|
一 可靠性简介
Storm的可靠性是指Storm会告知用户每一个消息单元是否在一个指定的时间(timeout)内被完全处理。完全处理的意思是该MessageId绑定的源Tuple以及由该源Tuple衍生的所有Tuple都经过了Topology中每一个应该到达的Bolt的处理。
注: timetout 可以通过Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS
来指定
Storm中的每一个Topology中都包含有一个Acker组件。Acker组件的任务就是跟踪从某个task中的Spout流出的每一个messageId所绑定的Tuple树中的所有Tuple的处理情况。如果在用户设置的最大超时时间内这些Tuple没有被完全处理,那么Acker会告诉Spout该消息处理失败,相反则会告知Spout该消息处理成功,它会分别调用Spout中的fail和ack方法。
Storm允许用户在Spout中发射一个新的源Tuple时为其指定一个MessageId,这个MessageId可以是任意的Object对象。多个源Tuple可以共用同一个MessageId,表示这多个源Tuple对用户来说是同一个消息单元,它们会被放到同一棵tuple树中,如下图所示:
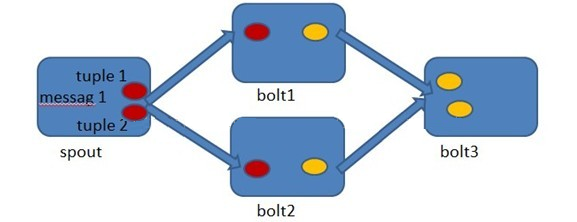
Tuple 树
在Spout中由message 1绑定的tuple1和tuple2分别经过bolt1和bolt2的处理,然后生成了两个新的Tuple,并最终流向了bolt3。当bolt3处理完之后,称message
1被完全处理了。
二 Acker 原理分析
storm里面有一类特殊的task称为acker(acker bolt),
负责跟踪spout发出的每一个tuple的tuple树。当acker发现一个tuple树已经处理完成了。它会发送一个消息给产生这个tuple的那个task。你可以通过Config.TOPOLOGY_ACKERS来设置一个topology里面的acker的数量,
默认值是1。 如果你的topology里面的tuple比较多的话, 那么把acker的数量设置多一点,效率会高一点。
理解storm的可靠性的最好的方法是来看看tuple和tuple树的生命周期,
当一个tuple被创建, 不管是spout还是bolt创建的, 它会被赋予一个64位的id,而acker就是利用这个id去跟踪所有的tuple的。每个tuple知道它的祖宗的id(从spout发出来的那个tuple的id),
每当你新发射一个tuple, 它的祖宗id都会传给这个新的tuple。所以当一个tuple被ack的时候,它会发一个消息给acker,告诉它这个tuple树发生了怎么样的变化。具体来说就是它告诉acker:
我已经完成了, 我有这些儿子tuple, 你跟踪一下他们吧。
(spout-tuple-id, tmp-ack-val)
tmp-ark-val = tuple-id ^ (child-tuple-id1 ^ child-tuple-id2 ... ) |
tmp-ack-val是要ack的tuple的id与由它新创建的所有的tuple的id异或的结果
当一个tuple需要ack的时候,它到底选择哪个acker来发送这个信息呢?
storm使用一致性哈希来把一个spout-tuple-id对应到acker,
因为每一个tuple知道它所有的祖宗的tuple-id, 所以它自然可以算出要通知哪个acker来ack。
注:一个tuple可能存在于多个tuple树,所有可能存在多个祖宗的tuple-id
acker是怎么知道每一个spout tuple应该交给哪个task来处理?
当一个spout发射一个新的tuple, 它会简单的发一个消息给一个合适的acker,并且告诉acker它自己的id(taskid),
这样storm就有了taskid-tupleid的对应关系。 当acker发现一个树完成处理了, 它知道给哪个task发送成功的消息。
Acker的高效性
acker task并不显式的跟踪tuple树。对于那些有成千上万个节点的tuple树,把这么多的tuple信息都跟踪起来会耗费太多的内存。相反,
acker用了一种不同的方式, 使得对于每个spout tuple所需要的内存量是恒定的(20 bytes)
. 这个跟踪算法是storm如何工作的关键,并且也是它的主要突破。
一个acker task存储了一个spout-tuple-id到一对值的一个mapping。这个对子的第一个值是创建这个tuple的taskid,
这个是用来在完成处理tuple的时候发送消息用的。 第二个值是一个64位的数字称作:ack val, ack
val是整个tuple树的状态的一个表示,不管这棵树多大。它只是简单地把这棵树上的所有创建的tupleid/ack的tupleid一起异或(XOR)。
当一个acker task 发现一个 ack val变成0了, 它知道这棵树已经处理完成了。
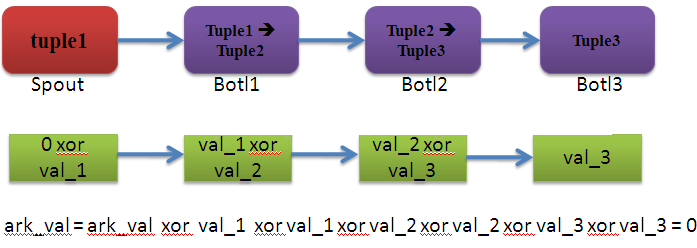
例如下图是一个简单的Topology。
一个简单的 Topology
ack_val的初值为0,varl_x表示新产生的tuple id ,它们经过Spout,Bolt1,Bolt2,Bolt3
处理,并与arv_val异或,最终arv_val变为0,表示tuple1被成功处理。
下面看一个稍微复杂一点的例子:
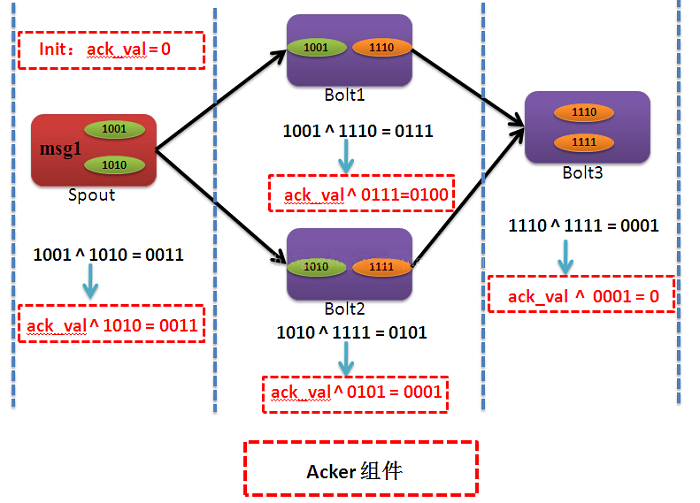
注:红色虚线框表示的是Acker组件,ack_val表示acker value的值,它的初值为0
msg1绑定了两个源tuple,它们的id分别为1001和1010.在经过Bolt1处理后新生成了tuple
id为1110,新生成的tuple与传入的tuple 1001进行异或得到的值为0111,然后Bolt1通过spout-tuple-id映射到指定的Acker组件,向它发送消息,Acker组件将Bolt1传过来的值与ack_val异或,更新ack_val的值变为了0100。与此相同经过Bolt2处理后,ack_val的值变为0001。最后经Bolt3处理后ack_val的值变为了0,说明此时由msg1标识的Tuple处理成功,此时Acker组件会通过事先绑定的task
id映射找到对应的Spout,然后调用该Spout的ack方法。
其流程如下图所示:
注:1. Acker (ack bolt)组件由系统自动产生,一般来说一个topology只有一个ack
bolt(当然可以通过配置参数指定多个),当bolt处理并下发完tuple给下一跳的bolt时,会发送一个ack给ack
bolt。ack bolt通过简单的异或原理(即同一个数与自己异或结果为零)来判定从spout发出的某一个Tuple是否已经被完全处理完毕。如果结果为真,ack
bolt发送消息给spout,spout中的ack函数被调用并执行。如果超时,则发送fail消息给spout,spout中的fail函数被调用并执行,spout中的ack和fail的处理逻辑由用户自行填写。
2. Acker对于每个Spout-tuple保存一个ack-val的校验值,它的初始值是0,
然后每发射一个tuple 就ack一个tuple,那么tuple的id都要跟这个校验值异或一下,并且把得到的值更新为ack-val的新值。那么假设每个发射出去的tuple都被ack了,
那么最后ack-val一定是0(因为一个数字跟自己异或得到的值是0)。
A xor A = 0.
A xor B…xor B xor A = 0,其中每一个操作数出现且仅出现两次。
3. tupleid是随机的64位数字, ack val碰巧变成0(例如:ark_val
= 1 ^ 2 ^ 3 = 0)而不是因为所有创建的tuple都完成了,这样的概率极小。算一下就知道了,
就算每秒发生10000个ack, 那么需要50000000万年才可能碰到一个错误。而且就算碰到了一个错误,
也只有在这个tuple失败的时候才会造成数据丢失。
看看storm在每种异常情况下是怎么避免数据丢失的:
1. 由于对应的task挂掉了,一个tuple没有被ack: storm的超时机制在超时之后会把这个tuple标记为失败,从而可以重新处理。
2. Acker挂掉了: 这种情况下由这个acker所跟踪的所有spout
tuple都会超时,也就会被重新处理。
3. Spout挂掉了: 在这种情况下给spout发送消息的消息源负责重新发送这些消息。比如Kestrel和RabbitMQ在一个客户端断开之后会把所有”处理中“的消息放回队列。
就像你看到的那样, storm的可靠性机制是完全分布式的, 可伸缩的并且是高度容错的。
三 Acker 编程接口
在Spout中,Storm系统会为用户指定的MessageId生成一个对应的64位的整数,作为整个Tuple
Tree的RootId。RootId会被传递给Acker以及后续的Bolt来作为该消息单元的唯一标识。同时,无论Spout还是Bolt每次新生成一个Tuple时,都会赋予该Tuple一个唯一的64位整数的Id。
当Spout发射完某个MessageId对应的源Tuple之后,它会告诉Acker自己发射的RootId以及生成的那些源Tuple的Id。而当Bolt处理完一个输入Tuple并产生出新的Tuple时,也会告知Acker自己处理的输入Tuple的Id以及新生成的那些Tuple的Id。Acker只需要对这些Id进行异或运算,就能判断出该RootId对应的消息单元是否成功处理完成了。
下面这个是spout要实现的接口:
public interface ISpout extends Serializable {
void open(Map conf, TopologyContext context,
SpoutOutputCollector collector);
void close();
void nextTuple();
void ack(Object msgId);
void fail(Object msgId); |
首先storm通过调用spout的nextTuple方法来获取下一个tuple,
Spout通过open方法参数里面提供的SpoutOutputCollector来发射新tuple到它的其中一个输出消息流,
发射tuple的时候spout会提供一个message-id, 后面通过这个message-id来追踪这个tuple。
this.collector.emit(new Values("hello world"),msgId); |
注:msgId是提供给Acker组件使用的,Acker组件使用msgId来跟踪Tuple树
接下来, 这个发射的tuple被传送到消息处理者bolt那里, storm会跟踪由此所产生的这课tuple树。如果storm检测到一个tuple被完全处理了,
那么storm会以最开始的那个message-id作为参数去调用消息源的ack方法;反之storm会调用spout的fail方法。值得注意的是,
storm调用ack或者fail的task始终是产生这个tuple的那个task。所以如果一个spout被分成很多个task来执行,
消息执行的成功失败与否始终会通知最开始发出tuple的那个task。
作为storm的使用者,有两件事情要做以更好的利用storm的可靠性特征。
首先,在你生成一个新的tuple的时候要通知storm; 其次,完成处理一个tuple之后要通知storm。
这样storm就可以检测整个tuple树有没有完成处理,并且通知源spout处理结果。storm提供了一些简洁的api来做这些事情。
由一个tuple产生一个新的tuple称为:anchoring。你发射一个新tuple的同时也就完成了一次anchoring。看下面这个例子:
这个bolt把一个包含一个句子的tuple分割成每个单词一个tuple。
public class SplitSentence implements IRichBolt {
OutputCollector _collector;
public void prepare(Map conf,
TopologyContext context,
OutputCollector collector) {
_collector = collector;
}
public void execute(Tuple tuple) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
_collector.emit(tuple,new Values(word));
}
_collector.ack(tuple);
}
publicvoid cleanup() {}
publicvoid declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(newFields("word"));
}
} |
看一下这个execute方法, emit的第一个参数是输入tuple,
第二个参数则是输出tuple, 这其实就是通过输入tuple anchoring了一个新的输出tuple。因为这个“单词tuple”被anchoring在“句子tuple”一起,
如果其中一个单词处理出错,那么这整个句子会被重新处理。作为对比, 我们看看如果通过下面这行代码来发射一个新的tuple的话会有什么结果。
_collector.emit(new Values(word)); |
用这种方法发射会导致新发射的这个tuple脱离原来的tuple树(unanchoring),
如果这个tuple处理失败了, 整个句子不会被重新处理。一个输出tuple可以被anchoring到多个输入tuple。这种方式在stream合并或者stream聚合的时候很有用。一个多入口tuple处理失败的话,那么它对应的所有输入tuple都要重新执行。看看下面演示怎么指定多个输入tuple:
List<Tuple> anchors = new ArrayList<Tuple>();
anchors.add(tuple1);
anchors.add(tuple2);
_collector.emit(anchors,new Values(1,2,3)); |
我们通过anchoring来构造这个tuple树,最后一件要做的事情是在你处理完这个tuple的时候告诉storm,
通过OutputCollector类的ack和fail方法来做,如果你回过头来看看SplitSentence的例子,
你可以看到“句子tuple”在所有“单词tuple”被发出之后调用了ack。
你可以调用OutputCollector 的fail方法去立即将从消息源头发出的那个tuple标记为fail,
比如你查询了数据库,发现一个错误,你可以马上fail那个输入tuple, 这样可以让这个tuple被快速的重新处理,
因为你不需要等那个timeout时间来让它自动fail。
每个你处理的tuple, 必须被ack或者fail。因为storm追踪每个tuple要占用内存。所以如果你不ack/fail每一个tuple,
那么最终你会看到OutOfMemory错误。
大多数Bolt遵循这样的规律:读取一个tuple;发射一些新的tuple;在execute的结束的时候ack这个tuple。这些Bolt往往是一些过滤器或者简单函数。Storm为这类规律封装了一个BasicBolt类。如果用BasicBolt来做,
上面那个SplitSentence可以改写成这样:
<pre name="code" class="java"> publicclass SplitSentence implements IBasicBolt {
public void prepare(Map conf,
TopologyContext context) {
}
public void execute(Tuple tuple,
BasicOutputCollector collector) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
collector.emit(newValues(word));
}
}
publicvoid cleanup() {}
publicvoid declareOutputFields(
OutputFieldsDeclarer declarer) {
declarer.declare(newFields("word"));
}
} |
这个实现比之前的实现简单多了, 但是功能上是一样的,发送到BasicOutputCollector的tuple会自动和输入tuple相关联,而在execute方法结束的时候那个输入tuple会被自动ack的。
作为对比,处理聚合和合并的bolt往往要处理一大堆的tuple之后才能被ack, 而这类tuple通常都是多输入的tuple,
所以这个已经不是IBasicBolt可以罩得住的了。
注:当一个Tuple处理失败的时候,storm不会自动的重发该tuple,需要用户自己来编写逻辑重新处理fail掉的Tuple,可以将其放入一个列表中,在nextTuple()中获取这些失败的tuple,重新发射。
四 调整可靠性
acker task是非常轻量级的, 所以一个topology里面不需要很多acker。你可以通过Strom
UI(id: -1)来跟踪它的性能。 如果它的吞吐量看起来不正常,那么你就需要多加点acker了。
如果可靠性对你来说不是那么重要 ― 你不太在意在一些失败的情况下损失一些数据,
那么你可以通过不跟踪这些tuple树来获取更好的性能。不去跟踪消息的话会使得系统里面的消息数量减少一半,
因为对于每一个tuple都要发送一个ack消息。并且它需要更少的id来保存下游的tuple, 减少带宽占用。
有三种方法可以去掉可靠性:
第一是把Config.TOPOLOGY_ACKERS 设置成 0. 在这种情况下,
storm会在spout发射一个tuple之后马上调用spout的ack方法。也就是说这个tuple树不会被跟踪。
第二个方法是在tuple层面去掉可靠性。 你可以在发射tuple的时候不指定messageid来达到不跟踪某个特定的spout
tuple的目的。
最后一个方法是如果你对于一个tuple树里面的某一部分到底成不成功不是很关心,那么可以在发射这些tuple的时候unanchor它们。
这样这些tuple就不在tuple树里面, 也就不会被跟踪了。
五 小结
在分布式系统中实现对数据的可靠处理是一件繁琐的事情,storm将其实现的非常优雅,其Arcker不仅使得对数据的可靠处理变得简单而且还很高效,这个很值得学习和借鉴。 |






