|
HBase��һ���ֲ�ʽ�ġ������еĿ�Դ���ݿ⣬�ü�����Դ�� Fay Chang
��д��Google���ġ�Bigtable��һ���ṹ�����ݵķֲ�ʽ�洢ϵͳ��������Bigtable������Google�ļ�ϵͳ��File
System�����ṩ�ķֲ�ʽ���ݴ洢һ����HBase��Hadoop֮���ṩ��������Bigtable��������HBase������ʵ����Bigtable
�����ᵽ��ѹ���㷨���ڴ�����Ͳ�¡��������Base��Apache Hadoop�����ݿ⣬�ܹ��Դ��������ṩ�����ʵʱ�Ķ�д���ʡ�HBase��Ŀ���Ǵ洢���������͵����ݡ�HBase�ı��ܹ���ΪMapReduce��
�����������������ͨ��Java API����ȡ���ݣ�Ҳ����ͨ��REST��Avro����Thrift��API�����ʡ�HBase��ͬ��һ��Ĺ�ϵ���ݿ⣬����һ���ʺ��ڷǽṹ�����ݴ洢��
���ݿ⡣��һ����ͬ����HBase�����еĶ����ǻ����е�ģʽ��

HBase ��ͬ��һ��Ĺ�ϵ���ݿ⣬����һ���ʺ��ڷǽṹ�����ݴ洢�����ݿ⡣��ν�ǽṹ�����ݴ洢����˵HBase�ǻ����еĶ����ǻ����е�ģʽ�����������д��
�������ݡ�HBase�ǽ���Map Entry(key & value)��DB Row֮���һ�����ݴ洢��ʽ���е��������������е�Memcache�����������Ǽ�һ��key��Ӧһ��
value����ܿ�����Ҫ�洢������Ե����ݽṹ����û�д�ͳ���ݿ������ô��Ĺ�����ϵ���������ν����ɢ���ݡ�����˵������HBase�еı�������
���Կ�����һ�źܴ�ı���������������Կ��Ը�������ȥ��̬���ӣ���HBase��û�б����֮�������ѯ����ֻ��Ҫ����������ݴ洢��HBase���Ǹ�
column families �Ϳ����ˣ�����Ҫָ�����ľ������ͣ�char,varchar,int,tinyint,text�ȵȡ���������Ҫע��HBase�в������������Ĺ�
�ܡ���hadoopһ����HBaseĿ����Ҫ����������չ��ͨ�������������۵����÷������������Ӽ���ʹ洢������HBase�еı�һ�����������ص㣺
1.��һ���������������У��ϰ�����
2.������:������(��)�Ĵ洢��Ȩ���ƣ���(��)����������
3.ϡ��:����Ϊ��(null)���У�����ռ�ô洢�ռ䣬��ˣ���������Ƶķdz�ϡ�衣
HBase���ŵ㣺
1.�еĿ��Զ�̬���ӣ�������Ϊ�վͲ��洢����,��ʡ�洢�ռ�
2.HBase�Զ��з����ݣ�ʹ�����ݴ洢�Զ�����ˮƽscalability
3.HBase�����ṩ�߲�����д������֧��
HBase��ȱ�㣺
1.����֧��������ѯ��ֻ֧�ְ���Row key����ѯ
2.��ʱ����֧��Master server�Ĺ����л�,��Master崻���,�����洢ϵͳ�ͻ�ҵ�
��ͼ��HBase��Hadoop Ecosystem�е�λ�ã�
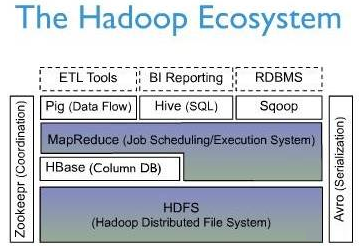
HBaseλ�ڽṹ���洢�㣬Χ��HBase����������HBase��֧�������
1.HDFS���߿ɿ��ĵײ�洢֧��
2.MapReduce�������ܵļ�������
3.Zookeeper���ȶ������failover����
4.Pig&Hive���߲�����֧�֣���������ͳ��
5.Sqoop���ṩRDBMS���ݵ��룬���ڴ�ͳ���ݿ���HBaseǨ��
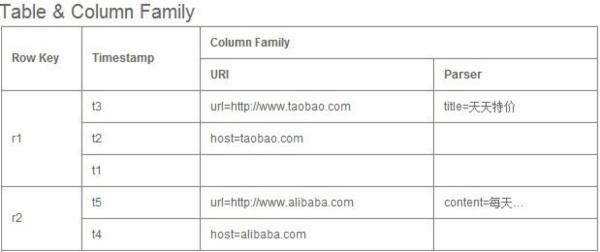
HBase ������ģ��
HBase�Ա�����ʽ�洢���ݡ������к�����ɡ��л���Ϊ���ɸ�����(row family)
1.Row Key�� Table���� �м� Table�м�¼����Row
Key����
2.Timestamp��ÿ�ζ����ݲ�����Ӧ��ʱ�����Ҳ�����ݵ�version
number
3.Column Family���дأ�һ��table��ˮƽ������һ�����߶���дأ��дؿ���������Column��ɣ��д�֧�ֶ�̬��չ������Ԥ�������������ͣ������ƴ洢���û������н�������ת��
Row Key
��nosql���ݿ���һ��,row key������������¼������������HBase table�е��У�ֻ�����ַ�ʽ��
1.ͨ������row key����
2.ͨ��row key��range
3.ȫ��ɨ��
Row key�м� (Row key)�����������ַ���(����� 64KB��ʵ��Ӧ���г���һ��Ϊ 10-100bytes)����HBase�ڲ���row
key����Ϊ�ֽ����顣�洢ʱ�����ݰ���Row key���ֵ���(byte order)����洢�����keyʱ��Ҫ�������洢������ԣ�������һ���ȡ���д洢�ŵ�һ��(λ�������)����Ҫע��ģ��ֵ����int����Ľ��
�� 1,10,100,11,12,13,14,15,16,17,18,19,2,20,21,��,9,91,92,93,94,95,96,97,98,99��
Ҫ�������ε���Ȼ���м�������0������䡣�е�һ�ζ�д��ԭ�Ӳ��� (����һ�ζ�д������)�������ƾ����ܹ�ʹ�û���������������ڶ�ͬһ���н��в������²���ʱ����Ϊ��
����
HBase���е�ÿ���У���������ij�����塣�����DZ���schema��һ����(���в���)��������ʹ�ñ�֮ǰ���塣��������������Ϊǰ������courses:history��courses:math������courses
������塣
���ʿ��ơ����̺��ڴ��ʹ��ͳ�ƶ��������������еġ�ʵ��Ӧ���У������ϵĿ���Ȩ���ܰ������ǹ�����ͬ���͵�Ӧ�ã���������һЩӦ�ÿ��������µ�
�������ݡ�һЩӦ�ÿ��Զ�ȡ�������ݲ������̳е����塢һЩӦ����ֻ����������ݣ�����������Ϊ��˽��ԭ��������������ݣ���
ʱ���
HBase��ͨ��row��columnsȷ����Ϊһ��������Ԫ��Ϊcell��ÿ�� cell��������ͬһ�����ݵĶ���汾���汾ͨ��ʱ�����������ʱ�����������
64λ���͡�ʱ���������HBase(������д��ʱ�Զ� )��ֵ����ʱʱ����Ǿ�ȷ������ĵ�ǰϵͳʱ�䡣ʱ���Ҳ�����ɿͻ���ʽ��ֵ�����Ӧ�ó���Ҫ�������ݰ汾��ͻ���ͱ����Լ����ɾ���Ψһ�Ե�ʱ�����ÿ��
cell�У���ͬ�汾�����ݰ���ʱ�䵹���������µ�����������ǰ�档Ϊ�˱������ݴ��ڹ���汾��ɵĵĹ���
(��������������)������HBase�ṩ���������ݰ汾���շ�ʽ��һ�DZ������ݵ����n���汾�����DZ������һ��ʱ���ڵİ汾������������죩���û�����
���ÿ������������á�Cell��{row key, column(=<family> + <label>),
version} Ψһȷ���ĵ�Ԫ��cell�е�������û�����͵ģ�ȫ�����ֽ�����ʽ������
HBase �������洢
HBase�е����������ļ����洢��Hadoop HDFS�ļ�ϵͳ�ϣ���ʽ��Ҫ�����֣�
1.HFile HBase��KeyValue���ݵĴ洢��ʽ��HFile��Hadoop�Ķ����Ƹ�ʽ�ļ���ʵ����StoreFile���Ƕ�HFile������������װ����StoreFile�ײ����HFile
2.HLog File��HBase��WAL��Write Ahead Log�� �Ĵ洢��ʽ����������Hadoop��Sequence
File
HFile
HFile�ĸ�ʽΪ��
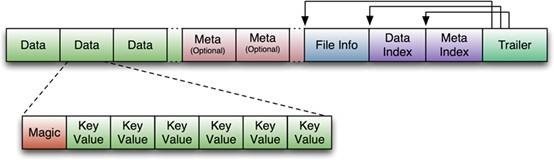
HFile��Ϊ�������֣�
1.Data Block �ΨC������е����ݣ��ⲿ�ֿ��Ա�ѹ��
2.Meta Block �� (��ѡ��)�C�����û��Զ����kv�ԣ����Ա�ѹ����
3.File Info �ΨCHfile��Ԫ��Ϣ������ѹ�����û�Ҳ��������һ���������Լ���Ԫ��Ϣ��
4.Data Block Index �ΨCData Block��������ÿ��������key�DZ�������block�ĵ�һ����¼��key��
5.Meta Block Index�� (��ѡ��)�CMeta Block��������
6.Trailer�C��һ���Ƕ����ġ�������ÿһ�ε�ƫ��������ȡһ��HFileʱ�������ȶ�ȡTrailer��Trailer������ÿ���ε���ʼλ
��(�ε�Magic Number��������ȫcheck)��Ȼ��DataBlock Index�ᱻ��ȡ���ڴ��У�������������ij��keyʱ������Ҫɨ������HFile����ֻ����ڴ����ҵ�key���ڵ�block��ͨ��һ�δ���io������
block��ȡ���ڴ��У����ҵ���Ҫ��key��DataBlock Index����LRU������̭��
HFile�ļ������������ȹ̶��Ŀ�ֻ��������Trailer��FileInfo
1.Trailer��ָ��ָ���������ݿ����ʼ��
2.File Info�м�¼���ļ���һЩMeta��Ϣ�����磺AVG_KEY_LEN, AVG_VALUE_LEN,
LAST_KEY, COMPARATOR, MAX_SEQ_ID_KEY��
HFile��Data Block��Meta Blockͨ������ѹ����ʽ�洢��ѹ��֮����Դ���������IO�ʹ���IO����֮�����Ŀ�����Ȼ����Ҫ����cpu����ѹ���ͽ�ѹ����Ŀ��Hfile��ѹ��֧�����ַ�ʽ��Gzip��Lzo��
Data Index��Meta Index���¼��ÿ��Data���Meta�����ʼ�㡣Data Block��HBase
I/O�Ļ�����Ԫ��Ϊ�����Ч�ʣ�HRegionServer���л���LRU��Block Cache���ơ�ÿ��Data��Ĵ�С�����ڴ���һ��Table��ʱ��ͨ������ָ������ŵ�Block������˳��Scan��С��Block���������ѯ��
ÿ��Data����˿�ͷ��Magic�������һ����KeyValue��ƴ�Ӷ���, Magic���ݾ���һЩ������֣�Ŀ���Ƿ�ֹ������
HFile�����ÿ��KeyValue�Ծ���һ����byte���顣���byte������������˺ܶ�������й̶��Ľṹ��

1.KeyLength��ValueLength�������̶��ij��ȣ��ֱ����Key��Value�ij���
2.Key���֣�Row Length�ǹ̶����ȵ���ֵ����ʾRowKey�ij��ȣ�Row ����RowKey��Column
Family Length�ǹ̶����ȵ���ֵ����ʾFamily�ij��ȣ����ž���Column Family���ٽ�����Qualifier��Ȼ���������̶����ȵ���ֵ����ʾTime
Stamp��Key Type��Put/Delete��
3.Value����û����ô���ӵĽṹ�����Ǵ���Ķ���������
HLog File
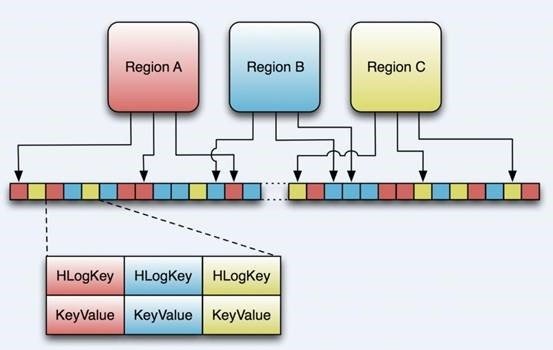
HLog�ļ�����һ����ͨ��Hadoop Sequence File��Sequence File ��Key��HLogKey����HLogKey�м�¼��д�����ݵĹ�����Ϣ������table��region�����⣬ͬʱ������
sequence number��timestamp��timestamp�ǡ�д��ʱ�䡱��sequence
number����ʼֵΪ0�����������һ�δ����ļ�ϵͳ��sequence number��HLog Sequece
File��Value��HBase��KeyValue������ӦHFile�е�KeyValue��
HBase ��ϵͳ�ܹ�
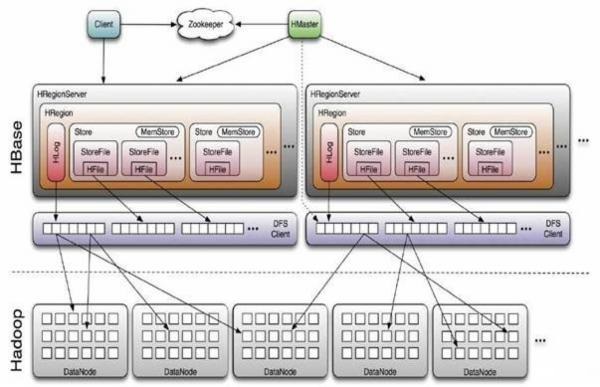
Client
��������HBase�Ľӿڣ�clientά����һЩcache���ӿ��HBase�ķ��ʣ�����regione��λ����Ϣ��
1.ʹ��HBase RPC������HMaster��HRegionServer����ͨ��
2.Client��HMaster����ͨ�Ž��й��������
3.Client��HRegionServer�������ݶ�д�����
Zookeeper
1.��֤�κ�ʱ��Ⱥ��ֻ��һ��master������HMaster��������
2.��������Region��Ѱַ��ڡ�
3.ʵʱ���Region Server��״̬����Region server�����ߺ�������Ϣʵʱ֪ͨ��Master��HRegionServer���Լ���Ephedral��ʽע�ᵽZookeeper�У�HMaster��ʱ��֪����HRegionServer�Ľ���״��
4.�洢HBase��schema,��������Щtable��ÿ��table����Щcolumn family��Zookeeper
Quorum�洢-ROOT-����ַ��HMaster��ַ
HMaster
HMasterû�е������⣬HBase�п����������HMaster��ͨ��Zookeeper��Master
Election���Ʊ�֤����һ��Master�����У���Ҫ����Table��Region�Ĺ���������
1.�����û��Ա�����ɾ�IJ����
2.����HRegionServer�ĸ��ؾ��⣬����Region�ֲ�
3.Region Split������Region�ķֲ�������ʧЧ��region server�����·������ϵ�region��
4.��HRegionServerͣ������ʧЧHRegionServer��RegionǨ��
5.����GFS�ϵ������ļ�����
HRegionServer
HBase������ĵ�ģ�飬��Ҫ������Ӧ�û�I/O������HDFS�ļ�ϵͳ�ж�д����
1.HRegionServer����һЩ��HRegion����
2.ÿ��HRegion��ӦTable��һ��Region��HRegion�ɶ��HStore���
3.ÿ��HStore��ӦTable��һ��Column Family�Ĵ洢
4.Column Family����һ�����еĴ洢��Ԫ���ʽ�������ͬIO���Ե�Column����һ��Column
Family�����Ч
5.HRegionServer�����з������й����б�ù����region

���Կ�����client����HBase�����ݵĹ��̲�����ҪHMaster���루Ѱַ����zookeeper��HRegionServer�����ݶ�д����HRegioneServer����HMaster����ά����table��region��Ԫ������Ϣ�����غܵ͡�
HStore
HBase�洢�ĺ��ġ���MemStore��StoreFile��ɡ�MemStore��Sorted
Memory Buffer���û�д�����ݵ����̣�
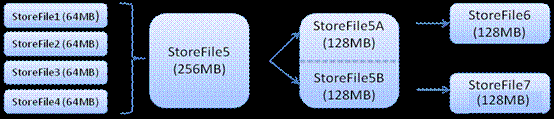
Clientд�� -> ����MemStore��һֱ��MemStore�� -> Flush��һ��StoreFile��ֱ��������һ����ֵ
-> ����Compact�ϲ����� -> ���StoreFile�ϲ���һ��StoreFile��ͬʱ���а汾�ϲ�������ɾ��
-> ��StoreFiles Compact�����γ�Խ��Խ���StoreFile ->
����StoreFile��С����һ����ֵ����Split�������ѵ�ǰRegion Split��2��Region��Region�����ߣ���Split����2������Region�ᱻHMaster���䵽��Ӧ��HRegionServer
�ϣ�ʹ��ԭ��1��Region��ѹ�����Է�����2��Region�ϡ��ɴ˹��̿�֪��HBaseֻ���������ݣ������ø��º�ɾ��������������Compact
�����ģ����ԣ��û�д����ֻ��Ҫ���뵽�ڴ漴���������أ��Ӷ���֤I/O�����ܡ�
HLog
�ڷֲ�ʽϵͳ�����У�������ϵͳ��������崻���һ��HRegionServer�����˳���MemStore�е��ڴ����ݾͻᶪʧ������HLog��
�Ƿ�ֹ���������ÿ��HRegionServer�ж�����һ��HLog����HLog��һ��ʵ��Write Ahead
Log���࣬ÿ���û�����д��Memstore��ͬʱ��Ҳ��дһ�����ݵ�HLog�ļ���HLog�ļ����ڻ�������£���ɾ���ɵ��ļ�(�ѳ־û���
StoreFile�е�����)����HRegionServer������ֹ��HMaster��ͨ��Zookeeper��֪��HMaster���ȴ���������
HLog�ļ�������ͬregion��log���ݲ�֣��ֱ�ŵ���ӦregionĿ¼�£�Ȼ���ٽ�ʧЧ��region���·��䣬��ȡ����Щregion��
HRegionServer��Load Region�Ĺ����У��ᷢ������ʷHLog��Ҫ��������˻�Replay
HLog�е����ݵ�MemStore�У�Ȼ��flush��StoreFiles��������ݻָ���
HBase �ķ���
1.Native Java API������Ч�ķ��ʷ�ʽ���ʺ�Hadoop
MapReduce Job����������HBase������
2.HBase Shell��HBase�������й��ߣ���Ľӿڣ��ʺ�HBase����ʹ��
3.Thrift Gateway������Thrift���л�������֧��C++��PHP��Python�ȶ������ԣ��ʺ������칹ϵͳ���߷���HBase������
4.REST Gateway��֧��REST ����Http API����HBase,
�������������
5.Pig������ʹ��Pig Latin��ʽ�������������HBase�е����ݣ���Hive���ƣ���������Ҳ�DZ����MapReduce
Job������HBase�����ݣ��ʺ�������ͳ��
6.Hive����ǰHive��Release�汾��û�м����HBase��֧�֣�������һ���汾Hive
0.7.0�н���֧��HBase������ʹ������SQL����������HBase
|






