|
这一章我们探索了Spark作业的运行过程,但是没把整个过程描绘出来,好,跟着我走吧,let
you know!
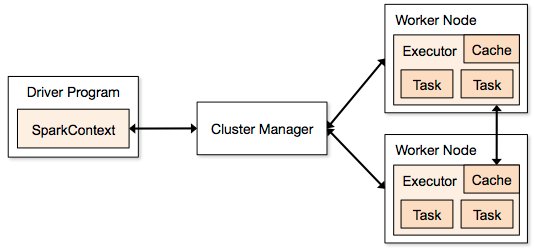
我们先回顾一下这个图,Driver Program是我们写的那个程序,它的核心是SparkContext,回想一下,从api的使用角度,RDD都必须通过它来获得。
下面讲一讲它所不为认知的一面,它和其它组件是如何交互的。
Driver向Master注册Application过程
SparkContext实例化之后,在内部实例化两个很重要的类,DAGScheduler和TaskScheduler。
在standalone的模式下,TaskScheduler的实现类是TaskSchedulerImpl,在初始化它的时候SparkContext会传入一个SparkDeploySchedulerBackend。
在SparkDeploySchedulerBackend的start方法里面启动了一个AppClient。
val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend", args, sc.executorEnvs,
classPathEntries, libraryPathEntries, extraJavaOpts)
val sparkHome = sc.getSparkHome()
val appDesc = new ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
sparkHome, sc.ui.appUIAddress, sc.eventLogger.map(_.logDir))
client = new AppClient(sc.env.actorSystem, masters, appDesc, this, conf)
client.start() |
maxCores是由参数spark.cores.max来指定的,executorMemoy是由spark.executor.memory指定的。
AppClient启动之后就会去向Master注册Applicatoin了,后面的过程我用图来表达。
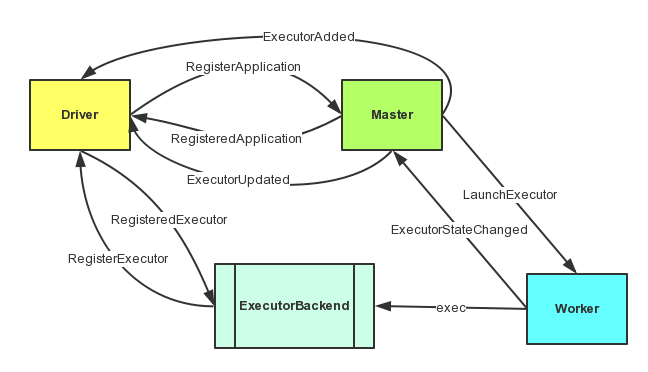
上面的图中涉及到了三方通信,具体的过程如下:
1、Driver通过AppClient向Master发送了RegisterApplication消息来注册Application,Master收到消息之后会发送RegisteredApplication通知Driver注册成功,Driver的接收类还是AppClient。
2、Master接受到RegisterApplication之后会触发调度过程,在资源足够的情况下会向Woker和Driver分别发送LaunchExecutor、ExecutorAdded消息。
3、Worker接收到LaunchExecutor消息之后,会执行消息中携带的命令,执行CoarseGrainedExecutorBackend类(图中仅以它继承的接口ExecutorBackend代替),执行完毕之后会发送ExecutorStateChanged消息给Master。
4、Master接收ExecutorStateChanged之后,立即发送ExecutorUpdated消息通知Driver。
5、Driver中的AppClient接收到Master发过来的ExecutorAdded和ExecutorUpdated后进行相应的处理。
6、启动之后的CoarseGrainedExecutorBackend会向Driver发送RegisterExecutor消息。
7、Driver中的SparkDeploySchedulerBackend(具体代码在CoarseGrainedSchedulerBackend里面)接收到RegisterExecutor消息,回复注册成功的消息RegisteredExecutor给ExecutorBackend,并且立马准备给它发送任务。
8、CoarseGrainedExecutorBackend接收到RegisteredExecutor消息之后,实例化一个Executor等待任务的到来。
资源的调度
好,在我们讲完了整个注册Application的通信过程之后,其中一个比较重要的地方是它的调度这块,它是怎么调度的?这也是我在前面为什么那么强调maxCores和executorMemoy的原因。
细心的读者如果看了第一章《spark-submit提交作业过程》的就知道,其实我已经讲过调度了,因为当时不知道这个app是啥。但是现在我们知道app是啥了。代码我不就贴了,总结一下吧。
1、先调度Driver,再调度Application。
2、它的调度Application的方式是先进先出,所以就不要奇怪为什么你的App总得不到调度了,就像去北京的医院看病,去晚了号就没了,是一个道理。
3、Executor的分配方式有两种,一种是倾向于把任务分散在多个节点上,一种是在尽量少的节点上运行,由参数spark.deploy.spreadOut参数来决定的,默认是true,把任务分散到多个节点上。
遍历所有等待的Application,给它分配Executor运行的Worker,默认分配方式如下:
1、先从workers当中选出内存大于executorMemoy的worker,并且按照空闲cpu数从大到小的顺序来排序。
2、遍历worker,从可用的worker分配需要的cpu数,每个worker提供一个cpu核心,直到cpu数不足或者maxCores分配完毕。
3、给选出来的worker发送任务,让它们启动Executor,每个Executor占用的内存是我们设定的executorMemoy。
资源调度的过程大体是这样的,说到这里有些童鞋在有点儿疑惑了,那我们任务调度里面FIFO/FAIR调度是在哪里用的?任务调度器调度的不是Application,而是你的代码里面被解析出来的所有Task,这在上一章当中有提到。
基于这个原因,在共用SparkContext的情况下,比如Shark、JobServer什么的,任务调度器的作用才会明显。
Driver向Executor发布Task过程
下面我们讲一讲Driver向Executor发布Task过程,这在上一章是讲过的,现在把图给大家放出来了。
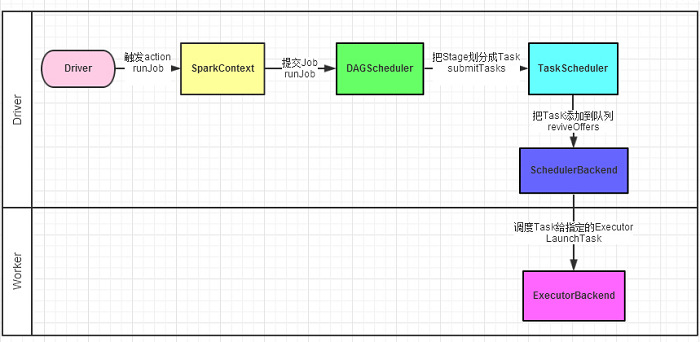
1、Driver程序的代码运行到action操作,触发了SparkContext的runJob方法。
2、SparkContext比较懒,转手就交给DAGScheduler。
3、DAGScheduler把Job划分stage,然后把stage转化为相应的Tasks,把Tasks交给TaskScheduler。
4、通过TaskScheduler把Tasks添加到任务队列当中,转手就交给SchedulerBackend了。
5、调度器给Task分配执行Executor,ExecutorBackend负责执行Task了。
补充:ExecutorBackend执行Task,是通过它内部的Executor来执行的,Executor内部有个线程池,new了一个TaskRunner交给线程池了。
Task状态更新
Task执行是通过TaskRunner来运行,它需要通过ExecutorBackend和Driver通信,通信消息是StatusUpdate:
1、Task运行之前,告诉Driver当前Task的状态为TaskState.RUNNING。
2、Task运行之后,告诉Driver当前Task的状态为TaskState.FINISHED,并返回计算结果。
3、如果Task运行过程中发生错误,告诉Driver当前Task的状态为TaskState.FAILED,并返回错误原因。
4、如果Task在中途被Kill掉了,告诉Driver当前Task的状态为TaskState.FAILED。
下面讲的是运行成功的状态,具体过程以文字为主。
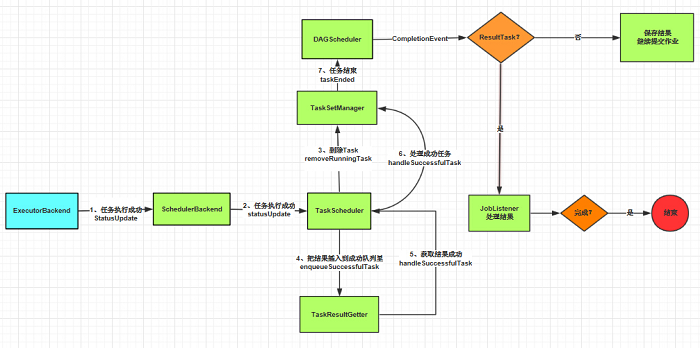
1、Task运行结束之后,调用ExecutorBackend的statusUpdate方法,把结果返回。结果超过10M,就把结果保存在blockManager处,返回blockId,需要的时候通过blockId到blockManager认领。
2、ExecutorBackend直接向Driver发送StatusUpdate返回Task的信息。
3、Driver(这里具体指的是SchedulerBackend)接收到StatusUpdate消息之后,调用TaskScheduler的statusUpdate方法,然后准备给ExecutorBackend发送下一批Task。
4、TaskScheduler通过TaskId找到管理这个Task的TaskSetManager(负责管理一批Task的类),从TaskSetManager里面删掉这个Task,并把Task插入到TaskResultGetter(负责获取Task结果的类)的成功队列里。
5、TaskResultGetter获取到结果之后,调用TaskScheduler的handleSuccessfulTask方法把结果返回。
6、TaskScheduler调用TaskSetManager的handleSuccessfulTask方法,处理成功的Task。
7、TaskSetManager调用DAGScheduler的taskEnded方法,告诉DAGScheduler这个Task运行结束了,如果这个时候Task全部成功了,就会结束TaskSetManager。
8、DAGScheduler在taskEnded方法里触发CompletionEvent事件,CompletionEvent分ResultTask和ShuffleMapTask来处理。
1)ResultTask:job的numFinished加1,如果numFinished等于它的分片数,则表示任务该Stage结束,标记这个Stage为结束,最后调用JobListener(具体实现在JobWaiter)的taskSucceeded方法,把结果交给resultHandler(经过包装的自己写的那个匿名函数)处理,如果完成的Task数量等于总任务数,任务退出。
2)ShuffleMapTask:
(1)调用Stage的addOutputLoc方法,把结果添加到Stage的outputLocs列表里。
(2)如果该Stage没有等待的Task了,就标记该Stage为结束。
(3)把Stage的outputLocs注册到MapOutputTracker里面,留个下一个Stage用。
(4)如果Stage的outputLocs为空,表示它的计算失败,重新提交Stage。
(5)找出下一个在等待并且没有父亲的Stage提交。 |






