|
随着互联网技术的发展,数宇信息正在成指数增加,根据Internet Data
Cente:发布的Digital Universe报告显示,在未来8年中所产生的数据量将达到40 ZB,相当于每人产生5200
G的数据,如何高效地计算和存储这些海量数据成为互联网企业所要而对的挑战。传统的大规模数据处理大多采用并行计算、网格计算、分布式高性能计算等,耗费昂贵的存储与
计算资源,而且对于大规模数据计算任务的有效分配和数据合理分割都需要复杂的编程才可以实现。基于Hadoop分布式云平台的出现成为解决此类问题的良好
途径,本文将在综述Hadoop核心技术:HDFS和MapReduce基础上,利用VMware虚拟机搭建一个基于Hadoop分布式技术的高效、易扩
展的云数据计算与存储平台,并通过实验验证分布式计算与存储的优势。
1、Hadoop及其相关技术
Hadoop是并行技术、分布式技术和网格计算技术发展的产物,是一种为适应大规模数据计算和存储而发展起来的模型架构。Hadoop是Apache
公司旗下的一个分布式计算和存储的框架平台,能够高效存储大量数据,而且可以编写分布式应用程序来分析计算海量数据。Hadoop可在大量廉价硬件设备集
群中运行程序,为各应用程序提供可靠稳定的接口来构建高扩展性和高可靠行的分布式系统。Hadoop具有成本低廉、可靠性高、容错性高、扩展性强、效率
高、可移植性强、免费开源的优点。
Hadoop集群为典型Master/Slave、结构,基于Hadoop的云计算与存储架构模型如图1所示。
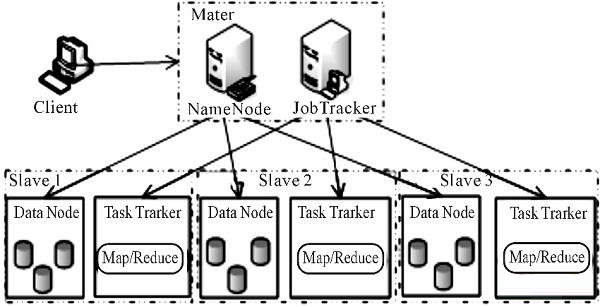
图 1 基于Hadoop的云计算与存储架构模型
1.1 Hadoop分布式文件系统HDFS
HDFS是一个运行在大量廉价硬件之上的分布式文件系统,它是Hadoop平台的底层文件存储系统,主要负责数据的管理和存储,对于大文件的数据访问
具有良好性能。HDFS与传统的分布式文件系统相似,但是也存在着一定的不同,具有硬件故障、大数据集、简单一致性、数据流式访问、移动计算的便捷性等特
点。HDFS的工作流程及架构如图2所示。
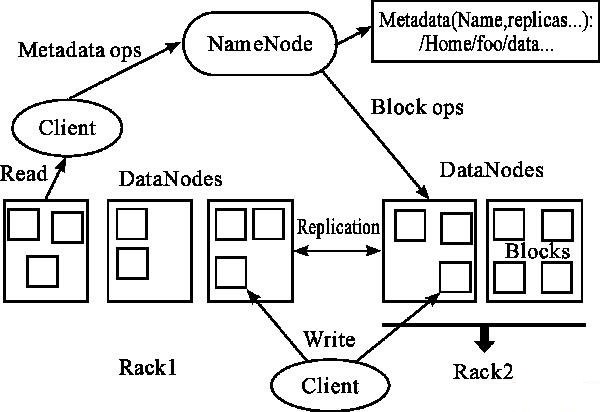
图 2 HDFS的工作流程及架构结构
一个HDFS集群中有一个NameNode和多个DataNode。如图2所示,NameNode是中心服务器,
它用来管理文件系统的元数据信息以及客户端对文件的读写访问,维护文件系统树及其子节点下的所有文件和目录。这些信息以编辑日志文件(Editlog)和
命名空间镜像文件(FsImage)的形式保存在磁盘中。NameNode还暂时记录着各个块(Block)所在的DataNode信息。其功能主要有:
管理元数据和文件块;简化元数据更新操作;监听和处理请求。
DataNode通常在集群中一个节点一个,用来存储、检索数据块,响应NameNode下达的创建、复制、删除数据块的命令,并定时向
NameNode发送“心跳”,通过心跳信息向NameNode汇报自己的负载情况,同时通过心跳信息来接受NameNode下达的指令信
息;NameNode通过“心跳”信息来确定DataNode是否失效,它定时ping每个DataNode,如果在规定的时间内没有收到
DataNode的反馈就认为此节点失效,然后对整个系统进行负载调整。在HDFS中,每个文件划分成一个或多个blocks(数据块)分散存储在不同的
DataNode中,DataNode之间进行数据块的相互复制而形成多个备份。
1.2 Map/Reduce编程框架
Map/Reduce是Hadoop用来处理云计算中海量数据的编程框架,简单易用,程序员在不必了解底层实现细节的基础上便可写出程序来处理海量数据。利用Map/Reduce技术可以在数千部服务器上同时开展广告业务和网络搜索等任务,并可以方便地处理TB、PB,甚至是EB级的数据。
Map/Reduce框架由JobTracker和TaskTracker组成。JobTracker只有一个,它是主节点,负责任务的分配和调度,
管理着几个TaskTracker;TaskTracker一个节点一个,用来接受并处理JobTracker发来的任务。
MapReduce针对集群中的大型数据集进行分布式运算,它的整个框架由Map和Reduce函数组成,处理数据时先执行map再执行
reduce。具体执行过程如图3所示。执行map函数前先对输入数据进行分片;然后将不同的片段分配给不同的map执行,map函数处理之后以
(key,value)的形式输出;在进入reduce阶段前,map函数先将原来的(key,value)分成多组中间的键值对再发给一个
reducer进行处理;最后reduce函数合并key相同的value,并输出结果到磁盘上。
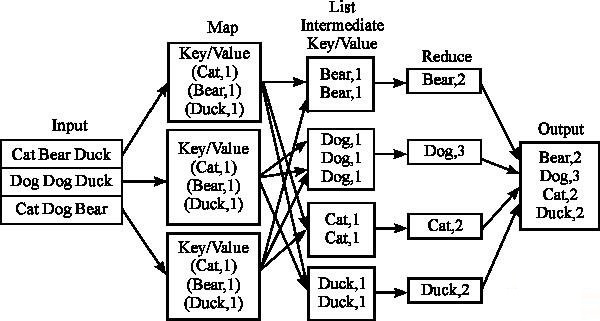
图 3 MapReduce计算过程
2、基于Hadoop的云计算与存储平台设计
目前,多核计算机的广泛使用使其在搭建Hadoop集群系统时,分给各DataNode节点的多个任务会产生对资源的竞争,例如:内存、CPU、输入
输出带宽等,这会导致暂时用不到的资源处于闲置状态,致使一些资源的浪费以及响应时间的延长,资源开销的增加最终会导致系统性能的降低。为解决此问题,本
研究提出一种基于VMware虚拟机和Hadoop相结合的集群环境模型,如图4所示,即在一台计算机中搭建多台虚拟操作系统,此种做法的优点是可以增加
DataNode和TaskTracker节点,而且可以充分利用物理资源,提高运算和存储的效率。
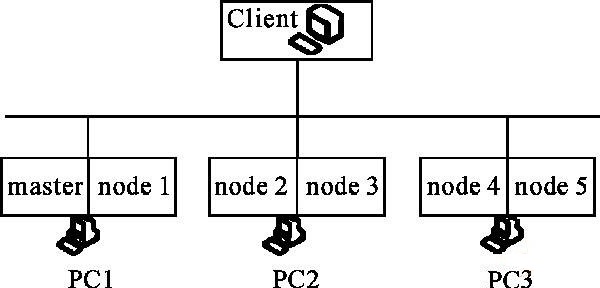
图 4 基于VMware虚拟机和Hadoop结合的模型
3、实验平台搭建
3. 1硬件环境配置
准备3台双核计算机,并分别安装2台VMware虚拟机软件,在虚拟机中装入Linux
OS,从而将3台计算机扩展成为6台计算机,3台计算机具有相同的配置,配置具体如表1所示。

Hadoop集群包括1个NameNode服务器和5个DataNode月及务器,配置信息如表2所示。

3.2 Hadoop环境搭建
Hadoop环境搭建过程为:配置集群hosts列表、安装JAVA JDK系统软件、配置环境变量、生成登陆密钥、创建用户帐号和Hadoop部署目录及数据目录、配置hadoopenv.sh环境变量、配置core-
site. xml、hdfs-site. xml、mapred-site. xml。
配置完毕之后进行格式化文件,命令为:
/opt/modules/hadoop/hadoop-1.0.3/bin/hadoop namenode deformat |
然后启动所有节点,输入命令:startall.sh。通过界而查看集群是否部署成功,首先检查NameNode和DataNode节点是否正常,打
开浏览器输入网址:http: //master: 50070,若Live Nodes有6个,说明全部节点成功启动。然后检查JobTracker和TaskTracker节点,输入网址:http:
//master:50030,若Nodes节点有6个说明节点启动成功。
4、实验内容及结果分析
在部署好的Hadoop云数据计算与存储平台上进行实验来验证基于分布式数据计算和存储的方法在数据计算和存储上存在优势。
1)实验一:运行Hadoop自带的蒙特卡洛求PI程序验证基于Hadoop分布式云计算的高效性。计算任务设为10个,计算量为10的3
、4、5 、6次方。
环境一:单机情况下运行;
环境二:3台物理机搭建的集群系统中运行;
环境三:6台虚拟机搭建的集群系统中运行。集群环境运行日志如图5所示。
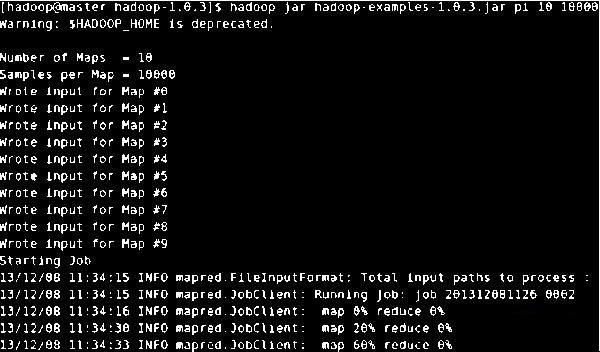
图 5 蒙特卡洛求PI程序运行日志
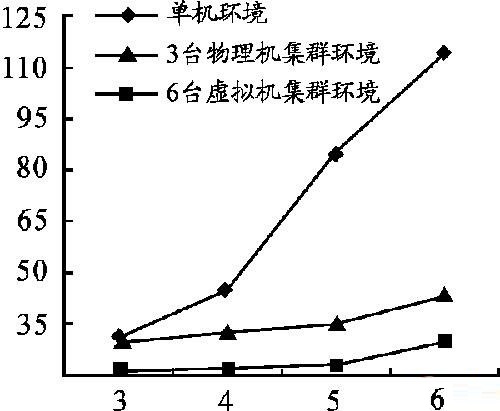
每组实验运行5次求所需时间的平均值,计算执行时间结果如图6所示,纵轴为时间/s,横轴是计算量/次方。从图6中可以看出单机环境下的运算时间远远大于分布式系统下的运算时间,而且集群系统中的节点越多计算速度越快。
2)实验二:通过运行宇符统计程序(wordcounter.jar)测试基于Hadoop分布式云数据读写的高效性来验证其存储性能。有4组数据,大小分别为400MB、600MB、1GB和1.5GB。
本组实验设置Hadoop块大小为16M默认情况下是64 M ) ,冗余备份参数设置为3(默认值),实验环境同实验一,程序运行5次,记录时间并计算平均值,运行日志如图7所示。
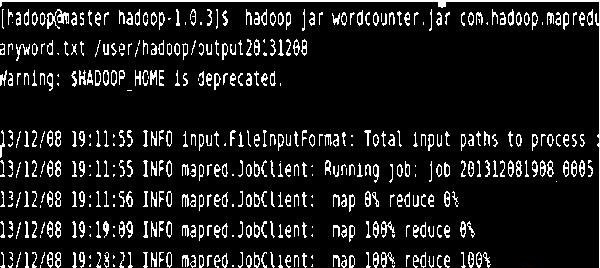
图 7 字符统计程序运行日志
运行结果如图8所示,纵轴为执行时间/s,横轴为数据量/MB。从图8中可以得出单机环境下的数据读写速度明显低于分布式环境下的速度,而且节点越多读写速度越快。
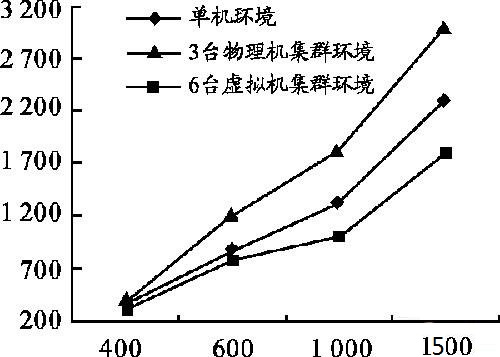
图 8 字符统计程序在3种环境中的性能对比
可以看出,与传统数据计算与读写方式相比,本文提出的在虚拟化环境下搭建的基于Hadoop分布式技术的云计算与存储平台,有效地提高了海量数据分析与读写的速度和效率;而且利用虚拟化技术搭建的集群比物理机集群效率更高,速度更快,从而大大提高了资源的利用率。
5、结束语
本文通过对Hadoop分布式文件系统HDFS、 MapReduce编程框架进行研究,利用VMware虚拟机搭建基于Hadoop的云数据计算与存储平台,并通过实验验证其相对于传统数据处理方式具有
高效、快速的特点,满足云计算领域的相关需求;而且通过应用虚拟化技术来扩展节点数量,既提高了运行效率又提高了硬件资源的利用率,为今后云计算的研究方
向打下了基础。 |






