϱ༭���ļ�������Ҫ��worker��master�����еĻ����ϱ༭���ļ�
�ٸ�ʵ�ʵ�����
spark.executor.extraJavaOptions -XX:MaxPermSize=896m
spark.executor.memory 5g
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.cores.max 32
spark.shuffle.manager SORT
spark.driver.memory 2g |
�������ñ�ʾΪ��application�ṩ������Դ��executor����ʱ,
heap memory��Ҫ��5g��
������Ҫ����ע����ǣ����worker�ڼ���cluster��ʱ�������Լ����ڵĻ���ֻ��4g�ڴ棬��ôΪ������application����executor�ǣ���worker�����ṩ�κ���Դ����Ϊ4g<5g����������͵���Դ����
3.3.2 spark-env.sh
Spark-env.sh������Ҫ����ָ��ip��ַ��������е���master������Ҫָ��SPARK_MASTER_IP�����������driver��worker����Ҫָ��SPARK_LOCAL_IP��Ҫ�ͱ�����IP��ַһ�£������������ˡ�
���þ�������
export SPARK_MASTER_IP=127.0.0.1
export SPARK_LOCAL_IP=127.0.0.1 |
3.3.3 ����Spark��Ⱥ
��һ������master
$SPARK_HOME/sbin/start-master.sh |
�ڶ�������worker
$SPARK_HOME/bin/spark-class org.apache.spark.deploy.worker.Worker spark://master:7077 |
��master�滻��MASTERʵ�����е�ip��ַ
�������һ̨���������ж��worker(��Ҫ�����ڲ���Ŀ��),��ô�������ڶ����������workerʱ��Ҫָ����webui-port�����ݣ�����ᱨ�˿��Ѿ���ռ�õĴ���,�����ڶ����õ���8083������������8084���������ơ�
$SPARK_HOME/bin/spark-class org.apache.spark.deploy.worker.Worker spark://master:7077
�Cwebui-port 8083 |
��������worker�ķ�ʽֻ��Ϊ�˲������������㣬����ķ�ʽ����$SPARK_HOME/sbin/start-slaves.sh���������worker�������漰��ssh�����ã��Ƚ��鷳��������ͼ�İ취��
��$SPARK_HOME/sbin/start-slave.sh������workerʱ��һ��Ĭ�ϵ�ǰ�ᣬ����ÿ̨������$SPARK_HOME������ͬһ��Ŀ¼��
ע�⣺
ʹ����ͬ���û������û���������Master��Worker������Executor��������ᱨ�����������Ĵ���
����ʵ�ʵ�ʹ�õ��У�������no route to host���Ĵ�����Ϣ�����������Ϊ����û�����úã���������ԭ���Ų�֮��Ȼ��ʶ���п���ʹ���˲�ͬ���û������û��飬ʹ����ͬ���û���/�û���֮��������ʧ��
3.3.4 Spark-submit
spark��Ⱥ��������֮����������������ύapplication����Ⱥ�����ˡ�
Spark-submit����Spark application���ύ�����У���ʹ�����ָ���ʱ����������������ָ��Ӧ������Ҫ����������
���Ȳ鿴һ��spark-submit�İ����ļ�
$SPARK_HOME/bin/submit --help |
�м���ѡ���������ָ���������Ŀ⣬�ֱ�Ϊ��
1.--driver-class-path driver�������İ��������֮����ð��(:)�ָ�
2.--jars driver��executor����Ҫ�İ��������֮���ö���(,)�ָ�
Ϊ�˼��������ͨ����jars��ָ������������ָ������
$SPARK_HOME/bin/spark-submit �Cclass Ӧ�ó�������� \
--master spark://master:7077 \
--jars �����Ŀ��ļ� \
sparkӦ�ó����jar�� |
3.3.5 RDD����ʹ�õ�һЩ����
1��collect
������ݼ��ر��ҪóȻʹ��collect����Ϊcollect�Ὣ������ͳͳ���ռ����ص�driver�ڵ㣬�����dz�������driver����ڴ治�㣬�����˳�
2��repartition
�������ṩ��core��Ŀ�����ǰ���£����ݼ��ķ�����ĿԽ����ζ�ż���һ��������ʱ��Խ�࣬��Ϊ�м��ͨѶ�ɱ��ϴ����ݼ��ķ���ԽС��ͨ�ſ���С�����¼���������ʱ��Խ�̣������ݷ���ԽС��ζ���ڴ�ѹ��Խ��
����Ϊÿ��spark application�ṩ�����core��Ŀ��32,��ô��partition
number����Ϊcore number������������ȽϺ��ʣ���parition numberΪ64��96��
3��/tmpĿ¼����
����Spark�ڼ����ʱ��Ὣ�м����洢��/tmpĿ¼����Ŀǰlinux�ֶ�֧��tmpfs����ʵ˵���˾��ǽ�/tmpĿ¼���ص��ڴ浱�С�
��ô����ʹ���һ�����⣬�м������ർ��/tmpĿ¼д�����������´���
No Space Left on the device |
����취�������tmpĿ¼������tmpfs,��/etc/fstab�������archlinux������/etc/fstab�Dz����ģ�����Ҫִ������ָ�
3.4 Cassandra�������Ż�
3.4.1 ���ṹ���
Cassandra���ṹ��Ƶ�һ����Ҫԭ�����ȸ����Ҫ�Դ洢����������Щ������Ȼ��ſ�ʼ��Ʊ��ṹ���磺
1.ֻ�Ա��������ӣ���ѯ����
2.�Ա���Ҫ�������ӣ��ģ���ѯ
3.�Ա��������Ӻ��IJ���
һ����˵�����Cassandra��ij�ž���ı����С����ӣ��ģ���ѯ��������һ���õ�ѡ����л��漰��Ч�ʼ�һ���Ե�������⡣
Cassandra�Ƚ��ʺ������ӣ���ѯ���ֲ���ģʽ��������ģʽ�£���Ҫ�ȸ����Ҫ����Щ��ѯȻ������������ṹ��
�����Cassandra��primary key������ֵ�������������Ƴ���Ч��ѯ�ı��ṹ��
create test ( k int, v int , primary key(k,v)) |
����������primary key��(k,v)��ɣ�����k��partition
key,��v��clustering columns�����k��ͬ����ô��Щ��¼�������洢����ʵ�Ǵ洢��ͬһ���У���Cassandra�г����ἰ��wide
rows.
�����������֮�Ϳ��Խ��з�Χ��ѯ��
select * from test where k = ? and v > ? and v < ? |
��ȻҲ���Զ�k���з�Χ��ѯ������Ҫ��token���У���һ�������ķ�Χ��ѯ��������������뵽��
select * from test where token(k) > ? and token(k) < ? |
Cassandra����Զ��������Dz�֧�ַ�Χ��ѯ�ģ�һ�е�һ�ж�������������⡣
3.4.2 ��������
Cassandra�����ò�����ܶ࣬����������˵��Ҫ�����ڶ��������ļ�������������⡣
1.cassandra.yaml Cassandraϵͳ�����в���
2.cassandra-env.sh JVM�����
��cassandra-env.sh�����JVM������
JVM_OPTS="$JVM_OPTS -XX:+UseParNewGC"
JVM_OPTS="$JVM_OPTS -XX:+UseConcMarkSweepGC"
JVM_OPTS="$JVM_OPTS -XX:+CMSParallelRemarkEnabled"
JVM_OPTS="$JVM_OPTS -XX:SurvivorRatio=8"
JVM_OPTS="$JVM_OPTS -XX:MaxTenuringThreshold=1"
JVM_OPTS="$JVM_OPTS -XX:CMSInitiatingOccupancyFraction=80"
JVM_OPTS="$JVM_OPTS -XX:+UseCMSInitiatingOccupancyOnly"
JVM_OPTS="$JVM_OPTS -XX:+UseTLAB"
JVM_OPTS="$JVM_OPTS -XX:ParallelCMSThreads=1"
JVM_OPTS="$JVM_OPTS -XX:+CMSIncrementalMode"
JVM_OPTS="$JVM_OPTS -XX:+CMSIncrementalPacing"
JVM_OPTS="$JVM_OPTS -XX:CMSIncrementalDutyCycleMin=0"
JVM_OPTS="$JVM_OPTS -XX:CMSIncrementalDutyCycle=10" |
���nodetool�����ӵ�Cassandra�Ļ�����cassandra-env.sh��������������
JVM_OPTS="$JVM_OPTS -Djava.rmi.server.hostname=ipaddress_of_cassandra" |
��cassandra.yaml�У�ע��memtable_total_space_in_mb�����ã���Ҫ����ֵ����ر�������ó�ΪJVM
HEAP��1/4����һ���ȽϺõ�ѡ�������ֵ����̫�ᵼ�²�ͣ��FULL GC����ô�����������Cassandra�����Ͳ������ˡ�
3.4.3 nodetoolʹ��
Cassandra�������ڼ����ͨ��nodetool�����ڲ���һЩ���������
�翴һ�¶�ȡ��������
nodetool -hcassandra_server_address tpstats |
�������cluster��״̬
nodetool -hcassandra_server_address status |
������ݿ���ÿ�����������ж���
nodetool -hcassandra_server_address cfstats |
|






